




最新开源Claude时刻到来,智谱GLM5.2大模型与Mythos同台对比

近日,智谱开源模型GLM-5 2在安全漏洞检测领域表现突出,裸跑IDOR漏洞检测F1达39%,超越了ClaudeCode;在追加指令后追平ClaudeMythos。平均每发现一个安全漏洞成本仅0 17美元。目前国产模型与美国顶级模型性能差距已收窄至2 7个百分点。
本周末,智谱公司发布的最新开源模型 GLM-5.2 在网络安全领域引起了全球范围内的广泛关注。多家国际媒体跟进报道,《华尔街日报》更直言「中国重置了AI竞赛」。代码安全公司 Semgrep 的评估测试显示,GLM-5.2 在寻找安全漏洞这一关键任务上的表现,已经与 Anthropic 的 Claude Mythos 不相上下。接下来,我们将为您详细解读这一事件的核心要点、技术细节以及背后的行业趋势。
一、GLM-5.2 在安全漏洞检测中的惊人表现
Semgrep 的测试初衷并非评选最强开源模型,而是想探究:AI 查找漏洞的成绩中,模型本身的能力与外部脚手架(如 SDK、工具链)的贡献各占多少?这一结果让整个团队感到非常意外。
1. 裸跑测试:碾压其他模型与闭源产品
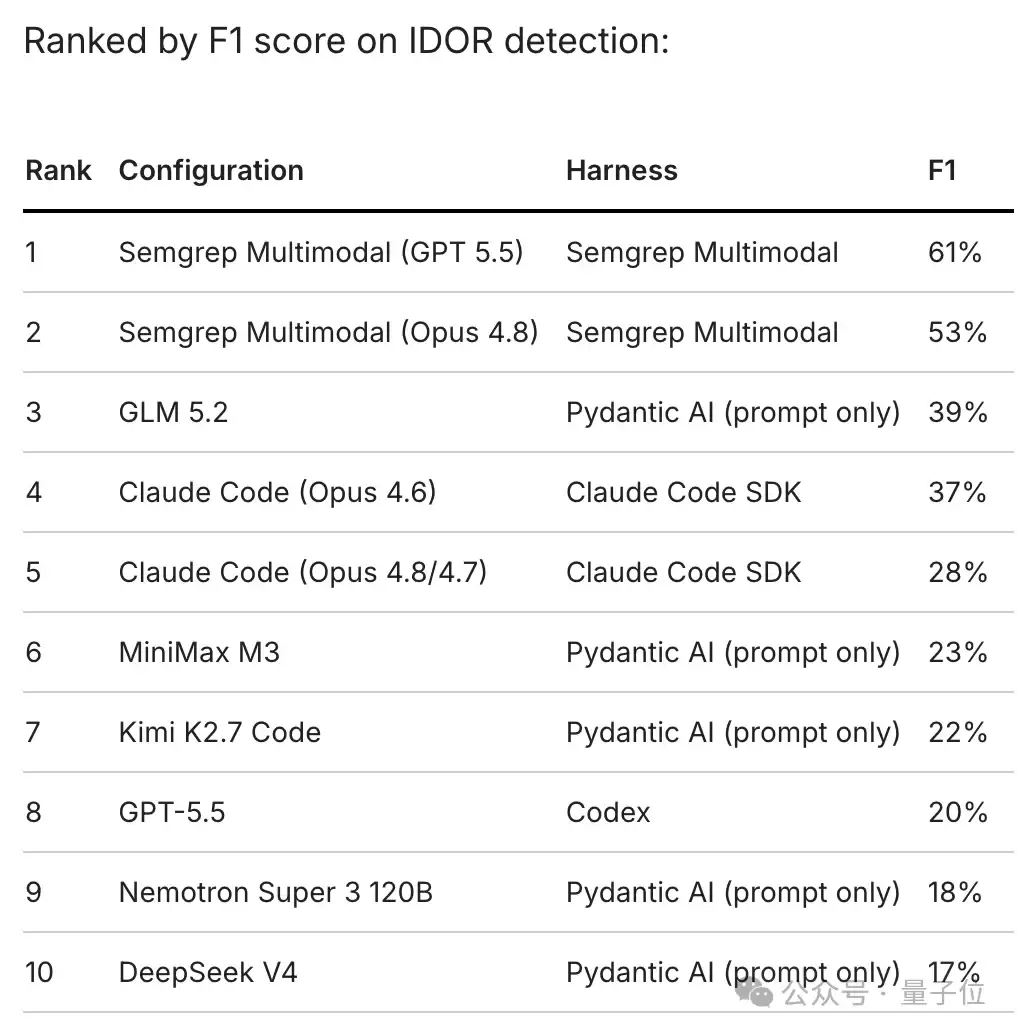
GLM-5.2 在没有任何额外指令或工具辅助的情况下,仅凭一个提示词(prompt)和一堆代码进行「裸跑」,在 IDOR(不安全的直接对象引用)漏洞检测 上取得了 39% 的 F1 分数。这一成绩不仅远超其他同样裸跑的开源模型,甚至 击败了搭载完整 SDK 支持、使用 Opus 4.8 的 Claude Code(后者仅 32%)。

2. 什么是 IDOR 漏洞?为何它如此难检测?
IDOR 的全称是 Insecure Direct Object Reference,简单来说就是:系统暴露了内部的用户 ID 或数据库键值,却没有验证请求方是否拥有访问权限。 只需修改一下 ID,就能获取他人的数据。这类漏洞在安全领域以难以检测而著称——它并非普通的危险函数调用,而是考验模型能否发现一个「本应存在但缺失的校验机制」。目前,IDOR 在 HackerOne 漏洞类型排行榜上位列第四,是实战中最常被利用的漏洞之一。
