




英伟达GPU与阿里云GPU异构机型详解

NvidiaGPU架构从Pascal到Hopper持续演进,通过引入NVLink、NVSwitch及合并L1 共享内存等技术提升GPU间通信效率和并行处理能力,以适应大模型训练与推理需求。阿里云ECS提供多种GPU实例规格,覆盖不同规模模型的训练与推理场景,并通过异构调度优化资源利用。
深入解析Nvidia GPU技术革新与阿里云GPU异构机型的应用优势
本文将从Nvidia GPU架构的发展历程入手,深入剖析各代架构的关键特性与技术飞跃,特别是那些旨在提升GPU间通信效率和并行处理能力的创新。随后,我们会重点探讨这些技术在大模型时代的具体应用,例如如何加速AI训练和推理。最后,将盘点阿里云ECS当前在售的GPU实例规格族及其适用场景,并揭示阿里云如何通过独特的技术手段来弥补单卡算力不足的问题。
一、前言
当下,关于大模型的文章和讨论大多集中在工程应用、算法优化、Prompt工程,或是PAI、百炼等多产品架构组合上。但一个关键却略显分散的领域是:AI/ML训练任务的管理、任务流的分配、任务调度关系,以及数据集的加速等支撑性环节。不同AI任务对异构资源(如GPU)的调度、分配、隔离需求千差万别,而不同的调度策略,又直接影响训练时间和最终结果。更现实的问题是,在GPU卡越来越昂贵的今天,如何通过高效的调度,让AI任务充分利用GPU等异构资源,尽量减少空闲的GPU核心,实现资源效益最大化,已成为至关重要的一环。
因此,我们可以将AI/ML的体系大致梳理如下:
- 业务应用层: 阿里云AI、开源AI、用户自有AI平台。
- AI任务层: 例如弹性训练、弹性推理。
- AI任务流管理平台: 负责任务调度、数据加速、任务流管理,代表性工具如Kubeflow、Arena。
- 异构资源调度层: 负责异构资源的管理、分配、隔离和拓扑感知,以满足不同AI任务的并行需求。
- 基础异构资源层: 核心就是GPU等计算单元。
- 支撑体系: AI仓库数据和AI观测。
本系列文章将聚焦于基础异构资源、异构资源调度和AI任务流管理平台这三个层面。作为开篇,我们从最基础的异构资源——GPU入手。重点介绍Nvidia GPU的发展历程,解答几个关键问题:除了SM核心算力的持续增强,Nvidia为何要引入NVLink和NVSwitch?为何要对L1/共享带宽进行合并?同时,我们也会梳理阿里云ECS目前提供的异构机型及其适用场景。
二、Nvidia GPU
2.1. 架构演进
(内容涵盖架构演进的时间线和代际关系,此处省略具体图片)
2.2. 主要架构
2.2.1. Pascal(2016年)
Pascal架构的关键特性可以总结为几点:
- CUDA核心: 每个SM包含64个单精度(FP32)CUDA核心,分为两个处理块。虽然数量比前代Maxwell少了一半,但TPC(纹理处理器簇)的改进保持了相当的寄存器文件和线程块占用率。
- 线程和寄存器: 尽管单个SM的核心数减少,但GP100芯片拥有多达60个SM,因此总寄存器数量更多,可同时支持的线程、warp和线程块数量也大幅增加。GP100总核心数为:FP16核心64*60=3840个,FP32核心32*60=1920个。
- 共享内存: SM数量的增加也带来了总共享内存的增加,聚合共享内存带宽实际上实现了翻倍。
- 高效执行: 改进后的SM架构使得代码执行更高效,指令调度器有更多warp可供选择,提高了加载启动次数和每线程到共享内存的带宽。
- 高级调度: 每个warp调度器(每个处理块一个)能在每个时钟周期调度两个warp指令。
