




深入解析基于Python的人工神经网络工作原理

从一项核心观点开始探讨:要使人工智能真正具备“智能”,一个重要路径便是借鉴人脑的运作机制。这一理念直接催生了“神经网络”这一方向。人类大脑中拥有数十亿个神经元,每个神经元又与上万个其他神经元相连,交织成一张复杂的信息网络。其精妙之处在于:尽管单独一个神经元的能力极为有限,但当数十亿个神经元协同工作时
从一项核心观点开始探讨:要使人工智能真正具备“智能”,一个重要路径便是借鉴人脑的运作机制。这一理念直接催生了“神经网络”这一方向。人类大脑中拥有数十亿个神经元,每个神经元又与上万个其他神经元相连,交织成一张复杂的信息网络。其精妙之处在于:尽管单独一个神经元的能力极为有限,但当数十亿个神经元协同工作时,便涌现出意识、记忆、推理等高级认知能力。深度学习的底层逻辑,正是将这种“大规模简单单元协作产生智能”的模式,通过数学与计算的方式加以复现。
杰弗里·辛顿曾用一句话点明方向:“人们需要认识到,深度学习正在让许多幕后事物变得更好。深度学习已经应用于谷歌搜索和图像搜索,你可以通过它搜索像‘拥抱’这样的词语来获得相应的图像。”
神经元
神经网络的基本构建模块是人工神经元,它模仿了人类大脑中神经元的结构。这些神经元作为简单而强大的计算单元,拥有加权输入信号,并通过激活函数产生输出信号。它们分布在神经网络的多个层级中。
