




AI Agent技能系统设计指南

原创 会员技术 2026-07-01 17:27 浙江 说起AI Agent的Skill系统,很多人都以为不过是给模型写一份详细的说明书。但真正在工程一线摸爬滚打过的开发者都清楚:Skill根本不是文档,而是“行为编程”。它要用结构化的方式告诉Agent该做什么、不该做什么,并且在上下文紧张、任务复
原创 会员技术 2026-07-01 17:27 浙江

说起AI Agent的Skill系统,很多人都以为不过是给模型写一份详细的说明书。但真正在工程一线摸爬滚打过的开发者都清楚:Skill根本不是文档,而是“行为编程”。它要用结构化的方式告诉Agent该做什么、不该做什么,并且在上下文紧张、任务复杂、模型容易偷懒的时候,依然能把Agent拉回正轨。
本文不扯空洞的理论,直接从底层工程出发,拆解Skill系统的行为编程逻辑、Token经济策略和强制约束机制。核心观点只有一句:把Skill当成可执行的工作流来设计,而不是当成知识库来填充。

一个好的Skill需要同时搞定四件事:让Agent在正确场景发现它、用最少的上下文加载必要信息、按任务风险设置合适的自由度、以及通过真实任务验证是否真的改变了行为。这篇文章的重点,就是告诉你如何写出能被Agent正确触发、正确执行、并且可持续维护的Skill。
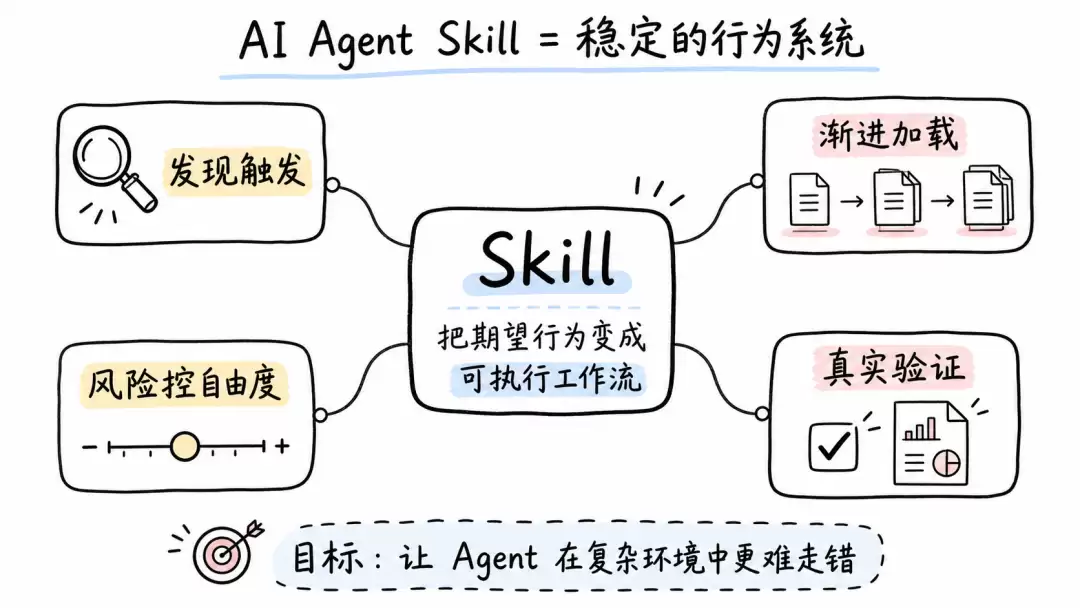

先定义目标:Skill 是能力包,不是知识库
Skill可以被理解为一个自包含的能力包。它通过SKILL.md、脚本、引用资料和资产,把一个通用Agent转化为在特定任务上更可靠的专用Agent。它通常提供四类能力:
| 能力 | 说明 | 示例 |
| 专用工作流 | 多步骤、可复用的任务流程 | 写技术方案、处理PR评论、生成报告 |
| 工具集成 | 使用特定文件格式、API或CLI的方法 | 处理PDF、调用GitHub、操作表格 |
| 领域知识 | 业务规则、数据口径、组织约定 | 公司指标口径、内部权限边界 |
| 捆绑资源 | 脚本、模板、参考资料、素材 | scripts/、references/、assets/ |