3. 追加指令后追平 Mythos
根据《华尔街日报》的报道,GLM-5.2 在加入额外指令后,漏洞查找能力可以进一步追平 Mythos。这意味着,开源模型在最重要的安全维度上,首次与闭源顶级模型站在了同一水平线上。

4. 性价比:一个漏洞仅需 0.17 美元
GLM-5.2 在价格上极具竞争力:输出 token 价格仅为 Claude Opus 4.8 的五分之一、GPT-5.5 的七分之一。每发现一个漏洞的计算成本仅为 0.17 美元。在 Kilo Code 中运行规划任务时,GLM-5.2 获得了 9.0 分,而 Fable 5 为 9.1 分,两者几乎持平。
小提示: 如果在实际网络安全工作中部署 AI 漏洞扫描,建议优先测试 GLM-5.2 的裸跑效果,再根据预算决定是否加入定制指令——性价比优势非常明显。
5. 孤独的领跑者:与第二名差距显著
值得特别注意的是,GLM-5.2 与排名第二的开源模型之间的差距,比它和 Claude Code 之间的差距还要大 16 个百分点。这并非意味着开源模型集体追上了闭源,而是智谱独自跨越了那道门槛。
二、国产模型正在崛起:不止是智谱
7AI 的 CEO Lior Div 评价道:中国在持续缩小与美国的差距,而且这一趋势不会停止。Stanford 2026 AI Index 数据显示:美国和中国最强模型之间的综合能力差距已收窄到 2.7 个百分点。
1. 智谱的持续加速:4 个月 4 个前沿模型
智谱在过去四个月里发布了四个前沿级的 coding 模型:GLM-5、5-Turbo、5.1、5.2。这一发布节奏不输任何顶级实验室。智谱创始人唐杰在 Mythos Preview 发布后曾表示:AI 查找漏洞学习的不仅仅是搜索,而是顶级黑客的直觉和方法论,并且能够 24 小时不间断运行。他判断,这本质上是一场替代黑客的革命。
2. 360 等厂商的跟进
就在 GLM-5.2 引发热议的同一周,另一家中国安全公司 360 也宣布推出自己的漏洞检测工具,同样声称能够比肩 Mythos。国产模型在网络安全这一战略维度上,正逐步形成集团优势。
常见问题
Q:GLM-5.2 是否已经全面超越 Claude Mythos?