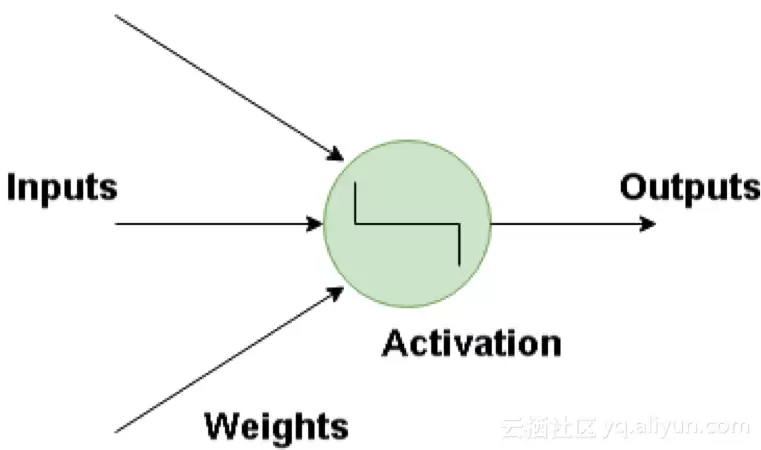
inputs 输入 outputs 输出 weights 权值 activation 激活
人工神经网络的工作原理是什么?
深度学习由人工神经网络构成,这类网络模拟了人脑中类似的连接方式。当数据穿越这个人工网络时,每一层都会处理数据的一个方面,过滤掉异常值,识别出熟悉的实体,并最终产生输出。
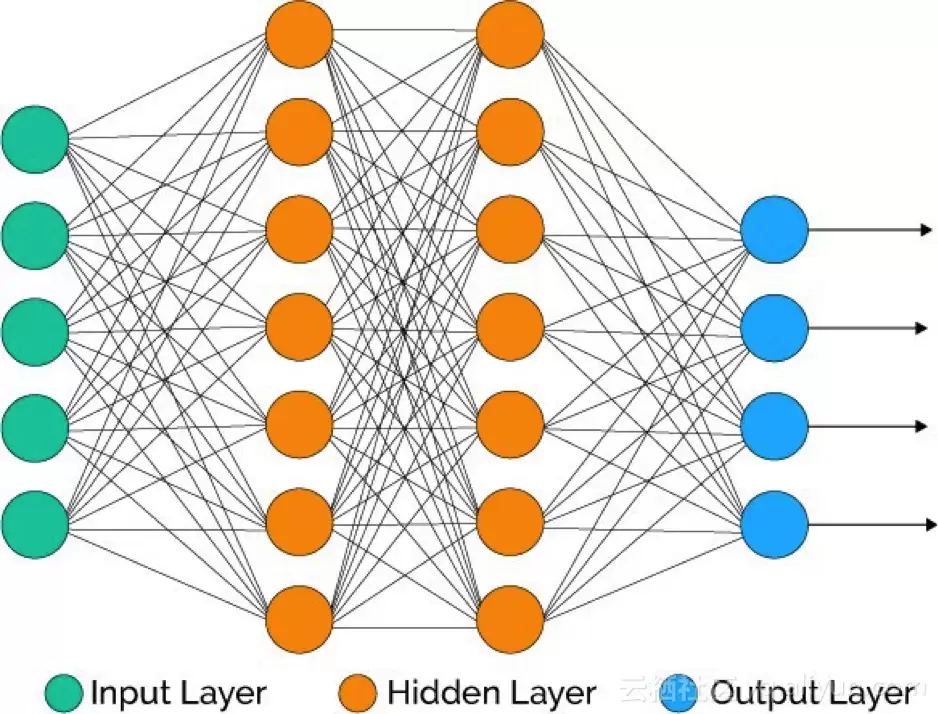
输入层:该层由神经元组成,仅负责接收输入信息并将其传递到其他层。输入层的神经元数量应与数据集中的属性或特征数目相等。输出层:输出层具有预测功能,具体取决于你所构建的模型类型。隐含层:隐含层位于输入层与输出层之间,其结构与模型类型相关。隐含层包含大量神经元,这些神经元先对输入信息进行变换,再将其传递出去。随着网络不断训练,权重会持续更新,从而使模型更具前瞻性。
神经元的权重
权重指的是两个神经元之间连接的强度或幅度。如果熟悉线性回归,可以将输入的权重类比为回归方程中的系数。权重通常初始化为较小的随机数值,例如0到1之间的值。
前馈深度网络
前馈监督神经网络是第一个也是最成功的学习算法之一。该网络也被称为深度网络、多层感知机(MLP)或简单神经网络,它清晰地展示了具有单一隐含层的原始架构。每个神经元通过某个权重与另一个神经元相连。网络向前处理输入信息,激活神经元,最终产生输出值。这一过程被称为前向传递。
