探索未来知识图谱技术的新突破:无需向量数据库,实现大语言模型的长期记忆 先说一个值得思考的问题:在为大语言模型(LLM)提供长期记忆这件事上,目前的主流路线是检索增强生成(RAG),而RAG的标配通常是向量数据库。那么,有没有一种可能——不用向量数据库,也一样能把这事儿办了? 这篇论文([R
### 探索未来知识图谱技术的新突破:无需向量数据库,实现大语言模型的长期记忆
先说一个值得思考的问题:在为大语言模型(LLM)提供长期记忆这件事上,目前的主流路线是检索增强生成(RAG),而RAG的标配通常是向量数据库。那么,有没有一种可能——不用向量数据库,也一样能把这事儿办了?
这篇论文([RecallM: 一种具有时间理解能力的可适应记忆机制](https://arxiv.org/abs/2307.02738)),由 Brandon Kynoch、Hugo Latapie 和 Dwane van der Sluis 共同提出,给出了一种新思路:用自动构建的知识图谱作为 LLM 长期记忆的核心。
说得直白一点,就是让 LLM 自己“建图”并“用图”来记住东西。本文将深入拆解 RecallM 的工作原理——它的知识图谱是怎么更新的,推理机制又是怎么运作的,并通过几个具体例子来把整个过程讲清楚。
我们会先看知识图谱的更新机制,分两轮示例来一步步说明。然后,探究 RecallM 的推理机制,看它如何利用图谱来回答问题。期间还会拎出时间推理的例子,展示系统对时间相关信息的理解能力。最后,我们也要坦诚地聊聊它的局限性——毕竟,没有完美的方案。
## 知识图谱更新
### 第一轮:添加新事实
假设我们要把一个句子塞进知识图谱:
> Brandon 喜欢咖啡
这事儿分几步走。
**首先,识别概念。** 概念基本就是句子里的名词,它们会成为知识图谱里的节点。为了避免重复,概念会被统一转成小写,再用词干提取技术做归一化。这些操作可以借助 NLP 工具包 Stanza 来完成。
Stanza 对“Brandon loves coffee”的分析结果长这样:
```json
[
[
{
"id": 1,
"text": "Brandon",
"lemma": "Brandon",
"upos": "PROPN",
"xpos": "NNP",
"feats": "Number=Sing",
"head": 2,
"deprel": "nsubj",
"start_char": 0,
"end_char": 7,
"ner": "S-PERSON",
"multi_ner": [
"S-PERSON"
]
},
{
"id": 2,
"text": "loves",
"lemma": "love",
"upos": "VERB",
"xpos": "VBZ",
"feats": "Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"head": 0,
"deprel": "root",
"start_char": 8,
"end_char": 13,
"ner": "O",
"multi_ner": [
"O"
]
},
{
"id": 3,
"text": "coffee",
"lemma": "coffee",
"upos": "NOUN",
"xpos": "NN",
"feats": "Number=Sing",
"head": 2,
"deprel": "obj",
"start_char": 14,
"end_char": 20,
"ner": "O",
"multi_ner": [
"O"
],
"misc": "SpaceAfter=No"
}
]
]
```
在这个例子里,名词就是“Brandon”和“coffee”。经过 Porter 词干提取并转小写后,我们得到“brandon”和“coffe”。
**第二步,查找每个概念的邻居。** 概念的邻居就是那些和它有关系、在句中其他位置的概念。可以用依存句法分析来判断关系,但为了简化,直接根据概念在句子中的位置“距离”来定。所谓“距离”,就是指概念在句中间出现的先后顺序。比如,“brandon”在索引0,“coffe”在索引1。
下面这个代码片段能帮你理解“距离”是怎么算的:
```python
# 默认距离设为 1
def fetch_neigbouring_concepts(concepts, distance=1):
concepts = sorted(concepts)
for i in range(len(concepts)):
concepts[i].related_concepts = []
for j in range(-distance, distance + 1, 1): # 如果当前概念的距离小于参数 distance
if 0 <= i + j < len(concepts): # 确保索引在范围内
if j == 0:
continue
if concepts[i].name < concepts[i + j].name: # 确保在 Neo4J 图数据库中仅创建一个连接
concepts[i].related_concepts.append(concepts[i + j])
```
这一步走完,“brandon”就和“coffe”建立了关系,而“coffe”那边是不会反过来再连一次“brandon”的。
**第三步,创建概念节点及其关系。** 用图数据库(比如Neo4J)来存这些东西。最后图谱长这个样子:
红色节点就是概念,通过白色的“RELATED”关系连在一起。蓝色节点是“全局时间步”,在时间推理中很关键。这里它的值是1,表示这是第一次更新图谱。
创建这张图的 Cypher 查询如下:
```cypher
MERGE (c00:Concept {name: 'brandon'})
MERGE (c01:Concept {name: 'coffe'})
WITH c00, c01
MERGE (c00)-[rc00c01:RELATED]->(c01)
WITH c00, c01, rc00c01, COALESCE(rc00c01.strength, 0) + 1 AS rc00c01ic
SET c00.t_index = 1, c01.t_index = 1
SET rc00c01.strength = rc00c01ic
SET rc00c01.t_index = 1
```
有两点值得注意:
1. 节点和关系都有一个 `t_index` 属性,用来记录它们上次更新的时间步。
2. “RELATED”关系还有一个 `strength` 属性,用于追踪这个关系在更新过程中被提及的次数。
**第四步,添加概念的上下文。** 上下文就是概念在句子里的用法。每个概念,我们都要先从图谱里取出它的上下文信息:
```cypher
MATCH (n:Concept)
WHERE n.name IN ['brandon', 'coffe']
RETURN n.name, n.context, n.revision_count
```
由于是第一次添加,查询结果自然是空。然后,我们把当前的句子“Brandon loves coffee”作为上下文塞给概念节点,并更新图谱:
```cypher
MATCH (n:Concept)
WHERE n.name IN ['brandon', 'coffe']
WITH n,
CASE n.name
WHEN 'brandon' THEN '. Brandon loves coffee'
WHEN 'coffe' THEN '. Brandon loves coffee'
ELSE n.context
END AS newContext,
