




Dwarkesh Patel谈下一代AI源自实践应用

硅谷知名科技播客主持人 Dwarkesh Patel 近期在业内抛出了一个备受关注的问题:AI 领域下一个训练范式,究竟会朝哪个方向发展? 首先了解一下背景。年仅25岁的 Dwarkesh Patel,其主持的《Dwarkesh Podcast》已成为 AI 从业者获取前沿动态的重要渠道。他曾访谈过
硅谷知名科技播客主持人 Dwarkesh Patel 近期在业内抛出了一个备受关注的问题:AI 领域下一个训练范式,究竟会朝哪个方向发展?
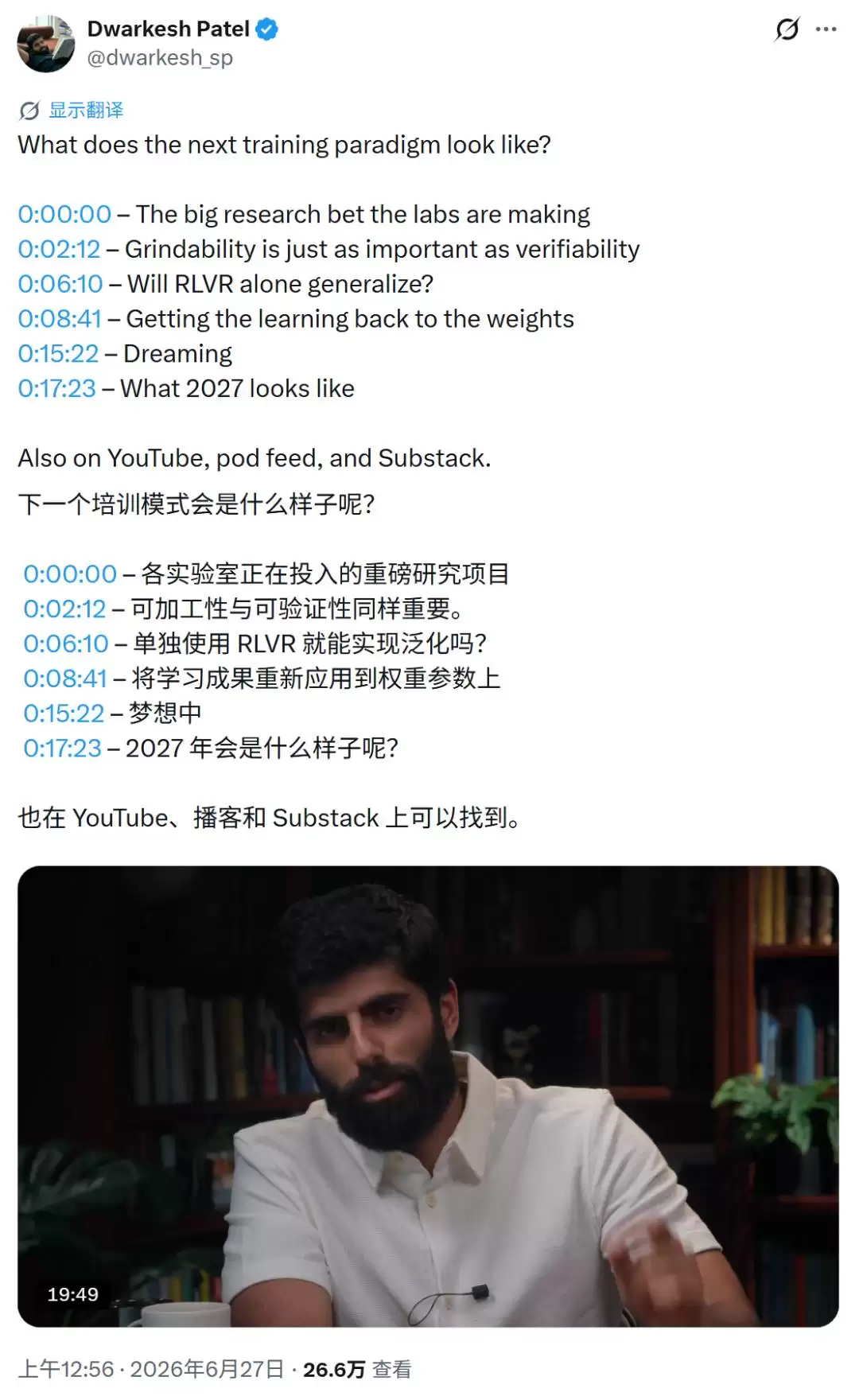
首先了解一下背景。年仅25岁的 Dwarkesh Patel,其主持的《Dwarkesh Podcast》已成为 AI 从业者获取前沿动态的重要渠道。他曾访谈过的嘉宾包括 Ilya Sutskever、Andrej Karpathy、Dario Amodei、Demis Hassabis、Mark Zuckerberg 等行业领军人物,2024年更是被《时代》杂志列入 TIME100 AI 榜单。可以说,他所提出的观点基本反映了前沿 AI 实验室正在探索的方向。
在其最新一期节目中,他将当前主流 AI 实验室押注的技术路线概括为一个核心概念:RLVR,即基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards)。简单来说,就是让模型在大量能够自动判断对错的任务中反复试错,从而训练出规划、纠错、迭代和长线执行的能力。今天代码与数学领域取得的快速突破,很大程度上正是得益于这一思路。
不过,Dwarkesh 真正想追问的是:如果下一代 AI 仅仅依赖这种“可验证任务训练”,真的足够吗?
他的判断是:很可能不够。原因在于,一个任务仅仅“可验证”还不够,还必须具备“可反复练习”的特性。这里的关键概念是 “可磨性”(grindability)——放到 AI 训练的语境中,就是指“可频繁刷题性”或“可大规模并行试错的能力”。
代码任务就是典型的“可刷”任务。你准备一个软件仓库、一个待修复的 bug、一个测试用例,然后将同一环境复制出几千份,让几千个智能体同时进行尝试。谁通过了测试,谁就获得分数。这个过程完全并行、可复现、可重置,几乎是为 RLVR 量身定制。数学题也是同样的道理,答案对错可验证,训练环境也易于复制。
但 Dwarkesh 提出了一个非常有趣的观察:为什么 AI 在“使用电脑”这项任务上,进展反而比代码和数学慢?表面上看,电脑使用也是可验证的——商品下单是否成功、活动场地有没有预订、税表是否提交,这些结果都能判断。然而,问题在于它很难被大规模复制和回放。你不可能让一千个智能体同时跑到亚马逊上反复执行同一个结账流程,因为真实网站会识别机器人、封禁账户、改变状态。当然,你可以克隆 Slack、Gmail、Amazon 这类应用来构建模拟器,但在这个阶段,那仍然是一个高成本、低扩展性的工程。
