




SkillOpt 助力 AI 智能体技能资产化训练

At a glance AI袋里经常失败,因为它们的指令(或称技能)被人为修改,却无法保证改进效果。SkillOpt将技能编辑转变为训练过程,在不改变模型权重的前提下,让袋里行为更可靠。 SkillOpt把袋里的技能文件视为一个可训练的参数,它存在于冻结的目标模型之外,从而将技能编写从一次性提示变成
At a glance
- AI袋里经常失败,因为它们的指令(或称技能)被人为修改,却无法保证改进效果。SkillOpt将技能编辑转变为训练过程,在不改变模型权重的前提下,让袋里行为更可靠。
- SkillOpt把袋里的技能文件视为一个可训练的参数,它存在于冻结的目标模型之外,从而将技能编写从一次性提示变成受控的优化流程。
- 在六个基准测试、七个目标模型和三种执行模式下,SkillOpt在全部52个评估单元中均取得最佳或并列最佳的性能,且无需更新模型权重。
- 通过有界文本编辑、验证门控、被拒编辑反馈以及慢速/元更新机制,SkillOpt让技能保持紧凑且可审计,避免了失控的提示漂移。
- 优化后的技能可以跨模型规模、袋里框架和相关任务进行迁移,这说明它们捕获的是可复用的工作流知识,而非针对特定基准测试的指令。
大型语言模型(LLM)作为袋里的应用越来越广泛,它们需要收集证据、调用工具并执行多步骤任务。对于这些袋里来说,核心难题已经不再是是否能够调用某个工具,而是能否可靠且一致地完成任务。目前,袋里技能主要来自三个渠道:专家手动编写、前沿模型一次性生成,或者袋里在执行后自行修订。但这些方式没有一种能像深度学习优化器那样工作——它们缺乏步长控制、没有独立的验证集,也不记录那些失败的修订。结果就是,每次改写都让技能变得更长、更容易跑偏,一个看似合理的修订,可能会悄悄拖垮实际任务的性能。这种不受控的技能演化,已经成为从袋里原型迈向可靠生产级部署的主要绊脚石。
在近期发表的研究论文《SkillOpt: Executive Strategy for Self-Evolving Agent Skills》中,我们把问题从“如何写出更好的提示词”重新定义为“如何训练技能本身”。SkillOpt把技能文件视为一个可训练的参数,它存在于冻结的目标模型之外,因此可以引入训练式的优化循环。实验结果显示,它在52个评估单元上取得了持续的性能提升,并且最终生成的是一个紧凑、可读、可审计且易于迁移的技能文件。
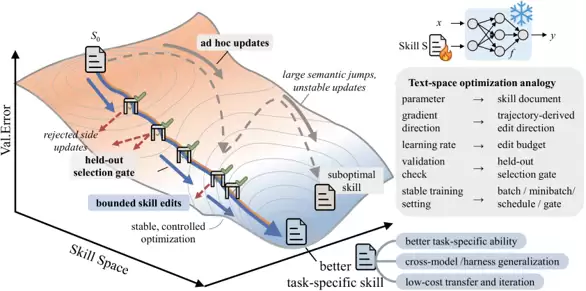
SkillOpt 是如何工作的
SkillOpt将整个技能编辑过程组织成一个在文本空间中的“前向—反向—更新”循环。在前向传播阶段,冻结的目标模型使用当前的技能去执行一批训练任务;批次大小控制着每次更新所依据的证据量。在反向传播阶段,一个独立的优化器模型以反射迷你批次的方式读取这些执行轨迹,从中提炼出需要保留的成功模式,以及需要修正的失败模式。
在更新步骤中,优化器会提出小的添加、删除和替换编辑操作。这些候选编辑会被合并、去重、排序,并通过一个“文本学习率”——即每步的编辑预算——进行裁剪。每个候选技能随后都必须通过严格的验证门控:只有它在独立的验证集上取得比当前技能严格更高的分数,才会被采纳。被拒绝的编辑也不会被丢弃,而是进入一个被拒编辑缓冲区,作为该Epoch内后续优化器调用的负反馈。此外,在更慢的节奏上,还有一个Epoch级的慢速/元更新机制,用于整合单批次数据无法揭示的长期经验教训(图2)。有界编辑、验证门控以及最优版本选择这三者共同作用,确保技能优化过程可控、可审计,最终使技能收敛而非漂移。
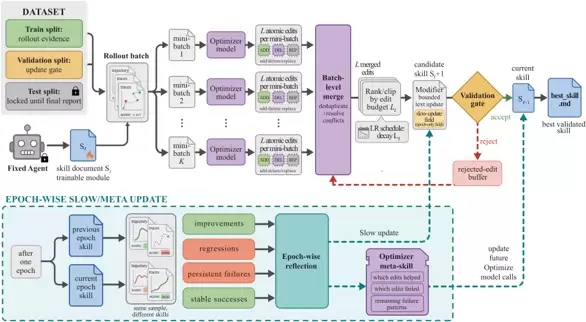
跨基准测试、模型和执行模式的持续性能提升
我们在六个基准测试(SearchQA、SpreadsheetBench、OfficeQA、DocVQA、LiveMathematicianBench 和 ALFWorld)、七个目标模型(从前沿的 GPT-5.5 到小规模开源模型 Qwen3.5-4B)以及三种执行模式(直接聊天、Codex 和 Claude Code)上评估了 SkillOpt。把每个组合算作一个评估单元,与人工编写的技能、一次性生成的 LLM 技能、Trace2Skill、TextGrad、GEPA 和 EvoSkill 相比,SkillOpt 在全部 52 个单元上都取得了最佳或并列最佳的结果。对于一个不更新任何模型权重的方法来说,这些性能提升的幅度非常可观。以 GPT-5.5 直接聊天模式为例,SkillOpt 将六个基准测试的平均分从 58.8 提升至 82.3,绝对值提升了 23.5 分——甚至比“神谕”方法(即从每个单元中挑选出最好的单一对比方法)还高出 5.4 分。最大的提升出现在流程性基准测试上:SpreadsheetBench 从 41.8 升至 80.7,OfficeQA 从 33.1 升至 72.1,LiveMathematicianBench 从 37.6 升至 66.9。同样的机制也适用于袋里循环,在 Codex 框架内,GPT-5.5 的性能(相对于无技能基线)提升了 24.8 分,在 Claude Code 框架内提升了 19.1 分。
