




微调与RAG对比:大模型意图识别工程化实践

针对智能电视意图识别场景,传统NLP在复杂语境、多轮对话和泛化推理方面存在不足。采用7B小尺寸模型进行LoRA微调,结合自动质检与自动微调工程链路,实现平均延迟500ms、实时准确率98%以上的落地效果,有效支撑“可见即可说”交互体验。
今年,智能电视行业正式迈入AI技术应用的关键元年,各品牌纷纷探索如何将大模型能力切实融入电视操作系统。某国产品牌提出的“可见即可说”理念,核心目标是借助大模型在自然语言处理与逻辑推理方面的突破,彻底重塑电视端的交互体验。用户不再局限于下达简单的系统指令,而是能够提出个性化、模糊甚至略带“刁钻”的问题——例如“帮我播放两个男人在天台决斗的电影”,或者“我想听一个小朋友不好好吃饭就会肚子疼的故事”。
这一切都指向同一个核心难题:意图识别。只有精准理解用户的需求,后续所有服务才能真正高效运转。
业务背景
尽管智能电视的概念早在十多年前就已提出,并逐步具备基础的人机交互能力,但在传统NLP技术框架下,始终存在几个“老大难”问题:复杂语境中的意图识别、上下文理解与多轮对话、泛化推理能力。
举例来说,当用户说“想看两个男人在天台决斗的电影”,传统NLP几乎无法识别出用户实际想观看的是《无间道》。而大模型凭借强大的泛化推理能力,能够很好地理解这类隐喻式表达。
传统NLP算法在意图识别场景的不足
语言理解能力
传统NLP算法高度依赖基于规则的方法,例如早期的专家系统依靠人工编写大量规则来解析语义。然而自然语言极其灵活,这些规则根本无法穷举。像依存句法分析,在简单句中尚能识别词语间的语法关系,一旦遇到复杂长句,准确率便急剧下降。
上下文感知能力同样是明显的短板。隐马尔可夫模型等算法在处理文本时,主要集中在局部状态转移概率,对长序列的上下文整合能力较弱。而大模型所采用的Transformer架构,能够同时关注输入文本不同位置的信息,在多轮交互场景下表现显著更优。
交互体验方面
多轮对话一直是老问题。传统对话管理系统常使用有限状态机构建,依靠预设的状态转移规则驱动流程。在电视的多轮对话场景下,这种做法的局限性非常突出——一旦稍微偏离预设路径,对话就会“卡住”。
灵活性与泛化能力也远远不够。用户搜索词稍有变化,例如从“科幻电影”改为“带有科幻元素的冒险电影”,基于布尔逻辑的检索系统可能无法精准匹配。大模型则不同,凭借海量数据训练出的泛化能力,能够适应各种不同表述。
知识更新和拓展方面
传统的影视知识问答库完全依赖人工录入更新。新片上映、影视潮流变化后,知识库的更新明显滞后。大模型可以通过持续从互联网抓取最新资讯,自动学习新知识,保持前沿性。
知识拓展能力也非常有限。传统模型如专门用于电影推荐的协同过滤算法,一旦需要拓展到跨领域的影视知识科普,就必须重新设计和训练。大模型基于通用性,能够从影视娱乐知识自然拓展到文化历史、科技特效等领域,满足用户更多元的需求。
