




机器学习中特征工程的作用与意义解析

1、特征工程与意义 特征,说白了就是从原始数据里提取出的、能帮我们预测结果的有用信息。而特征工程,就是用专业知识和各种技巧去处理数据,让这些特征能更好地服务于机器学习算法。这个过程的本质,是决定模型上限的关键一环——数据决定了模型的天花板,而特征工程就是那个搭梯子的人。 2、基本数据处理 数据采集
1、特征工程与意义
特征,说白了就是从原始数据里提取出的、能帮我们预测结果的有用信息。而特征工程,就是用专业知识和各种技巧去处理数据,让这些特征能更好地服务于机器学习算法。这个过程的本质,是决定模型上限的关键一环——数据决定了模型的天花板,而特征工程就是那个搭梯子的人。
2、基本数据处理
数据采集
做特征工程前,先得想明白三个问题:哪些数据真的有用?这些数据能不能容易地采集到?线上实时计算时获取起来快不快?这三个问题想清楚了,后面的路才好走。
数据清洗
数据清洗的核心任务就是——洗掉脏数据。怎么洗?可以从两个角度入手:
- 单维度考量:身高3米?不可能。一个月买脸盆墩布花了10万?也不太现实。
- 组合或统计属性判定:号称在美国但IP一直在大陆的新闻阅读用户,明显有问题。再比如,你要预测一个人会不会买篮球鞋,可样本里女性占了80%,这数据本身就有偏差。
- 统计方法:用箱线图的上下界来识别异常值,或者直接去掉缺省值特别多的字段。总之,不可信的样本要果断剔除,缺省值太多的字段干脆就别用了。
数据采样
分类问题里,正负样本不均衡是家常便饭——比如患病和健康人群的数据。大多数模型(像逻辑回归)对样本比例很敏感。
怎么办?通常有几种思路:
- 随机采样/分层采样。如果正样本远多于负样本,且数据量都很大,就在正样本里做下采样。比如正样本200万,负样本20万,那就从正样本里随机抽20万,凑成1:1的比例来训练。
- 如果正样本多但数据量不大:要么采集更多数据,要么做上采样(过采样)。比如10万正样本、1000负样本,最简单的是把负样本重复几遍,但这样容易过拟合。更聪明的方法是给负样本加点变化——图像识别里判断是不是猫,可以把图片旋转、镜像、加点噪声。
- 修改损失函数:另一种方案,通过调整损失函数的权重来平衡样本影响。
3、常见特征工程
数值型特征
数值型特征的处理方式有很多:
- 幅度调整/归一化:包括缩放(Scaling)、标准化(Standardization)、归一化(Normalization)。
