




卷积神经网络应用与技术详解

卷积神经网络在图像分类与目标检测中表现优异,其核心含卷积层、池化层、激活函数及损失函数。综述梳理了CNN发展脉络与关键技术(如权重共享、扩张卷积和多种池化方式)。ReLU等激活函数可缓解梯度消失,Hinge、Softmax等损失函数适用于不同任务。CNN泛化能力强,但训练依赖大数据与算力,模型可解释性仍是未来。
从图像分类到目标检测,再到实例分割和场景理解,深度卷积神经网络(CNN)已经在深度学习应用的多个领域展现出了卓越性能,其泛化能力也令人印象深刻。南洋理工大学的一篇综述论文《Recent Advances in Convolutional Neural Networks》对CNN的关键组件及近年来的进展进行了系统梳理,内容涵盖了卷积、池化的数学原理,以及常用的激活函数和损失函数。机器之心技术分析师对这篇论文做了解读。

话说回来,这篇综述不仅梳理了CNN从诞生至今的发展脉络,还给出了几个关键要点:卷积层的数学基础是什么?池化层又是如何工作的?常用的激活函数有哪些?损失函数怎么选择?基于CNN的应用又有哪些?下面我们逐一来看。
卷积层的数学原理
如果要问CNN核心层所采用的计算原理,数学公式是这样的:第l层的第k个特征图在位置(i,j)处的特征值z_{i,j,k}^l,是通过以下方式计算得到的——
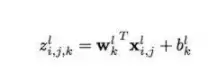
其中,w_k^l是第l层的权重,b_k^l是第l层的偏置,而x_{i,j}^l则是第l层在(i,j)位置的输入图块。值得留意的是,同一个特征图内的权重是共享的。这种权重共享机制是CNN的一大优势,因为它能大幅减少参数量,降低计算复杂度,同时也让训练和优化变得更简单。
基于这类基本卷积层的最著名应用之一,就是用于USPS数字和MNIST识别的LeNet-5,它的结构如下图所示。
LeNet-5由三类层构成:卷积层、池化层和全连接层。卷积层的目标是学习更能代表输入的特征,池化层负责降低空间维度,全连接层则用于类别预测。具体来讲,卷积层由多个卷积核组成,每个卷积核都能生成一个特征图。而特征图中的每个神经元,都与前一层中一个临近的神经元区域相连,这个区域就是所谓的“感受野”。
如上图所示,通过求输入与一个已学习的卷积核的卷积,可以得到一个新的特征图,然后在结果上逐元素地应用非线性激活函数。即便是在今天,MNIST和USPS数字分类的效果依然很好,不少研究者还会用它们来验证新算法。可以说,任何类型的卷积网络在这类数据集上,都能轻松实现97%到98%的准确率。
近年来,研究者也提出了一些新的卷积架构。其中比较有名的是扩张卷积。扩张卷积为卷积层引入了额外的超参数——扩张因子。通过在过滤器之间插入零值,可以有效增大网络的感受野,使其覆盖更多相关信息。从数学上看,一维信号的扩张卷积公式如下:(F_{*l} k)_t = sum_t (k_t * F_{t−l * t}),其中*l表示l-扩张卷积。这个公式可以直接扩展到二维空间。
上图中展示了三层扩张卷积,其中扩张因子l每层呈指数增长。中间特征图F2是由底部特征图F1经过1-扩张卷积得到的,F2中的每个元素拥有一个3x3的感受野。F3由F2经过2-扩张卷积得到,而F4则是由F3经过4-扩张卷积得到的。具体细节可以看看图上红框标注的部分。
池化层的数学原理
池化层是CNN中另一个关键模块。它的核心目标是降低特征图的大小,方法是通过某个函数来融合子区域——最常见的就是取平均值或最大值/最小值。池化的工作方式,是在输入上滑动一个窗口,然后将窗口中的内容送入池化函数;整个过程类似于离散卷积,只不过用其他函数替代了卷积核的线性组合。
