




AI短剧音画同步技术拆解口型匹配语速控制与字幕对齐

一条短剧跑了两天,画面终于出来了,导入剪辑软件放第一遍的时候——角色嘴闭上了,配音还在念词。 那一刻的心情,做短剧的创作者应该都懂。 画质不够好,观众最多说一句“AI感重”。但音画不同步,观众看 10 秒就会划走。平台算法看到跳出率高,后续推荐直接砍半。 这不是某一个模型的锅,也不是某一个环节的坑。
一条短剧跑了两天,画面终于出来了,导入剪辑软件放第一遍的时候——角色嘴闭上了,配音还在念词。
那一刻的心情,做短剧的创作者应该都懂。
画质不够好,观众最多说一句“AI感重”。但音画不同步,观众看 10 秒就会划走。平台算法看到跳出率高,后续推荐直接砍半。
这不是某一个模型的锅,也不是某一个环节的坑。所以,想把音画同步做好,真不是搞定某一环就行的,得从每个环节下手,一点点抠。
一、问题到底出在哪
先不谈解法,把问题定位清楚。其实掰开来看,真正造成音画不同步的原因,主要有三个层面。
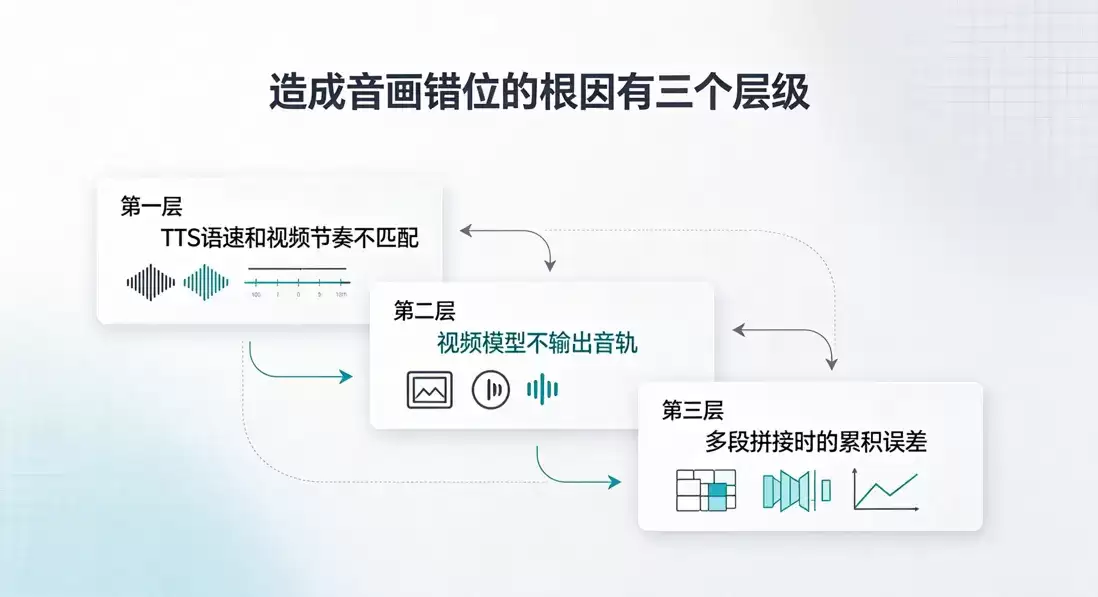
第一层:TTS 语速和视频节奏不匹配。 一条台词,你用 TTS 引擎生成配音花了 2.8 秒,但视频模型生成的那个片段里,角色开口到闭嘴的时间窗口只有 2.1 秒。多出来的 0.7 秒就是错位。
第二层:视频模型不输出音轨。 这是目前主流 AI 视频生成模型(包括 Seedance、万相、HappyHorse)的通用局限——它们生成的是纯画面,不带音频。口型是什么样、动了几下,跟你后面贴上去的配音没有任何关联。你贴什么音轨,它就"假装"在说什么。
第三层:多段拼接时的累积误差。 一条 3 分钟短剧通常由 30-50 个视频片段拼接而成。每个片段差个 100ms,看起来不明显。但 40 段拼起来,累积偏差可能到 3-4 秒,后半段的音画已经错位到没法看了。
二、TTS 层的解法:语速参数化控制
最容易入手的一层。TTS 语速控制是音画同步的第一道防线。
主流 TTS 引擎都支持通过 SSML 标签或 API 参数调节语速。以 SSML 为例:
这段台词需要放慢一点
这段赶时间,加速
但语速调整有个硬边界:大多数 TTS 引擎在 0.8x-1.25x 范围内音质损失可控,一边调整一边听,超过这个范围基本就会开始出问题:超过 1.3x 就会出现吞字、断句异常、情感衰减等问题。低于 0.7x 则拖音严重,听感像慢放。
实战做法是:从剪映或 Premiere 里导出每个片段的精确时长(精确到 100ms),然后在 TTS 调用时动态设置语速参数。偏差在 ±20% 以内的,调语速;超出这个范围的,需要上第二层方案。
三、文本层的解法:约束改写
当配音时长和画面窗口差距超过 20% 时,单纯调语速已经不够——需要从台词本身入手。
最直接的思路是回到台词本身,用大语言模型做一次“约束改写”:给定目标字数(或音节数),在保持原意和情绪基调的前提下压缩或扩展句子。