A:并非如此。在 IDOR 漏洞检测这一特定任务上,GLM-5.2 在裸跑和相关指令加持下追平甚至局部超越了 Mythos,但在其他安全任务(如复杂逻辑漏洞、0day 发现层级)的对比数据尚未公开。Mythos 在 OpenBSD 中发现 27 年旧漏洞等成就,仍然代表了最高水平。GLM-5.2 的意义在于证明了开源模型在关键安全任务上已经具备竞争力。
Q:企业应该如何评估是否使用 GLM-5.2?
A:建议从三个维度进行评估:①任务类型(IDOR 类漏洞优先推荐);②成本预算(成本仅为闭源方案的 1/5~1/7);③安全合规(开源模型可本地部署,避免数据外泄风险)。可以先利用 Semgrep 等工具搭建裸跑测试环境来验证效果。
三、安全维度为何战略意义重大?
Mythos 曾花费两天时间、约 2 万美元的算力,挖出一个隐藏在 OpenBSD 里长达 27 年、从未被人发现的漏洞。Anthropic 研究员 Nicholas Carlini 使用一套后来被称为「Carlini Loop」的提示词驱动 Mythos 扫描代码,翻出了数百个 bug,其中 Ghost 平台的一个漏洞在几周后就被黑客在野外利用了。这套能力既能防守也能进攻,已经被现实所验证。
1. 安全圈的现实:bugmageddon 降临
安全圈有一个术语叫 bugmageddon:AI 发现漏洞的速度,已经超过了人类打补丁的速度。八年前,一个漏洞从被发现到被利用平均需要 847 天;现在这个窗口期已缩短到 一天以内。
2. 市场天平正在倾斜
曾领导 Google 安全团队的 Niels Provos 判断:这种局面正把全球用户推向更便宜但同样强大的中国开源模型。差距在缩小,使用天平也在同步倾斜——本质上是市场在用实际行动,对国产模型的 AI Coding 能力投下赞成票。
3. 马斯克与唐杰的隔空对话
六月中旬,马斯克在 X 上表示,智谱最快到明年初就能在 benchmark 上追上美国顶尖模型。当时智谱创始人唐杰回了一句:「不用那么久」。现在看来,至少在查找安全漏洞这件事上,他说对了。
参考链接:
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:最新开源Claude时刻到来,智谱GLM5.2大模型与Mythos同台对比要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在 Degiro 上进行投资的用户,常常会遇到一个共同的痛点:平台自带的数据展示较为基础,若想获取更深入的投资组合分析、风险指标,甚至对未来走势做出预测,通常只能借助 Excel 手动处理。不过,现在有一款 Chrome 扩展程序可以完美解决这一难题——Mercury,专为 Degiro 用户量身打
在投资决策过程中,客观数据往往比主观直觉更值得信赖。名为Lorna的智能平台,运用独特的现金流分析体系,帮助投资者穿透虚饰的财务报表,直达企业真实的财务健康状况。 什么是Lorna?——数据驱动的现金流分析投资工具 简而言之,Lorna是一个以数据为核心驱动力的投资分析工具。其核心利器是独创的“现金
Front Street自动追踪你的每一笔消费,整合各类忠诚度计划,并提供财务洞察与省钱妙招——说白了,就是帮你把钱&包管得明明白白。 什么是Front Street? 简单讲,Front Street就是你的购物管家。它自动记录你在每个品牌、每家店的所有购买行为,然后把零散的忠诚度计划全部整合到一
在创投圈深耕多年,你会发现一个普遍难题:融资过程中,投资者关系维护、尽职调查、潜在投资人挖掘……这些环节往往耗费巨大精力,却又直接决定成败。如果能有一款工具将这些琐事自动化,让团队聚焦于真正重要的沟通与战略决策,那该多理想?Finta 正是为此而生。 什么是Finta? Finta 本质上是一款 A
- 日榜
- 周榜
- 月榜
热点快看