




DAPO与Dr.GRPO长度偏置问题深度解读

上一讲从代码层面解释了GRPO为何能省略critic——本质上是利用同一条prompt的多条response在组内计算相对baseline,而无需单独训练一个value model。但省略critic后,最容易被低估的问题是什么呢?
先给出核心判断:DAPO-style recipe和Dr. GRPO关注的不是“增加一个模型角色”,而是reward形状、advantage归一化以及loss聚合方式。它们实际上都在处理同一个工程现实:LLM后训练阶段,response长度从来不是中性变量。长答案会影响reward如何计算、advantage如何广播、token loss如何聚合、显存如何分配,以及rollout阶段的长尾分布。
先看整体组合图。注意:在verl示例中,DAPO-style recipe仍然设置`algorithm.adv_estimator=grpo`,真正变化的是reward manager、overlong buffer、actor clip、loss聚合和动态batch这些训练旋钮。
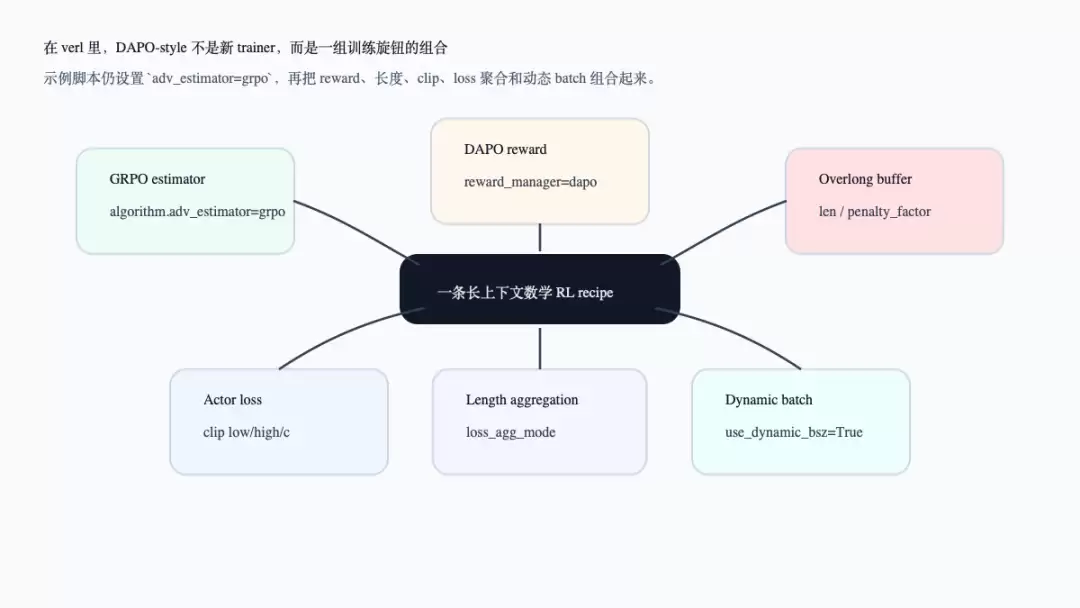 这张图对应`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh`的配置组合:算法依然是`adv_estimator=grpo`,in-reward KL关闭;reward manager设为`dapo`,并开启overlong buffer;数据侧设置最大prompt/response长度;actor侧设置dynamic batch、clip ratio和`loss_agg_mode`(参考`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:100-147`)。
### 1. DAPO-style recipe优先调整reward形状
DAPO在该仓库中的直接代码入口是`DAPORewardManager`。它注册名为`"dapo"`,初始化时接收`max_resp_len`和`overlong_buffer_cfg`;若启用overlong buffer,则需要`max_resp_len`存在,且buffer长度必须为正(参考`verl/workers/reward_manager/dapo.py:25-56`)。
reward计算时,manager会解码prompt/response,调用`compute_score()`获得基础score,然后如果启用了overlong buffer,则根据response的有效长度计算额外惩罚:`expected_len = max_resp_len - overlong_buffer_len`,超过expected_len的部分按比例扣分,最后将reward写入最后一个有效response token上(参考`verl/workers/reward_manager/dapo.py:71-132`)。
下面这张图展示了overlong buffer的形状。它不是简单截断response,而是在reward层对过长答案施加连续负反馈。
这张图对应`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh`的配置组合:算法依然是`adv_estimator=grpo`,in-reward KL关闭;reward manager设为`dapo`,并开启overlong buffer;数据侧设置最大prompt/response长度;actor侧设置dynamic batch、clip ratio和`loss_agg_mode`(参考`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:100-147`)。
### 1. DAPO-style recipe优先调整reward形状
DAPO在该仓库中的直接代码入口是`DAPORewardManager`。它注册名为`"dapo"`,初始化时接收`max_resp_len`和`overlong_buffer_cfg`;若启用overlong buffer,则需要`max_resp_len`存在,且buffer长度必须为正(参考`verl/workers/reward_manager/dapo.py:25-56`)。
reward计算时,manager会解码prompt/response,调用`compute_score()`获得基础score,然后如果启用了overlong buffer,则根据response的有效长度计算额外惩罚:`expected_len = max_resp_len - overlong_buffer_len`,超过expected_len的部分按比例扣分,最后将reward写入最后一个有效response token上(参考`verl/workers/reward_manager/dapo.py:71-132`)。
下面这张图展示了overlong buffer的形状。它不是简单截断response,而是在reward层对过长答案施加连续负反馈。