换句话说,AI 在某个领域进步迅速,并不仅仅是因为答案可验证,而是因为该领域能够被包装成可复制、可回放、可并行试错的训练环境。这也解释了为什么代码、数学、游戏类任务成了 RLVR 的天然温床,而许多真实世界的任务却很难直接套用这套训练范式。
接着,他将问题推向更复杂的现实世界。如果我们想训练一个 AI 从零开始创业,该怎么办?想训练它打赢一场官司,怎么办?想训练它在市场中稳定盈利,或帮助一个候选人赢得选举,怎么办?这些任务当然也有结果——公司是否成功创办、官司是否获胜、交易是否盈利、选举是否胜出,最终都能判断。但它们的问题在于:反馈周期太长、变量过多、世界无法重置,也不可能在数据中心里复制一千次。一次创业可能持续数年,一次竞选依赖具体地区、候选人、选民情绪、媒体环境和偶然事件,一次法律案件也不可能从同一起点复制成一千个平行宇宙,让不同智能体分别试错。这类环境在强化学习里接近于“无重置、非平稳环境”——无法随意重置,而且环境本身还在不断变化。
因此,Dwarkesh 提出了一个非常尖锐的问题:在可验证、可反复练习的环境中训练出来的 RLVR 智能体,真的能泛化到这些真实世界任务吗?这不是一个靠口号就能回答的问题,而是需要实证检验的。乐观派会说,只要 RLVR 环境足够多、足够复杂,模型最终会学到通用的智能体能力——它在代码、数学、网页、工具使用中练出来的规划和试错能力,最终会迁移到创业、组织管理、法律、科研等领域。但 Dwarkesh 对此保持怀疑,因为真实世界中最有价值的知识,往往不是以清晰、可验证、可重复的方式出现的。它们可能来自一次含糊的客户反馈、一次失败的会议、一个组织内部的隐性流程、一种只有在真实任务中才会暴露的失败模式。模型要学会这些东西,不能仅仅依靠“刷题”,还需要具备真正的样本效率。
这就把讨论带到了全文最关键的节点:将学习重新写回权重(learning back to the weights)。
今天的大模型已经非常擅长上下文学习(in-context learning),可以在一个长上下文里阅读大量资料、理解项目背景、临时适应一个用户或组织的需求。但问题在于,这种学习大多停留在上下文窗口内,会话结束后,模型并不一定能真正“长记性”。Dwarkesh 认为,这是一种巨大的浪费。因为模型真正有价值的训练信号,恰恰是在部署之后才出现的。它被真实用户使用,进入真实组织,参与真实任务,暴露真实错误——它能观察到公司内部如何运转、人们实际拿它做什么、哪些地方经常失败、哪些建议在现实中根本行不通。但如果这些经验无法沉淀回模型权重,那就只是一次会话里的短暂适应,而不是能力的长期增长。
他用人类学习做了一个类比:人并不是靠把每天发生的所有事情都逐字背下来而变强的。一个员工工作半年后变得有用,不是因为他记得每封邮件、每句会议记录,而是因为他把这些经历压缩成了判断力、直觉、流程理解和问题模式。模型也应如此。真正的持续学习(continual learning),不是无限扩大 KV 缓存,也不是把所有历史记录塞进上下文,而是从真实经验中提炼出少量真正有用的知识,再把它们压缩进权重。
这正是 Dwarkesh 认为下一代训练范式必须解决的核心问题。
