




Harbor与LangChain构建智能体评测统一技术栈

核心要点 Harbor 只需一个轻量级入口点即可接入 agent:编写一个 langgraph json 注册文件,加上一个 make_graph 工厂函数,这就是唯一需要的“胶水代码”。该工厂函数可读取 Harbor 从命令行传入的模型参数,从而保持模型无关性。 云端沙盒让评估能够水平扩展,并为
核心要点
- Harbor 只需一个轻量级入口点即可接入 agent:编写一个
langgraph.json注册文件,加上一个make_graph工厂函数,这就是唯一需要的“胶水代码”。该工厂函数可读取 Harbor 从命令行传入的模型参数,从而保持模型无关性。 - 云端沙盒让评估能够水平扩展,并为 agent 提供隔离的运行环境。每次试验(trial)都会获得一个全新的 LangSmith 沙盒,各次试验之间互不共享状态。您可以并行运行上百次试验,而无需在一台机器上逐个串行处理。
- 追踪(Traces)将评分转化为可解释的答案。借助
langsmith插件,每次作业(job)都会以数据集和实验(experiment)的形式落地,验证器的奖励值(reward)作为反馈,agent 的追踪信息也直接关联。这样您不仅知道一次试验是否通过,还能理解它通过或失败的原因。
随着 agent 功能日益强大,评估难度也随之显著提升。像 Claude Code、Pi 和 Deep Agents 这样的 agent 框架,现在赋予 agent 访问整台计算机的权限——它们可以读取文件、执行脚本、运行代码等。每个 agent 在完成特定任务时,都需要一个干净、可复现的专属环境。
评估那些运行时间长、拥有状态的 agent,需要一种全新的评估运行器(eval runner)。在这一领域,Harbor 已经成为行业标杆。本文首先解释为什么每个进行 agent 评估的人都应该了解 Harbor,然后展示如何将 Deep Agents、LangSmith 沙盒和 LangSmith 实验(Experiments)集成到 Harbor 中。
最终目标很明确:我们需要在真实、可复现、隔离的环境下并行运行多个 agent,并在最后进行确定性检查。Harbor 恰好解决了这个问题,并且它现已直接与 Deep Agents、LangSmith 沙盒和 LangSmith 可观测性(Observability)平台打通。
Harbor 的工作原理
Harbor 本质上是一个评估框架(eval harness)。您需要提供三样东西:
- 您的 agent
- 您的数据集
- 您的沙盒
每个数据集包含多个任务,每个任务由以下几部分组成:
- 环境(Environment):Dockerfile 或 Docker Compose YAML 文件
- 指令(Instruction):Markdown 格式
- 评估脚本(Evaluation script):test.sh
与简单的 LLM 评估相比,这里有两个关键不同:
- agent 运行的环境至关重要——重要到需要将其作为任务的一部分明确指定。简单的 LLM 评估不需要环境,直接调用 LLM 即可;但 agent 需要!
- 对 agent 的评判通过脚本来完成。agent 常常会产生其他文件,或以某种方式修改状态。仅仅看 agent 的最终回复是不够的,您需要审视它在执行过程中创建的所有产物。