 这个设计的系统意义在于:长度管理不仅仅发生在tokenizer或rollout max length上。`data.max_response_length`决定生成上限,overlong buffer决定接近上限时的reward曲线,二者共同影响模型学到的“适宜长度”。
### 2. Dr. GRPO调整的是归一化和loss聚合
Dr. GRPO在当前`examples/grpo_trainer/README.md`中既不是新worker,也不是单独trainer。README给出的启用方法是在canonical GRPO上叠加三个配置:`actor_rollout_ref.actor.loss_agg_mode=seq-mean-token-sum-norm`、`actor_rollout_ref.actor.use_kl_loss=False`、`algorithm.norm_adv_by_std_in_grpo=False`(参考`examples/grpo_trainer/README.md:30-38`)。
这三个配置分别对应两段源码。第一段是GRPO advantage:`compute_grpo_outcome_advantage()`默认会将`score - group_mean`再除以组内std;当`norm_adv_by_std_in_grpo=False`时,它只做`score - group_mean`(参考`verl/trainer/ppo/core_algos.py:294-328`)。第二段是loss聚合:`agg_loss()`对`seq-mean-token-sum-norm`会先按序列求token-sum,再按global batch做seq-mean,最后除以固定scale factor或response horizon(参考`verl/trainer/ppo/core_algos.py:1141-1187`)。
下面这张图将两个关键开关放在一起。它补充说明:Dr. GRPO不改变actor/ref/reward/rollout的角色图,而是改变同一批token loss如何被缩放。
这个设计的系统意义在于:长度管理不仅仅发生在tokenizer或rollout max length上。`data.max_response_length`决定生成上限,overlong buffer决定接近上限时的reward曲线,二者共同影响模型学到的“适宜长度”。
### 2. Dr. GRPO调整的是归一化和loss聚合
Dr. GRPO在当前`examples/grpo_trainer/README.md`中既不是新worker,也不是单独trainer。README给出的启用方法是在canonical GRPO上叠加三个配置:`actor_rollout_ref.actor.loss_agg_mode=seq-mean-token-sum-norm`、`actor_rollout_ref.actor.use_kl_loss=False`、`algorithm.norm_adv_by_std_in_grpo=False`(参考`examples/grpo_trainer/README.md:30-38`)。
这三个配置分别对应两段源码。第一段是GRPO advantage:`compute_grpo_outcome_advantage()`默认会将`score - group_mean`再除以组内std;当`norm_adv_by_std_in_grpo=False`时,它只做`score - group_mean`(参考`verl/trainer/ppo/core_algos.py:294-328`)。第二段是loss聚合:`agg_loss()`对`seq-mean-token-sum-norm`会先按序列求token-sum,再按global batch做seq-mean,最后除以固定scale factor或response horizon(参考`verl/trainer/ppo/core_algos.py:1141-1187`)。
下面这张图将两个关键开关放在一起。它补充说明:Dr. GRPO不改变actor/ref/reward/rollout的角色图,而是改变同一批token loss如何被缩放。
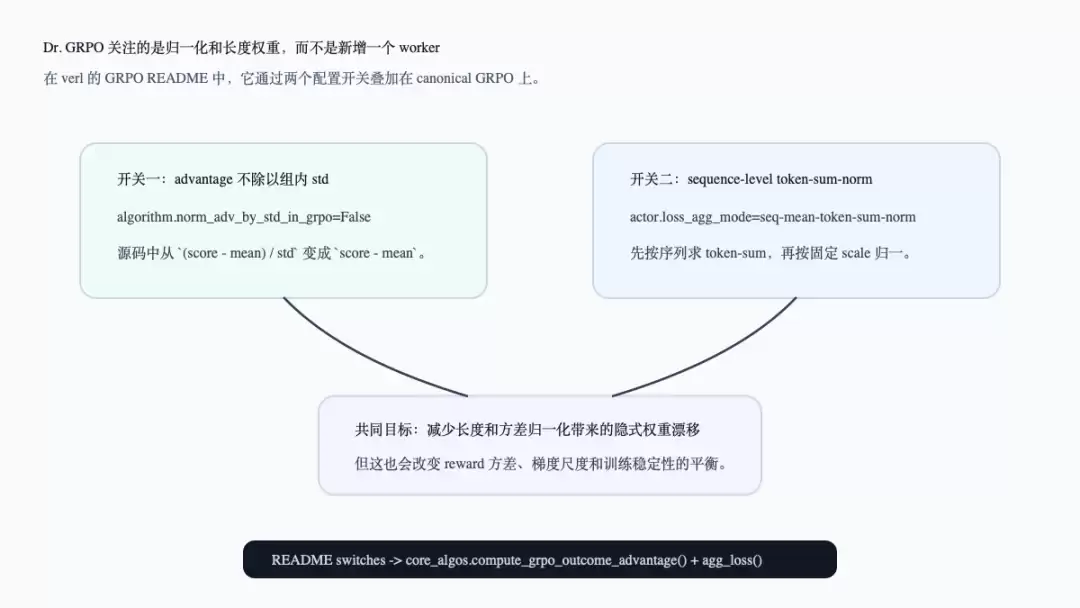 这里需要谨慎区分源码事实和工程解释。源码事实是:一个开关控制GRPO advantage是否除以组内std,另一个开关控制actor loss的token/sequence聚合方式。工程解释是:这两个开关都会改变长度、方差和梯度尺度之间的平衡,因此它们属于长度偏置和稳定性管理的一部分。
### 3. 长度偏置从三条路径进入训练
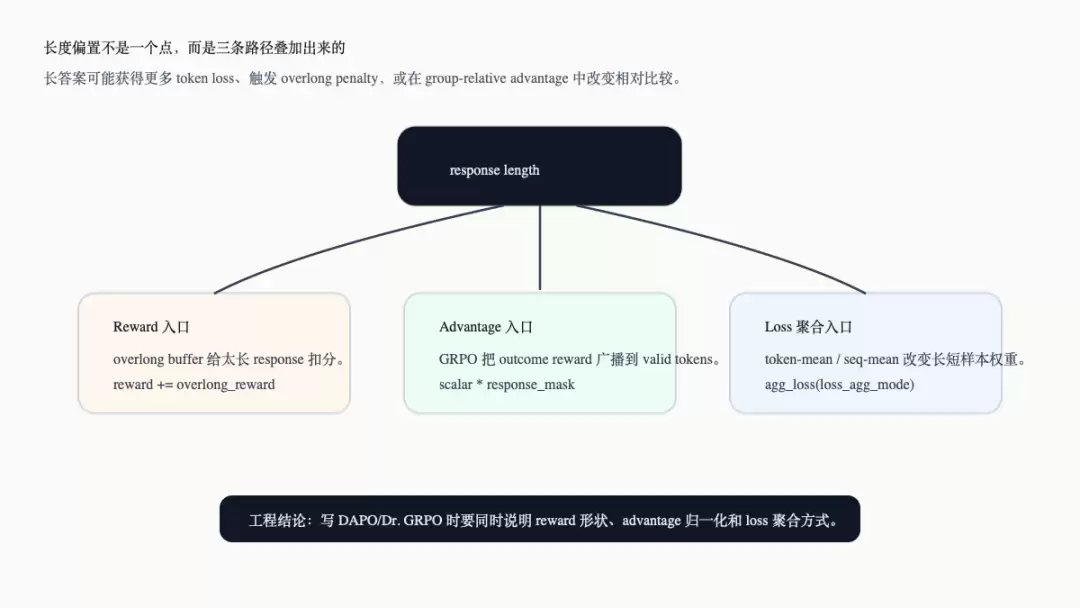
长度偏置不是一个单点bug,而是三条路径叠加产生的系统效应。
第一条是reward路径。DAPO overlong buffer明确将response长度纳入reward:超过expected_len后,reward会被额外扣分(参考`verl/workers/reward_manager/dapo.py:121-132`)。
