




人工智能大模型检索增强生成框架Dify深度解析

在生成式AI技术迅猛发展的背景下,Dify作为一款面向开发者的开源大语言模型应用开发平台,正在深刻改变AI应用的构建方式。它诞生于2023年前后,核心目标非常明确:通过低代码化与模块化设计,使开发者无需从零搭建复杂架构,即可快速部署生产级AI应用。随着大语言模型(LLM)技术的普及,Dify逐渐成为
在生成式AI技术迅猛发展的背景下,Dify作为一款面向开发者的开源大语言模型应用开发平台,正在深刻改变AI应用的构建方式。它诞生于2023年前后,核心目标非常明确:通过低代码化与模块化设计,使开发者无需从零搭建复杂架构,即可快速部署生产级AI应用。随着大语言模型(LLM)技术的普及,Dify逐渐成为连接算法能力与业务需求的关键桥梁——这让人联想到当年Spring Boot的崛起,但这一次,它精准瞄准了AI应用开发中的痛点。
一、背景与发展历程
Dify的核心理念可以概括为一句话:让AI应用的开发不再从零起步。它通过将模型调用、知识库管理、任务调度等核心功能模块化,使开发者能够像搭积木一样轻松构建AI应用。这种设计思路恰好回应了业内长期存在的矛盾:一方面是大模型能力的快速迭代,另一方面是应用落地的复杂性与高门槛。
二、核心原理与技术特点
要真正理解Dify的价值,关键在于弄清它的整体架构与技术思路。
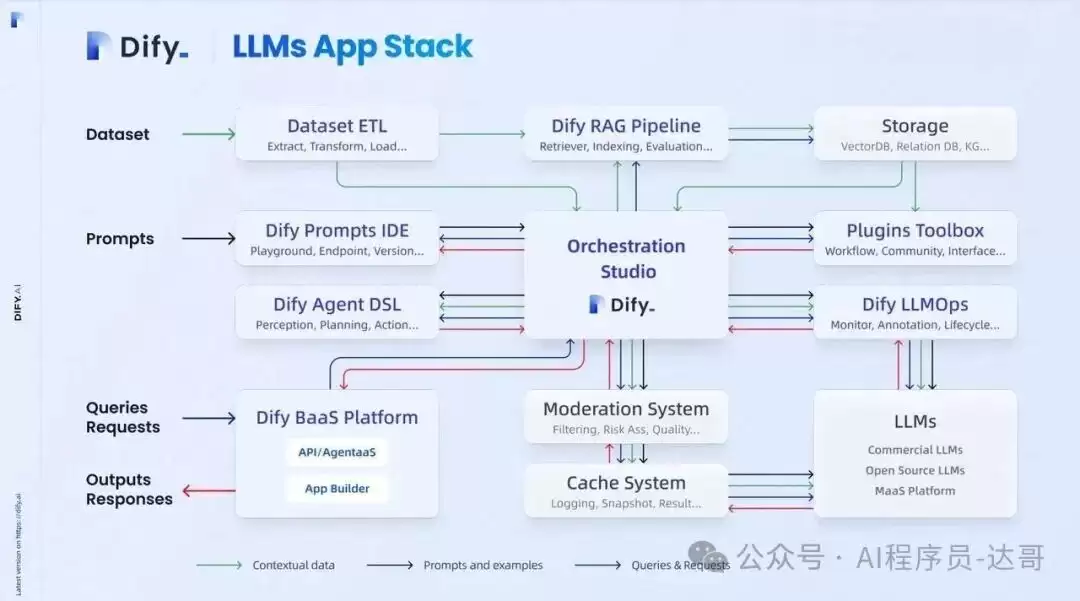
(1)核心架构原理
1. 分层架构设计
Dify采用前后端分离的现代Web开发模式,前端界面与后端服务各自独立运行,通过RESTful API进行交互。这意味着前端团队和后端团队可以并行工作,互不干扰。更深一层,它将核心功能拆解为知识库管理、模型调度、任务队列等独立模块,支持按需扩展或替换。这种模块化设计带来的好处非常直接:某个模块出现问题不会拖累整个系统;需要升级某个能力,只需替换对应的模块即可。
