




向量搜索结合图数据库 颠覆传统检索模式

想象一下,在浩瀚的信息海洋里,我们不再满足于“找到某个东西”,而是想探索“这个东西像什么”,甚至更进一步——“它们之间有什么故事”。这,正是向量搜索与图数据结合带来的革命。我们先来看一组对比,再聊聊它们如何联手。 01 概述 你猜怎么着?传统的数据库搜索,就像在翻一本电话簿——你能查“谁有一头红发
想象一下,在浩瀚的信息海洋里,我们不再满足于“找到某个东西”,而是想探索“这个东西像什么”,甚至更进一步——“它们之间有什么故事”。这,正是向量搜索与图数据结合带来的革命。我们先来看一组对比,再聊聊它们如何联手。
.01
概述
你猜怎么着?传统的数据库搜索,就像在翻一本电话簿——你能查“谁有一头红发”或者“蓝色的车是谁的”。逻辑清晰,但刻板得可怜。向量相似性搜索的出现把游戏规则彻底重写了。它不再依赖死板的关键词,而是回答:“这玩意儿跟什么最像?”——它在语义的深海里打捞那些隐藏的相似性。
但光找到相似的东西还不够。现实世界的复杂性,从来不是孤立的数据点,而是它们之间盘根错节的联系。这恰恰是图数据库的强项:它擅长看清“谁跟谁有关系”,或者“两点之间的最短路径是什么”。
那么,要是把这两样东西拼在一起呢?答案呼之欲出:你不仅能找到相似的东西,还能在一瞬间看到它们如何彼此关联——一个更完整、更真实的知识网络,就这么活过来了。
.02
传统数据库 vs. 向量相似性搜索 vs. 图数据库
举个例子,警方查案时,光知道嫌疑人的外貌特征远远不够,还得摸清他的社交圈、活动轨迹。向量相似性搜索能帮忙找到长相相似的面孔,而图数据库则负责把这些面孔之间的关系网描绘出来。两者合力,才触及了数据智能的真正内核。
.03
向量搜索的核心:向量嵌入
向量嵌入这东西,说穿了一点都不玄乎:它就是给文本、图片甚至节点“量一量身高腰围”,生成一串高维的数字。比如OpenAI的text-embedding-3-small,能把一段文字转成1536维的向量。打个比方,在二维空间里,“苹果”和“香蕉”会凑得很近,而“计算机”就站得远远的。这样一来,AI就能凭向量之间的距离,认出来事物之间的语义相似性。
速度和性能优化
- 查询延迟:像PineconeDB这类向量数据库,面对百万级别的嵌入向量,照样能在50毫秒内搞定查询。
- 批量处理:OpenAI的嵌入API每秒能处理几百条文本,给实时应用铺平了路。
- 维度 vs. 计算量:维度越高,向量揣着的信息越丰富,但计算开销也跟着涨。比如1536维的向量能捕捉更多语境细节,可搜索时就得靠更强的算力来撑。
要是换成PostgreSQL跑传统查询,它能找出“上个月买了某产品”的客户。但换到向量数据库Pinecone,它就能揪出“购买习惯相似”的人群——这才是真正意义上的智能搜索。
.04
图数据库:数据关系的魔法师
图数据库和关系型数据库的差别,就好比一张地铁线路图对上一份车站列表。后者告诉你每个站点的信息,前者却直接把站点之间的连接画给你看——最短路径,一目了然。
在图数据库里:
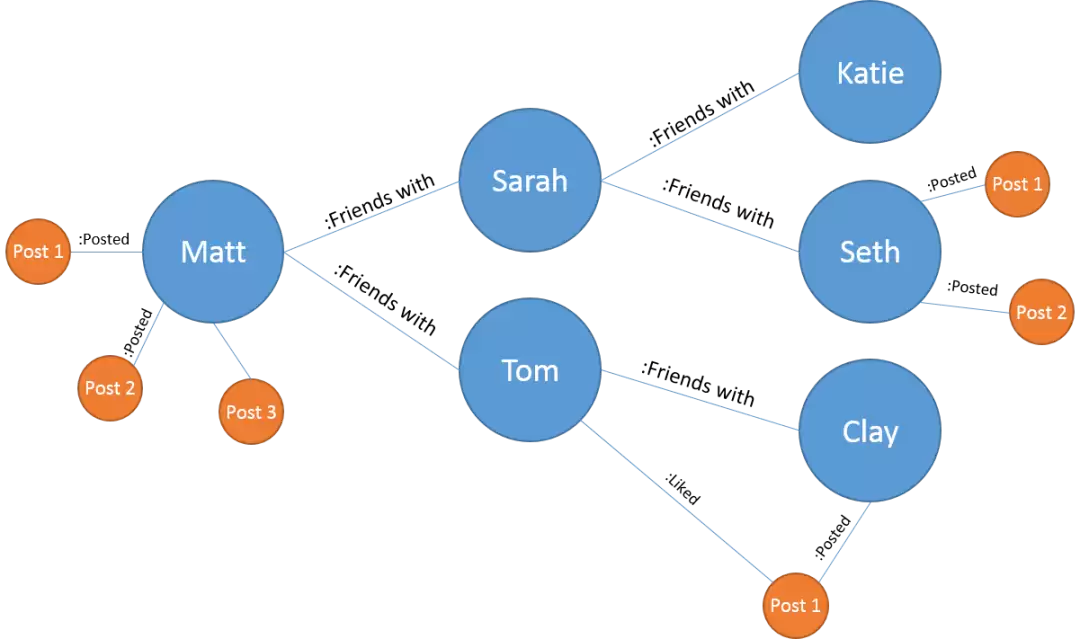
- 节点:代表实体(比如用户、产品)。
- 边:定义关系(比如“朋友关系”、“买过某物”)。
- 属性:存储额外信息(比如时间戳、评分)。
拿Neo4j来说,它能毫秒级处理复杂的关系查询,哪怕是在数十亿个节点和边的体量下,依然保持高效。相比之下,传统SQL得整好几个JOIN操作才能干类似的活,查询复杂度能到O(n^k)级别。
.05
两者结合:向量搜索 + 图数据库 = 未来趋势!