那么,具体应该怎么做?他提出了一个正在被讨论的方向:同策略自蒸馏(On-Policy Self-Distillation,简称 OPSD)。可以粗略理解为:让一个已经在长篇对话中积累了大量经验的模型,充当“老员工”或教师(teacher);然后训练基础模型,让它在没有这些完整上下文的情况下,也能做出类似教师的判断。也就是说,把模型在一次真实任务中通过上下文学习到的东西,再蒸馏回模型自身的权重。这和普通的监督微调(SFT)不同——最朴素的 SFT 可能只是让模型去预测会话里出现过的 Token,相当于让它复述整个工作日志,但这并非高效的学习。真正重要的不是记住全部细节,而是提炼出那些能帮助模型下次做得更好的关键洞见。OPSD 的优势在于,它不一定需要一个外部可验证的奖励,只要模型能在上下文里学到有用东西,就可以把“学习过后的模型”作为教师,让基础模型向它靠近。同时,相比普通强化学习只有最终的奖励信号,OPSD 可以提供更密集的监督信号——在 Token 层面比较教师和学生之间的概率分布差异,从而把一次真实任务中的稀缺经验压缩成更小、更精准的权重更新。
除了 OPSD,Dwarkesh 还提出了另一个方向:梦境模拟(dreaming)。这里的“梦境模拟”是指 AI 根据真实世界的观察,自己构造一个模拟环境,然后在其中反复练习、尝试策略、强化有效行为。这听起来很像强化学习传统中的基于模型的强化学习,也很像 Sutton 一直强调的智能体通过与环境互动积累经验。不同的是,Dwarkesh 将其置于大模型与真实部署的语境中。例如,一个 AI 在真实公司里观察到某个业务流程后,不光是写一份总结,而是花费大量计算,构造出这个流程的“游戏版模拟环境”。然后它在其中测试不同的沟通策略、执行路径和项目推进方式,观察什么更可能成功。最后,再把这些模拟练习中得到的经验压缩回模型。
如果这种路线成立,它可能会成为新的扩展维度。过去 AI 的扩展主要来自三条轴线:预训练(Pretraining)、强化学习(RL)和推理阶段计算(Inference-time Compute)。Dwarkesh 设想,未来可能还会多出第四条轴线:测试阶段训练(Test-time Training),或者说“梦境模拟”。模型不只是进行推理,而是在推理和任务执行过程中,为特定用户、特定组织、特定项目构造模拟环境,并在其中训练自己。这也是为什么评论区有人提到 David Silver 和 Richard Sutton 的《Welcome to the Era of Experience》,那篇文章同样强调,AI 不能永远依赖人类数据,下一阶段的关键将是智能体从自身与环境的互动中获得经验。

Dwarkesh 则将这个宏观判断具体化到了今天的大模型训练问题上。在他看来,RLVR 是一个重要的过渡阶段——它让模型在可验证任务中练就了智能体能力;但要进入更复杂的现实世界,模型必须学会从真实部署中持续学习,并把经验写回权重。在 Dwarkesh 设想的 2027 或 2028 年,训练流程可能会变成这样:首先,RLVR 训练出一个具备基本能力的智能体——这个智能体被扔到一个陌生问题里,至少能搞清楚情况、尝试不同策略、遇到障碍后继续迭代;然后,这个智能体被部署到真实世界中,开始做真实工作——它可能和用户一起连续工作一周,参与一个不在原始训练分布里的项目;一周结束后,用户给它一个赞或踩的评价,甚至写一段工作反馈。如果结果是正向的,模型就会把这次任务中学到的东西蒸馏回基础模型,这个过程可能用到 OPSD,也可能用到“梦境模拟”,或者某种目前尚未出现的新技术。