举个例子:一句中文台词 15 个字,翻译成配音脚本后预估输出 3.2 秒,但画面窗口只有 2.5 秒。偏差率 28%,调语速到 1.28x 勉强能用但音质已经开始下降。这时候让 LLM 把脚本压缩到约 80% 的长度,再配合 1.15x 语速,就能在音质损失最小的情况下对齐时长。
约束改写的 Prompt 关键是三点:
- 目标字符数区间(给范围,不要精确值)
- 保持原句的情绪基调和语气特征
- 不添加原文中没有的信息
改写后的输出需要做二次校验:TTS 预估时长是否落在目标窗口内,不符合就重新生成。这个环节多跑一轮,比后期在剪辑软件里手动调轴高效得多。
四、口型对齐:技术现实与工程取舍
说到底,这部分才是真正让人头疼的。
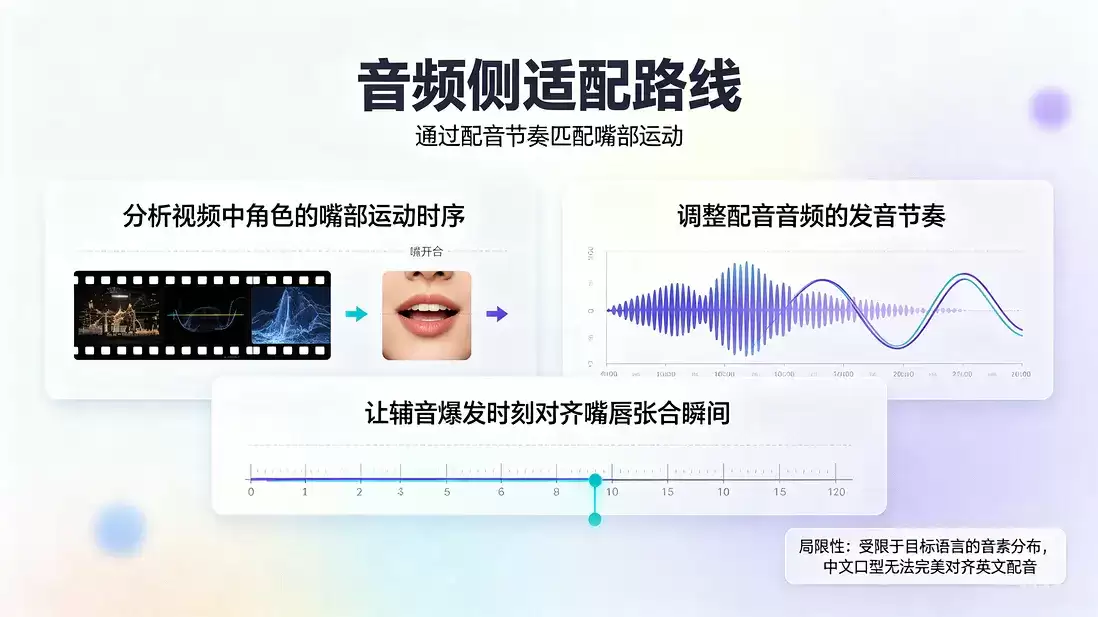
口型对齐在技术上有两条路:音频侧适配和视频侧适配。
音频侧适配的路线是:分析视频中角色的嘴部运动时序(哪些帧张嘴、哪些帧闭嘴),然后调整配音音频的发音节奏,让辅音爆发的时刻尽量对齐嘴唇张合的瞬间。这条路线的优势是不需要动视频画面,坏处是受限于目标语言的音素分布——想把中文的口型精确对齐英文配音,物理上就不可能完美。
视频侧适配的路线更彻底:直接用 AI 改画面上角色的嘴部。基于扩散模型的 lip-sync 方案(如 Wa v2Lip 及其后续变体)已经能在单角色正脸特写下做不错的逐帧口型匹配。但放到短剧生产场景里,问题来了:
- 多角色场景——两人对话时两个角色的嘴部区域都要逐帧处理,算力翻倍,且容易出现互干扰
- 侧脸和运动镜头——Wa v2Lip 对正脸效果好,但侧脸、低头、快速运动时精度急剧下降
- 稳定性——连续 30 帧以上开始出现嘴部区域闪烁,这在 1 分钟以上的片段里几乎必然触发
目前的工程实践里,大多数团队不追求逐帧口型对齐,而是做一个句段级起止时间对齐:确保每句台词的起止时间点在视频里角色开口/闭嘴的时间点 ±200ms 以内。这在观感上已经能消除 80% 以上的违和感。
对于需要逐帧口型的场景(比如角色面部特写超过 3 秒的片段),单独做后处理——把这一段导出,跑 lip-sync 模型,再贴回时间线。
五、字幕时间轴:最被低估的一环
有一个细节非常容易被忽视——字幕出现和消失的时间点,其实直接影响观众对“音画是否同步”的判断。
人耳对人声延迟的容忍度是 200ms 左右,超出这个阈值就会觉得“不对”。但字幕的敏感度更高——字幕如果晚了 100ms,观众很可能第一反应就是“口型对不上”,尽管口型本身可能没问题。
具体做法:
- 字幕时间轴以配音波形为基准,不要以视频里角色的嘴动作为基准。因为观众是先听到声音、再看字幕、最后才注意到口型,正确的锚点是音频。
- 句尾字幕提前 100ms 消失。听觉比视觉慢半拍,字幕在配音结束前就消失,能让观众的注意力平滑过渡到下一句。
- 多行字幕做重叠偏移。对话场景中两个角色台词交替时,前一句的字幕消失时间和后一句的出现时间之间留 50ms 间隙,避免视觉跳变。
六、跨模型的表现差异
不同视频生成模型在“配合音画同步”这件事上,表现差距明显。
| 模型 | 口型自然度 | 开口时机一致性 | 适合场景 |
|---|---|---|---|