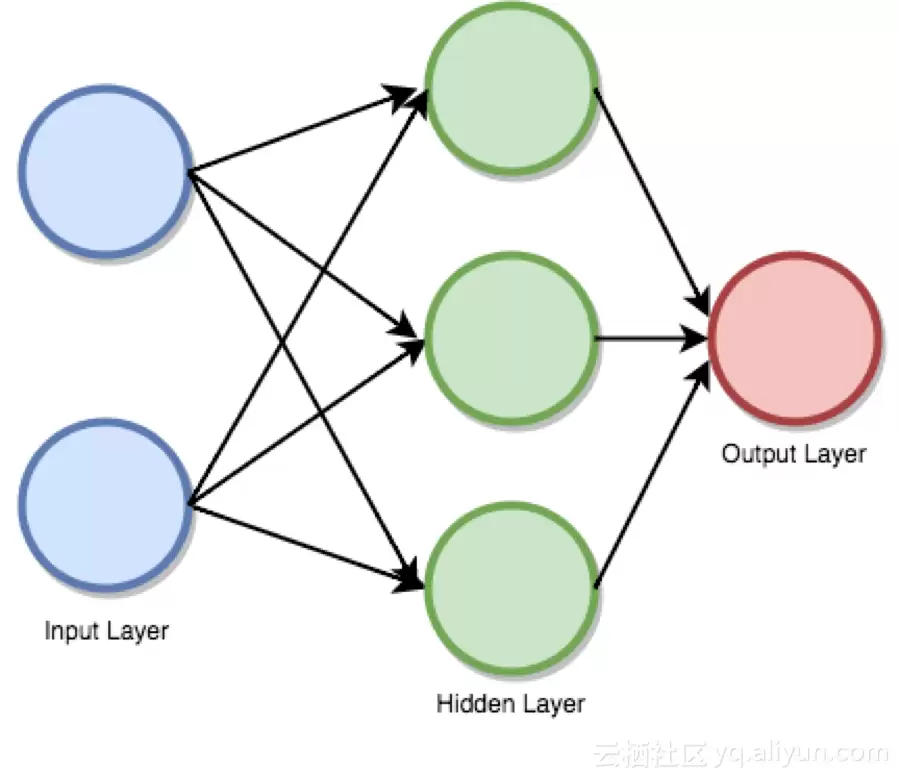
input layer 输入层 hidden layer 隐含层 output layer 输出层
激活函数
激活函数负责将加权输入的总和映射到神经元的输出上。之所以称为激活函数或传递函数,是因为它控制着激活神经元的初始值以及输出信号的强度。用数学形式表示为:
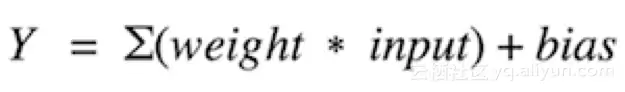
常用的激活函数有不少,其中应用最广泛的是整流线性单元函数(ReLU)、双曲正切函数(tanh)以及SoftPlus函数。以下是激活函数的速查表:

反向传播
在网络中,我们会将预测值与预期输出值进行对比,利用函数计算其误差。随后,该误差会逐层传回网络,每一层的权重根据其导致的误差大小进行更新。这一巧妙的数学方法就是反向传播算法。该过程会在训练数据的所有样本中反复执行,整个训练数据集完成一轮网络更新称为一个时期。一个网络可能被训练数十、数百甚至数千个时期。
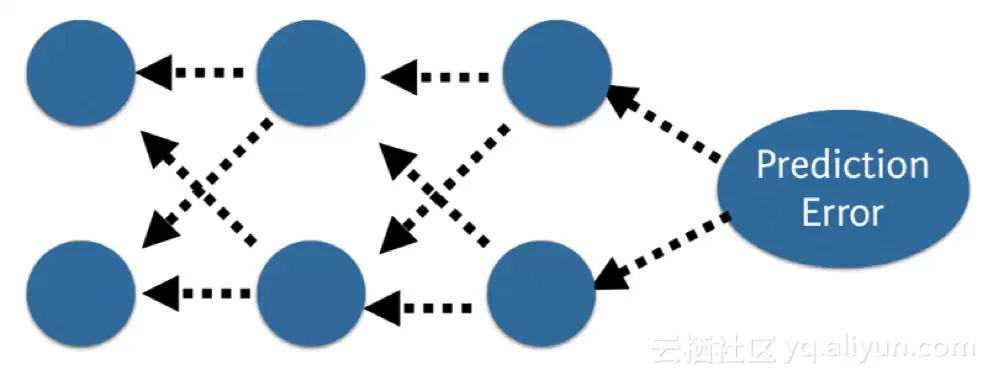
prediction error 预测误差
代价函数与梯度下降
代价函数衡量的是神经网络在给定训练输入和预期输出下“表现有多好”。该函数可能依赖权重、偏置等参数。代价函数是一个单值,而非向量,因为它从整体上评估神经网络的性能。在应用梯度下降优化算法时,每个时期后权重都会得到增量式更新。