第二条是advantage路径。GRPO的outcome score是标量,但`compute_grpo_outcome_advantage()`会把这个标量乘以`response_mask`广播到所有有效response token上(参考`verl/trainer/ppo/core_algos.py:329-331`)。同一个scalar advantage作用于多少token上,取决于response长度。
第三条是loss聚合路径。`agg_loss()`支持`token-mean`、`seq-mean-token-sum`、`seq-mean-token-sum-norm`、`seq-mean-token-mean`等模式;不同模式对长短response的权重不同(参考`verl/trainer/ppo/core_algos.py:1168-1197`)。actor默认配置也将`loss_agg_mode`作为一等配置项,并说明它支持这些模式(参考`verl/trainer/config/actor/actor.yaml:81-86`)。
下面这张图将三条路径整合在一起。它与前两张图互补:前面分别讲reward和Dr. GRPO开关,这张图说明为什么它们最终都落到长度偏置。
这里需要谨慎区分源码事实和工程解释。源码事实是:一个开关控制GRPO advantage是否除以组内std,另一个开关控制actor loss的token/sequence聚合方式。工程解释是:这两个开关都会改变长度、方差和梯度尺度之间的平衡,因此它们属于长度偏置和稳定性管理的一部分。
### 3. 长度偏置从三条路径进入训练
长度偏置不是一个单点bug,而是三条路径叠加产生的系统效应。
第一条是reward路径。DAPO overlong buffer明确将response长度纳入reward:超过expected_len后,reward会被额外扣分(参考`verl/workers/reward_manager/dapo.py:121-132`)。
第二条是advantage路径。GRPO的outcome score是标量,但`compute_grpo_outcome_advantage()`会把这个标量乘以`response_mask`广播到所有有效response token上(参考`verl/trainer/ppo/core_algos.py:329-331`)。同一个scalar advantage作用于多少token上,取决于response长度。
第三条是loss聚合路径。`agg_loss()`支持`token-mean`、`seq-mean-token-sum`、`seq-mean-token-sum-norm`、`seq-mean-token-mean`等模式;不同模式对长短response的权重不同(参考`verl/trainer/ppo/core_algos.py:1168-1197`)。actor默认配置也将`loss_agg_mode`作为一等配置项,并说明它支持这些模式(参考`verl/trainer/config/actor/actor.yaml:81-86`)。
下面这张图将三条路径整合在一起。它与前两张图互补:前面分别讲reward和Dr. GRPO开关,这张图说明为什么它们最终都落到长度偏置。
 因此,写到DAPO/Dr. GRPO时,不能只说“用了GRPO”。更完整的描述应同时说明reward形状、advantage归一化、loss聚合方式和max response length。否则同样是`adv_estimator=grpo`,训练语义可能已经不同。
### 4. 动态batch和sequence balancing是性能侧的配套
长度问题还会影响性能。GRPO/DAPO场景常见长上下文和多response,短样本与长样本混在一起时,padding、micro-batch token数和DP rank负载都会变成系统问题。
示例脚本中,actor侧会启用`actor_rollout_ref.actor.use_dynamic_bsz=True`,并设置`ppo_max_token_len_per_gpu`;rollout/ref logprob也经常跟随dynamic batch配置(参考`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:134-147`,`examples/grpo_trainer/run_qwen3_8b_fsdp.sh:148-172`)。actor配置文件也说明`ppo_max_token_len_per_gpu`通常需要与prompt/response长度相关(参考`verl/trainer/config/actor/actor.yaml:26-33`)。
trainer侧还有`balance_batch`:它会根据attention mask的有效token数计算workload,再对batch重排,使DP rank上的token数更接近;源码注释也提醒,这通常会改变样本顺序,但advantage依赖uid,因此不影响advantage计算(参考`verl/trainer/ppo/ray_trainer.py:1060-1128`,`verl/trainer/ppo/ray_trainer.py:1408-1415`)。