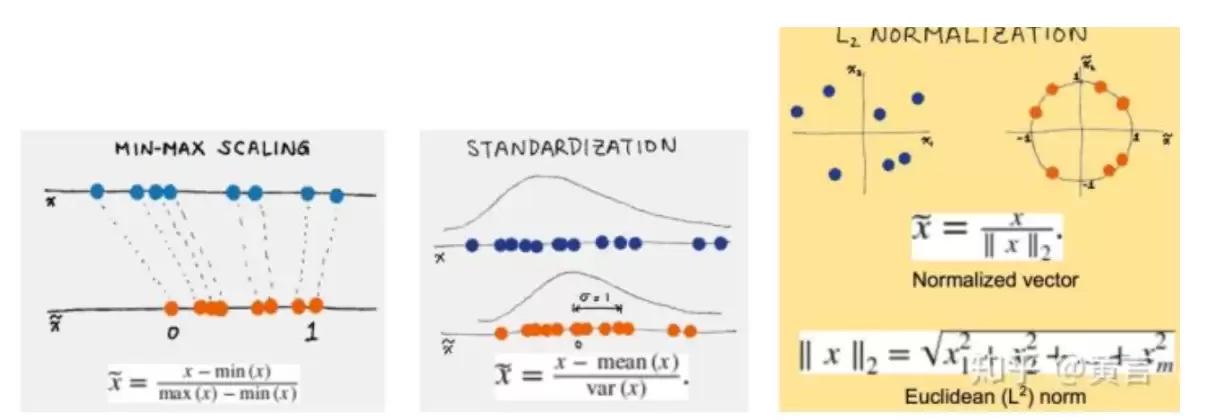
- 对数变换:对数值做log等变换,可以拉平长尾分布。
- 统计值:提取最大值、最小值、均值、标准差等。
- 离散化:把连续值按区间切分(分箱、分桶)。比如下面这段代码,生成20个标准高斯分布的随机数,用pandas的cut函数分成4个区间:
import numpy as np import pandas as pd arr = np.random.randn(20) factor = pd.cut(arr,4) factor Out[5]: [(-0.643, 0.329], (0.329, 1.302], (-1.616, -0.643], (-1.616, -0.643], (-0.643, 0.329], ..., (-0.643, 0.329], (-0.643, 0.329], (-0.643, 0.329], (0.329, 1.302], (-1.616, -0.643]] Length: 20 Categories (4, interval[float64]): [(-2.593, -1.616] < (-1.616, -0.643] < (-0.643, 0.329] < (0.329, 1.302]]
- 高次与四则运算特征:通过高次多项式或四则运算,把数据升维,挖掘非线性关系。
- 数值转类别:把数值映射成类别标签。
类别型特征
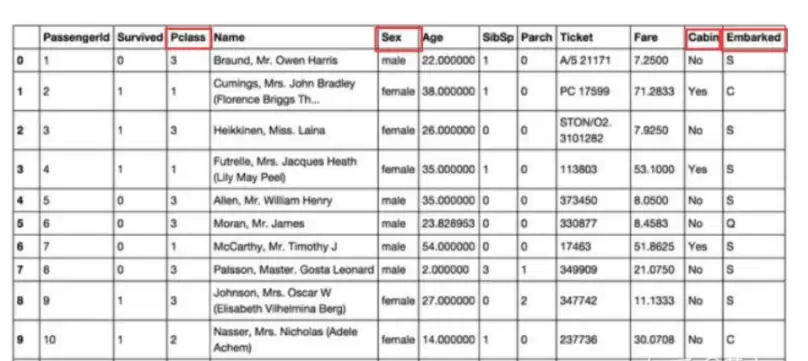
- One-hot编码/哑变量:把类别展开成多个0/1向量。注意,如果类别太多,one-hot会带来维度灾难,不太适用。
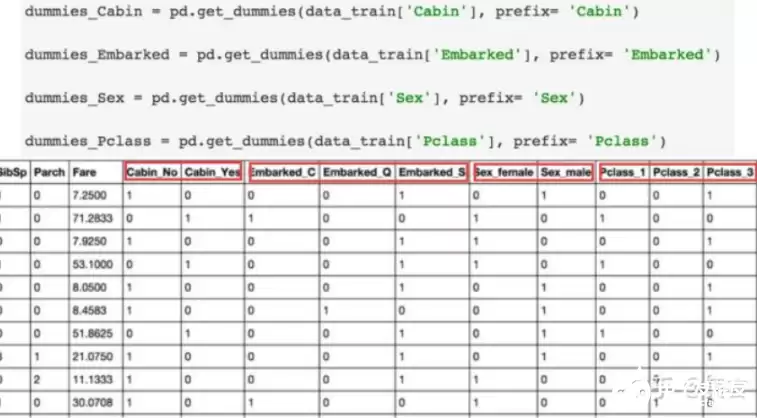
- Hash技巧:将文本型数据映射成固定长度的向量,避免高维稀疏。
时间型特征
时间型数据很有意思,既可以当作连续值(比如时间戳的差值),也可以当作离散值(比如星期几、月份、季节)。具体怎么用,取决于业务需求。
其他类型
文本型
- 词袋模型(Bag of Words):把文本预处理后去掉停用词,剩下的词在词库中映射成稀疏向量。
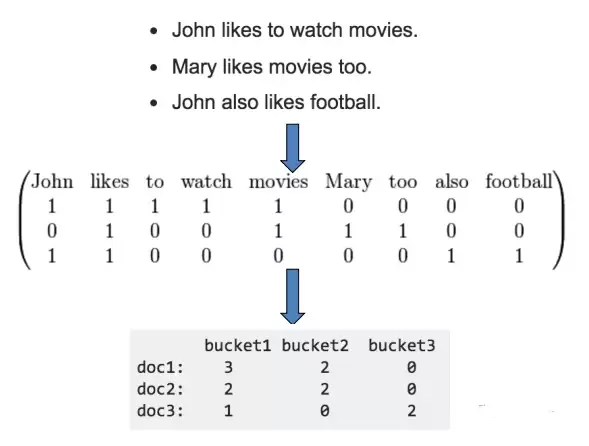
但词袋模型丢了词的顺序信息,所以可以引入n-gram。比如下面这张图,把“Bi-grams are cool!”这句话映射成1个单词和2个单词的组合。