CASE n.name
WHEN 'brandon' THEN 0
WHEN 'coffe' THEN 0
ELSE 0
END AS revisionCount
SET n.context = newContext
SET n.revision_count = revisionCount
```
注意,“brandon”和“coffe”的上下文是一样的,因为它们出现在同一个句子里——目前我们只处理了这一句。
最终图谱如下:
### 第二轮:扩展事实
现在,再往图谱里加一个新句子:
> Brandon 想去巴黎旅行
这句里的概念是“Brandon”和“Paris”。词干化并转小写后,得到“brandon”和“pari”。
把它们加到图谱后,结构会变成这样:
有几个变化值得留意:
* 全局时间步已经更新成了2。
* 新节点“pari”被加了进来。
* “brandon”和“pari”通过“RELATED”关系相连。
* “brandon”的 `t_index` 更新成了2,因为它在时间步2被更新了。
更新图谱的 Cypher 查询如下:
```cypher
MERGE (c00:Concept {name: 'brandon'})
MERGE (c01:Concept {name: 'pari'})
WITH c00, c01
MERGE (c00)-[rc00c01:RELATED]->(c01)
WITH c00, c01, rc00c01, COALESCE(rc00c01.strength, 0) + 1 AS rc00c01ic
SET c00.t_index = 2, c01.t_index = 2
SET rc00c01.strength = rc00c01ic
SET rc00c01.t_index = 2
```
**然后是更新概念的上下文。** 先查出当前上下文:
```json
{
"brandon": {
"context": ". Brandon loves coffee",
"revision_count": 0
},
"pari": {
"context": null,
"revision_count": null
}
}
```
可以看到,“brandon”已经有上下文了,“pari”还没有。接下来,把新句子追加到已有上下文中,再更新图谱:
```cypher
MATCH (n:Concept)
WHERE n.name IN ['brandon', 'pari']
WITH n,
CASE n.name
WHEN 'brandon' THEN '. Brandon loves coffee. Brandon wants to tra vel to Paris'
WHEN 'pari' THEN '. Brandon wants to tra vel to Paris'
ELSE n.context
END AS newContext,
CASE n.name
WHEN 'brandon' THEN 1
WHEN 'pari' THEN 0
ELSE 0
END AS revisionCount
SET n.context = newContext
SET n.revision_count = revisionCount
```
“brandon”的上下文现在包含了原句子和新句子,它的 `revision_count` 也变成了1,因为上下文被更新了。
最终的图谱:
## 推理机制
假设我们要回答一个问题:
> 谁想去巴黎旅行?
可以通过知识图谱来生成答案。
**第一步,识别概念。** 用和更新图谱时一样的 NLP 流程,发现问题里唯一的概念是“pari”。
**第二步,查找相关概念。** 在图谱里找出所有和“pari”有关联的概念:
```cypher
MATCH (startNode:Concept{name: 'pari'})
CALL apoc.path.spanningTree(startNode, {relationshipFilter: "", minLevel: 0, maxLevel: 2}) YIELD path
WITH path, nodes(path) as pathNodes, startNode.t_index as current_t
UNWIND range(0, size(pathNodes)-1) AS index
WITH path, pathNodes[index] as node, current_t
ORDER BY node.t_index DESC
WHERE node.t_index <= current_t AND node.t_index >= current_t - 15
WITH DISTINCT node LIMIT 800
MATCH ()-[relation]->()
RETURN node, relation
```
这个查询会找到从“pari”出发、深度不超过2的所有路径,并筛选出时间步在 `current_t - 15` 到 `current_t` 之间的概念。查询结果为:
```json
{
"pari": ". Brandon wants to tra vel to Paris",
"brandon": ". Brandon loves coffee. Brandon wants to tra vel to Paris",
"coffe": ". Brandon loves coffee"
}
```
**第三步,对相关概念排序。** 根据时间步和关系强度来排。下面的代码片段展示了如何计算排序分值 `sort_val`:
```python
graph_concepts = graph_concept_nodes.values()
for concept in graph_concepts:
concept.sort_val = 0
for relation in concept.related_concepts:
concept.sort_val += (relation.t_index * 3) + relation.strength # 3 是一个超参数,可调整
graph_concepts = sorted(graph_concepts, key=lambda c: c.sort_val, reverse=True) # 按降序排列
```
排序后,各概念的 `sort_val` 如下:
**第四步,构建上下文。** 先抓取问题涉及的核心概念——也就是“pari”。它的上下文是:
```
. Brandon wants to tra vel to Paris
```
然后,按 `sort_val` 降序,依次添加相关概念的上下文:
```
. Brandon loves coffee # 相关概念:coffe
. Brandon loves coffee. Brandon wants to tra vel to Paris # 相关概念:brandon
. Brandon wants to tra vel to Paris # 核心概念:pari
```
**第五步,生成回答。** 把建好的上下文作为提示词交给 LLM 来生成答案。最终提示词长这样:
```
使用以下陈述(statements)来回答问题(question)。这些陈述按照时间顺序排列,每句陈述在其时间步内均为真实:
statements:
. Brandon loves coffee
. Brandon loves coffee. Brandon wants to tra vel to Paris
. Brandon wants to tra vel to Paris
question:
谁想去巴黎旅行?