- 新特性: 支持处理16位和32位精度的指令和数据,FP16操作的吞吐量最高可达FP32的两倍。
Tesla P100首次引入了NVIDIA的高速接口NVLink,可提供高达160 GB/s的双向带宽,是PCIe Gen 3 x16带宽的5倍。在一个混合立方网格拓扑中,8个Tesla P100翻跟斗通过NVLink相连,每个GPU都有4个NVLink与其它GPU连接。GPU互联的路径分两种:
- NVLink路径: 表示两个GPU通过NVLink直连,可利用总带宽160GB/s(双向),单个GPU-to-GPU带宽为40GB/s(双向),单向20GB/s。
- PCIe路径: 必须走PCIe → CPU → PCIe的链路。在Pascal架构下,使用的是第三代PCIe,理论最大带宽为16GB/s(单向)。
虽然NVLink 1.0的GPU-to-GPU单向带宽(20GB/s)相比PCIe(16GB/s)的提升幅度看似不大,但关键在于,NVLink是GPU间独享的通道。而PCIe那16GB/s的单向带宽,是由两个GPU和2张网络接口卡(NIC)共享的,真正用于GPU间数据传输的带宽远达不到这个理论值。
NVLink:表示最大双向40GB/s
PCIe:表示最大双向32GB/s
所以,如果GPU需要通过PCIe方式读取其他GPU上的数据,其传输速度必然受到PCIe带宽的限制。从物理架构层面看,受到PCIe链路带宽的制约,AI任务调度应尽可能将任务分配到通过NVLink互联的GPU上。
(参考Nvidia官网白皮书:链接已省略)
2.2.2. Volta(2017年)
Volta架构带来了诸多革命性变化:
- 第二代NVLink: 单GPU支持6条NVLink链路,总带宽高达300 GB/s。
- HBM2内存: 16 GB的HBM2内存子系统,带宽达到900 GB/s。
- L1和共享内存合并: 由4个纹理单元共享。这里可以看到,内存的L1/L2分级和容量扩充,其核心目的就是为了避免数据从内存或硬盘反复读取,内存分级本身就是任务运算的关键瓶颈之一。
- 多进程服务(MPS): 提供服务质量(QoS)和隔离能力。
- 芯片规格: GV100芯片包含6个GPC(图形处理簇),每个GPC有7个TPC,14个SM。每个SM拥有64个FP32核心、64个INT32核心、32个FP64核心、8个Tensor Core和4个纹理单元。完整的GV100 GPU(84个SM)总计拥有5376个FP32核心、5376个INT32核心、2688个FP64核心、672个Tensor Core和336个纹理单元。
- Tensor Core: V100 GPU包含640个Tensor Core(每个SM有8个)。在Volta GV100中,每个Tensor Core每时钟周期执行64次浮点FMA运算,一个SM中的8个Tensor Core每时钟周期总共执行512次FMA运算(或1024次单浮点运算)。大胆的Tensor Core使得Volta架构能够高效训练大型神经网络。
- 互联升级: NVLink 2.0将GPU-to-GPU单向带宽提升至25GB/s,且单GPU可连接链路数增至6条,因此单GPU双向最大带宽达到了25*2*6=300GB/s,相比Pascal架构提升了一倍。同时,NVSwitch 1.0的引入旨在进一步提高GPU间的通信效率和性能,它可以支持多达16个GPU之间的通信。