这些是性能侧配套,不是算法替代。它们解决的是“长短样本如何高效进worker”,而非“长度本身该被奖励还是惩罚”。后者仍由reward manager、advantage和loss聚合共同决定。
### 小结:DAPO/Dr. GRPO是对GRPO主线的长度与尺度管理
把第08、09篇连起来看,第二组的逻辑是:
```
PPO 需要 critic baseline
GRPO 用组内相对 reward 替代 critic baseline
DAPO / Dr. GRPO 继续管理 reward 长度、advantage 归一化和 loss 聚合尺度
```
DAPO-style recipe在verl中不是替换GRPO主线,而是在GRPO上调整reward和训练配置。Dr. GRPO也不是新增worker,而是通过`norm_adv_by_std_in_grpo`和`loss_agg_mode`改变advantage与token loss的尺度。
下一篇可以继续写KL、clip、entropy:当reward、advantage和长度都进入系统后,还需要一组限速器防止actor更新过快。
### 本文源码索引
`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:100-147`:DAPO-style recipe中GRPO estimator、DAPO reward、overlong buffer、actor clip与loss aggregation配置。
`examples/grpo_trainer/run_qwen3_8b_fsdp.sh:130-172`:常规GRPO示例中的data、actor、rollout/ref dynamic batch配置。
`examples/grpo_trainer/README.md:30-38`:Dr. GRPO的三个配置开关。
`verl/workers/reward_manager/dapo.py:25-56`:`DAPORewardManager`的注册与overlong buffer参数校验。
`verl/workers/reward_manager/dapo.py:71-132`:DAPO reward计算、overlong penalty和reward写入位置。
`verl/trainer/ppo/core_algos.py:294-328`:GRPO advantage是否按组内std归一。
`verl/trainer/ppo/core_algos.py:329-331`:GRPO scalar advantage如何广播到response tokens。
`verl/trainer/ppo/core_algos.py:1141-1199`:`agg_loss()`的token/sequence聚合模式。
`verl/trainer/config/actor/actor.yaml:26-33`:dynamic batch与token长度上限配置。
`verl/trainer/config/actor/actor.yaml:81-86`:actor loss aggregation配置。
`verl/trainer/ppo/ray_trainer.py:1060-1128`:按有效token数做batch balance。
`verl/trainer/ppo/ray_trainer.py:1408-1415`:`fit()`中response mask与balance_batch的位置。
因此,写到DAPO/Dr. GRPO时,不能只说“用了GRPO”。更完整的描述应同时说明reward形状、advantage归一化、loss聚合方式和max response length。否则同样是`adv_estimator=grpo`,训练语义可能已经不同。
### 4. 动态batch和sequence balancing是性能侧的配套
长度问题还会影响性能。GRPO/DAPO场景常见长上下文和多response,短样本与长样本混在一起时,padding、micro-batch token数和DP rank负载都会变成系统问题。
示例脚本中,actor侧会启用`actor_rollout_ref.actor.use_dynamic_bsz=True`,并设置`ppo_max_token_len_per_gpu`;rollout/ref logprob也经常跟随dynamic batch配置(参考`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:134-147`,`examples/grpo_trainer/run_qwen3_8b_fsdp.sh:148-172`)。actor配置文件也说明`ppo_max_token_len_per_gpu`通常需要与prompt/response长度相关(参考`verl/trainer/config/actor/actor.yaml:26-33`)。