| Seedance 2.0 | 较高,正面特写口型清晰 | 画面帧节奏稳定,适合做句段级对齐 | 对话密集的剧集 |
| HappyHorse | 中等,口型偏模糊 | 运动镜头多,开口时机有波动 | 动作戏、快节奏段落 |
| 万相 2.7 | 中等偏高 | 节奏稳定但人物静止场景口型偏僵硬 | 叙事性段落 |
如果你的剧集以对话为主,Seedance 2.0 的视频生成口型基础更好,后续对齐的容错空间更大。如果是动作戏和追逃段落,HappyHorse 的运动镜头表现更稳,但需要单独跑 lip-sync 后处理来补口型精度。
七、一个完整流程
把前面的拆解串起来,一条 3 分钟短剧的音画对齐流程应该是这样的:
- 导出每个视频片段的精确时长(毫秒级)
- 跑 TTS 预估每段配音的时长,计算偏差率
- 偏差 ≤15%:直接调 TTS 语速参数;15%-35%:LLM 约束改写 + 语速调整;≥35%:改写 + 语速 + 静音段压缩
- 输出配音,导回剪辑软件,以配音波形为基准对齐字幕时间轴
- 检查所有面部特写片段,逐帧跑 lip-sync 后处理
- 完整播放验收,重点关注中段(累积偏差最容易在这里暴露)
这个流程跑顺之后,一条 3 分钟短剧的音画同步调校时间能从 2-3 小时压缩到 30 分钟左右。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:AI短剧音画同步技术拆解口型匹配语速控制与字幕对齐要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点要在MyEclipse中让Java实体类自动对应数据库表结构,同时又想避免编写繁杂的XML映射文件,启用注解映射是必经之路。这个需求听起来简单,但实际操作中稍不注意就容易踩坑——比如生成的POJO缺少@Entity、@Table等关键注解,或者驱动版本不兼容导致连接失败。下面将几个核心步骤逐一拆解,
讯飞听见在区分多人发言方面,其实并不神秘。其核心依赖声纹识别、说话人管理以及智能上下文建模三项技术的协同工作,而非简单依靠音量大小或停顿长短进行切割。只要正确设置并规范录入声纹,即便面对三人以上的轮流发言、语速较快甚至偶尔重叠的情况,系统也能稳定地将每句话准确标注到对应发言人,帮助用户高效整理会议记
在背景噪音较大的环境下,语音转写的准确率往往会明显下降。尽管讯飞听见并没有提供所谓的“一键降噪”按钮——你无法通过单一开关自动清除所有干扰——但它的应对策略是前置优化 + 模型适配 + 后期校正,并非依赖后期滤波一种方式,而是从录音源头、识别模型与人工干预三个环节协同发力,以实现更可靠的转写效果。
Gamma AI的演示文稿编辑能力远不止生成初稿这么基础。如果你已经用它搭建好幻灯片框架,却希望在不重写整页的前提下快速调整某页文案语气、更换图表类型,或让某个节点支持点击跳转——这些操作都可以在侧边栏的AI设计助手中实时完成,无需退出编辑模式或切换其他工具。下面直接拆解具体操作流程。 先交代一个前
- 日榜
- 周榜
- 月榜
热点快看