把向量搜索和图数据库凑到一起,主要有两条路子。
方式1:在图数据库里存向量
一些现代图数据库(比如Neo4j、Amazon Neptune)已经允许直接存储向量了,这样一来就能玩混合查询:
- 先用向量搜索找出相似节点。
- 再顺着图数据库找到它们的关系。
比如在一个社交平台上,你可以先向量搜索挑出兴趣相投的用户,再通过图数据库查他们的朋友链,逮出社交网络里的共同好友。
优点:
✅ 数据管理更简单,不用在多系统之间来回倒腾。
✅ 查询速度更快,数据搬运的延迟少了很多。
挑战:
⚠ 高维向量可能拖累图数据库的扩展性。
⚠ 有可能牺牲一点高维向量的查询精度。
方式2:分开存储,搞混合索引
另一种思路是把向量数据库和图数据库各自独立,然后用一个集成层把它们串起来。例如:
- 用Pinecone跑向量搜索,找到最相似的产品。
- 再用Neo4j图数据库,查这个产品的用户购买关系,推荐出最相关的商品。
这种方法特别适合大规模数据分析的场面,比如:
- 电子商务推荐系统:找出相似商品,再结合购买行为给出更精准的推荐。
- 金融反欺诈:检测交易模式相似的用户,同时剖析他们的社交关联。
优点:
✅ 每个系统都能独立优化,查询速度蹭蹭上涨。
✅ 能轻松扩展到更大的数据集。
挑战:
⚠ 需要额外的数据同步机制来维持一致性。
⚠ 查询延迟有可能稍微增加。
.06
结语:数据智能的未来
向量相似性搜索带我们发现“像”的东西,图数据库则帮我们理解“连”的东西。当它们撞到一起,数据的价值就被彻底点燃,带来一场全新的智能搜索体验。
眼下,越来越多的图数据库开始原生支持向量搜索,数据管理变革的风口就在面前。未来,AI不只是理解数据本身,更会读懂数据之间的千丝万缕——那时候,真正的智能决策才算落地。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:向量搜索结合图数据库 颠覆传统检索模式要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在招聘这个行业中,数据录入的繁琐程度相信大家都有切身体会。每天需要从各类网页、社交平台、招聘站点中搜寻候选人信息,再手动一条条录入系统,既耗时费力又容易出错。今天要介绍的这款Kwal Chrome插件,正是为了彻底解决这一痛点而设计的。什么是 Kwal Chrome 扩展程序 插件?该插件的定位十分
网红经济正在进化——Twinning AI带来的玩法是:粉丝可以直接跟你的人工智能分身聊天,而你,每次互动都能收到真金白银。它集成了专业的声音克隆、文本和语音消息,以及数据分析能力,让粉丝互动变得既有趣又能变&现。 什么是Twinning AI? 简单来说,Twinning AI允许网红创建一个属于
在跨境电商和全球业务快速发展的今天,发票与财务管理工具的重要性日益凸显。AI技术的加入,让这些原本繁琐的流程实现了质的飞跃。Invoicemint 正是这样一款专注全球企业的智能发票与财务管理软件——它不只是一个简单的发票生成器,而是一套覆盖从开票、对账到税务合规、催款的全链路解决方案。 什么是In
想象一下,你随时都能找到一个倾听者——不带任何偏见,不会感到疲惫,而且完全匿名。这听起来像科幻小说里的情节,但现在已经成为现实。MyWhy 就是这样一款 AI 心理治疗应用,它将专业的情感支持装进你的口袋,让心理健康服务不再是奢侈品,而是像打开手机一样触手可及。什么是MyWhy?简单来说,MyWhy
- 日榜
- 周榜
- 月榜
热点快看