一旦这条路径跑通,AI 的能力边界就不再被最初那些“可验证任务”所限制。它可以先通过 RLVR 学会代码、数学、网页任务、工具调用;再通过真实部署学习组织管理、业务流程、复杂协作;然后从这些经验出发,继续扩展到相邻领域。这也意味着,AI 进步的主要来源可能会发生变化。过去,一个模型在发布前就训练完毕,用户只是单纯使用它。下一代模型可能是:发布前先训练出基础智能体,发布后通过海量真实任务继续学习。每一次与用户的交互,每一次真实项目的执行,每一次失败与修正,都可能成为下一轮能力提升的宝贵素材。
所以,Dwarkesh 所提出的“下一代训练范式”,并非简单地意味着模型要更大、数据要更多、RL 要更强。它真正指向的是:AI 从发布前训练,走向发布后学习;从依赖人类数据,走向汲取环境经验;从上下文里的临时适应,走向权重里的长期能力塑造。未来最重要的 AI 训练数据,可能不再仅仅是互联网上已有的文本,也不仅仅是实验室里构造好的可验证任务,而是 AI 在真实世界里完成真实任务时,自己积累出来的宝贵经验。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Dwarkesh Patel谈下一代AI源自实践应用要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点一加Turbo6X开售,含标准版与Pro版,起售价1499元,国补价1274 15元。搭载天玑7360SUPER和7400SUPER,144Hz屏,7000 8000mAh电池,主打长续航高性价比。
蔚来汽车近日上市了2026款ET5、ET5T和EC6的冠军纪念版车型。新车主打赛道竞速设计风格,提供专属外观内饰与智能座舱主题。最大的亮点在于推出了BaaS电池租用方案,ET5 ET5T租电版起售价20 5万元,EC6租电版起售价26 5万元,大幅降低了购车门槛。车辆在底盘方面进行了针对性调校,提升
微软射击游戏《战争机器:E-Day》公布PC配置要求,将于2026年10月发售。配置清单引人注目地将尚未发布的RTX5050和RX9060显卡列为最低要求,同时兼容多款现有中端显卡。游戏需130GB固态硬盘空间,最低要求12GB内存和六核CPU。官方未明确对应画质与帧数,但推测将依赖超分辨率技术
软科近日发布2026年中国大学专业排名,覆盖1132所高校的3万余个专业点。排名显示,北京大学以93个A+专业位居榜首,清华大学和哈尔滨工业大学分列二、三位。榜单同时引入“A+专业精度”指标,中国人民公安大学以93 8%的精度领先。此外,北京大学、吉林大学、武汉大学在上榜专业总数上位列前三。该排名从
- 日榜
- 周榜
- 月榜
热点快看