从这个架构可以清晰地看到,Nvidia除了疯狂地堆叠SM和核心,也在想尽一切办法提升GPU-to-GPU之间的带宽,让数据能在GPU间快速读取。一个隐约的趋势已经显现:如何绕开PCIe、绕开CPU和内核切换,已经成为AI时代的瓶颈,因为在大模型时代,数据量是几何倍数的增长。
NVLINK:第一代GPU-to-GPU
NVLink1:表示最大双向50GB/s
NVLink2:表示最大双向100GB/s
PCIe:表示最大双向32GB/s
由此可见,Volta架构正努力将多个GPU整合成一个整体对外提供计算能力。但不同GPU间的数据传输效率仍存在差异,这对任务调度和GPU计算资源的合理分配提出了挑战。
(参考Nvidia官网白皮书:链接已省略)
2.2.3. Turing(2018年)
Turing架构可以看作是Volta的改版,主要引入了光线追踪功能,更多应用于3D大型游戏领域。其关键特性包括:
- 包含2560个CUDA核心和320个Tensor Core。
- 继承并优化了Volta的MPS功能,在小型推理任务中性能更好,延迟更低。
- Tesla T4配备了16GB显存和320GB/s的内存带宽,几乎是其前代产品P4的两倍。
- 每个SM的纹理处理器引入了warp调度,且拥有自己的寄存器进行数据切换。
- Tensor Core增加了对INT8/INT4/Binary的支持。TU102 GPU包含576个Tensor Core,每个Tensor Core使用FP16输入时,每时钟周期可执行多达64个浮点FMA操作。新的INT8精度模式以两倍速率工作。
T4最适合小型模型的推理。 关键特性是:比L4更旧、速度慢,适合小规模实验和原型设计。比如,可以用T4启动项目,然后在上生产环境时切换到L4或A10。
(参考:链接已省略)
2.2.4. Ampere(2020年)
Ampere架构是大模型时代的一个里程碑:
- Tensor Core: 每个SM含有4个第三代Tensor Core,每个拥有256个FP16/FP32计算单元,意味着每个SM拥有1025个。A100的SM总数增加到了108个,L1共享内存也增加到了192KB。
- 多实例GPU(MIG): 允许A100 GPU被安全地分割成最多7个独立的GPU实例,每个实例在处理器和内存系统中拥有完全隔离的路径,为云计算厂商提供算力切分和多用户租赁服务。
- 第三代NVLink: 数据速率达到50 Gbit/sec(每对信号),并首次引入了NVLink Switch全网格(full mesh)概念。
- PCIe Gen 4: 提供31.5 GB/s的带宽。搭配40 GB HBM2显存和40 MB L2缓存。
2.2.4.1. NVLink:第三代
在Ampere架构中,一个8卡A100的组网引入了6个NVSwitch。每个GPU通过2条链路连接到每个NVSwitch,每条链路单向25GB/s,双向50GB/s。通过NVSwitch的池化作用,理论上,任何一个GPU与其他GPU进行数据交换的速度最高可达双向50*12=600GB/s。
NVLink12:表示最大双向600GB/s
可以说,在Ampere架构中,Nvidia通过引入NVSwitch实现了GPU的全网格组网,使得8卡或4卡能够作为一个整体对外提供一致性服务。
除了GPU间的显存交互,PCIe、NIC(网络接口卡)与GPU之间的组网方式也值得关注。通常,8张NIC网卡会两两绑定成4张软件层面的网络设备(NIC0-NIC4)。这又引入了NIC间、NIC与CPU间的交互问题。
PCIe:表示数据只需经过PCIe交换。A100使用第四代PCIe,双向带宽达64GB/s
