




腾讯快思考模型的API调用成本不足深度求索一半

最近腾讯元宝的动作确实不小——先是多款产品接入了 DeepSeek,又推出了自研的混元 T1 模型,还在推广上猛发力,一度超越了字节的“豆包”,登上了中国区 App Store 免费榜第二。更不用说,它还入驻了微信生活服务的“九宫格”。在一片“深度思考”模型的热潮中,腾讯混元却“反常”地推出了一款主
最近腾讯元宝的动作确实不小——先是多款产品接入了 DeepSeek,又推出了自研的混元 T1 模型,还在推广上猛发力,一度超越了字节的“豆包”,登上了中国区 App Store 免费榜第二。更不用说,它还入驻了微信生活服务的“九宫格”。在一片“深度思考”模型的热潮中,腾讯混元却“反常”地推出了一款主打快思考的模型——Turbo S。
2月27日,腾讯混元自研的快思考模型 Turbo S 正式发布,目前已在腾讯云和元宝上线。与 DeepSeek R1、混元 T1 这类需要“想一下再回复”的慢思考模型不同,Turbo S 主打“秒回”。它的吐字速度提升了一倍,首字时延降低了 44%,在知识、数理、创作等方面也有突出表现。更关键的是,架构上的创新让部署成本大幅下降,进一步拉低了应用门槛。
有研究表明,人类约 90%—95% 的日常决策依赖直觉。快思考就像人的“直觉”,为大模型提供了通用场景下的快速响应能力;而慢思考更接近理性思维,通过逻辑分析来解决问题。两种能力的结合与补充,才能让大模型变得更智能、高效。
据介绍,通过长短思维链的融合,Turbo S 在保持文科类问题快思考体验的同时,借助自研混元 T1 慢思考模型合成的长思维链数据,显著改进了理科推理能力,整体效果得到了提升。作为旗舰模型,Turbo S 未来将成为腾讯混元系列衍生模型的核心基座,为推理、长文、代码等衍生模型提供基础能力。基于 Turbo S,通过引入长思维链、检索增强和强化学习等技术,腾讯自研了推理模型 T1,该模型已在腾讯元宝上线。用户可以在元宝中选择 Hunyuan 模型,点亮 T1 即进入深度思考,不点亮则使用 Turbo S。
开发者和企业用户已经可以通过腾讯云 API 调用 Turbo S,即日起一周内免费试用。定价方面,Turbo S 输入价格为 0.8 元/百万 tokens,输出价格为 2 元/百万 tokens,相比前代混元 Turbo 模型下降了数倍,是 DeepSeek API 成本的 1/2 到 1/4。团队甚至调侃说“比大模型界的拼多多还便宜”。另外,混元满血 T1 将在 3 月初发布。
在 3 月 2 日的腾讯混元直播中,专家团队对这次推出的快思考模型做了详细解读。极客公园整理了重点,下面逐一展开。
为什么要做“快思考”?
团队在分析中发现,用户大约 90% 的请求,都可以依靠大模型的“直觉”——也就是快思考模型——快速、精准地给出答案,根本不需要深度思考。而对于剩下的约 10% 的请求,才需要模型进行深度思考甚至反思,才能给出更精准的回答。快思考不仅成本更低,还具备强大的数据融合能力,能够融入 MySQL 模型或 Max 模型中的优质数据。Turbo S 借鉴了慢思考模型 Hunyuan T1 的数据,通过一种称为长思维链合成的技术进行训练,帮助模型在保持速度优势的同时,学会处理多步骤推理问题。这样一来,那 10% 需要反复反思的问题,也能得到比较精准的答案。
技术解析:模型架构与工程优化
在业界通用的多个公开 Benchmark 上,Turbo S 在知识、数学、推理等多个领域,展现了对标 DeepSeek V3、GPT-4o、Claude 3.5 等领先模型的效果。
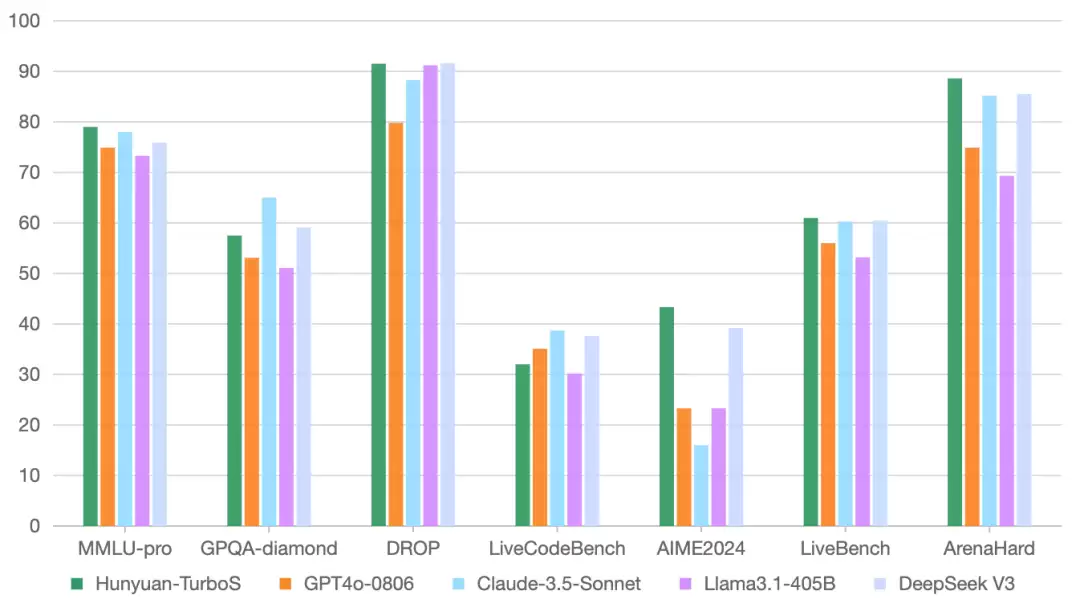
