




DeepSeek新作:代码转思维链,全面提升大模型推理能力

先说几个核心判断:利用代码训练模型,不仅仅是为了让模型具备编程能力——其中蕴藏的推理能力,竟然还能泛化到其他领域。DeepSeek团队近期发布的一项研究,正好证实了这一点。 他们构建了一个名为CODEI O的数据集,包含超过300万个训练样本,核心思路是将代码转化为推理链条,然后用这个数据集去训练Q
先说几个核心判断:利用代码训练模型,不仅仅是为了让模型具备编程能力——其中蕴藏的推理能力,竟然还能泛化到其他领域。DeepSeek团队近期发布的一项研究,正好证实了这一点。
他们构建了一个名为CODEI/O的数据集,包含超过300万个训练样本,核心思路是将代码转化为推理链条,然后用这个数据集去训练Qwen、Llama等开源模型。最终结果:模型在各类推理任务上均取得了显著提升,即便是与代码毫无关联的任务,也从中获益。
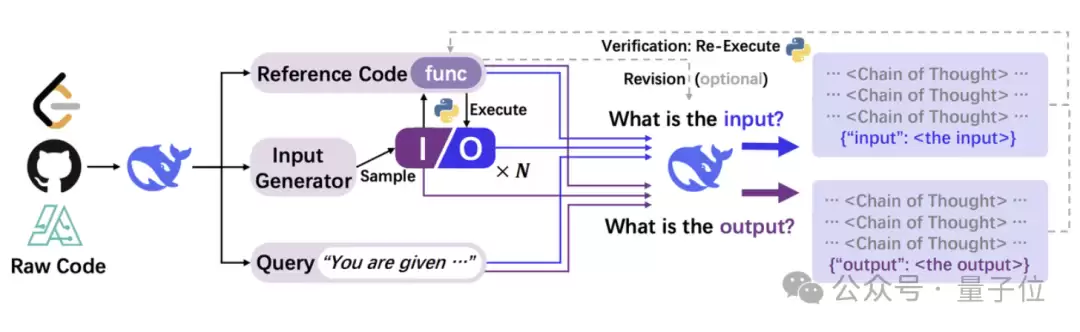
背后的逻辑其实很直观:代码天然蕴含了各种场景下的推理逻辑——条件判断、循环、递归、数据结构操作……这些本质上就是"从输入如何得到输出"的思考过程。团队的目标,就是把这种过程"萃取"出来,转化为模型能够理解的自然语言思维链。
具体怎么做?他们生成了大量训练数据,实际运行这些代码,然后把代码本身、输入/输出对、功能描述一起喂给DeepSeek-V2.5,自动合成自然语言形式的推理过程。在此基础上,又引入了验证与修正机制,打造出质量更高的CODEI/O++。
从代码中构建思维链
第一步是收集原始代码。团队从CodeMix、PyEdu-R等数据集中提取了80多万份代码文件,涵盖多种编程语言(以Python为主),任务类型丰富多样,其中包含的推理模式相当广泛。
不过原始代码通常结构混乱、依赖关系不明确、无法直接运行。因此需要先用DeepSeek-V2.5进行预处理,统一格式。主要操作包括:将核心逻辑提取为函数,添加一个主入口函数来统筹全局,明确主入口的输入输出定义,创建独立的基于规则的输入生成器,以及生成简洁的问题描述作为查询。
转换之后,针对每个函数,使用输入生成器采样多个输入,然后执行代码获取输出,从而收集到输入-输出对。当然,并非所有代码都能顺利执行——超时、复杂度太高、不可执行、结果不确定的样本都被过滤掉了。最终保留了40多万份代码文档,生成了350万个样本实例。
接下来是关键环节:将代码、输入输出对、功能描述等信息,输入给DeepSeek-V2.5,生成自然语言思维链(CoT)。每个输入-输出对被拼成一个提示,包含:函数定义(标准化后的Python代码)、文本描述(功能概括)、参考代码(带有注释的代码)、以及具体的输入或输出。模型根据这个提示,生成一段解释"如何从输入推导出输出"的文字。这就是CODEI/O的原始数据。
而CODEI/O++的改进在于:利用代码的可执行特性来验证质量。具体流程是——先对CODEI/O中生成的每条响应,重新执行代码验证正确性。如果发现结果有误,就把执行信息(例如输出预测的正确性、错误消息等)追加到下一轮输入中,要求模型重新生成。第二轮生成后再检查一次。无论结果如何,最终响应都包含四部分:第一轮响应、第一轮反馈、第二轮响应、第二轮反馈。如果第一轮就正确,第一轮反馈标记为"Success",跳过第二轮。所有经过修正的响应都被保留下来,形成了增强版的CODEI/O++。
