




DeepSeek DSpark高并发推理服务Token高效生成优化

刚刚过去的周末,DeepSeek 放出了一篇关于推理加速的新论文,叫《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》。内容挺实在,聚焦于大模型推理服务里一个再具体不过的问题:
刚刚过去的周末,DeepSeek 放出了一篇关于推理加速的新论文,叫《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》。内容挺实在,聚焦于大模型推理服务里一个再具体不过的问题:在真实的高并发场景下,Speculative Decoding(投机解码)到底怎么才能既反赌,又别让目标大模型在无效的验证计算上白费力气?
先简单回顾下背景。Speculative Decoding 的核心思路是“让轻量模型先打个草稿,再由目标大模型来批改确认”。理想情况下,只要草稿够准,模型就能一次向前推进多个 token,而不是一个接一个地等。听起来很直接:草稿模型(draft model)多生成点候选 token,目标模型一次性验证就行。

但一放到真实服务里,事情就复杂了。草稿块(Draft block)变长,不代表最终被目标模型接收的 token 就更多;验证(verification)虽然可以并行,但也不是越长就越划算。尤其是在高并发的在线推理场景下,目标模型的 batch capacity(同一轮能处理的计算额度)是紧巴巴的资源,低置信度 token 的验证,会直接拖累整体的吞吐。
所以,DSpark 真正盯住的问题不是“怎么让草稿模型多猜几个 token”,而是:怎么让草稿 token 更容易被接受,同时让目标模型只去验证那些真正值得验证的 token。
围绕这个核心,DeepSeek 提出了两个设计:用半自回归生成来缓解并行草稿的后缀质量衰减;用置信度调度,根据 token 被接受的概率和系统负载,动态决定验证的长度。
我们一步步来看。
为什么并行草稿后面的 token 容易掉队?
在 Speculative Decoding 里,草稿模型的作用是提前生成候选 token。为了提高生成速度,一个很自然的想法就是让草稿模型一次生成长一点的草稿块(draft block)。直觉上,草稿块越长,目标模型一次接受更多 token 的机会就越大。
但真正决定加速效果的,不是草稿块有多长,而是被接受的长度(accepted length)能有多高。Accepted length 越高,说明每一轮能向前推进更多 token,加速效果才明显。现实是,长草稿块并不会天然带来更高的 accepted length。
现有的草稿模型,大致可以分成两类。