因此,在整个链路中,首先要解决的就是意图识别问题。下面重点介绍我们运用大模型对传统NLP能力进行全面升级的落地过程与思考。
意图识别场景解析
意图识别概念介绍
意图识别,简单来说就是一种让机器理解用户“到底想干什么”的技术。在问答机器人、智能客服、虚拟助手等场景中被广泛使用。其核心是分析用户的文本或语音输入,识别出用户询问、请求或指令背后的真实目的。
例如在智能客服场景中,用户的话可能很模糊、复杂,其中夹杂着咨询、抱怨、建议等多种潜在意图。大模型通过意图识别,剖析语句的语言模式、关键词以及语义关联,准确判断用户是想咨询产品功能,还是对服务质量不满,进而给出针对性回复。
在大模型的应用体系中,意图识别就像桥梁,连接着用户模糊或明确的表达与大模型后续要执行的具体任务。只有这一步走准了,后续动作才可能有效。
意图改写:在不改变用户原始意图的前提下,对表达意图的文本进行重新表述。例如“明天的天气”可以改写成“帮我查一下明天的天气状况”,从而提高大模型输出的准确率。
意图分类:通过为不同意图分配特定标签,方便大模型快速分类和处理。比如将意图分为“查询类”、“预订类”、“咨询类”等大类别,下面再细分“查询天气”、“查询航班”等具体标签。
意图槽位:这就像是捕捉用户需求的“小格子”。在预订机票场景中,出发地、目的地、出发时间、舱位等级都是不同的意图槽位。大模型分析用户语句后,将信息填充到相应槽位,从而理解用户的真实需求。
意图置信度:模型在预测用户意图时的自信程度,通常用概率值表示。概率越高,模型对预测结果越有把握。
意图识别在智能电视中的落地挑战
由于意图识别处于电视C端业务的核心交互链路上,要求极高。主要挑战来自三个方面:
延迟要求:全链路较长,用户对延迟容忍度很低。意图识别模型必须在500ms-800ms内返回全部结果,后续链路才能继续处理业务。
准确性要求:C端用户对体验效果非常敏感,一个不准确的意图会导致全链路功能失效。因此准确性要求极高:简单指令100%准确率,复杂指令98%+准确率。
实时数据处理能力:电视场景需要涉及最新的媒资信息或互联网上新出现的“梗”,例如“老默吃鱼”。单纯依靠基模能力无法有效理解,必须把新的知识内容注入给模型。
几种落地方案选型
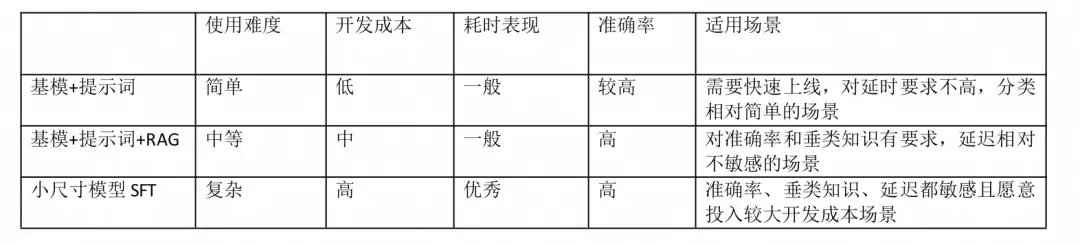
方案一:基模 + Prompt
方案特点:开发成本低,适用于需要快速上线、对延时要求不高、分类相对简单的场景。
模型选择:主要依赖基模的推理能力,建议至少使用32b以上的模型,例如qwen-plus、qwen-max。
方案说明:Prompt的写法有很多技巧,常用的包括:
CoT思维链:引导模型逐步构建逻辑链,一步一步思考后完成分类任务。
Few-Shot少样本学习:通过在prompt中引入少量示例,有效提高大模型在意图识别分类任务中的能力。