描述池化层特性的数学公式相对直接,它涉及几个关键参数:输入大小i_j,池化窗口大小k_j,步幅s_j。沿方向j的输出大小o_j可以这样计算:o_j = (i_j - k_j) / s_j + 1。需要注意的是,池化层通常不会使用零填充。
最大池化和平均池化实际上可以归纳为Lp池化,它的数学描述如下:
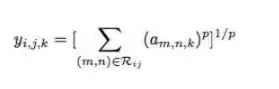
其中,y_{i,j,k}是池化算子在第k个特征图位置(i,j)处的输出,a_{m,n,k}是第k个特征图中池化区域R_{ij}内位置(m,n)处的特征值。特别要指出,当p=1时,Lp池化对应平均池化;当p趋近无穷大时,Lp池化退化为最大池化。
池化还有一些其他选择,比如混合池化。混合池化的公式可以写成:
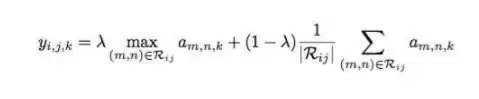
可以把它看作是最大池化和平均池化的混合版,其中λ是一个0到1之间的随机值,它决定了使用平均池化还是最大池化。从实践来看,这种方法有助于降低过拟合风险,且表现通常比单独使用最大池化或平均池化要好一些。
某些常用的激活函数
ReLU
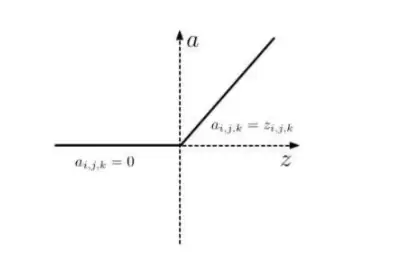
上图展示的是ReLU函数。ReLU激活函数的定义如下:
这里z_{i,j,k}是第k通道中位置(i,j)处激活函数的输入。ReLU是一个逐元素操作的函数,它会保留正数部分,把负数部分全部变成零。相比sigmoid或tanh,ReLU中的max(.)运算让它速度快很多。不过,它也有一个明显的缺点:在零点处不连续,这在反向传播过程中可能带来梯度消失的问题。
Leaky ReLU
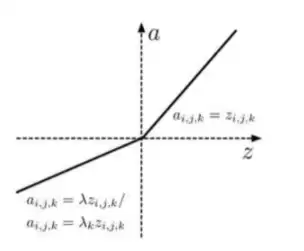
为了缓解梯度消失问题,研究者提出了Leaky ReLU这个重要的变体。它的数学形式为:
其中λ的取值范围是(0,1)。Leaky ReLU没有强制将负数部分设为零,而是允许它有一个较小的非零梯度。
PReLU
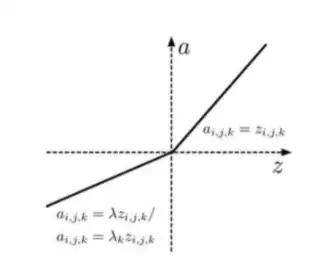
上图是PReLU的图示。PReLU和Leaky ReLU的不同之处在于参数λ的处理方式。PReLU的公式如下:
这里的λ_k是第k个通道通过学习得到的参数。也就是说,这些λ不是预先设定的,而是从数据中学习而来的。可学习的参数λ_k的数量正好等于网络中通道的数量。由于用于训练的额外参数很少,所以不用担心过拟合问题;它可以在反向传播过程中与其他参数一起同步优化。当然,还有不少其他实用的非线性激活函数,比如ELU、Maxout等。
某些常用的损失函数
Hinge损失
Hinge损失通常用于训练SVM及其变体。用于多类SVM的Hinge损失定义如下:
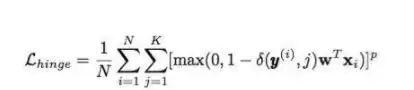
这里,w是可训练权重;δ(y(i), j)是指示函数:如果y(i) = j,输出为1,否则为0。N是样本数量,K是类别数量。如果p=1,称为L1-Hinge损失;如果p=2,则称为L2-Hinge损失。
Softmax损失
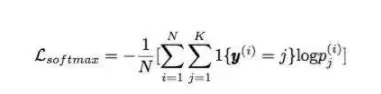
Softmax损失可以说是分类任务中最流行的损失函数了。其中N是图像数量,K是类别数量,p_j是第j类的概率,y是真实标签。1{.}也是一个指示函数:如果y_i == j,输出为1,否则为0。Softmax损失可以看作是logistic损失的一种泛化形式,它将预测结果转换成(0,1)范围内的非负值,并给出一个在各类别上的概率分布。