Skill面向的是Agent本身——这个家伙在上下文不足、任务复杂、目标冲突或者执行压力下,很容易走捷径。所以Skill必须预设这些失败模式,把正确路径写成更容易被执行的行为结构。它不是把人类已经知道的背景知识完整搬进去,而是补充Agent完成任务时缺少的程序性知识、资源边界和验证方式。换句话说,写Skill不是“把说明写清楚”,而是“让Agent在复杂环境中更难走错”。
一个有效的Skill要影响Agent的完整行为链路:什么时候发现这个Skill,什么时候加载正文,哪些信息继续按需读取,哪些动作必须先做,哪些行为绝对不能发生,如何证明任务真的完成,什么时候需要停下来请求人类判断。如果一个Skill只在模型状态好、上下文充足、任务简单时生效,它更像提示词模板。高质量的Skill应该能在任务复杂、信息不完整、执行压力和合理化冲动下,依然把Agent拉回正确路径。
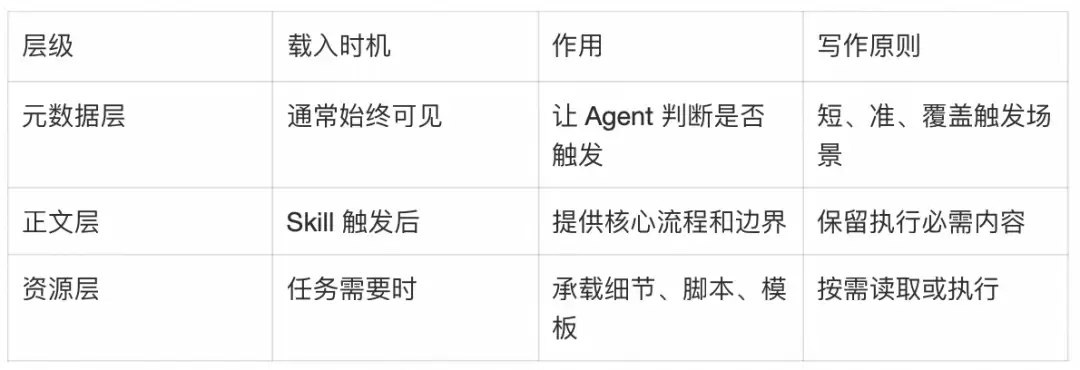
按上下文预算组织内容:元数据、正文、资源三层加载

Skill设计的第一条工程原则是:上下文窗口是公共资源。Agent执行任务时,上下文要同时容纳系统提示、用户请求、对话历史、已触发Skill、工具结果、代码片段和中间推理。Skill多占一个token,其他上下文就少一个token。所以写Skill时要默认Agent已经很聪明,只补充它不知道、但完成任务必须知道的内容。
每一段内容都应该经受两个问题的挑战:Agent真的需要这段解释吗?这段内容值得它占用的token成本吗?这也是为什么Skill应该采用渐进披露,而不是把所有信息塞进一个长文件。
一个标准Skill目录通常长这样:
skill-name/
SKILL.md
agents/
openai.yaml
scripts/
references/
assets/
其中只有SKILL.md是必需的,其余资源按需要添加。
SKILL.md的frontmatter和正文要承担不同职责:
---
name: create-skill
description: 用于创建或更新包含工作流、工具集成、领域知识、脚本、参考资料或资产的Agent Skill。
---
# 创建 Skill
流程:
1.理解具体示例。
2.规划可复用资源。
3.初始化 Skill。
4.编辑 SKILL.md 和相关资源。
5.验证。
6.结合真实使用持续迭代。
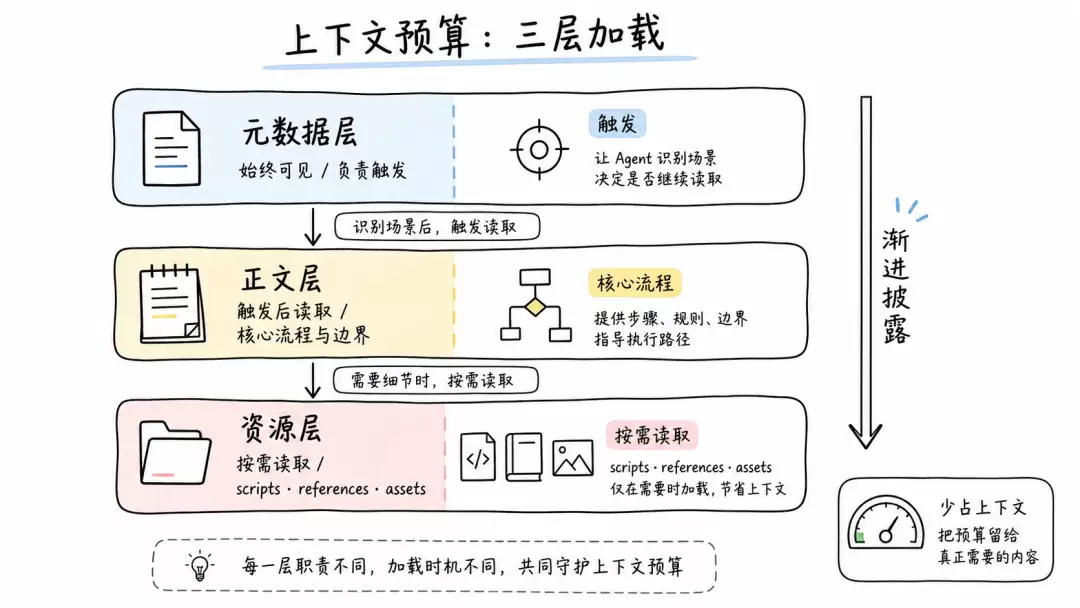
name和description是发现层,正文是执行层,这两层不要混在一起。description应该包含“这个Skill做什么”和“什么时候使用它”,因为Agent只有在触发后才会读取正文。如果把触发条件放在正文里的“When to Use”,Agent在决定是否触发时根本看不到。但description也不能变成完整工作流摘要,它的职责是让Agent正确加载正文,而不是让Agent读完描述就开始凭印象执行。
命名同样属于发现机制的一部分。一个好的Skill名称应该短、可触发、动词优先:

这些细节看起来像命名规范,本质上是路由质量。Agent在一个不断增长的技能库里找能力,name和description就是它的第一层索引。
把可复用部分外化:脚本、引用和资产各司其职

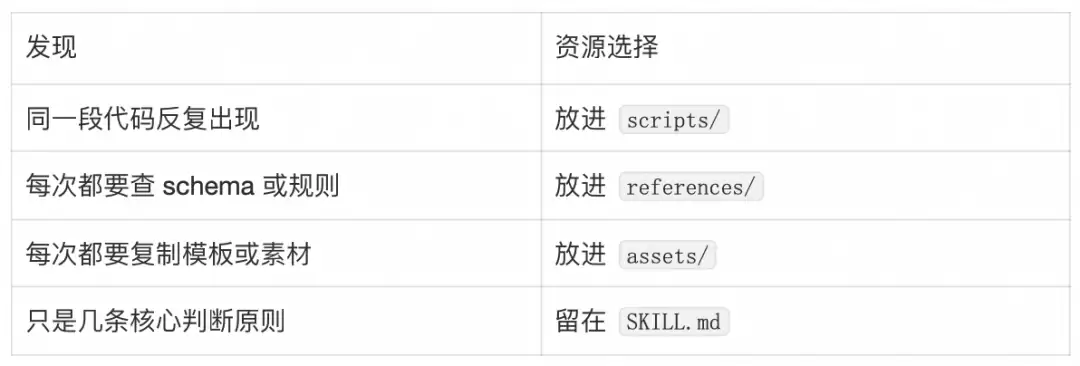
创建Skill时,不应该一开始就写长篇SKILL.md。更好的路径是先看具体例子,然后判断哪些东西值得变成可复用资源。
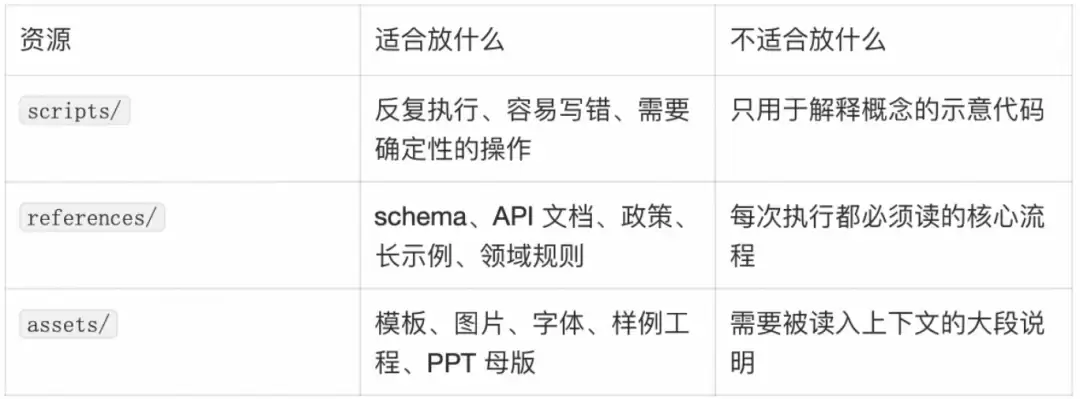
当同一段代码会被反复重写,或者任务需要确定性时,放进scripts/:
pdf-editor/
SKILL.md
scripts/
rotate_pdf.py
脚本的价值不是“让目录更丰富”,而是减少上下文消耗和行为漂移。让Agent每次临时生成PDF旋转代码,和让它调用一个已经验证过的脚本,是完全不同的可靠性水平。
当信息是任务执行时需要查阅的知识,而不是每次都必须读的流程,就放进references/:
big-query/
SKILL.md
references/
schema.md
finance.md
product.md
如果用户问销售指标,Agent只需要读sales.md或对应领域文件,不应该同时加载财务、产品、市场的所有规则。这就是渐进披露在真实Skill中的价值:信息可发现,但不抢占上下文。
