




基于FPGA的神经网络算法优化与硬件加速实现方案

从算法、编译器、硬件三个维度优化FPGA神经网络加速,算法优化决定部署效率的上限。量化需结合FPGA特点,采用对称仿射变换并令缩放因子为2的幂次。以Transformer为对象,在TensorFlow中插入量化操作并自定义梯度,实践过程中遇到多种语法与功能问题。
AI芯片的优化,尤其是针对FPGA做神经网络加速,其实可以从三个维度来拆解:算法优化、编译器优化和硬件优化。算法优化直接决定了神经网络部署效率的天花板——它减少了网络所需的算力;而编译器与硬件优化则是在算力确定的基础上,尽可能把计算和带宽的性能压榨到极致。这篇文章算是我花了一年多理论学习后,第一次动手做神经网络算法优化的尝试。一个原本做FPGA的人转向算法,背后有几个很现实的原因。
首先,神经网络在AI芯片上落地,根本离不开算法优化。浮点数的加法或乘法,和定点数比起来,资源消耗差距悬殊。FPGA这种逻辑资源有限的芯片,天然更偏爱定点计算,而且能带来数倍于浮点计算的性能提升。其次,神经网络的量化压缩必须紧密结合FPGA的硬件特点——存储资源、计算符号能不能被FPGA友好地实现,都是需要掂量的因素。在很多AI翻跟斗项目中,算法团队和FPGA团队是分开的,FPGA会向算法组提要求,比如激活函数怎么量化、normalization怎么做,算法组再按这些约束去优化。如果一个人同时熟悉FPGA和算法,那就能更敏锐地发现优化的切入点。第三,FPGA的开发方式正在走向多样化。虽然RTL语言仍然是主流,它要求开发者有一定的数字电路基础,但胜在底层、灵活、可调优空间大。与此同时,FPGA也一直渴望突破传统,让不懂硬件的软件开发者也能快速上手,比如HLS。可以预见,随着HLS的成熟和FPGA芯片的演进,采用这种方式的开发者会越来越多。算法复杂、更新快的项目里,HLS更有优势;而那些对资源、时序、功耗要求苛刻的场景,RTL依然是首选。当硬件平台逐渐软件化,对FPGA开发者的算法能力要求只会越来越高。
Transformer网络结构
Google那篇《Attention is all your need》提出了用全attention结构替代LSTM的Transformer模型,在翻译任务上表现更出色。这个网络计算量大,但计算符号相对简单,而且应用广泛,很适合拿来做网络加速的展示。整体模型结构如下:
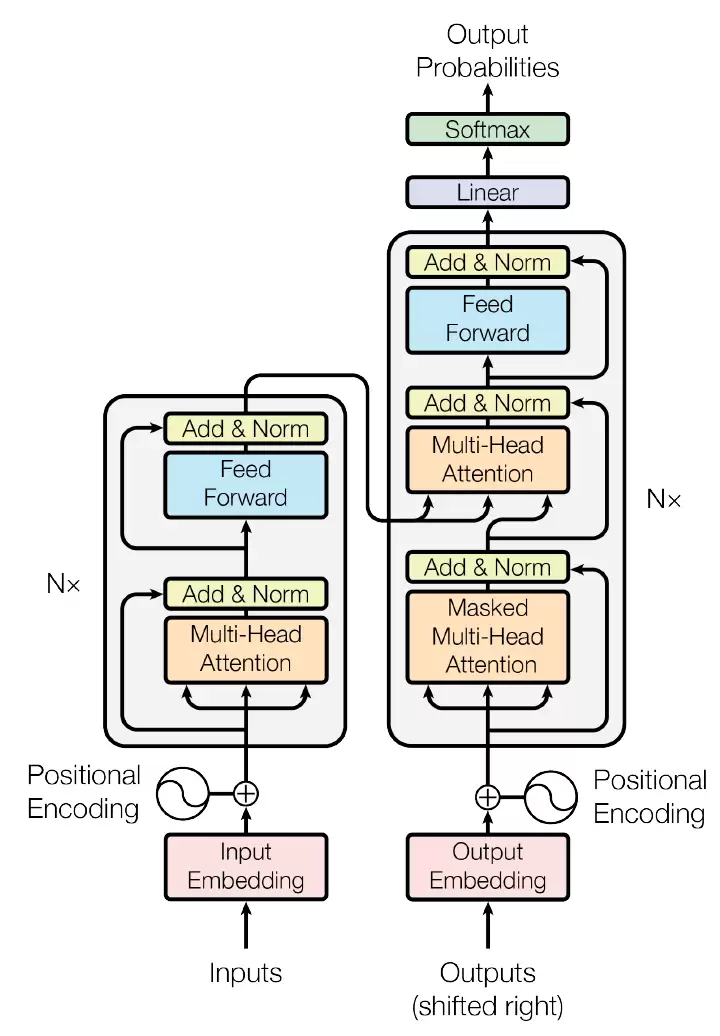
1 embedding