小模型 + 技能文件 = 强大的组合
更进一步,SkillOpt 还能缩小小规模或开源模型与前沿模型之间的差距——全程无需改变任何权重,也不需要在推理时增加额外的模型调用。经过优化后,GPT-5.4-mini 的六个基准测试平均分(64.3)已经超过了更大版本 GPT-5.4 的无技能基线(59.7);GPT-5.4-nano(57.4)则超过了 GPT-5.2 的无技能基线(51.3)。而仅有 40 亿参数的开源模型 Qwen3.5-4B,其表现也超越了 GPT-5.2 的无技能基线。过去需要通过换用更大模型才能获得的性能提升,现在一个优化后的技能文件就能近似实现。
可迁移的技能:一次训练,处处复用
优化后的技能文件捕获的是一套可复用的任务解决流程,而不是针对单一模型、基准测试或执行环境过度拟合的指令。这正是为什么同一个技能在跨模型规模、跨袋里框架甚至跨相关任务迁移时,仍能带来性能提升的原因。在迁移实验中,技能在跨模型规模、跨执行框架以及迁移到相近的数学基准测试时,都持续展现了改进效果。最明显的例子是跨框架迁移:一个在 Codex 内训练的电子表格技能,不做任何进一步优化,直接放入 Claude Code 框架,将无技能基线从 22.1 猛升至 81.8,提升了 59.7 分——甚至略高于直接在 Claude Code 内训练取得的 80.4 分。由于这两个框架暴露出的工具接口不同,这个结果强烈表明,SkillOpt 学习到的是通用的工作流程逻辑,而非仅仅针对特定框架的策略。
紧凑、可读,且仅由少量被接受的编辑构成
最终生成的产物 best_skill.md,既不是晦涩难懂的参数块,也不是持续膨胀的日志文件。在六个案例研究中,最终技能文件长度的中位数大约只有 920 个 token。而且,由于验证门控拒绝了绝大多数提案,最终文件中仅包含一到四个被接受的编辑。例如,OfficeQA 上 39.0 分的巨大提升,就仅仅源于一个被接受的编辑。这些学到的规则读起来就像资深从业者的经验之谈。模块消融实验也证实了这些控制机制的作用:移除被拒编辑缓冲区会导致三个消融基准测试的分数全部下降;而同时移除元技能和慢速更新,则让 SpreadsheetBench 的得分从 77.5 骤降至 55.0。
面向袋里时代的新型适配层
SkillOpt 为领域适配袋里提供了一条更轻量级的路径:团队无需微调模型权重、硬编码任务逻辑或手动调优提示词,而是可以训练一个小巧、可版本化、可审计的自然语言技能层——只要有自动评估机制或可靠的验证器存在即可。通过将学习率、调度策略、验证集、被拒绝样本以及慢速更新这些训练机制引入袋里技能领域,SkillOpt 证明了训练不必局限于模型权重。模型之外的流程性知识同样可以被优化。当这个流程受到控制、验证并被记录下来时,一个自然语言技能文件就能成为连接前沿模型能力与真实世界工作负载之间一个稳定、可迁移且可逆的适配器。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:SkillOpt 助力 AI 智能体技能资产化训练要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点一加Turbo6X开售,含标准版与Pro版,起售价1499元,国补价1274 15元。搭载天玑7360SUPER和7400SUPER,144Hz屏,7000 8000mAh电池,主打长续航高性价比。
蔚来汽车近日上市了2026款ET5、ET5T和EC6的冠军纪念版车型。新车主打赛道竞速设计风格,提供专属外观内饰与智能座舱主题。最大的亮点在于推出了BaaS电池租用方案,ET5 ET5T租电版起售价20 5万元,EC6租电版起售价26 5万元,大幅降低了购车门槛。车辆在底盘方面进行了针对性调校,提升
微软射击游戏《战争机器:E-Day》公布PC配置要求,将于2026年10月发售。配置清单引人注目地将尚未发布的RTX5050和RX9060显卡列为最低要求,同时兼容多款现有中端显卡。游戏需130GB固态硬盘空间,最低要求12GB内存和六核CPU。官方未明确对应画质与帧数,但推测将依赖超分辨率技术
软科近日发布2026年中国大学专业排名,覆盖1132所高校的3万余个专业点。排名显示,北京大学以93个A+专业位居榜首,清华大学和哈尔滨工业大学分列二、三位。榜单同时引入“A+专业精度”指标,中国人民公安大学以93 8%的精度领先。此外,北京大学、吉林大学、武汉大学在上榜专业总数上位列前三。该排名从
- 日榜
- 周榜
- 月榜
热点快看