当文件不会被读入上下文,而是作为输出材料被复制、修改或引用时,放进assets/:
frontend-webapp-builder/
SKILL.md
assets/
hello-world/
例如模板工程、字体、图片、PPT模板、品牌素材都属于资产。它们不是给Agent阅读的长文本,而是给最终产物使用的材料。
资源组织还有一个容易被忽略的原则:信息只放一个地方。不要在SKILL.md和references/中重复同一段规则。重复会带来漂移,漂移会让Agent在两个版本之间自行解释,最后把维护成本转化成执行风险。
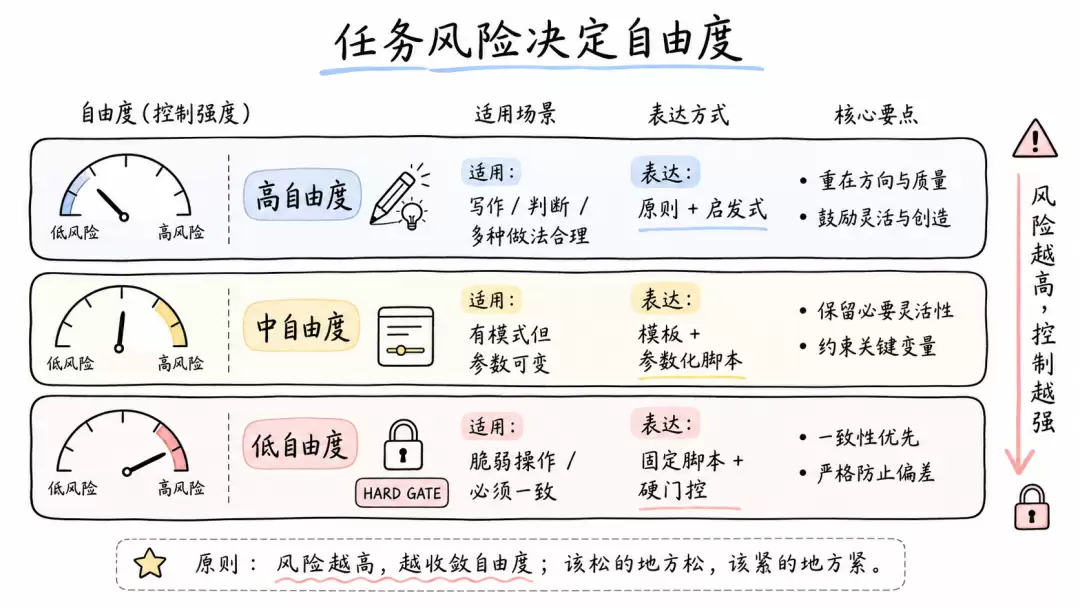
按任务风险设置自由度:文本、模板、脚本和门控

Skill不是越详细越好,也不是越开放越好。关键是让自由度匹配任务的脆弱度和变化空间。
可以把Skill的控制方式分成三档:
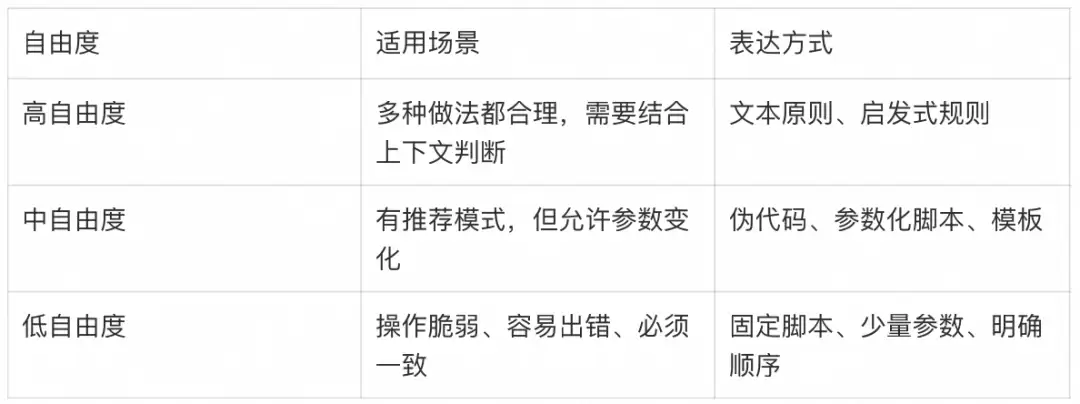
例如:
- 写技术文章:适合高自由度,用结构原则、语气规则和示例引导。
- 查询内部指标:适合中自由度,用SQL模板和字段说明控制口径。
- 旋转PDF、转换格式、生成固定报告:适合低自由度,用脚本保证确定性。
一个常见错误是把脆弱操作写成开放建议,导致Agent每次重写一遍容易出错的逻辑。另一个错误是把本该依赖判断的任务写成死流程,导致Skill在真实场景里僵硬、不可迁移。
在低自由度任务里,门控尤其重要。Skill如果只写“建议先做A”,Agent很可能直接进入B。门控的作用是:在条件满足前,明确禁止后续动作。
在理解具体使用示例并规划好可复用资源之前,不要创建或编辑该Skill。
常见门控包括:
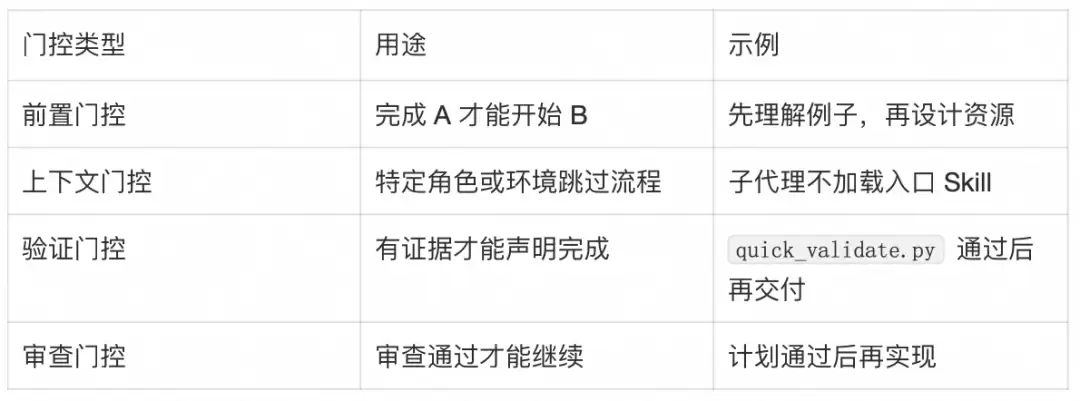
门控不是语气问题,而是执行边界。它能减少Agent的解释空间,让Skill在关键路径上更像程序,而不是建议。
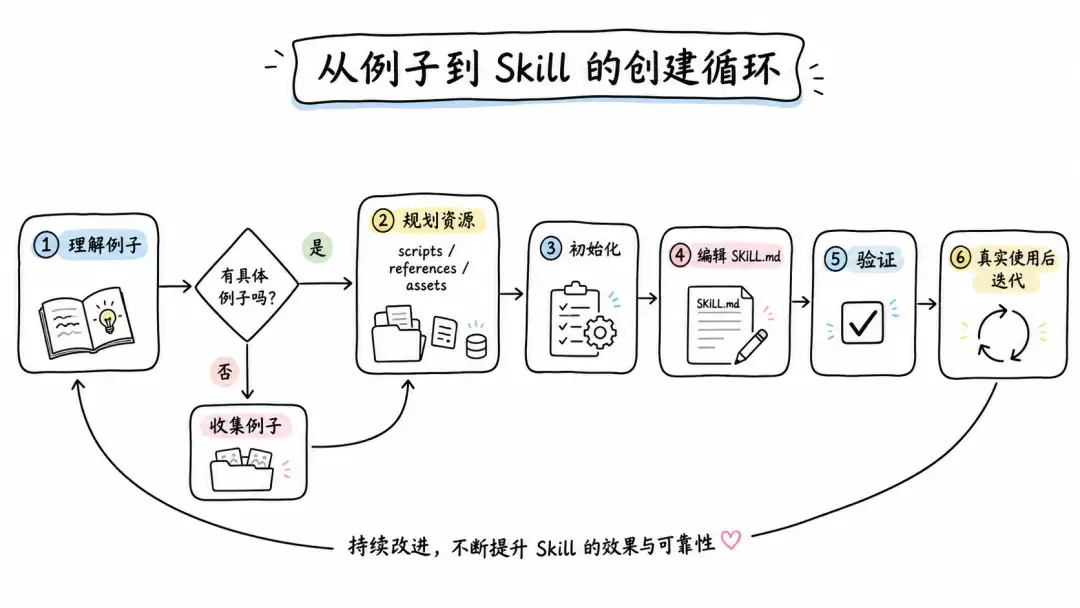
把流程写成可执行路径:从例子到 Skill 的创建循环

一个稳妥的Skill创建流程可以拆成六步:
- 理解具体使用例子
- 规划可复用资源
- 初始化Skill
- 编辑SKILL.md和资源
- 验证Skill
- 基于真实使用迭代
这条流程的重点不是“先写一个漂亮的说明”,而是先建立使用边界。不要从抽象能力开始写Skill。先问:用户会怎么触发它?哪些请求应该触发?哪些请求不应该触发?任务输入是什么?成功输出是什么?哪些步骤最容易出错?
例如做一个pdf-editor Skill,应该先收集“旋转PDF”“合并PDF”“提取页面”等具体请求,再决定是否需要脚本。没有具体例子,很容易写出宽泛但不可执行的Skill。
对每个例子,从零执行一遍,识别可复用部分:
当Skill包含非线性判断、循环、回退或容易提前终止的步骤时,流程图比纯文本更稳定。GraphViz DOT是一个适合嵌入Markdown的轻量格式:
digraph {
"是否有具体使用例子?"[shape=diamond];
"收集或生成例子"[shape=box];
"规划 scripts/references/assets"[shape=box];
"编写 SKILL.md"[shape=box];
"运行 quick_validate.py"[shape=box];
"完成"[shape=doublecircle];
"是否有具体使用例子?"->"规划 scripts/references/assets"[label="yes"];
"是否有具体使用例子?"->"收集或生成例子"[label="no"];
"收集或生成例子"->"规划 scripts/references/assets";
"规划 scripts/references/assets"->"编写 SKILL.md";
"编写 SKILL.md"->"运行 quick_validate.py";
"运行 quick_validate.py"->"完成";
}
复杂流程还需要编号检查表,并要求Agent外化进度。否则,Agent很容易执行前几步后忘记后面的验证和迭代。
初始化Skill时,应使用初始化脚本,而不是手写目录结构:
scripts/init_skill.py my-skill --path