trainer侧还有`balance_batch`:它会根据attention mask的有效token数计算workload,再对batch重排,使DP rank上的token数更接近;源码注释也提醒,这通常会改变样本顺序,但advantage依赖uid,因此不影响advantage计算(参考`verl/trainer/ppo/ray_trainer.py:1060-1128`,`verl/trainer/ppo/ray_trainer.py:1408-1415`)。
这些是性能侧配套,不是算法替代。它们解决的是“长短样本如何高效进worker”,而非“长度本身该被奖励还是惩罚”。后者仍由reward manager、advantage和loss聚合共同决定。
### 小结:DAPO/Dr. GRPO是对GRPO主线的长度与尺度管理
把第08、09篇连起来看,第二组的逻辑是:
```
PPO 需要 critic baseline
GRPO 用组内相对 reward 替代 critic baseline
DAPO / Dr. GRPO 继续管理 reward 长度、advantage 归一化和 loss 聚合尺度
```
DAPO-style recipe在verl中不是替换GRPO主线,而是在GRPO上调整reward和训练配置。Dr. GRPO也不是新增worker,而是通过`norm_adv_by_std_in_grpo`和`loss_agg_mode`改变advantage与token loss的尺度。
下一篇可以继续写KL、clip、entropy:当reward、advantage和长度都进入系统后,还需要一组限速器防止actor更新过快。
### 本文源码索引
`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:100-147`:DAPO-style recipe中GRPO estimator、DAPO reward、overlong buffer、actor clip与loss aggregation配置。
`examples/grpo_trainer/run_qwen3_8b_fsdp.sh:130-172`:常规GRPO示例中的data、actor、rollout/ref dynamic batch配置。
`examples/grpo_trainer/README.md:30-38`:Dr. GRPO的三个配置开关。
`verl/workers/reward_manager/dapo.py:25-56`:`DAPORewardManager`的注册与overlong buffer参数校验。
`verl/workers/reward_manager/dapo.py:71-132`:DAPO reward计算、overlong penalty和reward写入位置。
`verl/trainer/ppo/core_algos.py:294-328`:GRPO advantage是否按组内std归一。
`verl/trainer/ppo/core_algos.py:329-331`:GRPO scalar advantage如何广播到response tokens。
`verl/trainer/ppo/core_algos.py:1141-1199`:`agg_loss()`的token/sequence聚合模式。
`verl/trainer/config/actor/actor.yaml:26-33`:dynamic batch与token长度上限配置。
`verl/trainer/config/actor/actor.yaml:81-86`:actor loss aggregation配置。
`verl/trainer/ppo/ray_trainer.py:1060-1128`:按有效token数做batch balance。
`verl/trainer/ppo/ray_trainer.py:1408-1415`:`fit()`中response mask与balance_batch的位置。
来源:https://cloud.tencent.com.cn/developer/article/2701616
这张图对应`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh`的配置组合:算法依然是`adv_estimator=grpo`,in-reward KL关闭;reward manager设为`dapo`,并开启overlong buffer;数据侧设置最大prompt/response长度;actor侧设置dynamic batch、clip ratio和`loss_agg_mode`(参考`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:100-147`)。
### 1. DAPO-style recipe优先调整reward形状
DAPO在该仓库中的直接代码入口是`DAPORewardManager`。它注册名为`"dapo"`,初始化时接收`max_resp_len`和`overlong_buffer_cfg`;若启用overlong buffer,则需要`max_resp_len`存在,且buffer长度必须为正(参考`verl/workers/reward_manager/dapo.py:25-56`)。