对比损失
对比损失常用于训练图像检索或人脸验证中的孪生网络。它的基本思想是:增大不相似配对之间的距离,同时减小相似配对之间的距离。数学公式如下:
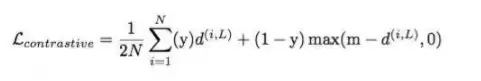
如果y=1,第二项为0,全部损失来自第一项,意味着目标就是缩小相似配对之间的距离。如果y=0,第一项为0,全部损失来自第二项,目标变为拉大不相似配对之间的距离。需要留意的是,如果不相似配对之间的距离小于余量,总损失会增加。
三重损失
三重损失是对对比损失的一种巧妙改进。假设有三张图像:(x_a, x_p, x_n)——锚图像、正例图像和负例图像。损失公式如下:
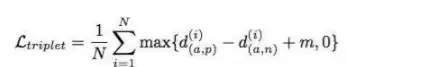
其中N是图像数量,d_{a,p}是锚图像与正例图像之间的距离,d_{a,n}是锚图像与负例图像之间的距离,m是余量。它的目标是让d_{a,n}尽可能大,使得d_{a,p}与d_{a,n}之差大于余量m。简单说,就是同时最小化锚图像与正例的距离,最大化负例与锚图像的距离。
当然,常用的损失函数还有很多,比如histogram损失、LDA损失、KL散度损失等,这里就不一一列举了。
CNN的应用
图像分类
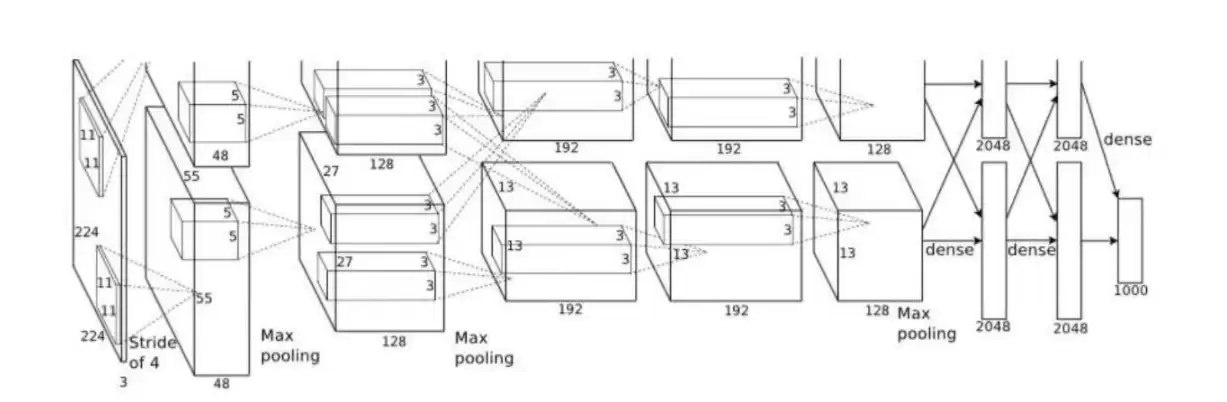
2012年,Krizhevsky等人提出了LeNet-5的一个扩展版本——AlexNet,并在ILSVRC 2012上取得了当时最佳的表现。上图中的架构就是AlexNet。由于当时计算时间受限,他们采用了并行训练方式:一个GPU处理图中顶部的层,另一个GPU处理底部的层。
目标检测
2014到2017年间,微软和Facebook的研究人员开发了多种基于CNN的目标检测方法,包括R-CNN、SPP-Net、Fast RCNN、Faster RCNN以及Mask RCNN。上图展示的是基础的R-CNN流程。从原始图像中提取出区域提议后,这些提议会被调整为固定尺寸,然后输入到一个预训练的CNN中。之后,输出的特征会经过边界框回归和分类模块进行精细优化。
图像分割
图像分类任务可以大致分为语义分割和实例分割两大类,其核心目标是预测单张图像中每个像素的类别。CNN可以从像素级别或图块级别来预测类别可能性。Long等人提出了一种用于像素级分割的全卷积网络。如上图所示,它和一般的网络结构类似,只是最后一层有所不同——这一层被称为“去卷积层”。它的学习目标是对标签图进行上采样,恢复其分辨率。最终输出是一张图像,其中包含了密集的像素级预测结果。
基于CNN的方法还被应用于许多其他领域,比如图像检索、人脸识别、文本分类、机器翻译、3D重建、视觉问答、图像绘制等。限于篇幅,这里不可能一一覆盖。
分析师简评
尽管CNN表现出色且泛化能力优异,但仍有几个问题亟待解决。首先,CNN的训练需要大规模数据集和强大的计算能力,而人工收集数据成本高昂且容易出错。因此,研究者们正在探索弱监督学习和无监督学习,希望能有效利用大量未标注的数据。与此同时,为了加速训练,开发高效且可扩展的并行训练算法也十分必要。最后,也是最重要的一个命题:如何解释网络内部的工作原理。试想,如果人们无法理解CNN为何会给出某个结果,恐怕没有人愿意乘坐一辆基于CNN的自动驾驶汽车,也未必愿意接受基于CNN的医疗诊断。这,才是未来真正的挑战所在。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:卷积神经网络应用与技术详解要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看