




MindSQL开源:企业级四种训练方式及私有数据RAG高并发

MindSQL是基于Python的开源文本到SQL生成工具,内建RAG机制,支持通过自然语言查询数据库。它具备高并发弹性扩展能力,每分钟可处理数千请求。核心通过索引数据库结构信息至向量存储,结合大语言模型生成SQL。支持问答对、DDL、文档字符串和批量数据四种训练方式,准确率依赖训练数据质量。
如果你正在关心如何让业务系统直接通过自然语言查询数据库,那 MindSQL 这个开源包值得花几分钟了解一下。它是一个基于 Python 的文本到 SQL 生成工具,内建了 RAG(检索增强生成)机制,用于快速搭建 Chat2SQL 类的应用。说白了,就是给数据库装上一个“自然语言翻译器”,让非技术用户也能用大白话问数据。
除了常规开源软件的几个优点——完全免费、数据隐私可控、架构灵活可自定义——MindSQL 还重点解决了两大企业级痛点:
高度准确
准确率的高低直接取决于你喂给它的训练数据质量。数据量越扎实,生成的 SQL 就越精确。
高并发
它的架构设计支持弹性扩展,每分钟可以扛住数千个请求,应付业务高峰期不成问题。
工作原理
MindSQL 本质上是一个 Python 库,核心思路是利用 RAG 技术,在大型语言模型(LLM)的帮助下生成适配你数据库的精确 SQL 语句。具体流程分两步:
- 先把数据库的结构信息(如表定义、字段说明)索引到向量存储中,形成一个针对该数据库的 RAG“模型”。
- 然后根据用户的自然语言问题,基于向量存储中的上下文自动构建 SQL,并在数据库上执行。
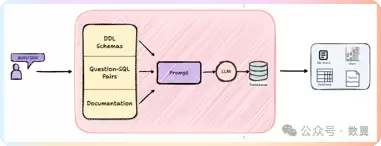
在实际开发中,你主要和两个核心 API 打交道:
minds.index(...)— 把数据库的 DDL 或示例问答对索引到向量库,作为后续查询的知识底座。minds.ask_db(...)— 接收用户提问,结合向量库上下文生成 SQL,并直接与数据库交互返回结果。
MindSQL 内部由三个基础组件构成,它们都继承自 MindSQLCore 基类:数据库(管理连接与操作)、向量存储(存储索引上下文)、LLMs(集成各类大模型,提升 SQL 生成的相关性)。
安装使用
安装非常简单,直接 pip:
pip install mindsql
接着配置环境变量(可通过命令行或 .env 文件):
- API_KEY — 用于调用 OpenAI、Gemini、LLAMA 等大模型的密钥
- DB_URL — 数据库连接字符串
- EXAMPLE_PATH — 用于批量索引的示例 JSON 文件路径(可选)
常见数据库的连接字符串格式:
mysql://username:password@host:port/databasepostgresql://username:password@host:port/databasemongodb://username:password@host:port/database
程序代码也很直观。先引入相关模块:
from mindsql.core import MindSQLCore from mindsql.databases import Sqlite from mindsql.llms import GoogleGenAi from mindsql.vectorstores import ChromaDB
然后创建 MindSQLCore 实例,传入 LLM 配置、向量存储和数据库类型:
minds = MindSQLCore(
llm=GoogleGenAi(config={"api_key": "YOUR-API-KEY"}),
vectorstore=ChromaDB(),
database=Sqlite()
)
接着用连接字符串连上数据库:
connection = minds.database.create_connection(url="YOUR_DATABASE_CONNECTION_URL")
把所有表结构(DDL)索引到向量库:
minds.index_all_ddls(connection=connection, db_name='NAME_OF_THE_DB')
如果有预设的问答样本,可以批量索引(这一步不是必须的):
minds.index(bulk=True, path="your-qsn-sql-example.json")
之后就可以向数据库提问了:
response = minds.ask_db(
question="YOUR_QUESTION",
connection=connection,
visualize=True
)
如果开启了可视化(visualize=True),还可以从响应中提取图表并展示:
chart = response["chart"] chart.show()
最后别忘了关闭连接:
connection.close()
一个完整的示例代码:
from mindsql.core import MindSQLCore
from mindsql.databases import Sqlite
from mindsql.llms import GoogleGenAi
from mindsql.vectorstores import ChromaDB
config = {"api_key": "YOUR-API-KEY"}
minds = MindSQLCore(
llm=GoogleGenAi(config=config),
vectorstore=ChromaDB(),
database=Sqlite()
)
connection = minds.database.create_connection(url="YOUR_DATABASE_CONNECTION_URL")
minds.index_all_ddls(connection=connection, db_name='NAME_OF_THE_DB')
minds.index(bulk=True, path="your-qsn-sql-example.json")
response = minds.ask_db(
question="YOUR_QUESTION",
connection=connection,
visualize=True
)
chart = response["chart"]
chart.show()
connection.close()
查询数据
ask_db() 是查询系统的核心入口,它的参数结构如下:
result = ask_db(
question = "员工的平均工资是多少",
connection = my_connection,
table_names = ["employees"],
visualize = False
)
table_names 是一个可选参数。如果指定了表名,MindSQL 就不再去向量库中检索相关表,而是直接用你提供的表名获取对应的 DDL。这在表结构复杂、需要明确限定查询范围时非常有用。
另外,visualize 参数设为 True 后,系统会用 plotly 自动生成查询结果的可视化图表(不过在实际生产环境中,这个开关一般保持关闭,只用于演示场景)。
手动构建索引知识库
前面提到了可以用示例文件批量构建知识库,其实你还能随时通过代码手动添加索引。MindSQL 支持以下几种方式:
问答对
直接告诉系统某个常见问题对应哪条 SQL,效果相当于给模型“灌输”标准答案:
index(
question = "平均工资是多少?",
sql = "SELECT A VG(工资) FROM 员工"
)
添加 DDL 语句
把数据库对象的定义(表结构、字段类型等)喂给系统,让它掌握数据模型:
index(ddl="CREATE TABLE employees (id INT, name VARCHAR(50), salary FLOAT)")
添加文档字符串
提供业务层面的上下文信息,比如术语解释、计算规则等,帮助模型更准确地理解查询意图:
index(documentation="员工工资以美元($)计算")
批量数据添加
如果有一整批问答对要导入,可以启用 bulk=True 并指定 JSON 文件路径,系统会一次性处理:
index(bulk=True, path="data.json")
JSON 文件的数据结构如下:
[
{
"Question": "员工的平均工资是多少?",
"SQLQuery": "SELECT A VG(salary) FROM employees"
},
]
最后
实际测试中,面对 400 多张表的环境,大多数简单查询都能正确返回结果。但遇到字段名或表名非常相似的情况时,偶尔会出现选择错误。此时,指定表的查询效果要明显好很多——这需要上层应用配合,比如先用一个 AI 模型做表名选择,再将结果传给 MindSQL。
不过在真正的生产场景里,决定准确率的依然是私有训练数据。大多数客户的 Chat2BI 需求范围相对固定,只要针对性的训练数据足够充分,准确率完全可以逼近 100%。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:MindSQL开源:企业级四种训练方式及私有数据RAG高并发要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看