兼容代价函数
用数学公式表达为差值平方和:
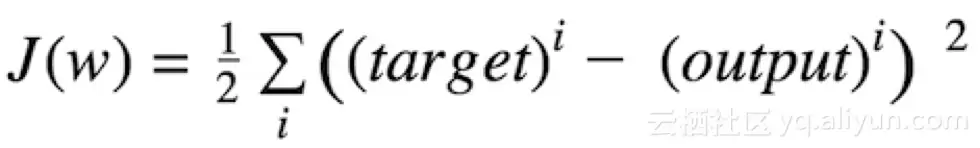
target 目标值 output 输出值
权重更新的大小和方向,由在代价梯度的反方向上采取步骤计算得出。
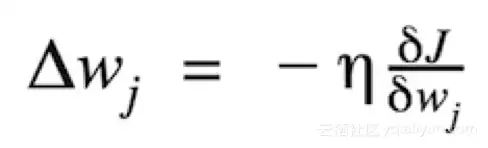
其中η 是学习率
这里的Δw是一个向量,包含每个权重系数w的权重更新,其计算方式如下:
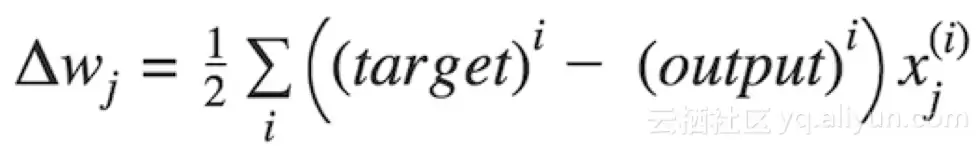
target 目标值 output 输出值
图表中考虑的是单系数的代价函数。
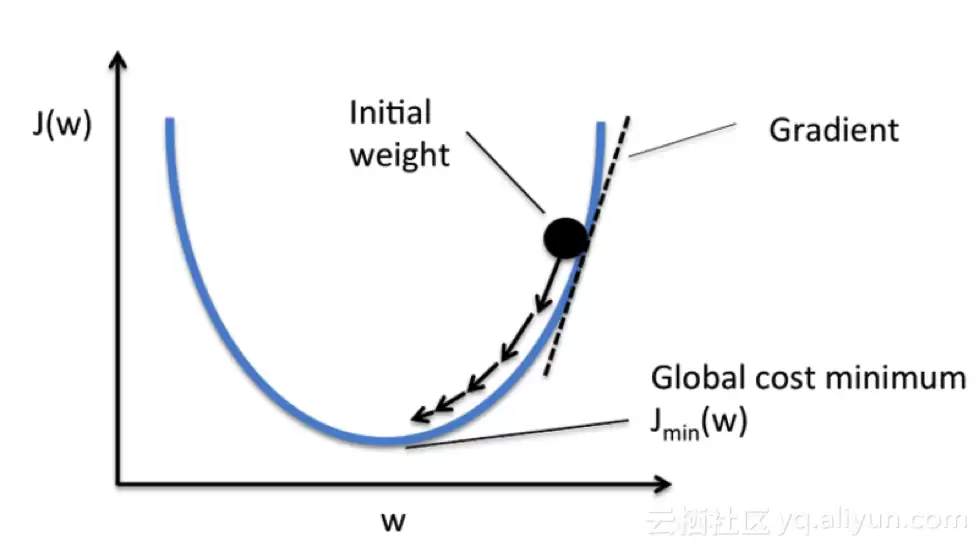
initial weight 初始权重 gradient 梯度 global cost minimum 全局代价最小值
在导数达到最小误差值之前,我们会持续计算梯度下降,每一步都取决于斜率(梯度)的陡峭程度。
多层感知器(前向传播)
这类网络由多层神经元组成,通常以前馈方式(向前传播)相互连接。一层中的每个神经元可以直接连接到后续层的神经元。在许多应用中,这些网络的单元采用Sigmoid函数或整流线性单元(ReLU)作为激活函数。