第一类是自回归式(autoregressive drafter),也就是草稿模型自己老老实实一个 token 一个 token 地生成。好处是后面 token 能依赖前面生成的内容,序列连贯;坏处也很明显:草稿生成本身变慢,块越长,计算时间越长。
第二类是并行式(parallel drafter),一次性并行生成一整段候选 token。优势是快,因为所有位置的 token 可以在一轮 forward pass(一次完整计算)中同时生成。但它有个结构性问题:每个位置的 token 是同时预测的,后面的 token 根本不知道前面实际采样出了什么。
DeepSeek 举了个很直观的例子。假设上下文后面既可以接 “of course”,也可以接 “no problem”。两种续写本身都合理。但如果每个位置独立预测,模型可能把不同续写路径混在一起,生成 “of problem” 或 “no course” 这种四不像。这类问题被称为多模态冲突(multi-modal collision),它直接导致一个后果:草稿块越往后,token 越容易不连贯,越容易被目标模型拒绝。这种现象也叫后缀衰减(suffix decay)——草稿越往后,越容易掉队。
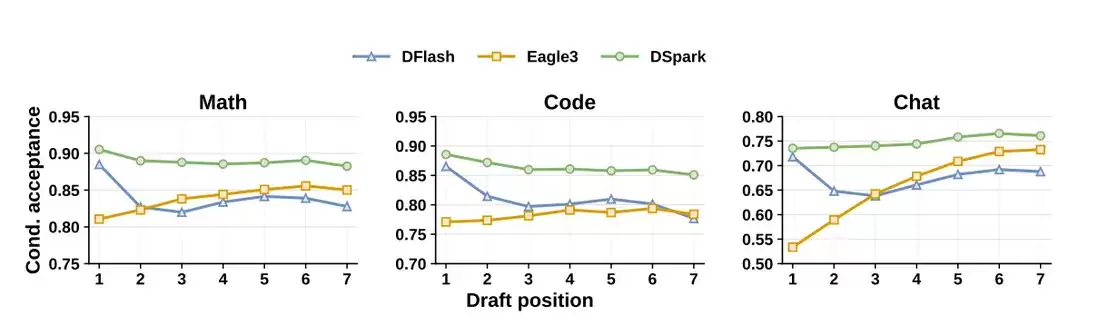
上图是论文里的关键验证。重点看不同 draft position 上的条件接受率(conditional acceptance),它衡量的是:在前面 token 都已接受的前提下,当前位置 token 能继续被接受的概率。可以看到,DFlash(图中蓝线)这类纯并行 drafter 在前几个 token 上表现不错,但越往后,条件接受率明显下降。这不是说它不能快速生成草稿,而是越往后越容易猜偏。这就是并行草稿的核心问题:它在猜测一整段时,不清楚自己之前到底踏上了哪条语义路径。
所以,DSpark 要解决的第一个问题就是:能不能保留并行生成的速度,同时让后面的 token 能感知到前面已经生成的内容?
为什么验证在高并发服务里不能无脑做长?
长草稿块的另一个问题,是验证资源的浪费。
验证可以理解为目标模型对草稿 token 的“批改确认”。在 Speculative Decoding 里,目标模型验证的是连续前缀。只要中间某个 token 被拒绝,后面的 token 即使本身质量不错,也会被一起丢弃。这就带来一个问题:如果草稿模型一次生成了很多 token,但后半段大概率会被拒绝,那么把这些 token 全部送给目标模型验证,很可能就是在浪费算力。
在单请求、低负载场景下,这种浪费或许不明显。但到了真实的高并发服务中,问题会被迅速放大。因为目标模型的 batch capacity 是有限的。每多验证一个低价值 token,就可能挤占其他用户请求的计算资源。这也是 DSpark 论文反复强调的工程背景:verification 不是免费的。