SYS:表示数据需经过CPU处理,存在上下文和内核切换
可以看到,数据的远距离调用和上下文切换对任务运行、耗时和算力都会产生影响。这是一个物理层面的瓶颈,我们只能想办法将任务调度得更“近”一点。
2.2.4.2. 多级带宽
最底层是这次架构升级引入的NVLink技术,用于优化单机多GPU卡间的数据互连。传统架构中,GPU间数据交换受限于CPU和PCIe总线。
往上一层是L2缓存和DRAM,负责单块GPU卡内部的存储。L2缓存用于存储高频访问数据以降低延迟,DRAM则提供大容量空间。两者协同,使GPU能高效处理大规模数据集。
再往上一层是共享内存和L1缓存,负责SM内的数据存储。共享内存允许同一SM内的线程快速共享数据,极大提高了数据访问效率和并行计算性能。
最上层则是处理具体计算任务的Math模块,包括Tensor Core和CUDA Core。
在Ampere之前,若想使用共享内存,必须先将数据从全局内存加载到寄存器,再写入共享内存。这不仅浪费寄存器资源,还增加了时延。Ampere架构提供了异步内存拷贝机制(LDGSTS指令),实现全局内存直接加载到共享内存,避免了中间环节,减少了时延和功耗。此外,A100还引入了软件层面的异步拷贝机制(Sync Copy),可直接将L2缓存中的全局内存传输到共享内存。
A100最适合训练和推理较大模型(70亿到700亿参数)。 关键特性:NVIDIA的主力GPU,适用于AI、数据分析和高性能计算(HPC),提供40GB和80GB两种显存版本。对于内存受限的工作负载,A100可能比H100更具成本效益。
A10最适合小型到中型模型(70亿参数或以下)的推理,以及小型模型的小规模训练。 关键特性:与A100同架构,代码兼容性好,小型工作负载的性价比良好。
(参考:链接已省略)
2.2.5. Ada Lovelace(2022年)
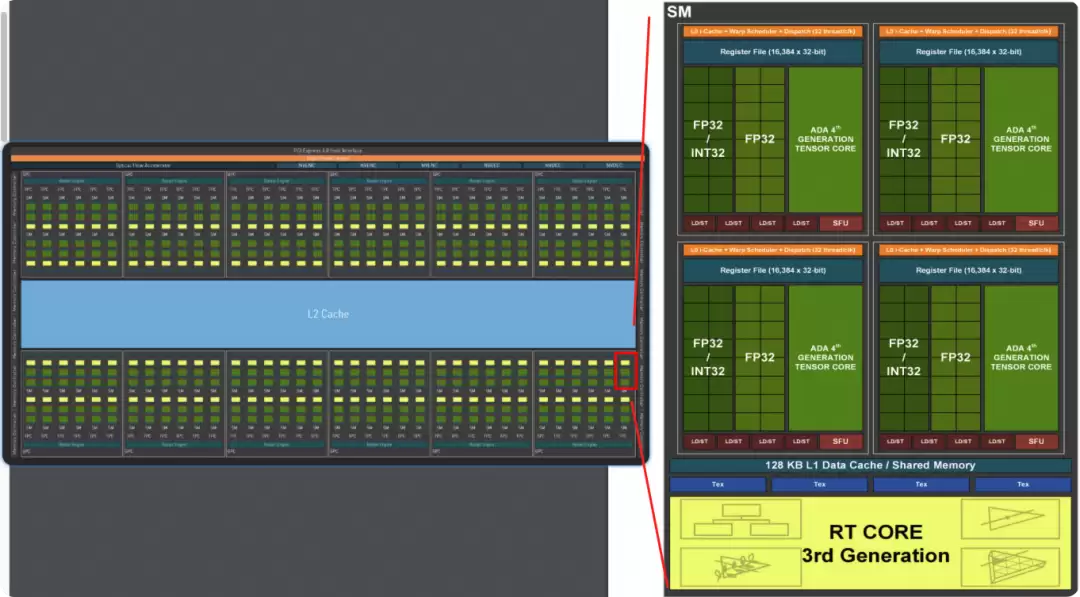
关键特性包括:
- AD102芯片包含12个GPC,72个TPC,144个SM。
- 每个SM包含128个CUDA核心、1个第三代RT Core、4个第四代Tensor Core、4个纹理单元、256KB寄存器文件和128KB L1/共享内存。
- RT Core是专用硬件单元,用于加速光线追踪任务。
L4最适合小型到中型模型(70亿参数或以下)的推理。 关键特性:成本效益高,显存容量与A10相同,但内存带宽仅为一半,性能比T4高出2到4倍。
(参考:链接已省略)
2.2.6. Hopper(2022年)
Hopper架构专为Transformer模型优化:
- Transformer引擎: 结合软件和定制的Hopper Tensor Core,专门加速Transformer训练和推理,通过智能管理FP8和16位计算,提供高达9倍的AI训练速度和30倍的LLM推理速度。
- HBM3显存: H100 SXM5是首款采用HBM3的GPU,提供3 TB/s的内存带宽。
- 50 MB L2缓存: 缓存更多模型和数据集,减少对HBM3的重复访问。
- 第二代MIG: 提供约3倍的计算能力和近2倍的内存带宽,每个GPU实例支持多达7个独立实例。
- 第四代NVLink: 总带宽900 GB/s,是PCIe Gen 5的7倍。
- 第三代NVSwitch: 最多可连接32个节点或256个GPU。
- SM内升级: 提供256KB共享内存和L1数据缓存,支持直接的SM间通信。