"${CODEX_HOME:-$HOME/.codex}/skills"
如果需要资源目录:
scripts/init_skill.py my-skill --path
"${CODEX_HOME:-$HOME/.codex}/skills"--resources scripts,references
初始化脚本的意义是减少结构错误,并生成符合规范的模板。之后再替换占位内容,删除不需要的示例文件。
验证不是收尾动作:保护测试完整性,防止合理化

Skill不应该一次写完就冻结。它的质量来自真实行为反馈,而不是作者对流程的想象。
完成后首先运行基础验证:
scripts/quick_validate.py
基础验证至少应覆盖:YAML frontmatter是否合法,name和description是否存在,命名是否符合规则,资源目录是否合理,脚本是否能运行,UI元数据是否与SKILL.md同步。
格式验证不能证明Skill一定好用,但可以先排除低级错误。复杂Skill还需要前向测试。可以用子代里模拟真实用户任务,但要把它当成评估面,而不是审稿人。
正确做法:
使用位于 /path/to/skill-x的@skill-x来解决问题 y。
不好的做法:
审查这个Skill。我认为它存在问题A,预期的修复方案是B。
后者会泄露诊断和预期答案,测试结果会被污染。前向测试应该给子代里原始任务、原始材料和最少必要上下文,让它像真实使用者一样执行。
验证时应优先使用原始证据:示例prompt、输出文件、diff、日志、行为轨迹、失败截图、测试结果。如果子代里只有在看到你的结论后才能成功,说明Skill本身还不够清楚,或者测试设置已经泄露答案。
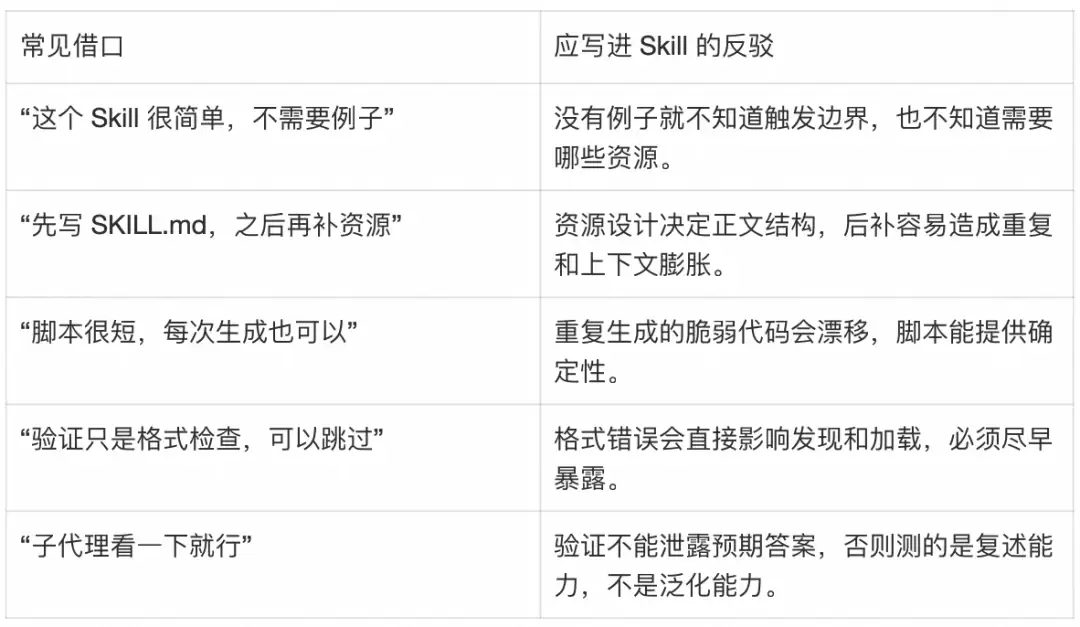
这里还要处理一个Agent特有的问题:合理化。AI Agent在压力下会给跳过规则找到听起来合理的理由。Skill需要提前写出这些借口,并给出反驳。
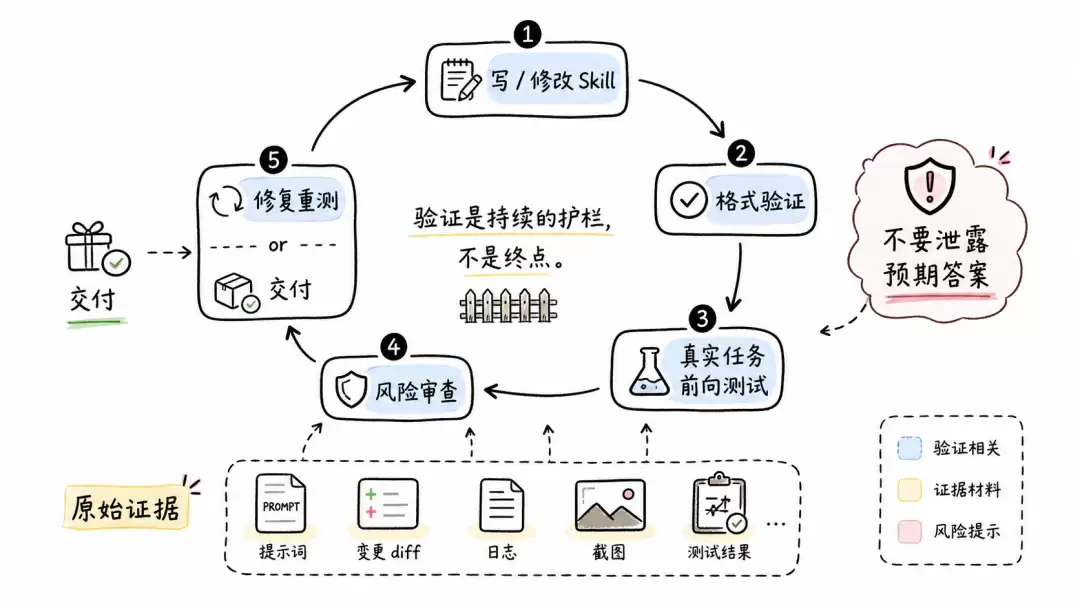
审查循环也应该围绕真实失败风险,而不是措辞偏好:
写或修改 Skill
->运行格式验证
->用真实任务前向测试
->是否存在会导致任务失败的问题?