Answer:
```
因为提示词已经包含了完整信息,GPT-3.5-Turbo 可以正确回答:“Brandon”。
## 时间推理
论文作者设计了一个实验,专门测试 RecallM 在时间理解和记忆更新方面的表现。
他们构建了一个按时间顺序排列的陈述数据集,每个新陈述都会更新之前的事实。然后,在不同时间步提问,考察系统的时间推理能力。实验包括两类问题:
1. **标准时间推理问题**:测试系统对时间概念的理解,以及能否正确更新记忆。
2. **长距离时间推理问题**:要求系统回忆数百个时间步之前的信息并做推理。例如,经过25轮更新后,系统需要回忆起1500多个更新之前的知识。
下面是一些实验结果,展示了 RecallM 在时间推理上的效果,以及与向量数据库的对比:
## 局限性
这个方法最主要的局限在于知识图谱的构建——**缺乏指代消解**。
举例来说,假设我们输入以下文本:
> Brandon 喜欢咖啡。他想去巴黎旅行。他喜欢猫。
理想的知识图谱应该是这样:
但实际得到的却是:
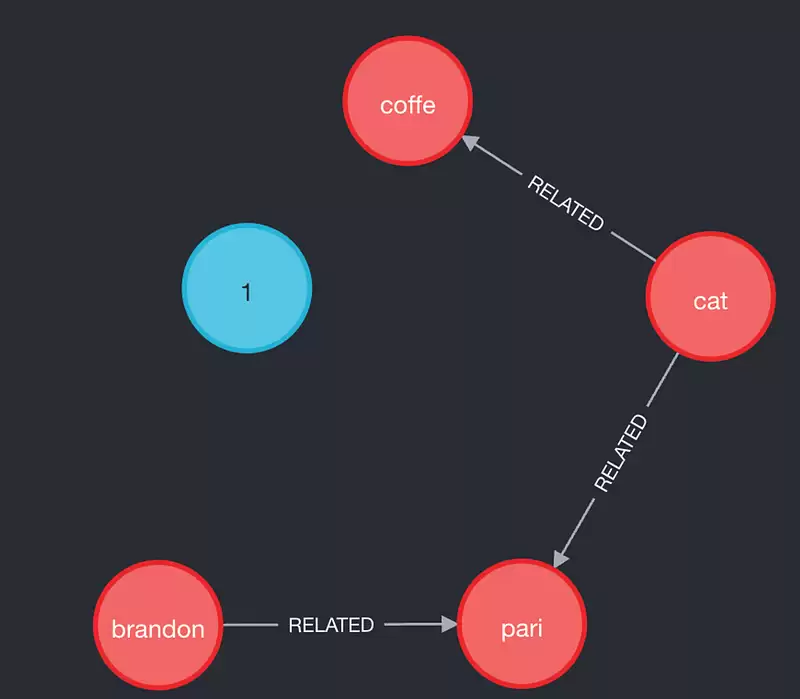
尽管如此,像这些问题:
* 谁想去巴黎旅行?
* 谁喜欢猫?
* 谁喜欢咖啡?
依然能得到正确答案,因为生成的上下文里包含了“Brandon loves coffee”,这足以让 LLM 给出正确回答。不过,在某些情况下也会出错。
一个可能的解决方向是**把文本转换成“命题”**,然后再把它存入知识图谱,而不是直接存原始文本。这个思路,论文 [Dense X Retrieval: What Retrieval Granularity Should We Use?](https://arxiv.org/abs/2312.06648) 里有相关探讨。
## 结论
总的来说,RecallM 提供了一种只用图数据库就能为 LLM 赋予长期记忆能力的方法。它在知识更新和时间推理上表现不错,但在构建精确知识图谱这件事上,依然存在挑战。不过,不妨说它是一个相当聪明的设计——代表了 AI 记忆机制上的一项重要进展,未来也还有很多优化和提升的空间。
热点追踪提示词
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Neo4j与RecallM构建无需向量数据库的知识图谱要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。






 相关热点
相关热点