




彻底破解vLLM与DeepSeek规模化部署的不可能三角之道

在LLM领域,vLLM和DeepSeek一直是技术社区热议的焦点。然而,将模型成功运行只是第一步,真正实现稳定、高效、低成本地为海量用户提供服务,则属于另一层面的挑战。这不仅涉及技术实现,更是一场关于规模化部署的精细权衡。本文将从实际应用出发,深入探讨这些关键问题。 vLLM的核心定位与价值 AI产
在LLM领域,vLLM和DeepSeek一直是技术社区热议的焦点。然而,将模型成功运行只是第一步,真正实现稳定、高效、低成本地为海量用户提供服务,则属于另一层面的挑战。这不仅涉及技术实现,更是一场关于规模化部署的精细权衡。本文将从实际应用出发,深入探讨这些关键问题。
vLLM的核心定位与价值
AI产业的爆发式增长,催生了诸如DeepSeek等性能卓越的推理模型。对于个人用户而言,DeepSeek免费开放界面,几乎零门槛的体验确实极具吸引力。但一旦进入企业级场景,情况就复杂得多——稳定性、数据隐私保护、以及避免模型训练数据被收集等能力,缺一不可。
正因如此,基于vLLM自建推理服务逐渐成为众多企业的首选方案。vLLM的核心价值在于,它打通了模型与终端用户之间的“最后一公里”。通过相对标准化的接口,开发者能够更便捷地向模型发起推理请求,大幅缩短从模型到应用的距离。围绕vLLM构建的商业生态也日益活跃。
企业级部署的核心难点
个人使用LLM关注的是输出结果,而企业部署LLM更注重服务的稳定性、成本与整体性能。以下是一些不可回避的挑战:
- 模型体积庞大:LLM之所以被称为“大”模型,是因为其参数规模动辄数十乃至上百GB。这导致冷启动速度缓慢——从下载模型文件到加载进GPU,往往需要漫长的等待。日常的模型上传、调试与发布,时间成本也随之显著增加。
- 推理实时性要求高:交互过程必须达到实时响应,数秒甚至毫秒级返回结果。这依赖于vLLM与模型之间缓存数据的利用率,直接关系到对话的连续性和响应速度。
- 上下文不可中断:许多应用场景依赖于多轮对话,如果每次请求被分配到不同的后端资源,上下文就会丢失。系统必须有效管理和协调底层资源,保障对话的连贯性与稳定性。
除了模型本身的技术挑战,支撑vLLM运行的显卡集群同样隐藏着三大难题:
- 资源利用的波峰与波谷:业务流量往往分布不均,高峰期需要大量显卡,低谷期则多数闲置。若只为覆盖峰值而采购硬件,平时大量资源将处于“空转”状态。
- 负载不均衡:即使在高峰期,若调度策略不合理,也容易出现某些服务器过载、另一些服务器空闲的状况,直接影响服务质量。
- 上云还是自购的两难抉择:云端弹性资源虽能缓解波峰波谷问题,但GPU实例要么价格高昂,要么冷启动缓慢,要么弹性不够实时。自购显卡则面临初期投入大、供货不稳定,以及可能需额外“囤货”的风险。
“不可能三角”:性能、成本、稳定性
综合以上难点,实际表现为一个典型的“不可能三角”——性能、成本与稳定性三者很难同时达到最优:
- 保障性能+保障稳定性:必须提前扩容、优化调度,导致成本和人力投入水涨船高。
