




RAG多抽象层级分块与对齐机制的ARM实现思路

探索RAG技术的最新突破,深入解析多层级文本块粒度与对齐机制结合的ARM检索方案,为信息检索与问答系统带来全新思路。本文核心要点:1 RAG技术中文本块切分带来的挑战与瓶颈2 多抽象层级文本块粒度解决方案的详细解读3 ARM方案的设计原理及其在真实问答数据集上的性能表现一、引入多抽象层级文本块
探索RAG技术的最新突破,深入解析多层级文本块粒度与对齐机制结合的ARM检索方案,为信息检索与问答系统带来全新思路。
本文核心要点:
1. RAG技术中文本块切分带来的挑战与瓶颈
2. 多抽象层级文本块粒度解决方案的详细解读
3. ARM方案的设计原理及其在真实问答数据集上的性能表现
一、引入多抽象层级文本块粒度的RAG方案
传统RAG方法通常依赖固定长度的文本块(chunk)来支撑问答任务,但这种做法容易导致信息碎片化,内容完整性难以保障。更棘手的是,当检索到的信息数量增多时,常常出现所谓的"中间迷失"问题——关键内容被大量无关文本淹没,同时可能触发token限制。因此,常见的优化策略主要围绕chunk进行:固定大小切分、递归切分、滑动窗口……这些方法都在努力让文本块更加合理。
当然,还有一种更具创新性的方向——不在长度层面纠缠,而在层次结构上做文章。这正是最新研究成果《Multiple Abstraction Level Retrieve Augment Generation》(https://arxiv.org/pdf/2501.16952)所探索的路径。

核心思路可以通过一张图清晰概括:

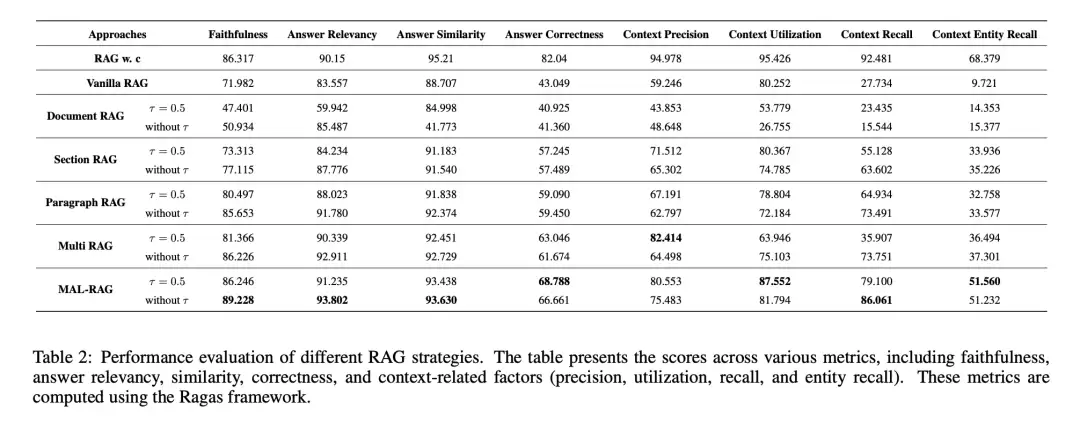
在索引阶段,首先将参考文献文档转化为四个抽象层次的文本块:文档级、节级、段落级和多句子级。
对于文档级和节级块,采用map-reduce方式生成摘要,目的是缩短文本长度、聚焦注意力。文档级块直接使用原始内容。节级块的处理则更细致:先为每个段落生成一段摘要,再将段落摘要聚合为节级摘要,最后将这些节级摘要汇总成文档摘要——这些摘要信息最终用于生成节级块的内容。
在检索阶段,使用Linq-Embed-Mistral嵌入模型生成问题与文本块的嵌入向量,通过余弦相似度计算相似性。随后利用softmax将相似性分数转换为概率,选取累积概率不超过预设阈值的文本块。
在生成阶段,将检索到的文本块与问题一并送入Vicuna-13B-v1.3模型,输出最终答案。
实际效果方面,在糖科学领域的问答数据集上,相比传统单层次RAG方法,答案正确性提升了25.739%。
二、引入对齐机制的ARM检索方案
这也是近期的一项突破性工作。现有基于LLM的问答系统(RAG)在分解问题时,往往缺乏对可用数据结构与分布的充分了解,导致检索效果不佳。迭代式RAG虽然能与数据集逐步交互,但每一步都依赖前一步结果,不仅效率低下,还容易引发推理偏差。
因此,一个值得关注的新思路出现了——论文《Can we Retrieve Everything All at Once? ARM: An Alignment-Oriented LLM-based Retrieval Method》(https://arxiv.org/pdf/2501.18539)提出的基于LLM的对齐导向检索方法ARM,专门应对复杂开放域问题的检索挑战。
具体流程如下:

首先,将表格、段落以及其他模态的数据对象(如图像)统一视为文本数据对象。对每个序列化的数据对象进行分块,计算每个块的嵌入向量,同时用N-gram集合进行表示和索引。
其次,指导LLM生成一个包含多个中间步骤的推理过程。第一步从用户问题中独立提取关键词,确定回答所需的关键信息。然后通过约束解码,利用数据对象中的N-gram来重述这些关键词。约束解码从解码一个左括号开始,到解码一个右括号结束,代表一个关键词的对齐完成。

接着进行信息对齐:将每个N-gram解码的结果作为查询,使用BM25算法在数据集中搜索相关文本块。然后计算用户问题与每个序列化对象之间的嵌入相似度,与BM25分数结合,形成最终排序分数。最终,根据排序分数选择最相关的对象,构成基础搜索对象集合,作为LLM继续生成"推理过程"的基础。
随后进入结构对齐:目标是推理出一组完整的搜索对象及其组织结构,以匹配所需信息并完整回答问题。结构对齐问题被形式化为一个混合整数规划(MIP)问题——目标是从给定的搜索对象列表中选择k个对象,最大化问题与选定对象之间的相关性,以及选定对象之间的兼容性。
最后,将MIP求解器生成的每个草稿序列化为字符串,通过约束解码注入到LLM的解码过程中。每个草稿包含选定的对象及其连接关系,然后LLM在解码过程中进行自验证,检查选定的对象是否覆盖问题的不同方面且连接正确。约束解码用于确保事实性。对每个草稿,使用束搜索生成多个推理过程,通过模型置信度(如logits的平均值)来衡量每个对象的权重和投票数。最终,对象的置信度是其加权投票数与投票数归一化值的加权和。最后,根据置信度选择最终的数据对象集合作为答案——高置信度的对象更有可能被选中,确保答案的质量和准确性。
具体来看一个例子:

不过,论文也坦承:在大多数情况下ARM表现出色,但在某些极端情况下,模型可能会忘记之前迭代中生成的信息,或者陷入相似关键词的循环搜索——即使已经检索到了相关对象。
总结
本文介绍了两个关于RAG的最新工作:一个是引入多层级文本块粒度的RAG方案,另一个是基于LLM的对齐导向检索方法ARM,用于解决复杂开放域问题的检索难题。两个方案的核心优势都体现在流程设计的精妙之处。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:RAG多抽象层级分块与对齐机制的ARM实现思路要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点交易决策的本质,始终是数据与判断力之间的博弈。如今,一款免费的AI平台——AI Trading Predictor——正致力于让数据占据更重要的分量,为股票、加密货币及商品交易提供实时预测与可视化支持。它并非神秘的黑箱魔法,而是将人工智能与市场数据深度融合,使普通投资者也能拥有接近机构级别的趋势分析
当前AI大模型正快速融入各个行业,但通用模型在处理垂直细分场景时往往精准度不足——例如法律文档审核、奢侈品真伪辨别、艺术品估价等任务,普通GPT难以提供可靠的答案。NeuralVault精准定位这一需求缺口:它针对法律文档分析、时尚奢侈品鉴定、艺术品估值、投资研究等专业领域,提供了一系列高度定制的G
加密货币交易圈子里,工具五花八门,但能真正把AI和实时数据结合到一块儿的,其实并不多。最近注意到一个叫CoinScreener的平台,它提供的不只是K线图,还有AI实时生成的信号——说白了,就是让机器帮你盯盘、帮你找机会。什么是CoinScreener?简单来说,CoinScreener是一个集实时
在股票与加密货币交易领域,AI 工具正逐步降低使用门槛,让更多人能够参与其中。今天要介绍的这款产品就是一个典型代表——它让完全没有编程经验的用户也能轻松创建个性化的交易策略。 什么是TraderGPT? 简单来说,TraderGPT 是一款由人工智能驱动的交易机器人。它的核心优势在于:用户不需要掌握
- 日榜
- 周榜
- 月榜
热点快看