




冷门新语言MoonBit AI训练:从零到及格线完整路线

先说说核心判断。对于Python、Ja va、Ja vaScript这些语言,大模型表现得相当成熟。 但换成那些更小众、样例不足的新兴语言呢?大模型到底是真的掌握了通用的编程能力,还是仅仅擅长处理训练数据中间出现无数次的语言? 答案来了。一篇新论文把这个问题的盖子揭开了一角。 这篇论文标题是《No
先说说核心判断。对于Python、Ja va、Ja vaScript这些语言,大模型表现得相当成熟。
但换成那些更小众、样例不足的新兴语言呢?大模型到底是真的掌握了通用的编程能力,还是仅仅擅长处理训练数据中间出现无数次的语言?
答案来了。一篇新论文把这个问题的盖子揭开了一角。
这篇论文标题是《No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages》,已经在arXiv上发表,并且已被IEEE Transactions on Software Engineering接收。它没有选Python、Ja va这些“富家子弟”,而是挑了两门相当年轻的选手:MoonBit和Gleam。
论文作者分别来自瑞士USI软件研究所(SEART研究组)和西班牙塞维利亚大学SCORE实验室(I3US研究所)。SEART长期深耕软件分析、开发者推荐系统和AI4SE,这让这份工作更像是一次来自软件工程研究圈的独立评估。
论文把这俩语言叫做“no-resource programming languages”,翻译过来就是“无资源编程语言”。
别误会,这不是说语言本身不行,而是它们太新、面世时间太短,导致公开的代码库、教程、问答和项目范例都还远远不够。大模型在预训练阶段,大概率没见过它们几次。
注:论文中统计数据的时间节点在2024年,到2025年6月,MoonBit的语料已经相对丰富了不少。
换句话说,这篇论文问了一个很扎心的问题:如果一门语言压根没被互联网语料喂饱,大模型还能把它写好么?
答案是:一开始,确实很难。
但更有价值的是,论文展示了另一种可能性:新语言不必苦等大模型自己“顿悟”。只要语言设计清晰、文档到位、代码和工具链齐备,它完全可以被系统地教给大模型。
编程语言被送进了新语言考场