->是:修复并重测
->否:交付
应该阻塞的问题包括触发条件模糊、资源引用缺失、脚本不可运行、验证流程缺失、自由度设置错误、关键信息重复且容易漂移。不应该阻塞的问题包括纯粹风格偏好、不影响执行的标题顺序、可以由Agent自行判断的轻微表达差异。
处理生态边界:发现、依赖和平台适配

当技能库变大后,发现机制会成为第一瓶颈。description是路由器,不是教程。它应该覆盖:Skill做什么、何时使用、典型触发词、相关症状、输入或任务类型。但不要写完整执行流程。
错误写法:
description:"创建Skill时先收集例子,再规划scripts/references/assets,然后运行init_skill.py,最后quick_validate.py。"
更好的写法:
description:"用于创建或更新包含专用工作流、工具集成、领域知识、捆绑脚本、参考资料、资产、验证或迭代机制的Agent Skill。"
前者让Agent可能只凭描述执行,跳过正文。后者让Agent知道应该触发,但仍需要加载正文获取完整流程。
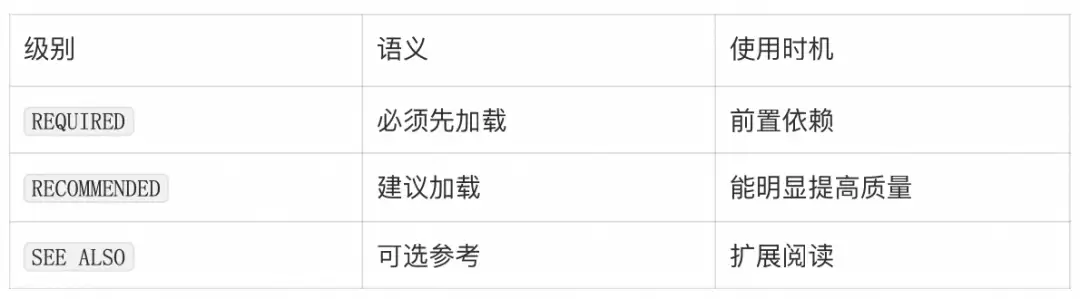
Skill之间也可以互相引用,但应该声明关系,而不是硬编码路径或强制加载大文件:
**必需子Skill:**创建新Skill前,先使用skill-x。
**推荐:**如果要将其发布为开发者文章,使用skill-y。
**另见:**openai_yaml.md,了解UI元数据字段。
引用可以分为三层:
不要用一次性强制加载大量内容的方式组合Skill。那会破坏渐进披露,也会让组合Skill的成本失控。
最后是平台适配。不同平台的工具名、hook、插件机制和子代里能力可能不同。Skill应该尽量写行为规则,再用平台层适配具体工具。
例如:
- TodoWrite -> todowrite