现在设想一个问题:根据给定的账户和家人数量来预测处理次数。要解决这个问题,首先需要构建一个前向传播神经网络。输入层是家人数量和账户数量,隐含层数为1,输出层是处理次数。将图中输入层到输出层的给定权重作为输入:家人数量为2,账户数量为3。
接下来通过以下步骤,使用前向传播计算隐含层(i,j)和输出层(k)的值。
步骤:
1. 乘法-加法方法。
2. 点积(输入×权重)。
3. 一次一个数据点的前向传播。
4. 输出即为该数据点的预测值。
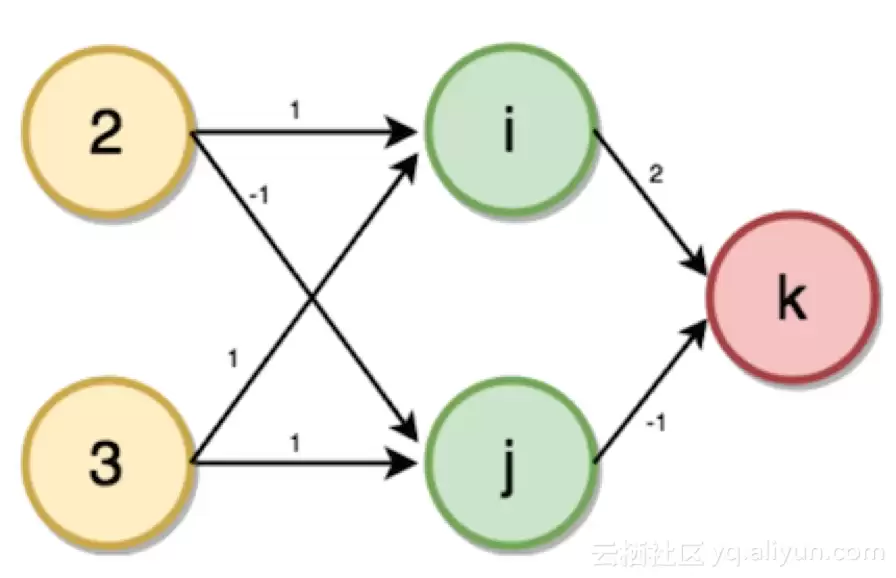
i的值将从相连神经元对应的输入值和权重中计算得出。
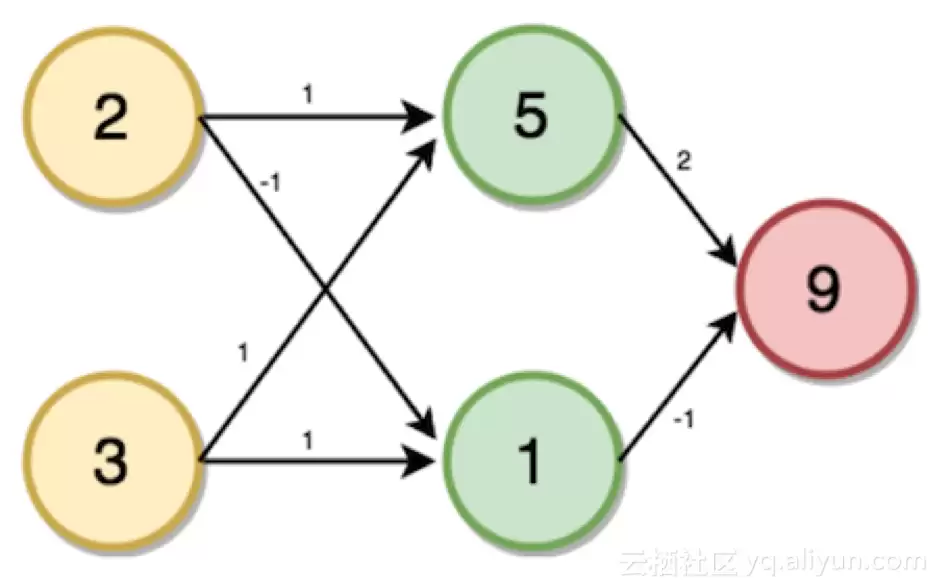
i = (2 * 1) + (3 * 1) → i = 5
同样地,j = (2 * -1) + (3 * 1) → j = 1
K = (5 * 2) + (1 * -1) → k = 9
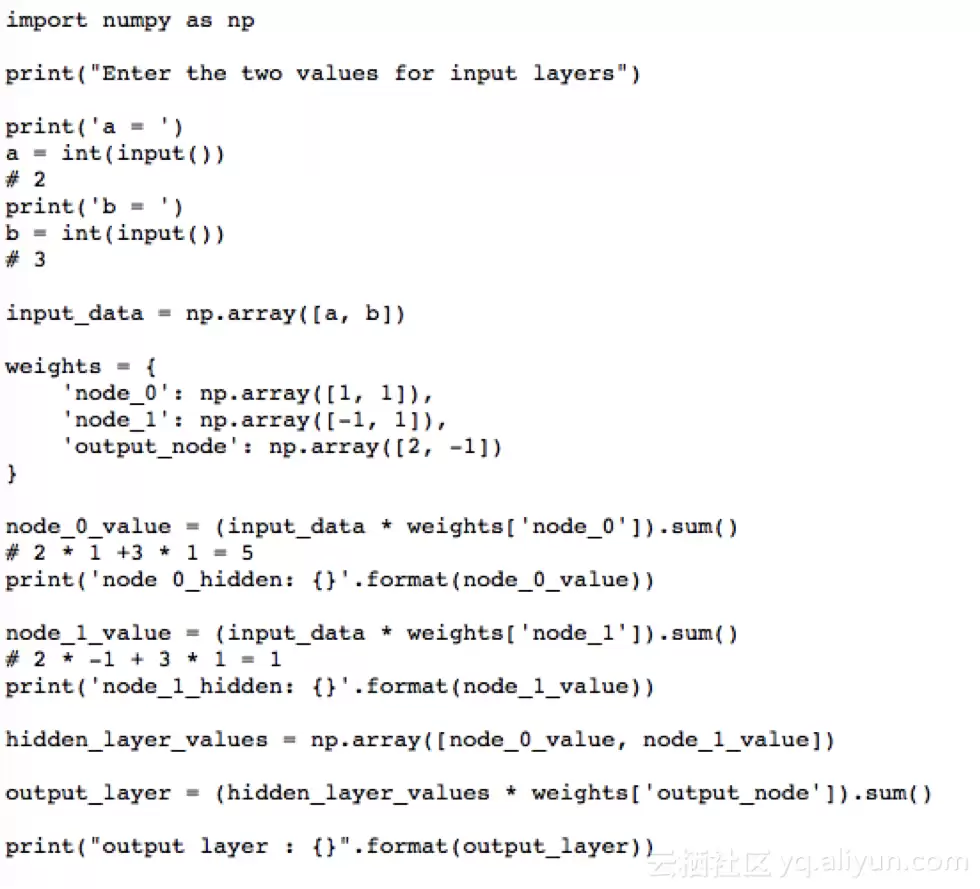
Python中多层感知器问题的实现

激活函数的使用
为了使神经网络达到最佳的预测能力,我们需要在隐含层应用激活函数,以捕捉非线性关系。通过将数值代入方程,我们可以在输入层和输出层应用激活函数。
这里我们采用整流线性单元(ReLU):
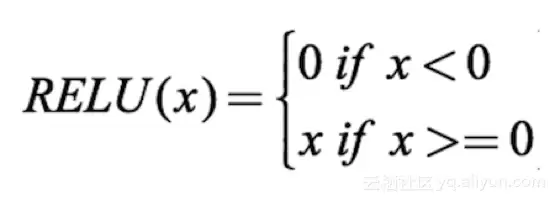


用Keras开发你的第一个神经网络