- Tf-idf特征:统计方法,评估一个字词在文件集中的重要程度。它结合了词频(TF)和逆文档频率(IDF)。
TF(t) = (词t在当前文中间出现的次数) / (t在全部语料库中间出现的次数) IDF(t) = ln(总文档数 / 含t的文档数) TF-IDF权重 = TF(t) * IDF(t)
统计特征
包括加减平均、分位线、次序型、比例型等。例如下面这张图展示了一个特征处理的示例。

4、特征选择方法
特征选择的意义很明确:一是去掉冗余特征,减少计算开销;二是剔除噪声,避免对预测造成负面影响。
特征选择 vs 降维:特征选择是直接剔除和预测关系不大的特征,而降维(如SVD、PCA)是压缩数据但保留大部分信息。两者都能解决高维问题,但思路不同。
过滤式特征选择
方法很直观:计算每个特征和目标值之间的相关程度,排个序,留下排名靠前的特征。常用的指标有Pearson系数、互信息、距离相关度等。
缺点也很明显:它只考虑单个特征与目标的关系,忽略了特征之间的交互作用,可能会误删一些本身不显著但组合起来很有用的特征。
相关Python包:

#SelectKBest选择排名前k个的特征 from sklearn.datasets import load_iris from sklearn.feature_selection import SelectKBest #chi2是卡方统计量 from sklearn.feature_selection import chi2 iris = load_iris() X, y = iris.data, iris.target # 之前的X数据集是有4个特征的 X.shape Out[13]: (150, 4) # 使用SelectKBest,使用卡方统计量,选出top2的两个特征 X_new = SelectKBest(chi2, k=2).fit_transform(X, y) X_new.shape Out[15]: (150, 2)
包裹式特征选择
包裹式方法把特征选择看作一个子集搜索问题:枚举各种特征子集,用模型的实际表现来打分。典型的算法是递归特征删除(RFE)。
举个例子,用逻辑回归怎么操作?
- 先用全量特征跑一个模型;
- 根据线性模型的系数(体现特征重要性),删掉5%-10%的特征;
- 观察准确率或AUC的变化;
- 逐步重复,直到准确率/AUC出现明显下滑才停止。
相关Python包:

from sklearn.feature_selection import RFE from sklearn.linear_model import LinearRegression from sklearn.datasets import load_boston boston = load_boston() lr = LinearRegression() rfe = RFE(lr, n_features_to_select=1) X = boston["data"] # 数据有13个特征 X.shape Out[27]: (506, 13) Y = boston["target"] names = boston["feature_names"] rfe.fit(X, Y) Out[28]: RFE(estimator=LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False), n_features_to_select=1, step=1, verbose=0) # 使用递归特征删除算法,将数据的13个特征排序,数字为对应特征的序号 rfe.ranking_ Out[29]: array([ 8, 10, 9, 3, 1, 2, 13, 5, 7, 11, 4, 12, 6])
嵌入式特征选择
嵌入式方法是在模型训练过程中自动完成特征选择,比如利用正则化。最常见的套路就是用L1正则化来做特征选择(因为它会让不重要的特征系数变成0),而L2正则化主要用来防止过拟合。
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_selection import SelectFromModel iris = load_iris() X, y = iris.data, iris.target # 之前的特征数为4 X.shape Out[6]: (150, 4) # 使用线性SVM分类器,正则化选L1 lsvc = LinearSVC(C=0.01, penalty='l1', dual=False).fit(X, y) model = SelectFromModel(lsvc, prefit=True) X_new = model.transform(X) # L1正则化后选择的特征数为3 X_new.shape Out[10]: (150, 3)
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:机器学习中特征工程的作用与意义解析要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看