Embedding层负责把词汇转化为网络输入向量,分为input和output两部分。矩阵大小取决于词汇量——对翻译任务来说,词汇表通常非常庞大,所以embedding不适合放在FPGA上加速,也没有量化的必要。有意思的是,input、output和softmax前的linear层共享同一套参数,这样做可以降低word level perplexity,同时也减少了参数存储量。最后的linear用embedding的权重,是为了把网络向量转化成词语出现的logits。
2 positional encoding
Transformer没有循环结构,所以需要靠位置编码来获取词汇之间的位置关系。实际上就是给每个词加上一个位置偏移,偏移函数选用了sin和cos:
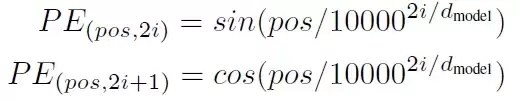
这里pos代表词汇位置,i是词汇向量的维度位置。
3 encoder
Encoder由多层multi-head attention和linear层组成,两者之间通过norm和add连接——这里的add是一种residual连接。Multi-head attention的结构如下:
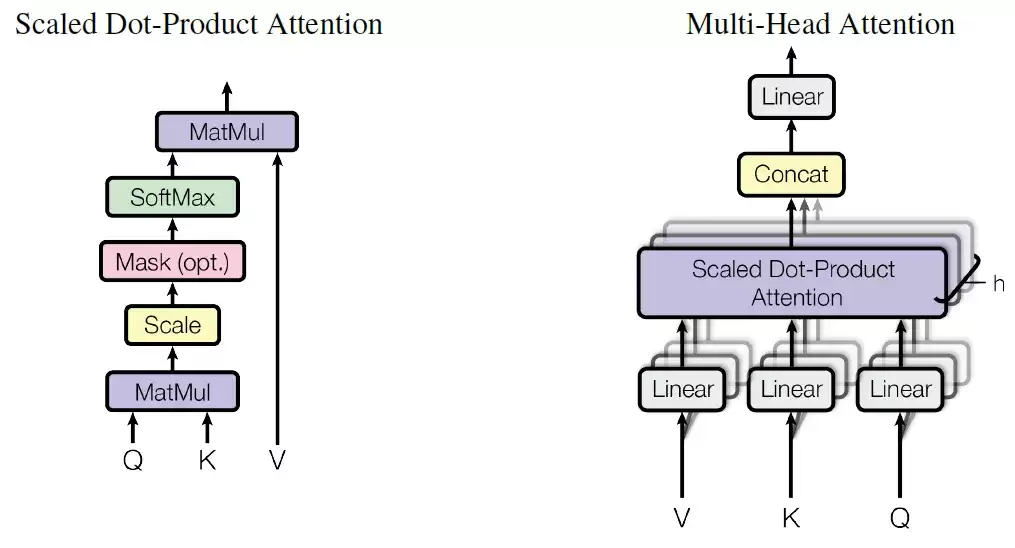
Q、K、V分别是query、key和value,这是attention机制中三个核心抽象变量。本质上是计算q和k的相似度,得到每个k对应的v的权重系数,然后对value做加权求和。Transformer用softmax来描述相似度,当然还有其他方法。公式中加了一个缩放因子1/sqrt(dk),目的是防止矩阵乘法结果太大导致softmax的梯度太小。需要特别注意的是,Transformer并没有对Q、K、V直接做单一的attention计算,而是先把它们拆分,平行计算各个部分,最后再把得到的attention值拼在一起。
4 decoder
Decoder和encoder结构类似,但多了一层:mask-multi-head attention、multi-head attention和FC。带mask的multi-head是为了屏蔽target句子中当前词之后的那些词——翻译是从前向后进行的,后面的词不应该影响前面词的预测。
量化方法
量化本质是一个仿射变换:
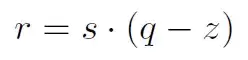
其中s是scale,q是量化后的数据,z是偏移。如果采用对称变换,令z=0,那么公式就变成:
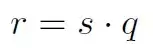
去掉中心z,可以消除矩阵计算中的交叉项。接下来关键是求q和s。q和s通过以下方式获得:
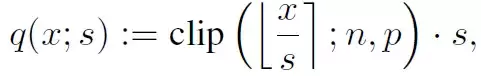
Clip操作是在最小值n和最大值p之间取x/s的向下整数值,如果超出范围就取边界值n或p。S的值通过训练得到,为了保证在FPGA上能高效计算,s最好取2的幂次。由于s和x都是训练参数,需要求梯度。梯度计算相对简单,对q(x,s)的x和s分别求导:
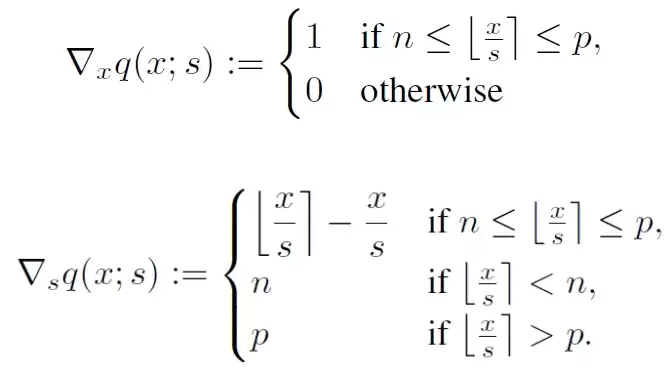
对x的梯度采用了Hinton提出的straight-through estimator,这样可以消除量化引入的噪声,加速训练。
实践
Transformer中有dense、matmul等操作,需要量化的数据包括dense中的权重,以及matmul中的Q、V、K变量。第一次做没有太多经验,决定循序渐进。先挑一个dense层进行量化。从GitHub上下载了一个Transformer的实现源码(https://github.com/Kyubyong/transformer),这个代码写得比较简洁,容易看懂。官方的实现代码比较复杂,依赖库多,之前尝试安装失败就放弃了。在跑Kyubyong的代码时还遇到了一个问题:训练能完成,但eval时报了维度错误。排查后发现是positional encoding中的embedding有问题——eval数据集的maxlen设成了10000,但embedding中传入的查找表维度是从hparams来的,两者不一致。不知道作者为什么留了这个bug,修正后eval就正常了。
量化的第一步是在tensorflow的图结构中插入量化操作,放在需要量化的权重数据后面。这需要重新定义op和梯度。TensorFlow提供了tf.custom_gradient装饰函数,可以用来定义梯度和op。这里定义如下:
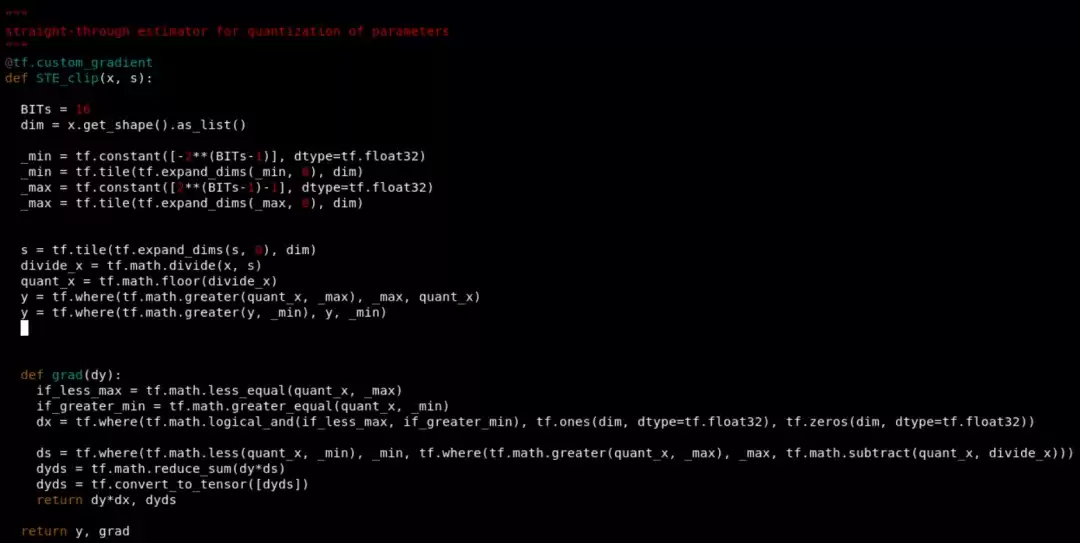
STE_clip中的y计算了对x的量化值,grad函数是对x和s的梯度计算。X和s分别是传入的(d, d)权重和scale。dy是传入的上一个节点的梯度,与STE_clip节点梯度的乘积就是最终梯度——这是函数梯度计算的传递性质决定的。注意s是标量,q(x,s)对s的梯度是一个矩阵向量,需要和dy做点积求和。
在tensorflow图构建中,把节点插入如下位置:
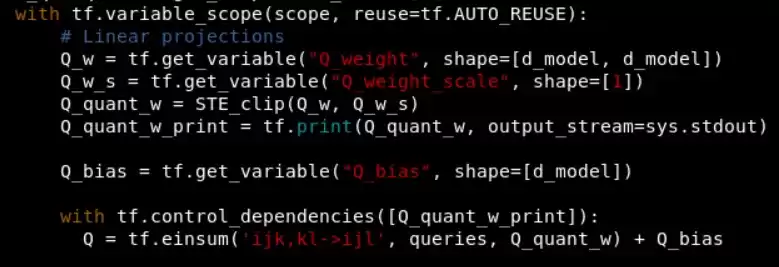
这里还加了tf.print,用来打印量化后的数据。
语法错误修正:
1. 定义custom_gradient函数时报NoneType object is not iterable——因为函数没有返回值,默认返回None。
2. TypeError: Input 'e' of 'Select' Op has type float32 that does not match type int32 of argument 't'——tf.greater(x, y)中x和y数据类型必须一致。
3. ValueError: Shapes must be equal rank——tf.greater中数据必须具有相同rank(即维度)。
4. ValueError: Shape must be rank 1 but is rank 2——tf.tile(x, axis)中x必须有维度,不能是0维。
5. ValueError: Shape must be rank 2 but is rank 3——tf.matmul中两个矩阵维度必须相同。
6. TypeError: Failed to convert object of type
7. TypeError: Expected int32, got None of type '_Message'——输入为[N, T, d_model],其中N是None类型,所以用tf.constant([N,1,1])会报错。
8. Incompatible shapes between op input and calculated input gradient——输入数据和该输入数据的梯度维度不一致。
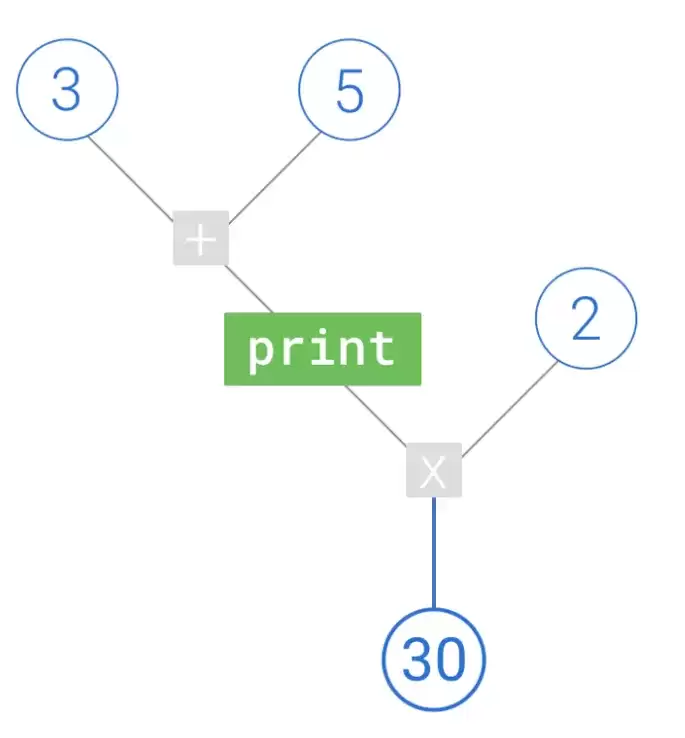
9. 使用tf.print无法打印出数据——因为print是tensorflow中的一个节点,需要加入图中才能输出,而且只有计算流经这个节点才会生效。形象地说:
功能问题:
1. 训练过程中scale和量化数据一直没有更新,始终保持不变,而且量化值与权重数据及scale计算的结果不一致。目前还在排查原因。
引用文献
1. Learning Accurate Integer Transformer Machine-Translation Models, Ephrem Wu