在第4代Tensor Core中,一个显著创新是Tensor Memory Accelerator(TMA)的引入。这个硬件化的数据异步加载机制,使得全局内存的数据能更高效地加载到共享内存,供寄存器读写,大大减少了线程间同步和协调的开销。
H100最适合训练和推理非常大的模型(700亿参数及以上),以及基于Transformer的架构和低精度(8位)推理。 关键特性:截至2024年底在售的最强大的NVIDIA数据中心GPU,大多数工作负载比A100快约两倍,但更难获取且价格更高。它优化用于LLM任务,提供超过3 TB/s的内存带宽,并包含专门用于FP8操作的计算单元。
(参考:链接已省略)
2.2.7. Blackwell
Blackwell架构目前(截至本文撰写时)预计推迟到2025上半年商业化,官方尚未发布详细白皮书。以下信息基于官方Brief说明:
- 新型AI超级芯片: 拥有2080亿个晶体管,采用双倍光刻极限尺寸的裸片,通过10 TB/s的片间互联技术连接成统一GPU。
- 第二代Transformer引擎: 结合定制Tensor Core、TensorRT-LLM和NeMo框架,加速LLM和MoE模型的推理和训练。
- NVLink 5.0: 为每个GPU提供1.8TB/s双向带宽,支持多达576个GPU间的无缝高速通信。
- RAS引擎: 通过专用引擎识别早期潜在故障,减少停机时间。
- 安全AI: 内置机密计算技术,保护数据和模型安全。
(参考:链接已省略)
2.3. NVLink和NVSwitch
迈入大模型时代,训练这些复杂的大型模型绝非易事。除了耗费巨大的GPU资源和时间,单个GPU内存也有限,无法承载许多大型模型的数据量。因此,业界转向了多GPU协作的分布式计算。
分布式通信的核心是将多个计算单元互联,使其协同工作。这依赖于节点间的高效通信机制。PCIe的每一代带宽都是前一代的2倍,但PCIe Gen 5 x16也仅有64GB/s,且全球能生产PCIe Gen 5和Gen 6的厂商屈指可数,产能有限。
H100的32位浮点计算能力为67 TFLOPS。如果每次计算都依赖从GPU外搬运新数据,而非复用旧数据,所需带宽将是天文数字(约268000 GB/s),远超PCIe能力。因此,为了避免算力闲置,就需要更大的带宽来支持数据处理。
NVLink正是为解决这一问题而生。NVLink 5.0连接主机和处理器的速度高达1800GB/s,是PCIe 5.0带宽的14倍多。NVSwitch则进一步将这一技术推向极致,它是一种专为高性能计算设计的高速互连芯片,能支持多达18个NVLink连接,实现多GPU配置中的极速数据流通。
利用NVSwitch,可以打破GPU间的单点链接,实现全网格的全互联。关于具体实现,可以参考2.2.4 Ampere章节中的描述。
(参考:链接已省略)
2.4. CUDA
使用GPU资源主要涉及两个层面:CUDA Driver和CUDA Toolkit(包括runtime和libraries)。程序调用GPU资源实际是调用CUDA Toolkit,而底层GPU资源的利用则是由CUDA Driver驱动的。
这里可以细分为三个层级:
- CUDA Toolkit: 面向开发者、应用程序暴露的调用GPU能力的Runtime和Libraries。
- CUDA User-mode Driver: 用户态CUDA驱动。
- CUDA Kernel-mode Driver: 内核态驱动。
需要关注的是:GPU卡所能支持的CUDA Driver版本,以及CUDA Driver版本和CUDA Toolkit的兼容性。官方提供了详细的兼容性表格。