reward计算时,manager会解码prompt/response,调用`compute_score()`获得基础score,然后如果启用了overlong buffer,则根据response的有效长度计算额外惩罚:`expected_len = max_resp_len - overlong_buffer_len`,超过expected_len的部分按比例扣分,最后将reward写入最后一个有效response token上(参考`verl/workers/reward_manager/dapo.py:71-132`)。
下面这张图展示了overlong buffer的形状。它不是简单截断response,而是在reward层对过长答案施加连续负反馈。
这个设计的系统意义在于:长度管理不仅仅发生在tokenizer或rollout max length上。`data.max_response_length`决定生成上限,overlong buffer决定接近上限时的reward曲线,二者共同影响模型学到的“适宜长度”。
### 2. Dr. GRPO调整的是归一化和loss聚合
Dr. GRPO在当前`examples/grpo_trainer/README.md`中既不是新worker,也不是单独trainer。README给出的启用方法是在canonical GRPO上叠加三个配置:`actor_rollout_ref.actor.loss_agg_mode=seq-mean-token-sum-norm`、`actor_rollout_ref.actor.use_kl_loss=False`、`algorithm.norm_adv_by_std_in_grpo=False`(参考`examples/grpo_trainer/README.md:30-38`)。
这三个配置分别对应两段源码。第一段是GRPO advantage:`compute_grpo_outcome_advantage()`默认会将`score - group_mean`再除以组内std;当`norm_adv_by_std_in_grpo=False`时,它只做`score - group_mean`(参考`verl/trainer/ppo/core_algos.py:294-328`)。第二段是loss聚合:`agg_loss()`对`seq-mean-token-sum-norm`会先按序列求token-sum,再按global batch做seq-mean,最后除以固定scale factor或response horizon(参考`verl/trainer/ppo/core_algos.py:1141-1187`)。
下面这张图将两个关键开关放在一起。它补充说明:Dr. GRPO不改变actor/ref/reward/rollout的角色图,而是改变同一批token loss如何被缩放。
这里需要谨慎区分源码事实和工程解释。源码事实是:一个开关控制GRPO advantage是否除以组内std,另一个开关控制actor loss的token/sequence聚合方式。工程解释是:这两个开关都会改变长度、方差和梯度尺度之间的平衡,因此它们属于长度偏置和稳定性管理的一部分。
### 3. 长度偏置从三条路径进入训练
长度偏置不是一个单点bug,而是三条路径叠加产生的系统效应。
第一条是reward路径。DAPO overlong buffer明确将response长度纳入reward:超过expected_len后,reward会被额外扣分(参考`verl/workers/reward_manager/dapo.py:121-132`)。
第二条是advantage路径。GRPO的outcome score是标量,但`compute_grpo_outcome_advantage()`会把这个标量乘以`response_mask`广播到所有有效response token上(参考`verl/trainer/ppo/core_algos.py:329-331`)。同一个scalar advantage作用于多少token上,取决于response长度。
第三条是loss聚合路径。`agg_loss()`支持`token-mean`、`seq-mean-token-sum`、`seq-mean-token-sum-norm`、`seq-mean-token-mean`等模式;不同模式对长短response的权重不同(参考`verl/trainer/ppo/core_algos.py:1168-1197`)。actor默认配置也将`loss_agg_mode`作为一等配置项,并说明它支持这些模式(参考`verl/trainer/config/actor/actor.yaml:81-86`)。
下面这张图将三条路径整合在一起。它与前两张图互补:前面分别讲reward和Dr. GRPO开关,这张图说明为什么它们最终都落到长度偏置。
因此,写到DAPO/Dr. GRPO时,不能只说“用了GRPO”。更完整的描述应同时说明reward形状、advantage归一化、loss聚合方式和max response length。否则同样是`adv_estimator=grpo`,训练语义可能已经不同。