2. 数据流与处理
在数据流方面,Dify的核心亮点在于检索增强生成(RAG)与异步任务处理。RAG通过向量化技术将文档转化为语义向量,再结合大模型生成答案——这有效解决了传统模型知识更新滞后的问题。举个例子,如果公司内部的客服知识库每个月更新一次,传统做法需要重新训练模型,而RAG只需更新向量库即可。异步任务处理则利用消息队列(如Celery)处理文档解析、模型推理等耗时操作,避免阻塞主线程,从而大幅提升系统并发能力。
这套设计既保证了系统的灵活性,也兼顾了整体性能表现。
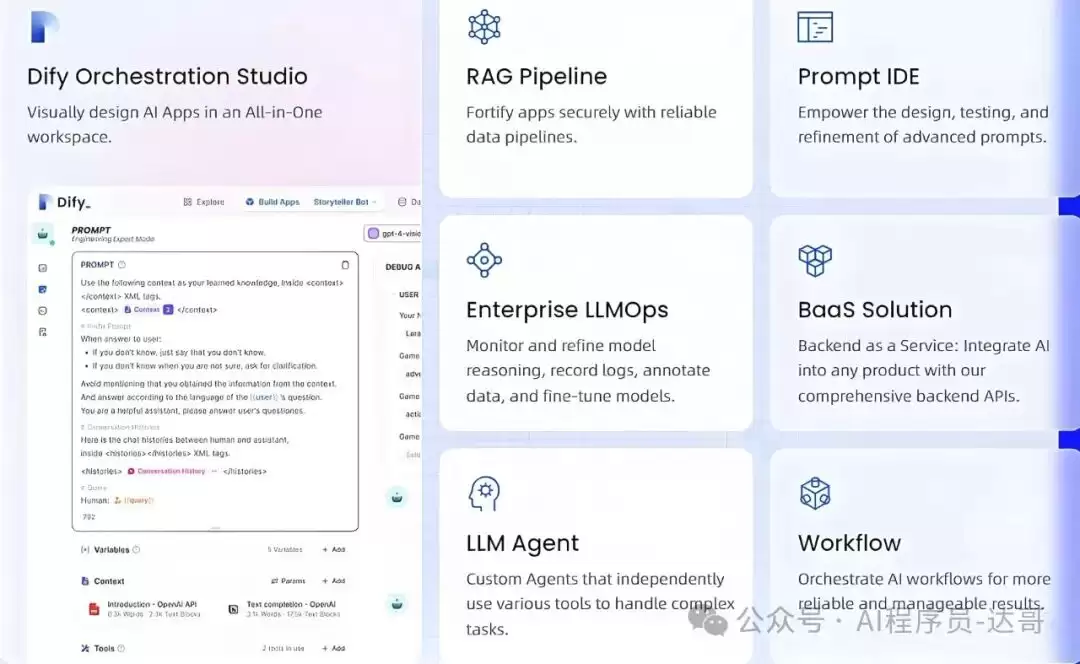
(2)核心技术特点
1. 低代码开发能力
可视化工作流是Dify的一大亮点。它提供了图形化界面(类似一张画布),让开发者可以通过拖拽方式编排数据处理、模型调用、结果反馈等节点。配合内置的Prompt IDE,还可以实时对比不同模型(如GPT-4与LLaMA)的输出效果,针对性地优化生成质量。这种“所见即所得”的方式大大降低了试错成本。
2. 全链路LLMOps支持
从模型选择、微调、部署到监控,Dify覆盖了完整的模型生命周期管理。它支持A/B测试与性能分析,方便开发者对比不同模型在实际场景中的表现。日志与可观测性方面,系统实时追踪请求响应时间、错误率等指标,一旦出现异常,开发人员可以快速定位问题。这些能力在传统开发中可能需要额外搭建一套监控系统,而在Dify中已内置集成。
3. 多模态与智能体扩展
Dify预置了50余种工具,包括谷歌搜索、DALL·E绘图、WolframAlpha计算等,通过API即可快速调用。更关键的是它的智能体(Agent)框架——基于ReAct或函数调用机制,开发者可以自定义工具链,实现类似“自动编写代码并执行”的复杂任务。这种扩展性让Dify不只是一个开发平台,更像一个AI应用的“操作系统”。
