




RAG前置文档解析:AI落地的关键环节

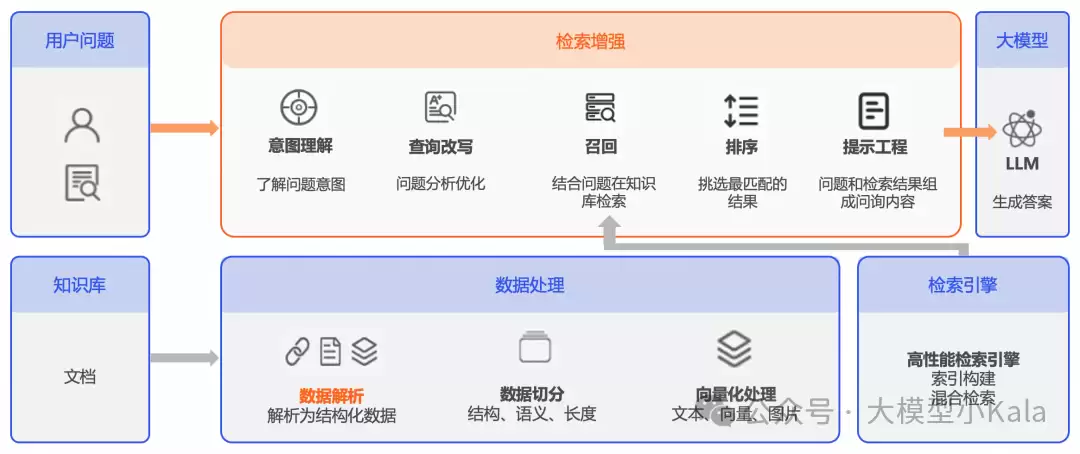
先给出核心结论:在构建RAG(检索增强生成)系统时,如何将那些杂乱的非结构化文档——如PDF、Word、邮件、图片——高效转化为系统可检索的结构化信息,这一步的处理质量直接决定了整个管线的上限。这远非简单的文本提取,而是对文档内容进行“拆解‑重组‑增强”的深度加工。以下展开详细讨论。 为何需要对非结
先给出核心结论:在构建RAG(检索增强生成)系统时,如何将那些杂乱的非结构化文档——如PDF、Word、邮件、图片——高效转化为系统可检索的结构化信息,这一步的处理质量直接决定了整个管线的上限。这远非简单的文本提取,而是对文档内容进行“拆解‑重组‑增强”的深度加工。以下展开详细讨论。
为何需要对非结构化文档进行解析
RAG系统的首要挑战,在于文档本身的“野性”。非结构化文档中既有纯文本,也包含表格、图表、页眉页脚、多级标题,甚至图文混排。若不经过解析,直接将整段文字丢给检索器,结果往往是:关键词虽能匹配,但上下文错乱,返回的片段无法拼接出完整语义。因此,解析的核心价值体现在以下四个维度。
提升检索精准度
结构化信息的提取是成败关键。将文档中的表格、图像等内容抽取出来,转化为标准的结构化数据(如JSON行、数据库记录),检索器才能实现精准定位。例如,一份PDF财报中的营收表格,若仅做全文检索,系统可能只捕获到“营收”一词,却无法理解表格的行列对应关系。解析后,表格变为行列清晰的结构,用户询问“2024年Q3营收是多少?”即可直接命中具体单元格。此外,保留文档的层次结构——标题、子标题、段落、列表——有助于模型理解片段间的父子关系,检索时不再“盲人摸象”。
强化生成质量
结构化信息为生成模型提供更丰富的上下文。例如,文档的树状结构能够通过层级关系告知模型:当前段落属于哪个章节,其前后文是什么,后续要讨论什么。这样在生成回答时,模型不易“断章取义”。同时,准确的解析能显著减少“幻觉”——即生成与原文矛盾或无关的内容。数据越干净、结构越清晰,模型越容易忠实于原文。
优化系统性能
更精准的解析意味着更高的召回率。检索阶段能够召回更多真正相关的片段,而非被噪声淹没。排序阶段同样受益:结构化数据可携带更多特征(如片段在文档中的位置、类型),便于进行更精细的相关性排序,确保排在前面的片段质量最高。
支持复杂查询
许多业务场景下的问题需要跨章节整合信息。例如,“某公司2024年研发投入比2023年增长了多少?”在散乱文本中需要分别找到两个年份的数据并计算。结构化的文档中每个数据点都带有来源标签,系统能够自动定位、提取、计算。在处理财务报告、法律文书、学术论文等密集非结构化文本时,像LlamaParse、spRAG这类专用工具能大幅提升准确性。
前置文档解析
好在Hugging Face生态中已有众多成熟的模型与工具,能够帮助我们完成“从非结构到结构”的转换。下面列举几个主流方案,各有侧重。
1. Unstructured
Unstructured是Python生态中非常全面的文档预处理库。它提供模块化流水线,用于处理PDF、HTML、Word等格式。核心思路是将非结构化数据转化为结构化的“元素”列表(如标题、段落、表格、列表),然后可进一步导出为DataFrame或JSON。需要注意的是,Unstructured依赖NLTK进行部分语言处理,下载语料包时可能需要手动操作。
2. PaperMage
PaperMage专注于学术PDF的解析。其处理分三步:首先用PDFPlumber提取纯文本,获取单词坐标,再根据相邻关系拼成行;然后对每一页进行光栅化,使用目标检测模型(efficientdet系列)识别图中的元素(表格、图片、公式等),得到带边界框的块;最后用基于LayoutLM的模型进行字符级标注,为每个单词打上标签(如“标题”、“作者”、“摘要”等)。这套流程对学术论文的版式适应性很强。
3. RAGFlow DeepDoc
RAGFlow的DeepDoc组件提供了一个灵活的文档切片模板引擎。它并非简单的固定长度分割,而是根据文档的实际结构(标题、章节)进行智能切片,适合不同业务场景下的检索需求。
4. unstructured-inference
这是Unstructured背后的推理模块,专门负责布局分析与OCR。它支持多种检测模型(Detectron2、YOLOX等),还能通过API与主unstructured包集成,实现端到端的文档解析流水线。
5. LangChain 文档加载器
LangChain作为框架,提供了丰富的文档加载器,底层大多依赖上述库。使用上直接调用API即可,下面是几个常见场景的代码示意(具体加载器名称与参数可根据版本调整):
# Word
from langchain.document_loaders import UnstructuredWordDocumentLoader