### 4. 动态batch和sequence balancing是性能侧的配套
长度问题还会影响性能。GRPO/DAPO场景常见长上下文和多response,短样本与长样本混在一起时,padding、micro-batch token数和DP rank负载都会变成系统问题。
示例脚本中,actor侧会启用`actor_rollout_ref.actor.use_dynamic_bsz=True`,并设置`ppo_max_token_len_per_gpu`;rollout/ref logprob也经常跟随dynamic batch配置(参考`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:134-147`,`examples/grpo_trainer/run_qwen3_8b_fsdp.sh:148-172`)。actor配置文件也说明`ppo_max_token_len_per_gpu`通常需要与prompt/response长度相关(参考`verl/trainer/config/actor/actor.yaml:26-33`)。
trainer侧还有`balance_batch`:它会根据attention mask的有效token数计算workload,再对batch重排,使DP rank上的token数更接近;源码注释也提醒,这通常会改变样本顺序,但advantage依赖uid,因此不影响advantage计算(参考`verl/trainer/ppo/ray_trainer.py:1060-1128`,`verl/trainer/ppo/ray_trainer.py:1408-1415`)。
这些是性能侧配套,不是算法替代。它们解决的是“长短样本如何高效进worker”,而非“长度本身该被奖励还是惩罚”。后者仍由reward manager、advantage和loss聚合共同决定。
### 小结:DAPO/Dr. GRPO是对GRPO主线的长度与尺度管理
把第08、09篇连起来看,第二组的逻辑是:
```
PPO 需要 critic baseline
GRPO 用组内相对 reward 替代 critic baseline
DAPO / Dr. GRPO 继续管理 reward 长度、advantage 归一化和 loss 聚合尺度
```
DAPO-style recipe在verl中不是替换GRPO主线,而是在GRPO上调整reward和训练配置。Dr. GRPO也不是新增worker,而是通过`norm_adv_by_std_in_grpo`和`loss_agg_mode`改变advantage与token loss的尺度。
下一篇可以继续写KL、clip、entropy:当reward、advantage和长度都进入系统后,还需要一组限速器防止actor更新过快。
### 本文源码索引
`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:100-147`:DAPO-style recipe中GRPO estimator、DAPO reward、overlong buffer、actor clip与loss aggregation配置。
`examples/grpo_trainer/run_qwen3_8b_fsdp.sh:130-172`:常规GRPO示例中的data、actor、rollout/ref dynamic batch配置。
`examples/grpo_trainer/README.md:30-38`:Dr. GRPO的三个配置开关。
`verl/workers/reward_manager/dapo.py:25-56`:`DAPORewardManager`的注册与overlong buffer参数校验。
`verl/workers/reward_manager/dapo.py:71-132`:DAPO reward计算、overlong penalty和reward写入位置。
`verl/trainer/ppo/core_algos.py:294-328`:GRPO advantage是否按组内std归一。
`verl/trainer/ppo/core_algos.py:329-331`:GRPO scalar advantage如何广播到response tokens。
`verl/trainer/ppo/core_algos.py:1141-1199`:`agg_loss()`的token/sequence聚合模式。
`verl/trainer/config/actor/actor.yaml:26-33`:dynamic batch与token长度上限配置。
`verl/trainer/config/actor/actor.yaml:81-86`:actor loss aggregation配置。
`verl/trainer/ppo/ray_trainer.py:1060-1128`:按有效token数做batch balance。
`verl/trainer/ppo/ray_trainer.py:1408-1415`:`fit()`中response mask与balance_batch的位置。 
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