4. 高效知识库管理
在知识库管理方面,Dify支持多格式文档自动解析:PDF、PPT、Word等文件上传后,系统自动提取文本并分块向量化。为提高检索准确性,它采用了混合检索策略——结合语义搜索(向量匹配)与关键词匹配,在准确性与召回率之间找到最佳平衡。这一点在实际应用中尤为重要,因为用户提问的方式往往千差万别。
(3)关键技术实现细节
这里需要提一下具体的技术选型。在向量化方面,Dify支持主流的嵌入模型(如OpenAI的text-embedding-ada-002或开源的Sentence-BERT);在模型调度层面,它对接了多个大语言模型的API,包括OpenAI、Azure、Hugging Face等。这种灵活性使得不同预算与场景的团队都能找到适合的选择。

(4)典型应用场景
从实际落地的案例来看,Dify的典型应用场景集中在三个方面:
智能客服系统是最常见的用法。通过RAG从知识库检索答案,结合大模型生成自然语言回复,既保持了准确性,又赋予了对话的自然感。
自动化数据分析是另一个重要方向。借助WolframAlpha等工具,Dify可以处理复杂的数学计算,生成可视化图表,让非技术人员也能轻松进行数据分析。
多模态内容创作则展示了Dify的扩展能力。通过串联文本生成(GPT-4)与图像生成(Stable Diffusion),可以实现图文混排的内容输出,例如自动生成产品手册、社交媒体帖子等。
三、本地部署与API集成
1. 本地部署步骤
Dify的本地部署并不复杂,但需要做好前期准备。首先安装Docker和Python 3.8+,然后从GitHub克隆仓库。接下来在configs目录下修改数据库连接、模型API密钥等参数。最后通过Docker Compose一键启动前后端服务,访问localhost端口即可使用。