论文为此专门建了三个代码生成基准测试:HumanEval、MBPP和McEval-Hard。
测试方法很直接:给模型一段自然语言描述和函数签名,让它补全函数实现,然后看测试用例能不能通过。
评分标准用的是pass@1——模型只有一次机会,一次性写出能通过的代码才算成功。
论文对比了三类语言:
- 高资源语言:Python、Ja va。
- 低资源语言:R、Lua、Haskell、Julia、Racket。
- 无资源语言:MoonBit、Gleam。
参与评测的模型包括GPT-4o、o3-mini、Qwen 2.5 Coder、Qwen 3等。论文还特别说明,HumanEval和MBPP被翻译成了MoonBit和Gleam版本,而McEval-Hard则基于McEval中的hard任务构建,最终形成跨语言对比的函数级代码生成任务。
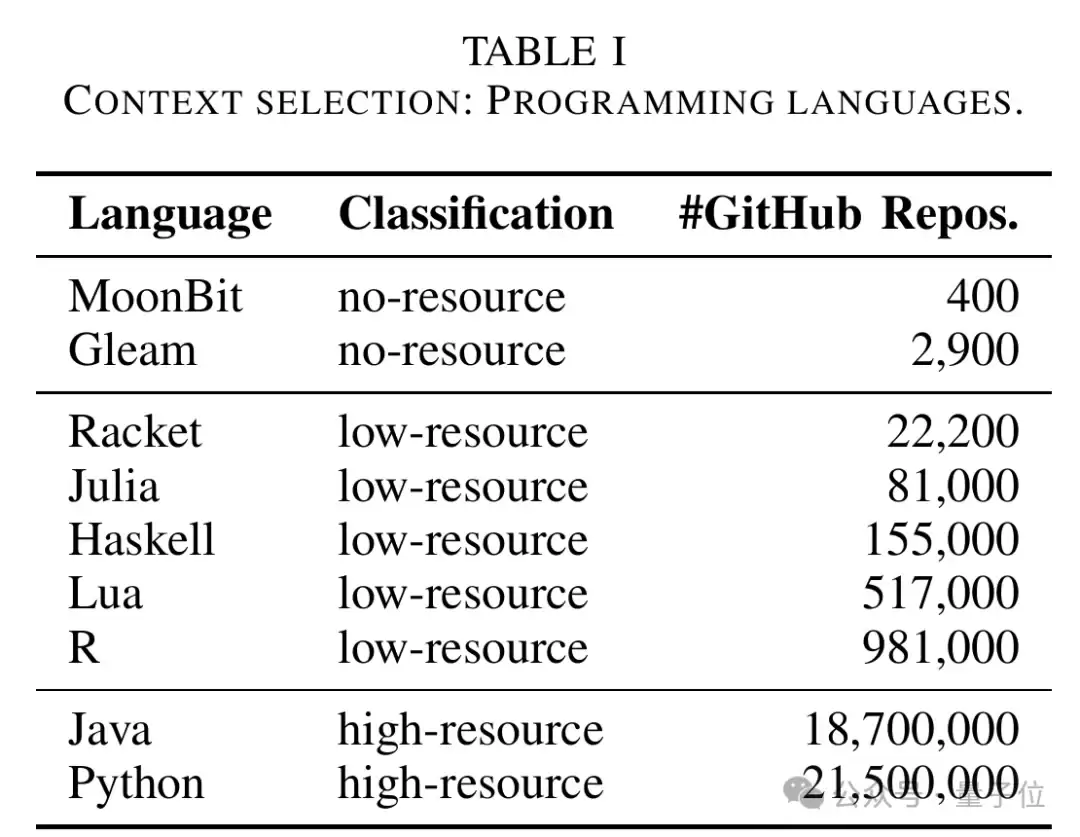
△论文中对不同语言GitHub仓库规模和资源类型的划分
零样本几乎失灵
结果并不意外,但非常有代表性。
在Python、Ja va这类高资源语言上,大模型表现依然凶猛;在低资源语言上,虽然有所下降,但依然可用;可一到MoonBit和Gleam,零样本的代码生成能力直接悬崖式下滑。
尤其是在更难的McEval-Hard上,高资源语言的pass@1大约在59%到89%之间,低资源语言在27%到84%之间,而低资源语言——只有0%到1%。论文进一步指出,无资源语言在多个模型和基准测试上的表现,通常落在0%到20%之间,平均约9%。
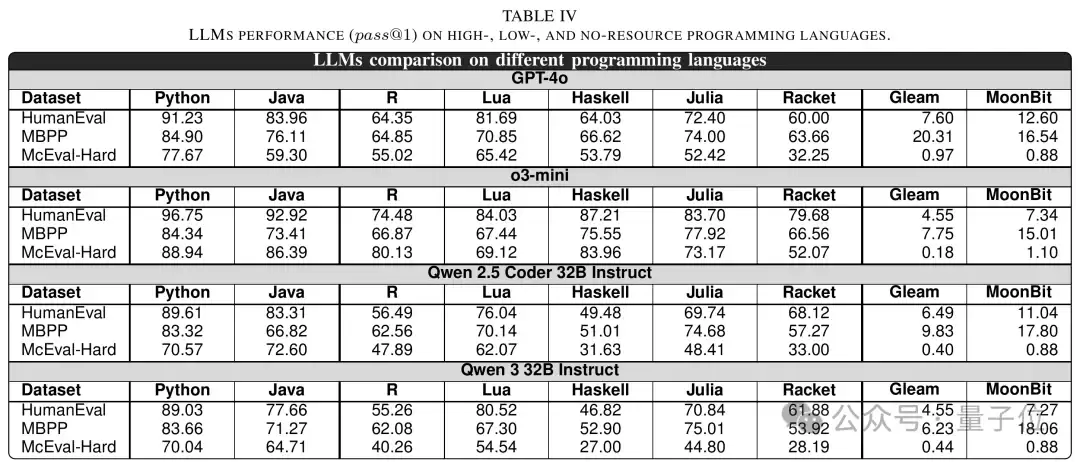
△零样本设置下,不同模型在不同语言上的pass@1对比
更关键的是,失败的原因远不止“算法没想明白”。
论文分析发现,在Gleam和MoonBit上,大量失败来源于语法错误。换句话说,模型常常连一段语法合法的代码都生成不出来。
这不能说明MoonBit不行。
更准确地说,是模型压根儿没真正学过MoonBit。大模型写Python稳如老狗,很大程度上是因为它见过的Python代码实在太多了。MoonBit作为一门年轻的语言,公开语料规模自然远小于成熟语言,因此正好用来观察一个核心问题:
AI时代的新编程语言,到底该如何被模型学习和理解?