不同任务也有差异。代码、数学这类结构化任务,草稿 token 通常更容易被接受;开放聊天这种自由度更高的任务,后缀 token 的不确定性更强,被拒绝的概率也更高。系统低负载时,可以多验证一点;系统高负载时,就要更谨慎地使用验证预算。
所以,Speculative Decoding 的难点就变成了两个:
- 草稿 token 本身是否足够靠谱;
- 这些 token 是否值得占用目标模型的验证资源。
DSpark 的两个核心设计,正是围绕这两点展开的。
第一步:给并行草稿加一点顺序依赖
针对并行草稿后缀容易衰减的问题,DSpark 的第一个设计是半自回归生成(Semi-Autoregressive Generation)。
这个名字可能会让人误解。它不是让草稿模型完全回到一个 token 一个 token 的老路上去,而是在并行生成的基础上,引入一层很轻的顺序依赖。
前面提到,并行草稿的优势是快:一次 forward pass 就能生成一整段。但问题也来自这里:多个位置同时预测,后面的 token 不知道前面实际采样出了什么。DSpark 的处理方式是折中。它保留了并行主干(parallel backbone),负责主要计算的部分,仍然一次性处理整个草稿块,保持速度优势。在此基础上,额外加入一个轻量顺序模块(lightweight sequential head),作用是在草稿块内给后续 token 补充局部顺序信息,让它们能参考前面已经采样出来的 token。
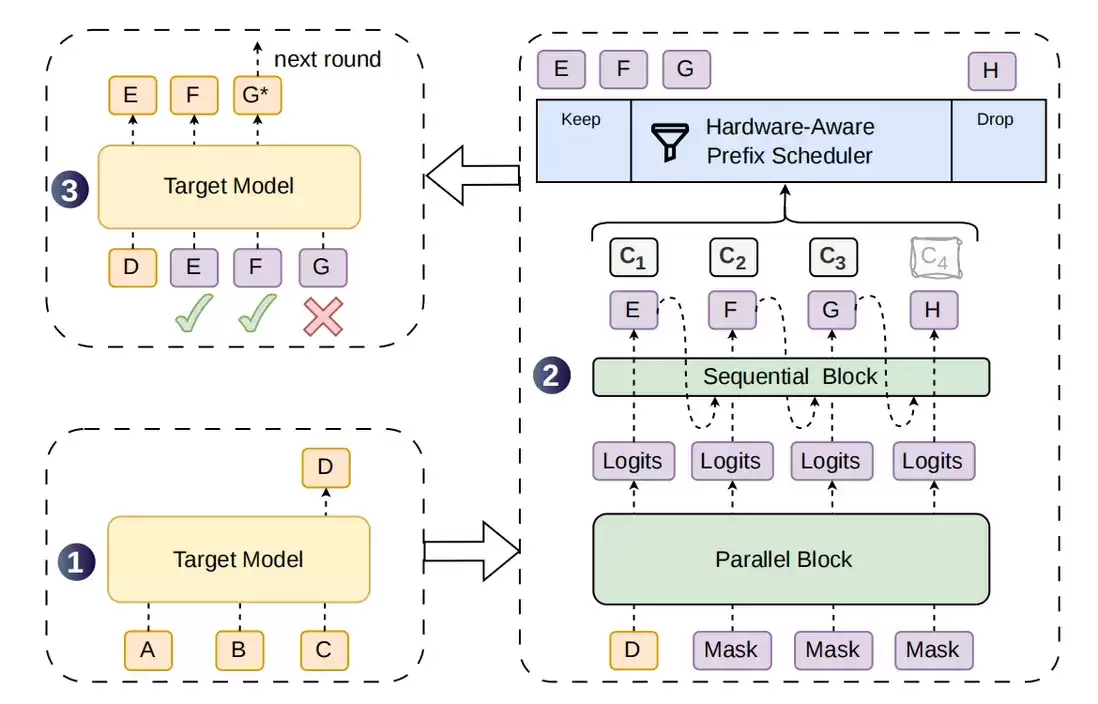
上图展示了这个结构。可以重点看两条路径:一条是草稿 token 的生成,先通过并行主干快速生成候选,再通过轻量顺序模块补上局部依赖;另一条是置信度分数(confidence score)的生成,在生成草稿的同时,也估计每个位置的 token 有多大概率通过目标模型的验证。
在顺序模块的实现上,DeepSeek 主要讨论了两种方案:马尔可夫头(Markov head)和 RNN 头(RNN head)。
Markov head 是默认方案。它只看前一个已采样的 token,用一个轻量的转移偏置来调整下一个 token 的概率分布。继续用前面的例子:如果前一个 token 已经采样成 “of”,Markov head 就会让后续 token 更倾向于走向 “course” 而不是 “problem”,减少路径混在一起的可能。
RNN head 可以记录更长的块内历史,理论上表达能力更强。但实验显示,相比 Markov head,它带来的收益有限,部署复杂度却更高。因此,DSpark 默认采用 Markov head。这个选择很有工程意味:对于生产级系统,额外模块不能只看效果提升,还要看是否足够轻、是否引入明显延迟、是否容易接入现有推理链路。
这里的关键判断是:DSpark 不是放弃并行生成,也不是把草稿模型重新变慢,而是在并行生成之后补上一层轻量顺序修正。