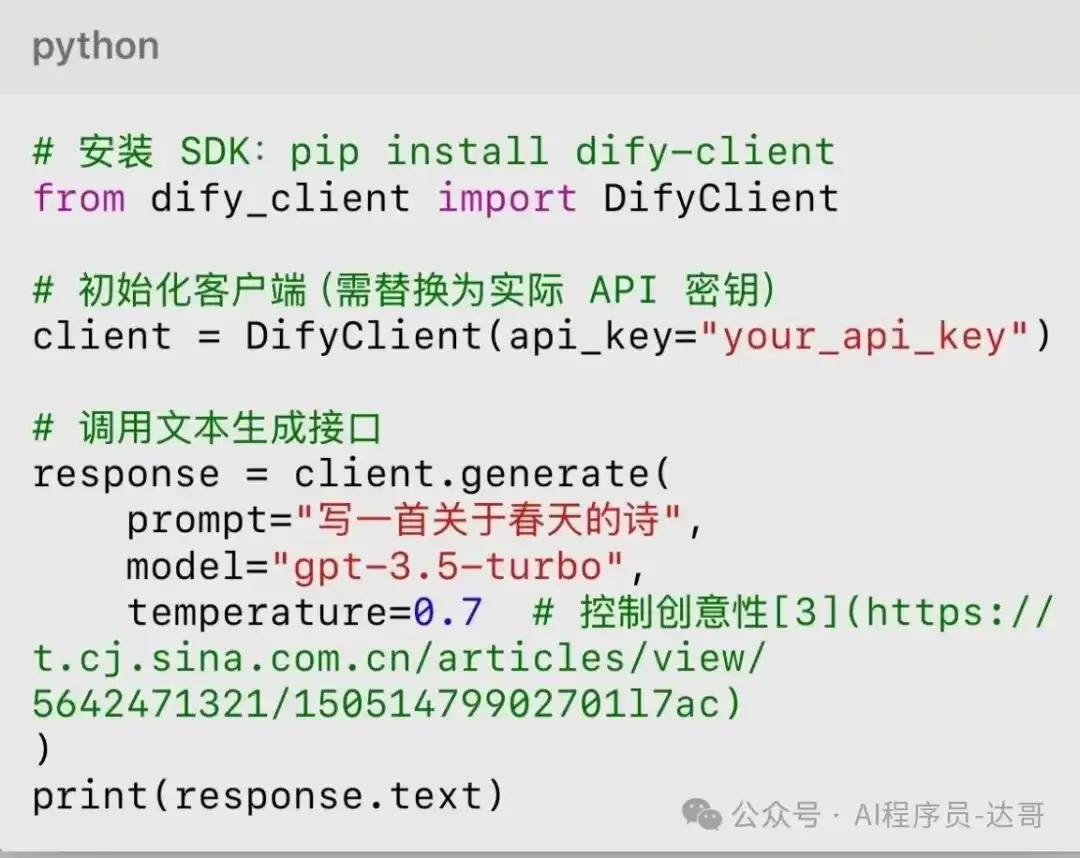
2. API集成示例
Dify提供了RESTful API与Python SDK(dify-client),调用流程如下:
四、Python实战案例:搭建问答机器人
这里用一个具体场景来说明:快速部署一个基于本地知识库的客服问答系统。
步骤非常清晰:
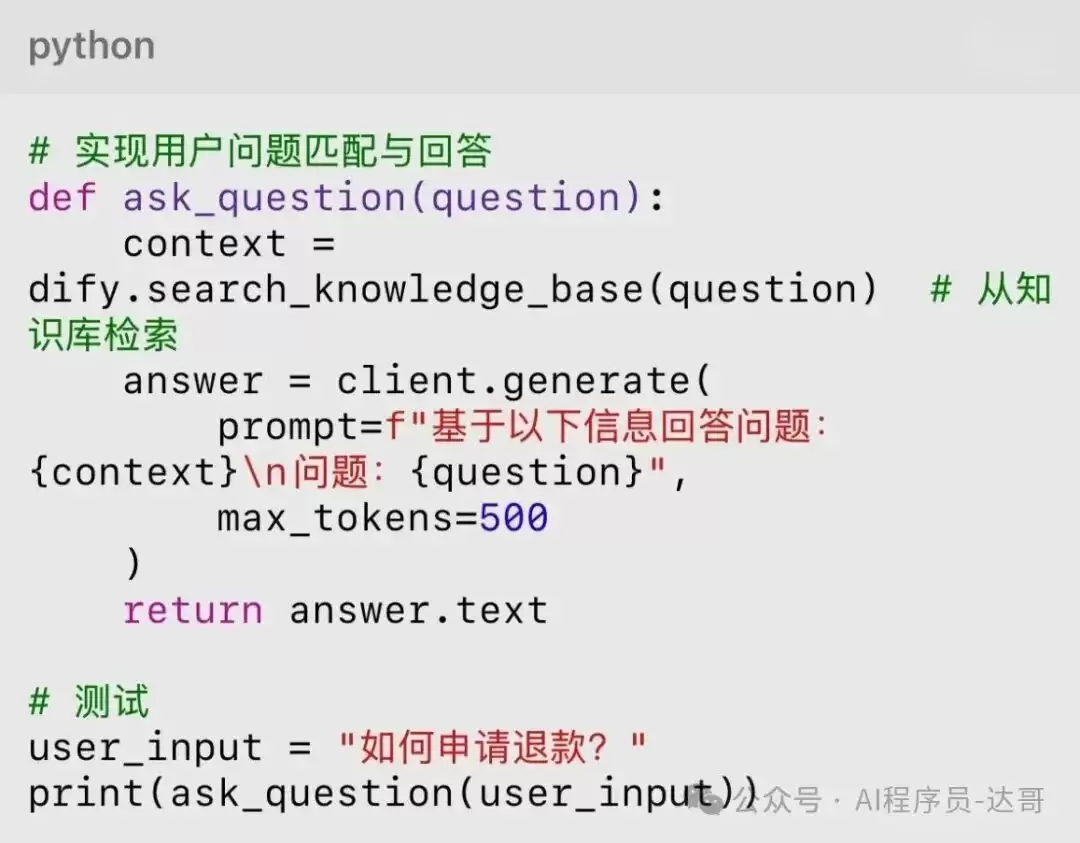
数据准备:将客服文档(PDF或Word格式)上传至Dify知识库,系统会自动进行分词与向量化处理。
配置模型:选择GPT-3.5或开源模型如LLaMA,设置最大上下文长度(如4096 tokens)。
编写交互逻辑:通过Python SDK调用API,实现对话交互。
五、学习建议
对于想要上手Dify的开发者,有几个关键点值得优先掌握:Transformer架构基础(如注意力机制)是理解大模型行为的重要前提;Python异步编程则对处理高并发请求至关重要。
避坑指南方面,需要提醒一下:不少团队一开始容易过度依赖云端模型,但这往往带来成本问题。本地部署时可以优先选择量化压缩的小模型,比如7B参数的LLaMA。这类模型在性能与成本之间取得了较好的平衡,对于大多数业务场景已经足够。
总的来看,Dify的设计理念与传统框架类似,但在AI应用开发这一全新领域找到了自己的位置。它让开发者能够跳过底层技术细节,聚焦业务逻辑创新。对于正在从Web开发转型AI的初学者而言,Dify提供了一条相对平滑的学习路径。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:人工智能大模型检索增强生成框架Dify深度解析要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看