ControlNet Mac电脑的详细完整安装教程:Apple Silicon与Intel配置步骤详解
ControlNet是常用AI绘画控制插件,macOS安装需区分AppleSilicon与Intel环境,重点处理Python、WebUI、插件目录、模型文件和启动参数,配置前应做好备份并关注版本兼容。
时间:2026-07-05 06:45

Krita AI Diffusion 新手入门从下载安装到首次运行保姆级教程
KritaAIDiffusion适合在Krita中完成文生图、图生图和局部重绘。安装重点是确认Krita版本、导入插件、配置本地或远程后端、下载模型,并在首次运行前检查显存、路径和权限。
时间:2026-07-05 06:44

Krita AI Diffusion安装失败?常见报错日志排查与升级回滚方案
KritaAIDiffusion安装异常多与版本不匹配、压缩包结构错误、Python插件未启用、后台服务或模型下载失败有关。可通过日志定位原因,按步骤重装、升级或回滚,避免覆盖配置和模型文件。
时间:2026-07-05 06:44

Krita AI Diffusion插件安装全流程教程:浏览器、编辑器、扩展市场
KritaAIDiffusion可将生成式绘图能力接入Krita,适合草图细化、局部重绘和风格探索。安装需确认版本、下载插件、配置后端服务与模型路径,并注意显卡资源、来源安全和版权合规。
时间:2026-07-05 06:44

Krita AI Diffusion API密钥配置教程:账号注册、密钥获取与国内网络设置
KritaAIDiffusion配置重点在于确认插件版本、完成服务账号注册、创建并保存APIKey,再结合本地代理、证书、下载源与连接测试解决国内网络不稳定问题,避免密钥泄露和误用。
时间:2026-07-05 06:44








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-05 06:45
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:43
2026-07-05 06:43
热门教程
2026-07-05 06:45
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:43
2026-07-05 06:43
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程

幸福的二人房隐藏彩蛋大全
发布于 2026-07-05

梦幻西游109化生寺平民属性合格标准
发布于 2026-07-05

交错战线幽兰培养建议及阵容搭配攻略
发布于 2026-07-05

梦幻西游仓库全部整理所需体力详解
发布于 2026-07-05

选技大乱斗新手进阶上分攻略最强玩法指南
发布于 2026-07-05

魔兽世界9.2大秘境装等掉落指南
发布于 2026-07-05

动物城咖啡店下载渠道与官方下载地址大全
发布于 2026-07-05

Valve正开发新物理引擎Ragnarok曝光
发布于 2026-07-05

Win11频繁断网提示默认网关不可用怎么办
发布于 2026-07-03

Mac如何取消正在进行的系统备份任务
发布于 2026-07-03

电脑显示器刷新率锁死60Hz无法调整的解决方法
发布于 2026-07-03

Linux系统下Systemd服务管理从零开始方法步骤详解完整教程
发布于 2026-07-03

博世洗衣机连接WiFi后手机无反应怎么办
发布于 2026-07-05

九号电动车定位消失,重启能解决吗
发布于 2026-07-05

东芝电饭煲复位键在面板哪个位置
发布于 2026-07-05

家用扫地机器人推荐榜首吸力多大合适
发布于 2026-07-05
热门话题