(参考:Nvidia官方驱动下载页面、CUDA Toolkit Release Notes、CUDA Compatibility文档)
三、阿里云异构计算实例机型
阿里云当前在售的GPU实例族及其使用的GPU类型、架构和适用场景,大部分信息可以总结自官方文档。如果官方文档未提供具体GPU型号,可以参考第三方查询网站。
阿里云的第七代和第八代实例提供了通过eRDMA将多台机器组成GPU集群的方案,以适配单卡算力不足的场景。但整体来看,其最大160Gb/s的带宽,与Hopper架构中NVSwitch 3.0支持的256 GPU互联、G2G 450GB/s的带宽相比,仍有较大差距。在处理大数据量计算场景时,必须考虑到数据搬运受带宽限制的瓶颈。
四、小结
本篇主要介绍了Nvidia异构架构的演进历史和阿里云ECS实例机型及其适用场景。通过上述介绍,我们初步了解了Nvidia历代架构,除了不断增强单GPU内部的SM、优化L1/共享缓存和HBM外,还费尽心思优化PCIe、NVLink、NVSwitch等GPU-to-GPU间的链路。所有架构上的优化,都是为了适应大模型时代“大数据规模、大参数规模、大算力需求”下,分布式计算对海量数据快速处理和搬运的需求。其最终目标,是提高单位时间内的GPU负荷率,降低资源浪费。
下一篇,我们将开始探讨【异构资源调度】这一核心话题。从调度层面开始,云上的用户需要关注并优化AI任务在GPU卡上的资源调度配置、GPU卡的隔离、QoS保障、NUMA感知等;需要解决由大参数、大数据带来的网络组网、GDR和RDMA需求;还需要了解ACK AI套件如何感知、分配和调度GPU资源。这些工作的最终目的,都是通过加速数据读取和搬运,在加快AI训练/推理任务的同时,减少GPU空闲,提高利用率,从调度层面尽可能“榨干”每一分GPU资源。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:英伟达GPU与阿里云GPU异构机型详解要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在 Degiro 上进行投资的用户,常常会遇到一个共同的痛点:平台自带的数据展示较为基础,若想获取更深入的投资组合分析、风险指标,甚至对未来走势做出预测,通常只能借助 Excel 手动处理。不过,现在有一款 Chrome 扩展程序可以完美解决这一难题——Mercury,专为 Degiro 用户量身打
在投资决策过程中,客观数据往往比主观直觉更值得信赖。名为Lorna的智能平台,运用独特的现金流分析体系,帮助投资者穿透虚饰的财务报表,直达企业真实的财务健康状况。 什么是Lorna?——数据驱动的现金流分析投资工具 简而言之,Lorna是一个以数据为核心驱动力的投资分析工具。其核心利器是独创的“现金
Front Street自动追踪你的每一笔消费,整合各类忠诚度计划,并提供财务洞察与省钱妙招——说白了,就是帮你把钱&包管得明明白白。 什么是Front Street? 简单讲,Front Street就是你的购物管家。它自动记录你在每个品牌、每家店的所有购买行为,然后把零散的忠诚度计划全部整合到一
在创投圈深耕多年,你会发现一个普遍难题:融资过程中,投资者关系维护、尽职调查、潜在投资人挖掘……这些环节往往耗费巨大精力,却又直接决定成败。如果能有一款工具将这些琐事自动化,让团队聚焦于真正重要的沟通与战略决策,那该多理想?Finta 正是为此而生。 什么是Finta? Finta 本质上是一款 A
- 日榜
- 周榜
- 月榜
热点快看