2. Trained uniform quantization for accurate and efficient neural network inference on fixedpoint hardware, Sambha v R. Jain, Albert Gural, Michael Wu, and Chris Dick
3. Attention Is All You Need, Ashish Vaswani, Noam Shazeer, Niki Parmar
4. Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations, Itay Hubara, Matthieu Courbariaux, Daniel Soudry
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:基于FPGA的神经网络算法优化与硬件加速实现方案要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点小米MiMo开放平台宣布,MiMo-V2系列的四款模型将于2026年6月30日正式下线,平台已推动开发者向V2 5系列迁移。具体涉及mimo-v2-pro、mimo-v2-omni、mimo-v2-flash和mimo-v2-tts模型。平台设置了系统替换时间作为缓冲:pro和omni模型于2026
2026重庆车展上,2026款长安猎手K50正式上市,共推出10款车型,售价14 19万至17 89万元。新车主要针对续航、电池和动力进行升级,搭载2 0T增程系统与双电机,纯电续航超180公里,快充仅需16分钟。全系标配30kW外放电功能,储备电量达239kWh,并新增山地与涉水模式,提升通过性。
上海期货交易所与上海市普陀区人民政府于6月12日签署战略合作协议,旨在建立长期共赢的合作机制,共同服务上海国际金融中心与国际贸易中心的联动发展。双方高层领导均出席签约仪式,彰显了对此次合作的高度重视。协议聚焦于发挥期货市场专业资源与区域发展综合优势,深化务实合作,探索金融创新与实体经济深度融合,以期
6月12日,世纪华通发生一笔大宗交易,以每股14 37元的价格成交757 24万股,成交总额为1 09亿元。值得注意的是,该成交价与当日市场收盘价持平,属于平价交易。此次交易额占该股当日总成交额的1 51%。市场分析认为,平价成交反映了买卖双方对当前股价水平的共识,交易行为相对平稳,未对市场预期造成
- 日榜
- 周榜
- 月榜
热点快看