DeepSeek 的实验也支持这一点。随着 proposal length(每轮尝试生成的候选 token 数量)变长,纯并行草稿的后缀衰减会更明显,而 DSpark 通过引入局部顺序依赖,能在更长 proposal length 下保持更好的 accepted length。
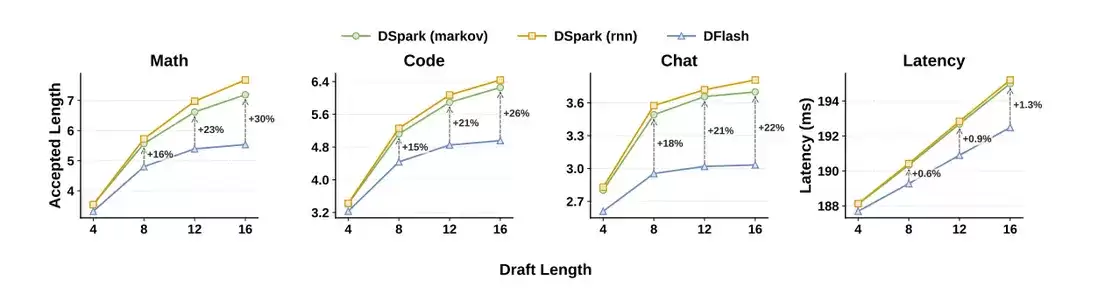
上图传达两个信息:一是 proposal length 变长时,DSpark 的 accepted length 优势更明显;二是 sequential head 带来的额外延迟很小。这说明 DSpark 并不是用显著增加草稿成本来换取接受率,而是用较小的顺序建模开销,补上了并行草稿在后缀一致性上的短板。
第二步:验证不是越长越好,而是要动态调度
如果说半自回归生成解决的是“草稿 token 怎么更容易被接受”,那么第二个设计解决的,是“哪些草稿 token 值得交给目标模型验证”。这就是基于置信度调度的验证(Confidence-Scheduled Verification)。
它的核心组件是置信度头(confidence head),一个轻量判断器,用来估计草稿 token 通过目标模型验证的概率。更准确地说,DSpark 预测的是前缀生存概率(prefix survival probability)——从第一个草稿 token 开始,连续通过验证并“活到当前位置”的概率。
为什么要预测这个值?因为 Speculative Decoding 的验证是前缀式的。如果第 2 个 token 被拒绝,第 3、4、5 个 token 即使本身不错,也会被一起丢弃。所以,第 5 个 token 是否值得验证,不只取决于它自己准不准,还取决于前面的 token 能不能先通过。这就是前缀生存概率的意义:它不是孤立判断某个 token,而是判断这个位置之前的整段前缀有没有机会连续通过验证。
有了这个估计之后,DSpark 还需要决定每个请求本轮到底验证多长,也就是验证长度(verification length)。
过去比较直接的做法,是设置一个固定长度,或者根据静态阈值来决定。但在真实在线服务里,这不够。因为一个 token 是否值得验证,不只取决于它的置信度,还取决于当前系统负载。低负载时,目标模型还有空余计算能力,多验证一些高置信 token 可能划算;高负载时,batch capacity 更紧张,低置信 token 就应该尽早被剪掉。
因此,DSpark 引入了硬件感知前缀调度器(hardware-aware prefix scheduler)。它了解推理引擎的吞吐表现和当前系统负载,会结合两类信息:一类是 token 层面的前缀生存概率,另一类是系统层面的吞吐曲线(engine throughput profile)。然后,它为每个请求动态选择更合适的验证长度,把目标模型的验证预算分配给预期收益更高的前缀 token。