关于Keras:
Keras是一个用Python编写的高级神经网络应用程序编程接口,可以运行在TensorFlow、CNTK或Theano之上。使用PIP在设备上安装Keras,并执行以下指令。
在Keras中执行深度学习程序的步骤
1. 加载数据;
2. 创建模型;
3. 编译模型;
4. 拟合模型;
5. 评估模型;
开发Keras模型
全连接层用Dense类表示。我们可以将层中神经元的数量作为第一个参数,将初始化方法作为第二个参数(即init参数),并使用activation参数指定激活函数。模型创建完成后,即可进行编译。我们在底层库(也称为后端)中用高效数字库编译模型,底层库可以是Theano或TensorFlow。至此,我们已完成模型的创建和编译,为高效计算做好了准备。现在可以在PIMA数据集上运行模型了。通过调用模型上的fit()函数,在数据上训练或拟合模型。
我们从KERAS中的代码开始:

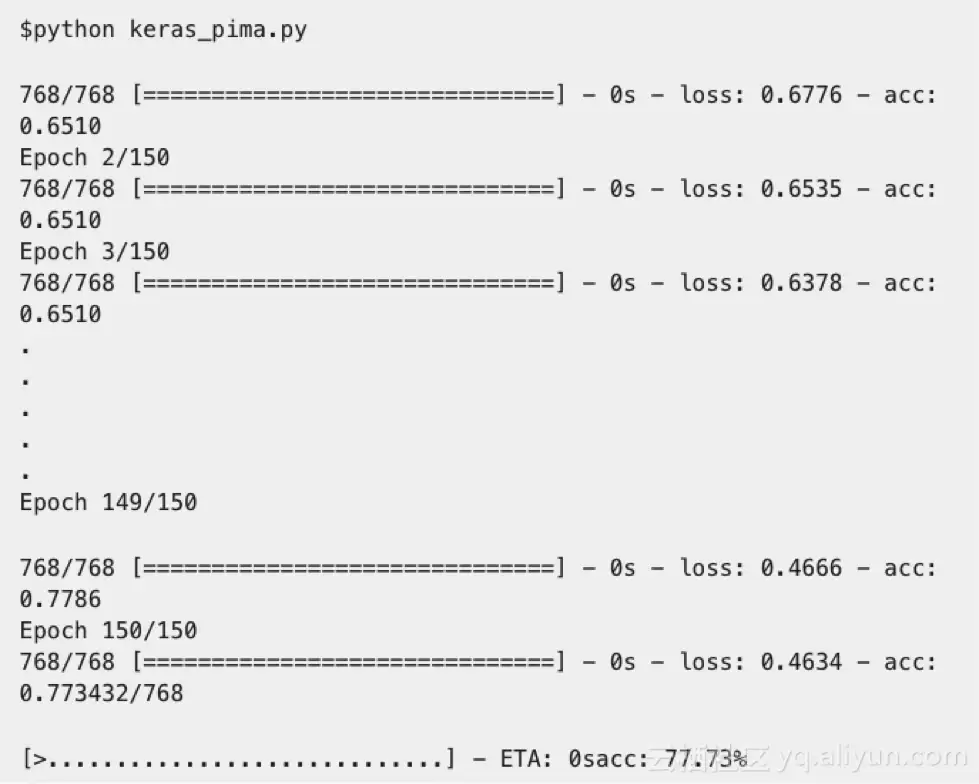
神经网络持续训练了150个时期,并返回了精确度值。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:深入解析基于Python的人工神经网络工作原理要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看