数据集准备完毕后,训练策略也很有讲究:两阶段训练。第一阶段先用CODEI/O或CODEI/O++训练推理能力;第二阶段再使用通用指令数据集进行微调,让模型学会遵循自然语言指令、执行各种任务。
模型推理能力全面提升
为了验证效果,团队选取了四个模型进行测试:Qwen 2.5-7B-Coder、DeepSeek v2-Lite-Coder、Llama 3.1-8B 和 Gemma 2-27B。评估覆盖了常识、数学、代码、物理、工程等十几个数据集,具体如下表(图片保留):
结果非常有趣。Qwen-Coder在代码理解任务上表现突出,同时在阅读理解和推理任务(如DROP)上也有明显提升——这充分说明通过代码训练获得的推理能力,确实能够迁移到其他领域。DeepSeek-Coder同样展现出均衡的进步,各个维度都有稳定改进。这两个代码专用模型的提升表明:即便模型本身已经是代码领域的专家,这种结构化的推理训练依然能使其变得更强。
Llama 3.1-8B的变化最为惊人:LeetCode-O上的性能提升了将近150%。这证明小参数模型在合适的方法下,同样能在特定任务上爆发出巨大潜力。而Gemma作为测试中规模最大的模型,展示了CODEI/O方法在大型模型上的适用性,多个关键领域均有所进步。
对比来看,CODEI/O的整体效果优于数据量更大的WebInstruct(WI);而相比于专门为数学设计的OpenMathInstruct2(OMI2)或教育类数据集PyEdu,CODEI/O展现了更强的通用性——它不只是提升某一项能力,而是让模型在多种推理任务上都变得更出色。
归根结底,代码本身就是一种高度结构化的思维语言。将其转化为模型能够理解的推理过程,或许比想象中更接近"教会模型思考"的核心。当然,这条路仍然漫长,但至少方向已经明确。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:DeepSeek新作:代码转思维链,全面提升大模型推理能力要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在 Degiro 上进行投资的用户,常常会遇到一个共同的痛点:平台自带的数据展示较为基础,若想获取更深入的投资组合分析、风险指标,甚至对未来走势做出预测,通常只能借助 Excel 手动处理。不过,现在有一款 Chrome 扩展程序可以完美解决这一难题——Mercury,专为 Degiro 用户量身打
在投资决策过程中,客观数据往往比主观直觉更值得信赖。名为Lorna的智能平台,运用独特的现金流分析体系,帮助投资者穿透虚饰的财务报表,直达企业真实的财务健康状况。 什么是Lorna?——数据驱动的现金流分析投资工具 简而言之,Lorna是一个以数据为核心驱动力的投资分析工具。其核心利器是独创的“现金
Front Street自动追踪你的每一笔消费,整合各类忠诚度计划,并提供财务洞察与省钱妙招——说白了,就是帮你把钱&包管得明明白白。 什么是Front Street? 简单讲,Front Street就是你的购物管家。它自动记录你在每个品牌、每家店的所有购买行为,然后把零散的忠诚度计划全部整合到一
在创投圈深耕多年,你会发现一个普遍难题:融资过程中,投资者关系维护、尽职调查、潜在投资人挖掘……这些环节往往耗费巨大精力,却又直接决定成败。如果能有一款工具将这些琐事自动化,让团队聚焦于真正重要的沟通与战略决策,那该多理想?Finta 正是为此而生。 什么是Finta? Finta 本质上是一款 A
- 日榜
- 周榜
- 月榜
热点快看