- 控制成本+保障服务质量:例如采用按需推理时,冷启动时间会因模型体积庞大而被放大到难以接受的程度。
- 追求性能+控制成本:GPU数量可能不足,资源一旦挤兑,系统稳定性便面临挑战。
这个“三角”直接关系到整体服务架构的稳固性。一个完整的企业级产品,不仅需要强大的资源底座,还需将日常迭代、模型管理、可观测性以及运维等琐碎但必要的功能整合起来。
DevOps的日常挑战
即便基础设施已就位,日常的开发和运维工作同样不轻松:
- 框架与模型持续迭代:vLLM和模型本身都在快速演进,版本控制与更新部署因模型体积庞大而变得复杂。
- vLLM服务器管理:需要管理、调度和监控大量实例,确保弹性伸缩、低延迟与高吞吐,实例的生命周期管理也是一大难题。
- 版本控制与兼容性:确保不同版本之间可追溯、可回滚,对技术栈提出了更高要求。
破解之道:FC GPU预留实例闲置计费
针对上述难题,函数计算(FC)的GPU预留实例闲置计费功能提供了一种富有创意的解决方案。
- 性能优化:提前启动vLLM服务实例,框架和模型均已部署就绪。请求到达时,服务可立即唤醒执行,有效避免冷启动延迟。同时,FC能够高效复用集群级缓存,确保高并发下的快速响应。
- 成本控制:这是该功能最突出的亮点。预留实例处于闲置状态时,只需支付少量保留费用;而在活跃使用时则按正常价格计费。结合定时预留功能,可动态调整资源池大小,最大限度提升资源利用率。
- 稳定性保障:FC自研的调度算法配合显存数据管理机制,确保模型到显卡、请求到容器、容器到显存池的高效调度。支持最长24小时的长链接以及WebSocket调用,保障对话不中断。
此外,FC在开发运维方面也相当全面:支持日常迭代、模型管理、多维度可观测指标、仪表板,以及丰富的请求调用机制——智能实例分配、灵活并发度调节、定时触发、同步异步调用、多种调用形式。企业能够更专注于业务逻辑本身,而不必被底层技术细节拖累。
部署流程:开箱即用,操作简便
FC提供了一套vLLM框架与模型解耦的部署流程,开箱即用,无需特殊配置。具体步骤如下:
- 上传vLLM镜像:使用官方Docker镜像,无需修改,直接上传至容器镜像服务。
- 创建函数:登录FC控制台,创建新的GPU函数,并选择合适的运行环境。
- 配置启动命令:务必加上
--enforce-eager参数以确保稳定性。
python3 -m vllm.entrypoints.openai.api_server --enforce-eager --model ${NAS中的模型路径} --trust-remote-code --served-model-name ${LLM模型} ...其他参数配置... --port ${函数暴露端口}
python3 -m vllm.entrypoints.openai.api_server --model /prod/models --trust-remote-code --served-model-name Qwen/Qwen-14B-Chat --gpu-memory-utilization 0.9 --max-model-len 4096 --port 8080