这一步的核心变化是:verification length 不再是一个固定超参数,而是一个随请求质量和系统负载变化的调度决策。
这里还有一个重要细节:置信度头的输出必须经过校准。如果模型给出的置信度只是“排序大致正确”,但概率本身不可信,调度器就可能误判。所以,DSpark 使用顺序温度缩放(Sequential Temperature Scaling)对置信度头的输出做后处理,让预测概率更接近真实接受率。这个设计说明,在生产系统里,置信度不只是一个辅助分数,而是会参与资源调度的决策信号,必须足够稳定、足够可信。
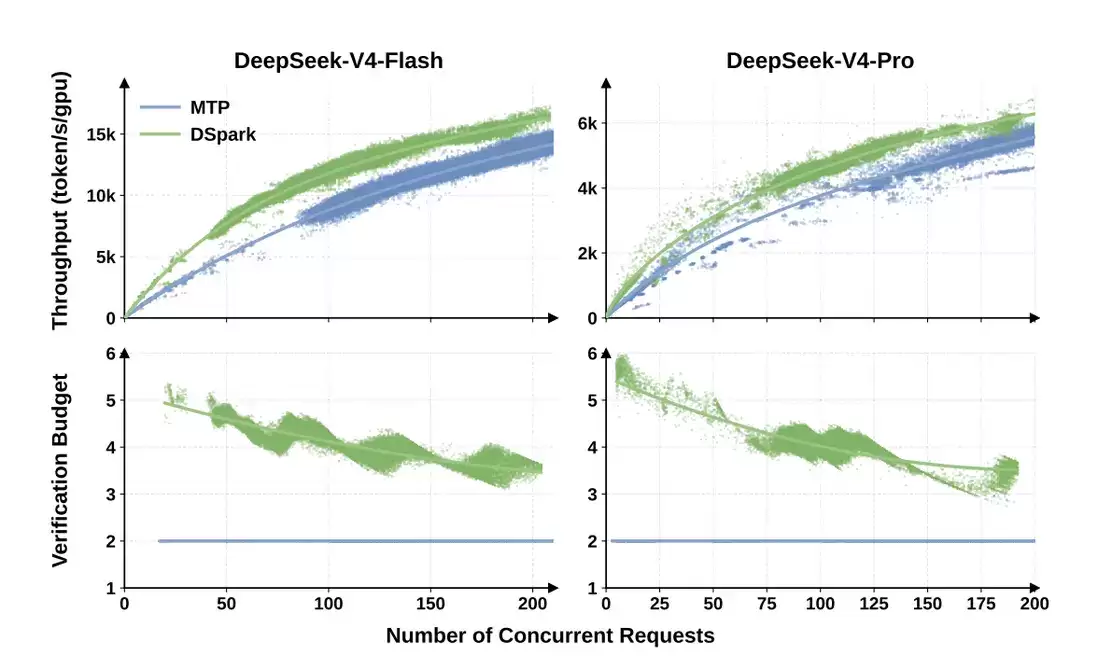
这张图展示了并发负载变化后,verification budget 如何变化。并发较低时,调度器会分配更长的验证预算;并发升高后,系统资源变紧,调度器会自动收紧验证长度。这就是 DSpark 在验证侧的工程取向:有空闲算力时,多验证高价值 token;系统压力变大时,减少低收益验证。
实验结果怎么看?
DSpark 的实验可以分成两部分来看:离线 benchmark 和线上生产部署。离线实验主要验证草稿质量——生成的草稿 token 是否更容易被目标模型接受;线上部署则验证系统价值——在真实流量和高并发环境下,能否改善吞吐和单用户生成速度之间的关系。两者回答的是不同问题。
离线实验:DSpark 的草稿更容易被接受
论文在 Qwen3-4B、Qwen3-8B、Qwen3-14B 和 Gemma4-12B 等目标模型上做了评估,任务覆盖数学推理、代码生成和日常聊天。对比对象包括 Eagle3(自回归草稿)和 DFlash(并行草稿)。DSpark 试图在两者之间取一个更适合在线服务的折中。
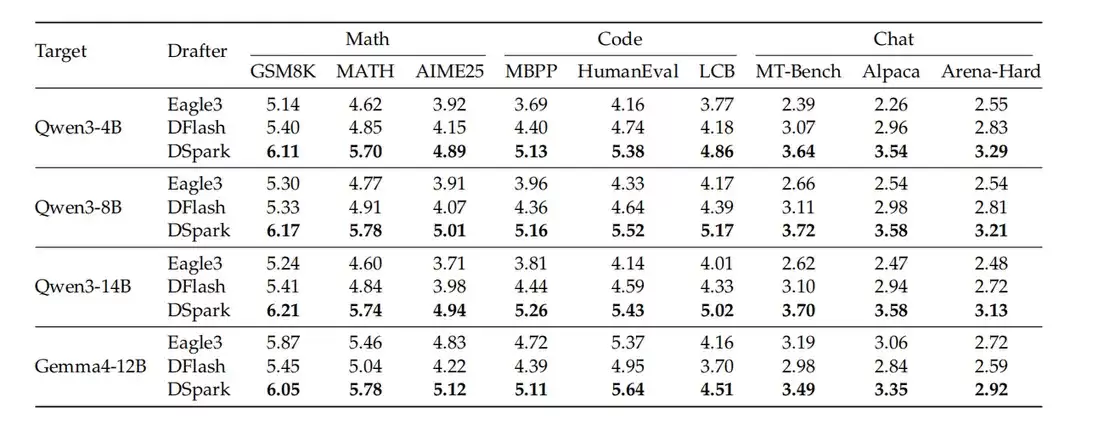
从表中可以看到,DSpark 的草稿 token 更容易被目标模型接受。论文称,在 Qwen3-4B、Qwen3-8B、Qwen3-14B 上,DSpark 相比 Eagle3 的宏平均 accepted length 分别提升 30.9%、26.7%、30.0%;相比 DFlash 分别提升 16.3%、18.4%、18.3%。这说明收益不是来自“生成更多 token”本身,而是来自“生成出来的 token 更容易被接受”。它确实缓解了并行草稿后缀不稳定的问题。
此外,不同任务之间的 accepted length 差异很明显。数学和代码这类结构化任务更容易获得较高 accepted length,而开放聊天任务更低。这不是简单的模型优劣问题,而是任务分布本身不同。这个结果也反过来支持了 DSpark 的第二个设计:verification length 不应该固定。