临时给点例子有用,但不够
论文先测试了两种常见方法:few-shot和RAG。
Few-shot就是在提示词里塞几个MoonBit代码示例,让模型照着学。RAG则是从MoonBit文档里检索相关内容,塞进提示词里,让模型参考着写。
这两种方法都有提升。论文观察到,few-shot效果一般比RAG稍好:在MoonBit的12组对比中,有8组是few-shot更好。作者推测,面对一门陌生的语言,模型从代码示例中抓取语法规则,比从零散文档片段中理解逻辑要更直接。
不过,这类方法的上限也很明显。临时塞进去几段代码或文档,顶多补点语法知识,很难让模型真正掌握一门语言的精髓。
继续预训练:让模型真正学会
真正奏效的,是继续预训练。
说白了,就是不再让模型临时抱佛脚,而是直接用MoonBit的代码和官方文档,对模型进行持续的增量训练。
论文里,MoonBit的继续预训练数据包括约1310万code tokens和60万documentation tokens,总计约1370万tokens。作为对比,可用于微调的MoonBit数据只有约50万tokens。
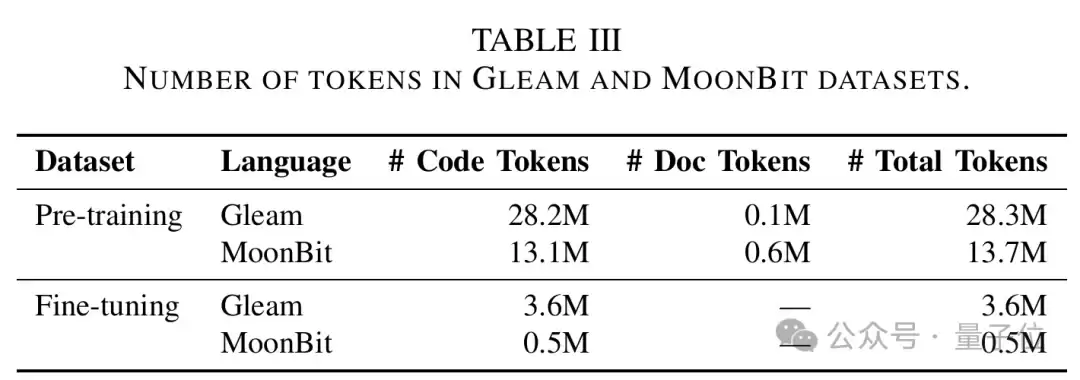
△论文中用于MoonBit/Gleam的预训练与微调数据规模
结果提升非常明显。
以Qwen 2.5 Coder 32B Base为例,继续预训练之后,模型在MoonBit上的pass@1达到:
- HumanEval:41.62%
- MBPP:44.76%
- McEval-Hard:25.86%
换句话说,从几乎不会写,到能在相当一部分任务上写出可通过测试的代码,MoonBit完全可以被模型系统地学会。
指令迁移:既懂编程语言,也听得懂开发者
不过,继续预训练还没解决全部问题。
它能让模型学会语言知识,但不一定能让它更擅长遵循用户指令。而真实的AI编程助手,不只是续写代码,还要能理解开发者的需求——比如解释类型错误、重构代码、补测试用例、根据反馈修改实现。
所以论文进一步使用了“指令迁移”技术。
思路很简单:先用MoonBit的代码和文档把base model教会写MoonBit,再把一个已经具备指令跟随能力(instruct model)的对话能力,迁移到这个已经学会MoonBit的模型上。
这样一来,得到的模型既懂MoonBit,又像一个能对话、能听懂需求的编程助手。
这一方法给出了论文中最强的MoonBit结果:在Qwen 2.5 Coder 32B上,指令迁移后,MoonBit的pass@1达到:
- HumanEval:50.71%
- MBPP:53.04%
- McEval-Hard:32.60%
尤其是最难的McEval-Hard,MoonBit从零样本接近0%,直接提升到了32.60%。
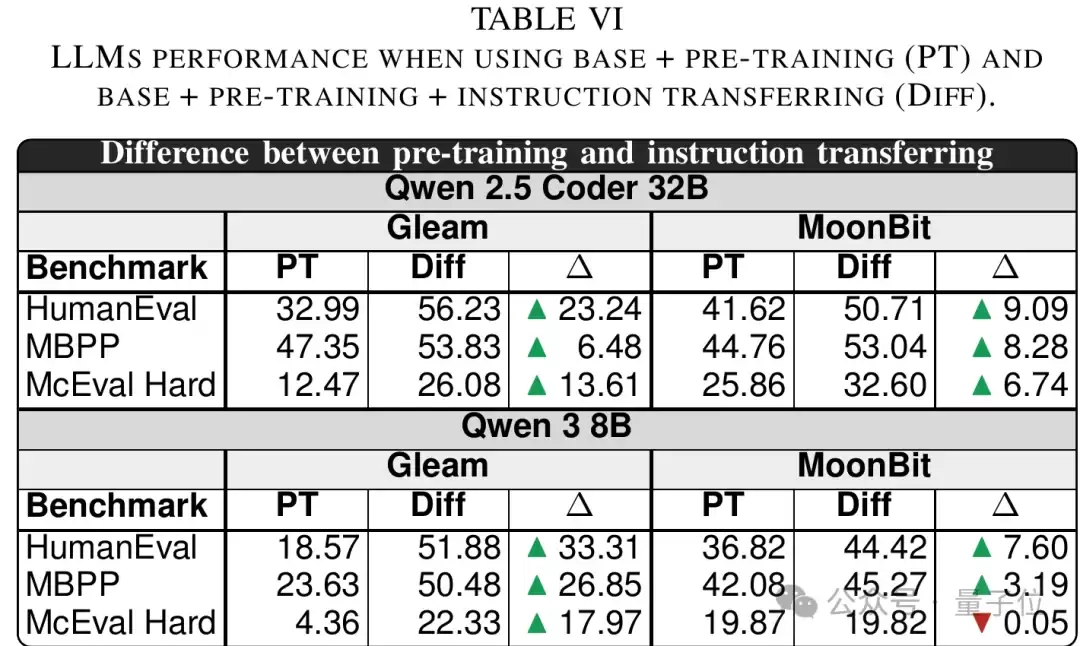
△进一步预训练与instruction transferring的效果对比
这组数字背后有一个关键信号:新语言的AI支持,不必干等着更大的通用模型某天自然覆盖。通过高质量代码、官方文档、标准基准测试和合适的训练方法,完全可以主动构建起来。
观察价值:让模型更容易学会新语言
这也是MoonBit值得观察的地方。
MoonBit官方将其定位为面向云和边缘计算的AI-native编程语言工具链,支持wasm、wasm-gc、js和native后端,并且支持在一个模块中构建混合后端项目。官方文档还强调更小的WASM输出、更快的运行时性能、先进的编译性能,以及简洁实用、面向数据的语言设计。
对AI编程来说,这一点非常关键。
因为AI写代码不是一次性生成文本,而是一个循环。语言设计越清晰,工具链反馈越完整,这个循环就越容易自动化。
MoonBit的AI-native设计也体现在语言结构上。其官方博客曾讨论过“扁平化设计”(flattened design):明确区分顶层定义和局部定义,顶层定义强制要求类型签名,并采用结构化的接口实现,减少额外嵌套代码块。博客还提到,这种减少嵌套的设计不只提升了可读性,也天然对KV-cache友好,有利于RAG、decoder correction、backtrack等场景下的模型推理效率。
对开发者来说,这意味着更清晰的代码组织;对模型来说,则意味着它更适合线性生成。模型不用在复杂的嵌套结构里频繁跳转,上下文组织更稳定,生成错误也更容易被工具链及时发现。
过去评价一门编程语言,我们看性能、语法、类型系统、标准库、工具链和生态。如今到了AI编程时代,还必须增加一个维度:模型是否容易学会这门语言。
这篇论文的价值正在于此。它不仅指出了“大模型不会天生写好新语言”这一现实,更重要的是给出了一条可执行的路径:先构建基准评测,摸清模型哪里不会;再拿真实代码和官方文档持续训练,让模型掌握语言本质;最后通过指令迁移,把指令跟随能力融合回来。
MoonBit在这条路径中的表现表明,AI-native编程语言不只是一个营销概念,而是可以切切实实体现在模型学习效率、代码生成质量和工具链闭环中的工程优势。