LangChain 在三个层面与 Harbor 集成。我们与 Deep Agents 打通,因此您构建的任何深度 agent 都可以在 Harbor 的沙盒化环境中运行。我们与 LangSmith 沙盒打通,使得 Harbor 可以为每个任务在一个 LangSmith 沙盒中运行,让每次 run 都拥有自己独立的干净机器。我们与 LangSmith 可观测性平台打通,这也是您可以查看详细结果的评估平台:每次 job 都会以一个数据集和实验的形式落地,如果 agent 支持,还会附带上完整的 agent 追踪信息。
统一 LangChain agent 与 Harbor
要接入 Harbor,您通过其内置的 langgraph agent 类型(使用 --agent langgraph 参数)来插入自定义 agent。这可以运行任何 LangGraph 应用,包括 Deep Agents。
Harbor 将 langgraph.json 视为一个注册中心。它列出了您 agent 所需的依赖,并将一个图(graph)的名称映射到构建该图的函数:
{
"dependencies": [
"deepagents>=0.6.10,<0.7.0",
"langchain-fireworks>=1.3.1,<1.4.0"
],
"graphs": {
"deep_agent": "./agent.py:make_graph"
}
}
这里,deep_agent 指向 agent.py 文件中的 make_graph 函数,该函数负责构建您的 Deep Agent 并返回编译好的图,Harbor 随后会调用它:
from deepagents import create_deep_agent
from deepagents.backends import LocalShellBackend
def make_graph():
return create_deep_agent(
model="fireworks:accounts/fireworks/models/glm-5p2",
backend=LocalShellBackend(),
)
这是您唯一需要编写的“胶水代码”。您的 agent 仍然是您的代码;make_graph 只是 Harbor 调用的入口点。默认情况下,create_deep_agent 会将文件保留在内存中的虚拟文件系统里,不会触及沙盒。因此,将其与 LocalShellBackend 配对,可以让 agent 访问 Harbor 运行环境中的真实文件和 Shell。
对于每一次试验,Harbor 都会将这个 agent 复制到该试验的沙盒中,在沙盒内安装 langgraph.json 中列出的依赖到一个全新的虚拟环境,然后在容器中运行这个图。每个沙盒都有自己独立的一份拷贝,因此各次试验之间不会有状态共享,您的 agent 在完全隔离的环境中运行。
补充一点: 图可以硬编码模型,但入口点也可以是一个工厂函数,Harbor 会带着运行配置(run config)来调用它。Harbor 会把通过 --model 参数选择的模型放入 configurable.model 中,因此上面的工厂函数可以保持模型无关,您从命令行传入的任何模型都会被直接传递给 create_deep_agent。
from deepagents import create_deep_agent
from deepagents.backends import LocalShellBackend
def make_graph(config):