线上部署:改善了吞吐与交互速度的关系
更值得关注的是,DSpark 不只做了离线 benchmark,还被部署到了 DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 的生产级在线推理系统中,并与 MTP-1 baseline 对比。线上实验验证的不是“单个请求能不能更快”,而是整个系统在真实流量下,能否在系统吞吐和用户可感知速度之间取得更好的平衡。
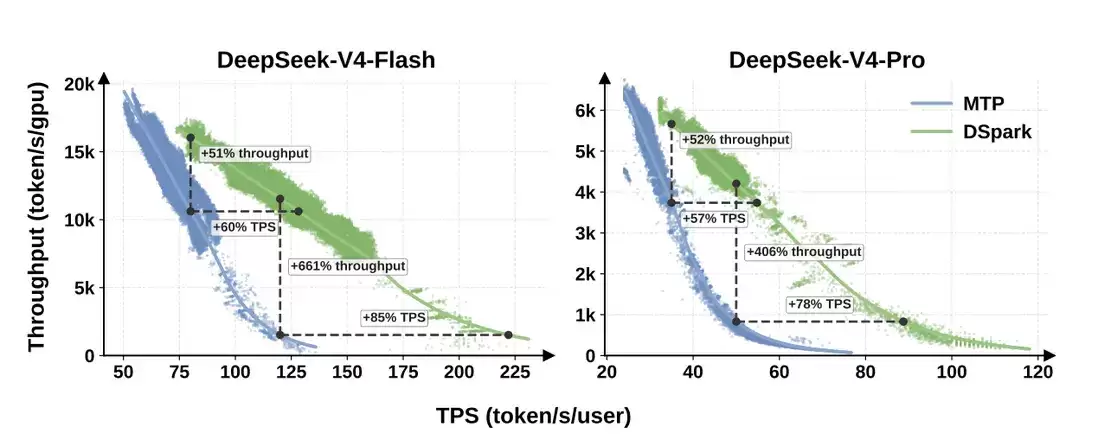
读这张图时,要同时看两个指标:throughput(系统整体吞吐,单位时间能输出多少 token)和 TPS/user(单个用户看到的生成速度)。真实服务中,这两个指标必须一起看。论文结果显示,在匹配吞吐水平下,DSpark 让 V4-Flash 的单用户生成速度提升 60%–85%,让 V4-Pro 提升 57%–78%。
这组数据的重点不是简单说“快了多少”,而是说明它改善了生产服务里的吞吐-交互速度边界(throughput–interactivity frontier)。在相同系统吞吐下,用户能看到更快的生成速度;在更高交互速度要求下,系统仍然能维持可用的并发能力。论文中有些严格 SLA 点上的相对提升比例非常高,但这需要谨慎理解。在严格 SLA 下,MTP-1 baseline 已接近能力边界,所以 DSpark 的相对提升比例会很大。更准确的理解是:DSpark 把系统原本难以达到的交互性区间往外推了一段。
之前的图也进一步解释了收益来源:并发较低时,调度器分配更长的验证预算;并发升高后,自动收紧验证长度,避免低置信 token 占用关键 batch capacity。这说明线上收益不是只来自“draft 更长”,而是来自 draft 质量和 verification 调度的配合。
这篇论文真正值得关注的地方
如果只看表面,DSpark 是一个 Speculative Decoding 框架。但从工程角度看,它的核心关注点在于:把大模型推理加速从单纯“生成更多 token”,推进到了“草稿质量 + 验证调度 + 系统负载”的联合优化。
过去我们容易把推理加速理解成一个模型问题:换一个更快的解码算法,或者设计一个更强的草稿模型。但 DSpark 说明,在真实生产级服务里,推理优化不只是模型结构问题,也是系统调度问题。
首先,草稿模型不能只追求快。它生成的 token 必须足够容易被目标模型接受,否则长草稿块只会带来更多无效候选。
其次,验证不能只追求长。目标模型的计算资源是在线服务里最关键的资源之一,尤其在高并发场景下,低置信 token 的验证会直接影响系统吞吐。
最后,调度策略必须理解系统负载。同一个 token,在低负载时可能值得验证,在高负载时就未必划算。