loader = UnstructuredWordDocumentLoader("example_data/fake.docx")
data = loader.load()
# PDF (基于Unstructured)
from langchain.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader("./example_data/layout-parser-paper.pdf", mode="elements")
docs = loader.load()
# PDF (基于PyPDF)
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
# PDF (基于PDFMiner)
from langchain.document_loaders import PDFMinerLoader
loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
# Email
from langchain.document_loaders import UnstructuredEmailLoader
loader = UnstructuredEmailLoader('example_data/fake-email.eml')
data = loader.load()
# 图片
from langchain.document_loaders.image import UnstructuredImageLoader
loader = UnstructuredImageLoader("layout-parser-paper-fast.jpg")
data = loader.load()
# Markdown
from langchain.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader(filepath, mode="elements", autodetect_encoding=True)
docs = loader.load()
# PPT
from langchain.document_loaders import UnstructuredPowerPointLoader
loader = UnstructuredPowerPointLoader("example_data/fake-power-point.pptx")
data = loader.load()
文档解析面临的难点
实际操作中,解析质量取决于文档本身的整洁度、版式复杂度、表格结构是否规整等因素。这部分挑战不小,值得单独开一篇深入探讨,此处先不展开。
文档解析后的——向量化(Embedding)
文档被解析为结构化的文本片段后,下一步就是向量化:将这些片段通过Embedding模型转化为高维向量,存入向量数据库,供后续语义检索使用。Hugging Face上对中文友好的Embedding模型不少,下面列出几个常用的(注意:模型下载若遇到网络问题,可通过镜像站解决,但为简洁此处不展开地址细节):
- bert-base-chinese:中文基础BERT,通用性强,适合分类、NER等任务,但需针对具体任务微调。
- uer/roberta-base-finetuned-cluener2020:针对CLUENER2020微调的RoBERTa,擅长中文命名实体识别。
- hfl/chinese-bert-wwm-ext:全词掩码预训练的中文BERT,迁移至NER等任务效果不错。
- hfl/chinese-roberta-wwm-ext:与上类似,性能略高。
- WENGSYX/Deberta-Chinese-Large:基于微软Deberta,在中文语料上预训练,提供更多选择。
- google-bert/bert-base-multilingual-cased:多语言BERT,支持104种语言,包括中文。
- FacebookAI/xlm-roberta-base:XLM-RoBERTa,支持100种语言,适合多语言文本分类等。
选择哪个模型取决于你的任务场景。若仅做语义相似度检索,使用sentence-transformers系列模型可能更直接(例如paraphrase-multilingual-MiniLM-L12-v2)。若后续还需进行实体识别或分类,上述预训练模型是理想之选。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:RAG前置文档解析:AI落地的关键环节要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看