return create_deep_agent(
model=config["configurable"]["model"],
backend=LocalShellBackend(),
)
统一 LangSmith 沙盒与 Harbor
在基于云的沙盒中运行评估,可以让您水平扩展,从而获得更快的反馈——可以同时跑数百次试验,而不是在一台机器上挨个串行处理。而且,沙盒是一个受限的执行环境,这正是一个长时间运行、会与环境交互的 agent 所需要的:一个干净、隔离的场所,让 agent 自由行动,同时不会影响外部环境。
每次试验都在自己独立的云端沙盒中运行。您使用 LangSmith 沙盒(通过 -e langsmith 参数选择),但环境是可插拔的。Harbor 也支持 Daytona、Docker、Modal 和 E2B 这些提供方,它们都可以通过同一个 -e 参数互换。切换提供方不会影响您的 agent、数据集或验证器。
一次试验(trial) 是工作的原子单元:您的 agent 在一个任务上的一次运行。由于 agent 是非确定性的,您通常需要对每个任务运行多次。n_attempts 参数决定了 Harbor 对每个任务重复运行的次数,然后对所有分数取平均值,这样就不会因为单次幸运或不幸的运行而定义最终结果。您的整个作业(job) 因此等于 n_attempts × tasks:每个任务运行 n_attempts 次,每次重复都是一次独立的试验。Harbor 负责编排这一切。
对于每一次试验,Harbor 会配置一个新的沙盒,并把该次运行所需的一切都复制进去:您的 agent 代码、任务(先缓存到磁盘,再加载到沙盒虚拟机中)、以及运行所需的任何初始文件。然后,Harbor 会运行 agent 来处理指令,运行验证器,并记录结果。Harbor 对多次试验的结果取平均值,最终形成包含了您所关注指标的作业结果。
统一 LangSmith 可观测性平台与 Harbor
harbor-langsmith 集成将对 LangSmith 追踪的一流支持带入了 Harbor,同时还包括将日志记录到数据集和实验的功能。
只需一个参数 --plugin langsmith,即可启用。之后,Harbor 会将每次作业记录到 LangSmith:它会同步数据集、创建实验,并为每次试验记录一次 run,同时将验证器的奖励值作为反馈。如果被测试的 agent 支持 LangSmith 追踪,这些追踪信息会直接关联到实验中——因此,您不仅能拿到分数,还能看到完整的、一步步的执行轨迹。即使 agent 不进行追踪,您仍然可以获得数据集、实验、结果和反馈。
在“数据集与实验”(Datasets & Experiments)页面中,我们可以查看所有正在使用的有效数据集。
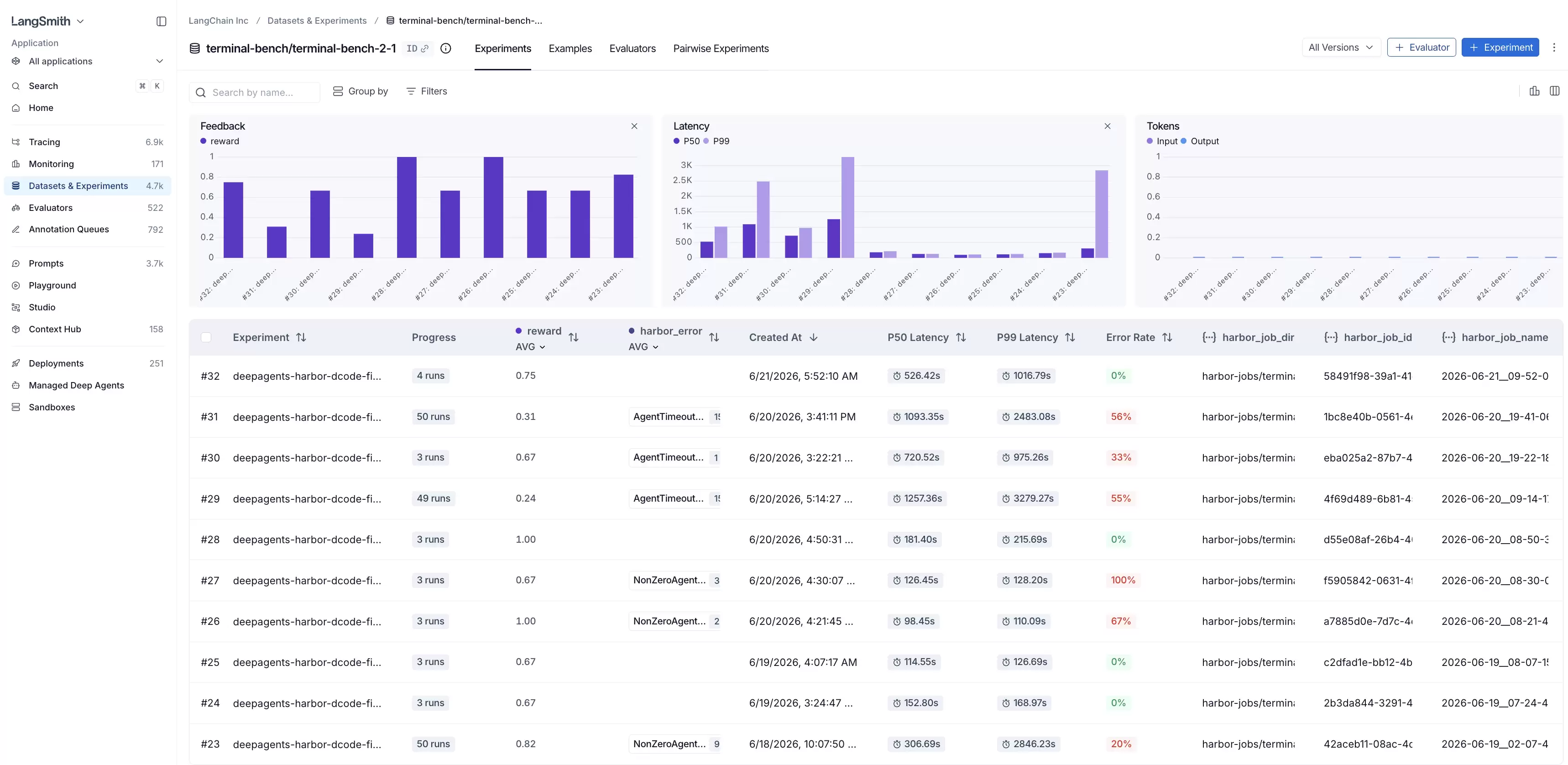
一个实验(experiment)是对一个给定数据集进行的一次完整运行。要查看特定数据集对应的具体实验及其分数和统计数据,点击进入即可。
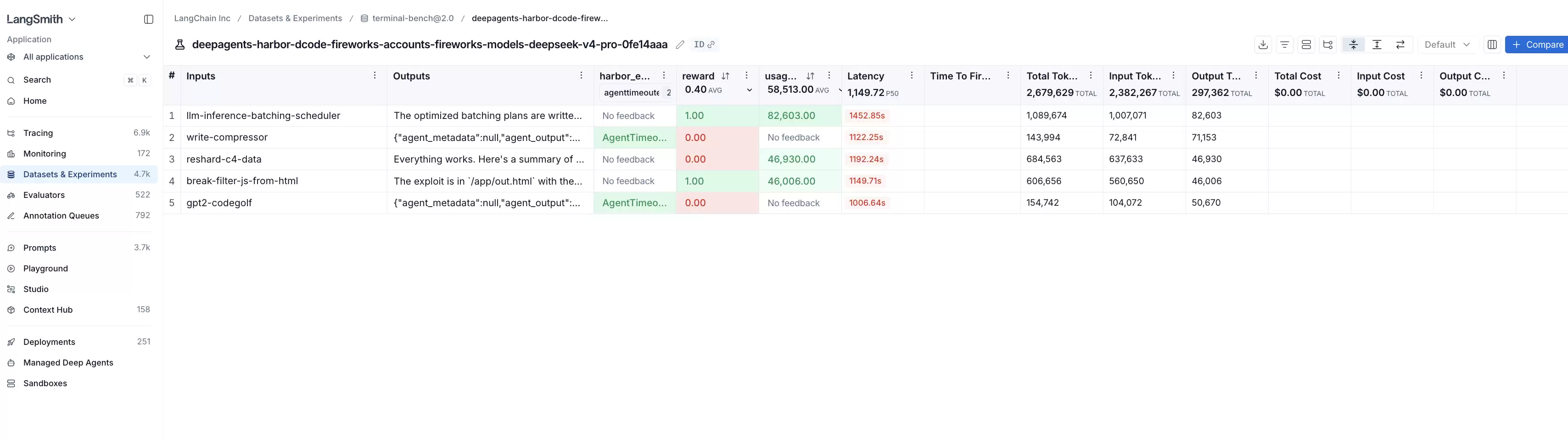
我们认为,将追踪信息整合到评估中,可以让您进一步优化评估方法,从而更好地理解和改进您的 agent。评分告诉您一次试验是否通过;而追踪信息告诉您它为什么通过或失败。
最终成果:一套完整的 agent 评估栈
综合来看,这是一个评估 agent 的完整技术栈,每一层都各司其职:
- Harbor —— 编排试验的评估框架。
- Deep Agents —— 用于构建被测的 agent。
- LangSmith 沙盒 —— 隔离的云端执行环境。
- LangSmith —— 数据集、实验、追踪信息和评分的记录系统。
而您只需要自己准备的部分,其实很少:
- 您的 agent —— 带不带追踪都可以。
- 您的数据集 —— 可以从远程注册中心获取,也可以来自本地磁盘。
- 您的云端沙盒 —— 使用 LangSmith,通过
-e langsmith指定。 - 您的 UI 视图 —— 通过
--plugin langsmith启用。
如果您已有 LangSmith 账户和数据集,那么安装带有 langsmith 扩展的 Harbor,就可以立刻体验整套流程。这个扩展同时包含了 LangSmith 沙盒环境和评估插件。然后设置好您的 LangSmith 和模型凭据,开启追踪功能,这样 agent 的追踪信息就会关联到实验上:
pip install "harbor[langsmith]"
export LANGSMITH_API_KEY=""
export LANGSMITH_PROFILE=prod
export LANGSMITH_TRACING=true
export LANGSMITH_PROJECT=harbor-deepagents
export FIREWORKS_API_KEY=""
harbor run \
--agent langgraph \
--model fireworks:accounts/fireworks/models/glm-5p2 \
--ak project_path=./deep-agent \
--ak graph=deep_agent \
-d terminal-bench@2.0 \
-e langsmith \
--plugin langsmith
阅读 Harbor 集成文档可以快速上手。想了解更多在 Harbor 中运行评估的细节,可以参考“运行评估”(Run evals)文档。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Harbor与LangChain构建智能体评测统一技术栈要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点RAG落地的关键在于数据检索而非大模型。直接大模型、微调与RAG各有适用场景。检索效果受分块粒度、排序策略及混合检索影响。常见误解包括认为RAG总是更优、简单余弦检索足够、更多文档效果更好。应注重数据质量,采用渐进式部署和用户反馈闭环。
微软推出AutoGenStudio低代码工具,业务人员可通过可视化拖拽组装模型、技能和记忆组件,构建智能体工作流。工具集成实时监控、调试评估功能,支持导出JSON配置文件进行部署,降低开发门槛。
英国国民保健署正将人工智能引入医疗体系,智能手机可居家监测肾脏疾病,穿戴贴片实时捕捉心律不齐,AI加速乳腺癌筛查分析。这些技术有望改善筛查、癌症治疗和中风护理,但全面应用仍需长期推进。
近年来,人工智能、云计算与大数据无疑是科技领域最受瞩目的三大趋势。其中,人工智能技术已深入渗透到各行各业,成为名副其实的核心驱动力。其背后的原因并不难理解——它不仅能带来实实在在的效益,更关键的是,正大力推动制造业向智能化方向转型升级。 众多学者同样对人工智能的发展前景给予了高度评价。他们认为,未来
- 日榜
- 周榜
- 月榜
热点快看