DSpark 给出的答案是:用半自回归生成提升草稿 token 的可接受性,再用置信度调度减少无效验证,把推理加速从单点生成优化推进到系统级资源调度。
当然,DSpark 也不是所有问题的最终答案。论文也提到,对于一些本身接受率较低、难度较高的请求,草稿侧的成本可能无法完全回收。未来仍然可以探索 difficulty-aware early exiting。这个限制也提醒我们:DSpark 的价值不在于提供一个“一劳永逸”的方案,而在于给出了一个生产级推理优化的样本——在高并发大模型服务中,生成速度、草稿质量、验证成本和系统负载,需要放在一起优化。
另外,这篇论文也提供了一个评估推理加速方案的判断框架:以后看一个推理优化方法,不能只看单请求的 token/s,也不能只看某个 benchmark 上的速度提升,更要看:
- 它生成的草稿 token 最后有多少真的被接受;
- 它是否减少了无效验证;
- 它在不同负载下是否还能维持系统吞吐;
- 它是否改善了用户可感知的生成速度;
- 它的收益是否在真实在线服务中成立。
这也是 DSpark 对理解生产级推理优化最有参考价值的地方。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:DeepSeek DSpark高并发推理服务Token高效生成优化要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在招聘这个行业中,数据录入的繁琐程度相信大家都有切身体会。每天需要从各类网页、社交平台、招聘站点中搜寻候选人信息,再手动一条条录入系统,既耗时费力又容易出错。今天要介绍的这款Kwal Chrome插件,正是为了彻底解决这一痛点而设计的。什么是 Kwal Chrome 扩展程序 插件?该插件的定位十分
网红经济正在进化——Twinning AI带来的玩法是:粉丝可以直接跟你的人工智能分身聊天,而你,每次互动都能收到真金白银。它集成了专业的声音克隆、文本和语音消息,以及数据分析能力,让粉丝互动变得既有趣又能变&现。 什么是Twinning AI? 简单来说,Twinning AI允许网红创建一个属于
在跨境电商和全球业务快速发展的今天,发票与财务管理工具的重要性日益凸显。AI技术的加入,让这些原本繁琐的流程实现了质的飞跃。Invoicemint 正是这样一款专注全球企业的智能发票与财务管理软件——它不只是一个简单的发票生成器,而是一套覆盖从开票、对账到税务合规、催款的全链路解决方案。 什么是In
想象一下,你随时都能找到一个倾听者——不带任何偏见,不会感到疲惫,而且完全匿名。这听起来像科幻小说里的情节,但现在已经成为现实。MyWhy 就是这样一款 AI 心理治疗应用,它将专业的情感支持装进你的口袋,让心理健康服务不再是奢侈品,而是像打开手机一样触手可及。什么是MyWhy?简单来说,MyWhy
- 日榜
- 周榜
- 月榜
热点快看