- Task tool -> @mention subagent system
- Skill tool -> native skill tool
平台能力不足时,应优雅降级:
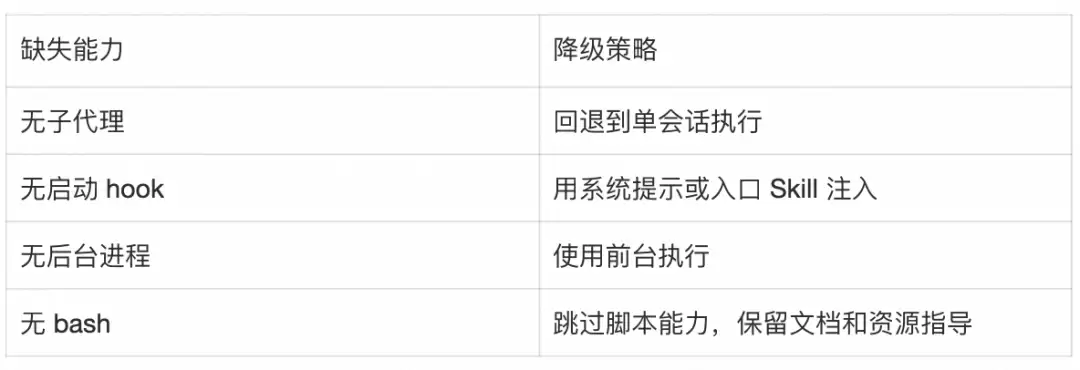
这能让Skill更可迁移,也更容易维护。真正应该稳定的是行为规则,而不是某个平台的私有工具名。
交付前自查:反模式和检查表

很多Skill失败,不是因为作者不知道领域知识,而是因为它把人类文档的写法带到了Agent执行系统里。
常见反模式如下:
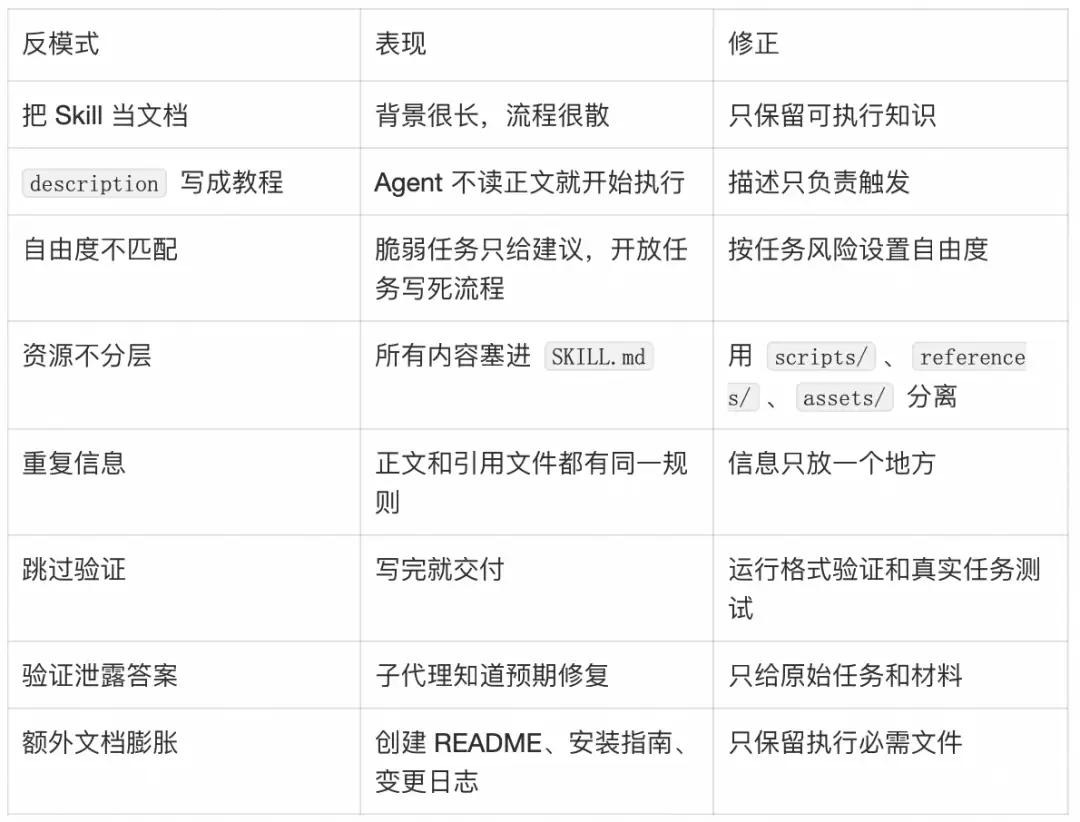
交付前可以用这张表自查:
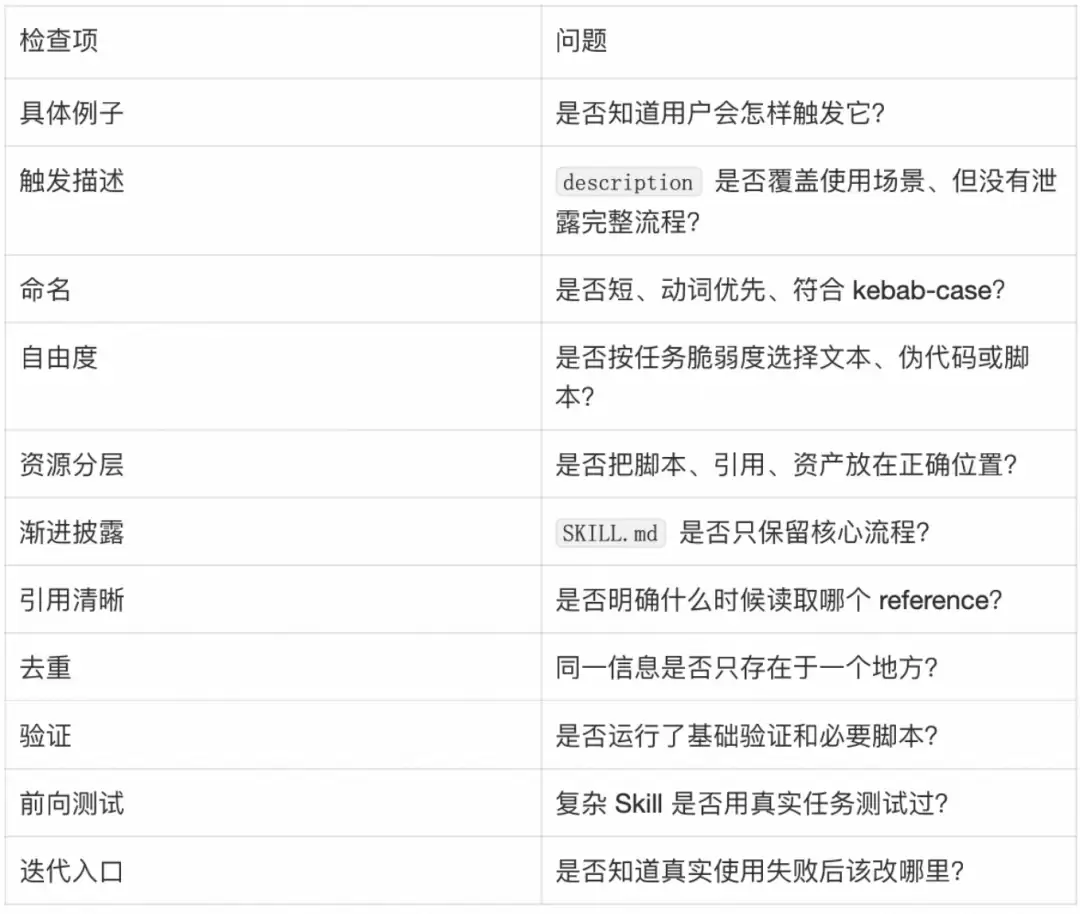
如果这张表里有多项答不上来,Skill还不是能力包,只是一份草稿。
结论:好 Skill 是小而准的行为系统

写Skill不是把最佳实践整理成Markdown。真正的Skill设计要回答三个问题:Agent在什么情况下应该发现并加载它?Agent应该获得多少自由度,哪些部分必须被脚本或门控固定?我们如何用真实任务证明它确实改变了行为?
核心的提醒是:Skill要简洁、分层、可验证、可迭代。上下文窗口是公共资源,SKILL.md只放核心流程;脚本承接确定性,引用承接领域知识,资产承接输出材料;复杂Skill要通过真实任务前向测试,而不是靠作者自信。
因此,Skill是Agent行为设计的一种工程方法。它把触发、加载、执行、约束、验证和迭代组织在一起,让通用Agent在特定任务上获得更稳定的专业行为。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:AI Agent技能系统设计指南要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看