- 选择显卡:推荐采用Ada系列GPU,使用整卡显存。
- 完成创建:按步骤配置后即可创建。
- 指定模型挂载路径:建议将模型存储在NAS中,自动挂载到FC实例,实现无缝集成。
- 配置预留实例并开启闲置计费:按需创建实例数量,并配置定时预留策略。
- 绑定自定义域名(可选):直接通过域名对外提供HTTP推理服务。
应用集成:灵活的输出方式
vLLM函数配置完成后,可以直接通过自定义域名对外提供服务。也可以进一步封装——将自定义域名嵌入上层服务并进行调用封装,企业无需关心底层的启动、调度、负载均衡与亲和性等细节。
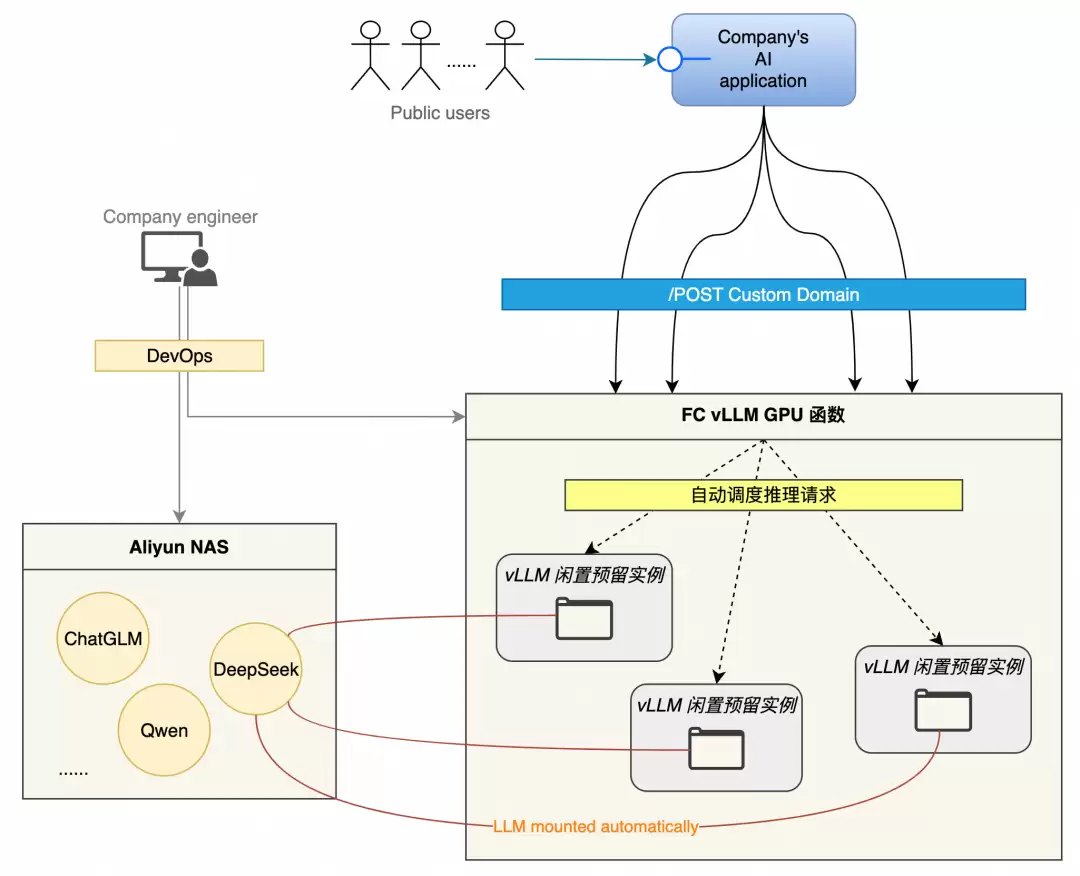
如果不想自行管理vLLM实例,还可以直接使用基于FC的模型应用平台(CAP)来简化部署,从而显著节省时间和精力。
总结
通过FC GPU预留实例的闲置计费功能,企业用户能够在发挥vLLM强大能力的同时,找到成本、性能与稳定性的最佳平衡点,并保持开发与运维的高效性。无论是直接对外提供服务,还是进行深度集成,抑或是通过CAP简化部署,都能找到适合业务需求的最佳实践。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:彻底破解vLLM与DeepSeek规模化部署的不可能三角之道要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点交易决策的本质,始终是数据与判断力之间的博弈。如今,一款免费的AI平台——AI Trading Predictor——正致力于让数据占据更重要的分量,为股票、加密货币及商品交易提供实时预测与可视化支持。它并非神秘的黑箱魔法,而是将人工智能与市场数据深度融合,使普通投资者也能拥有接近机构级别的趋势分析
当前AI大模型正快速融入各个行业,但通用模型在处理垂直细分场景时往往精准度不足——例如法律文档审核、奢侈品真伪辨别、艺术品估价等任务,普通GPT难以提供可靠的答案。NeuralVault精准定位这一需求缺口:它针对法律文档分析、时尚奢侈品鉴定、艺术品估值、投资研究等专业领域,提供了一系列高度定制的G
加密货币交易圈子里,工具五花八门,但能真正把AI和实时数据结合到一块儿的,其实并不多。最近注意到一个叫CoinScreener的平台,它提供的不只是K线图,还有AI实时生成的信号——说白了,就是让机器帮你盯盘、帮你找机会。什么是CoinScreener?简单来说,CoinScreener是一个集实时
在股票与加密货币交易领域,AI 工具正逐步降低使用门槛,让更多人能够参与其中。今天要介绍的这款产品就是一个典型代表——它让完全没有编程经验的用户也能轻松创建个性化的交易策略。 什么是TraderGPT? 简单来说,TraderGPT 是一款由人工智能驱动的交易机器人。它的核心优势在于:用户不需要掌握
- 日榜
- 周榜
- 月榜
热点快看