特定准则重点说明:让模型在识别前重点学习并记住预设的识别准则。
输出示例:要求以JSON格式进行输出。
方案缺点:对垂类领域的分类识别有一定局限性,而且由于需要一定的推理能力,选用大尺寸模型会带来延迟开销。
综合来看,基模+提示词的方案更适合业务相对简单、对延迟不敏感的场景。我们最终放弃了这一方案。
方案二:基模 + Prompt + RAG
RAG介绍:检索增强生成,即在LLM回答问题之前先从外部知识库中检索相关信息,将模型的参数化知识和非参数化的外部知识库结合起来。早期神经网络模型在处理需要依赖外部知识的任务时会遇到瓶颈,LLM的问题主要在于幻觉、依赖过时信息、缺乏专业领域知识。RAG正是为解决这些问题而提出。
方案特点:鉴于方案一中垂类知识不足的问题,通过加入RAG能力,在知识库中上传大量意图分类知识,让模型能够理解更垂类或更个性化的分类判定逻辑。
模型选择:引入RAG能力后,对模型推理要求降低,建议选性价比较高的模型,如qwen-turbo、qwen-plus。
方案说明:主要步骤包括意图语料结构设计、数据生成、知识上传和向量化。数据生成时,可用LLM生成同义句,再用大尺寸模型结合在线搜索能力生成相关意图分类和槽位。
方案缺点:需要做数据预处理,开发成本较高;知识库内容过多或质量不佳时,可能引发模型幻觉和分类冲突;相比方案一,会增加向量召回部分的延迟,模型要求依然在14b以上,延迟问题仍存在。
因此方案二也不太适用于电视C端交互链路。不过,方案二关于数据增强的思路值得借鉴——基于这一思路,我们可以尝试用小尺寸模型做SFT。
方案三:使用小尺寸模型进行SFT
方案特点:用小尺寸模型解决延迟问题,用微调解决数据增强问题。
模型选择:一般而言,模型底座越大,下游任务效果越好,但部署成本和推理代价也相应增大。针对意图识别场景,建议从4B左右的底座开始SFT和调参。效果提升遇到瓶颈时,换成7B的更大底座。超过10B的底座理论上能获得更好结果,但需权衡效果和成本。本场景使用7B底座,性价比较高。
微调方案:选用LoRA方式。核心思路是在固定主预训练参数的情况下,用支路去学习特定任务知识。在每层transformer block旁边引入一个并行低秩的支路,将支路输出和原始block输出相加,训练完成后把原始权重加上LoRA训练的权重,模型结构不变。
方案说明:SFT的大致流程包括意图语料结构设计、样本生成、模型训练参数设置、启动训练任务、模型离线评测、模型部署和Prompt设计。样本生成方面,可使用PAI-iTag工具进行标注,然后转换为训练数据格式。训练参数方面,使用LoRA算法,全局批次大小在GPU显存允许的情况下尽可能调大,序列长度选择64/128/256比较合适。学习率可偏大设置,如1e-4左右,不建议使用1e-3这一量级。
几种方案的对比
新的问题:准确率、时效性、成本
在实际的生成链路上,我们发现要同时保证准确率、时效性和成本,还存在一些绕不过去的难题:
1.如何确保生产准确率持续符合要求?互联网信息迭代迅速,尤其是娱乐性质较重的媒资类产品,几乎每天都会产生新的电视/电影/音乐等信息。用户个性化的问法层出不穷,持续保持98%以上的准确率是个巨大挑战。
2.如何在生产环境上对结果纠错?电视场景以语音交互为主,用户如果不满意,很难像手机或PC上那样通过“点踩”来反馈。出现事实性错误时,往往只能靠用户投诉来获知,这会极大损害用户体验。
3.海量C端用户的指令无法穷举,大量训练集如何产生?微调能解决垂直业务数据问题,但前期准备的训练数据只能解决一小部分问题。实际生产中的微调需要不断迭代,数据源从何而来是关键。
4.训练集不断增大,反复SFT耗时耗力,有没有自动化的方案?如果每天都需要人工进行模型训练和部署,人力成本会非常高昂。
进阶方案:自动质检和自动微调工程链路
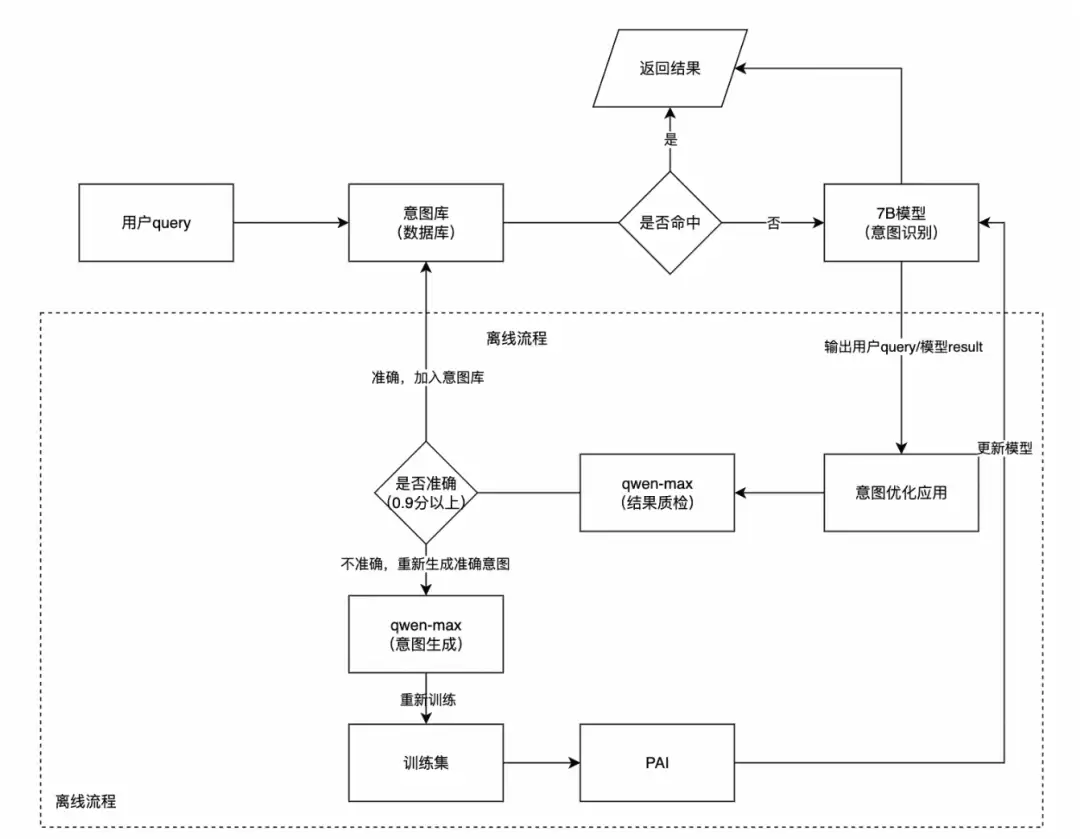
该方案通过多步骤处理流程,实现了线上意图的自动质检和模型的自动重新训练。整体分为在线流程和离线流程两部分:
在线流程:用户的query先经过意图缓存库,该库以query为key,将曾经正确返回的意图结果存储在ES中。命中缓存时直接返回结果,提高响应速度并保证准确性。缓存主要针对简单指令,如系统指令、媒资名搜索。如果缓存未命中,则进入模型推理链路,当前使用的是微调后的qwen-7b模型。
离线流程:大模型输出意图推理结果后,会异步将query+response传给意图优化应用,作为质检入口。调用大尺寸模型(如qwen-max)对结果进行质检,输出评分,满分为1分,只有0.9分以上的才算正确。如果意图准确,则将结果写回缓存。如果低于0.9分,则尝试用大尺寸模型重新生成意图,并引入LLM实时搜索能力,确保对新query的理解。重新生成的答案通过质检后,会被更新到训练集中,用于下一次SFT。
落地效果
在某国产头部电视厂家落地过程中,经过多轮技术选型,最终使用PAI平台进行qwen-7b模型的训练和推理部署。该方案在准确率和延迟上均有较大优势,平均延迟500ms,生产实时准确率达到98%+。
结尾
随着电视技术的迅猛发展和用户交互模式的日益多样化,意图识别技术在增强用户体验中发挥着不可或缺的作用。大模型技术仍在高速迭代演进,通过持续优化与升级现有模型结构,并融入多维度的数据源——比如语音情感分析、视觉内容感知等——未来的电视设备不仅能够准确理解用户指令,甚至能预判需求,提供超越预期的个性化服务。这种进步将重新定义观众与电视之间的互动方式,开启智能家居娱乐的新纪元。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:微调与RAG对比:大模型意图识别工程化实践要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看