架构层面,Turbo S 创新性地采用了 Hybrid-Mamba-Transformer 融合模式,有效降低了传统 Transformer 结构的计算复杂度,减少了 KV-Cache 缓存占用,实现了训练和推理成本的下降。
传统 Transformer 架构存在几个明显的短板:计算复杂度高,序列维度呈平方级关系;推理时需要 KV-Cache,且随着序列长度增加而线性增加,部署成本居高不下;预测时的时间成本高,每步预测叠加 KV-Cache 后与序列长度呈线性关系,越往后生成越慢。相比之下,Mamba 这类线性 Attention 机制,每步预测都是 O(1) 复杂度,因此行业也在探索更高效的 attention 方案,比如 window attention、mobile、NSA 等,本质都是通过不同方式压缩计算复杂度。
Hybrid-Mamba-Transformer 融合架构是 Turbo S 的一项突破性创新。Mamba 是一种状态空间模型(SSM),专为高效处理长序列设计,内存使用更节省。与 Transformer 不同,后者在处理长文本时会遇到 KV-cache 内存的平方级扩展问题,而 Mamba 可以在不产生过多计算开销的情况下处理更长的文本,特别适合阅读、总结和生成长文档的回答(比如法律文本、研究论文)。当然,Mamba 高效,但在捕捉复杂的上下文关系上不如 Transformer。Transformer 擅长理解复杂的模式和依赖关系,特别适合推理密集型任务,比如数学运算、逻辑推理和问题解决。
Turbo S 首次将 Mamba 应用到了超大规模 MoE 模型(专家混合模型)中。MoE 通过每次查询激活一部分参数来提高计算效率,在保持精度的同时,既用上了 Mamba 的高效性,也保留了 Transformer 在推理任务中的优势。这一突破不仅降低了训练和推理成本,还提升了速度和智能水平。
算法上的独特之处
核心在于长短思维链的融合。对于需要反复推理反思的问题,通过融合长链数据,模型也能给出更精准的答案。具体来说,T1 模型可以得到相对长的思维链数据,将这些长链数据和短链数据融合训练后采样,采样依据正确性和长度正确性,采用规则方法和滤波 model case,从而提升模型的整体能力。尤其在数学、代码、逻辑等强推理任务上,表现更为突出。而短链模型本身体验更佳,融合长链后,推理能力也上了一个台阶。
Scaling Law 还没结束
GPT-4.5 是短链模型的天花板,但 API 成本极高,以百万 tokens 计算约为 150 美元,大约是 Turbo S 成本的 500 倍。而且根据推测,GPT-4.5 的激活参数量已达到万亿级别。从这个角度看,Turbo S 这类快思考模型的出现,正是为了在保证响应速度的同时,降低成本并保持较好的性能。
无论是模型 size 的 scaling,还是训练数据的 scaling,目前 scaling law 远未结束。现在中文互联网上可获取的数据量,各家相差不大,谁能通过获取或合成方式获得更多数据量,是模型性能的关键。标注数据方面,更专业的标注团队对模型表现影响很大——比如小说创作、医疗方向,拥有更专业标注团队和数据的模型,表现会更好。总的来说,在数据、算法、算力工程优化等方面,对 scaling 的探索都远未结束。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:腾讯快思考模型的API调用成本不足深度求索一半要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看