大模型写Python很强,是因为它见过太多Python。大模型一开始不熟悉MoonBit,是它足够新。但当模型真正接触到MoonBit的代码、文档和语言设计之后,它可以快速提升。
这也许正是AI时代新语言生态的核心问题:不是等待模型某一天自然支持你,而是从语言、文档、工具链和数据开始,让模型更容易理解你。
MoonBit提供了一个值得观察的样本。
论文标题:《No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages》
链接:https://arxiv.org/abs/2606.16827
MoonBit相关数据来源:swe-agi (https://arxiv.org/abs/2606.16827)
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:冷门新语言MoonBit AI训练:从零到及格线完整路线要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在语言学习领域,AI 技术究竟能达到怎样的高度?过去几年,各类工具层出不穷,但真正能模拟真实对话、根据用户水平动态调整难度与话题的产品却屈指可数。LingoFella 的诞生,为这一领域注入了一股全新的活力。 LingoFella 是什么?AI 个性化语言学习工具解读 简单来说,LingoFella
在企业数据采集领域,传统问卷的局限性日益凸显——填写率持续走低、答案内容敷衍、深层信息难以获取。Wa veform ai 提供了一种创新方案:采用 AI 语音表单替代传统调查方式,让数据采集过程更加自然高效,从而获得更具洞察力的用户反馈。 什么是Wa veform ai? 通俗来讲,Wa vefor
在招聘流程中,初筛和面试通常是最耗时的环节。候选人众多、时间紧迫、标准需统一——能否借助机器来分担?Talkpush Sam 正是为此设计的 AI 语音面试助手。它能与求职者实时对话,自动完成信息采集与智能筛选评估,通话结束后即可生成匹配分数和详细报告。简而言之,Sam 能实现初筛面试的全面自动化,
你是否曾想过,如果拥有一款既能深刻理解ADHD带来的混乱感、又能像贴身教练一样帮你理清思绪的AI伙伴,生活将变得多么轻松?Comigo正是为此而生——它将循证行为疗法与高效生产力工具融为一体,专为ADHD人群设计,同时也适合任何希望改善情绪、提升动力与优化状态的人,提供真正个性化的支持。它全天候在线
- 日榜
- 周榜
- 月榜
热点快看