




深度学习模型中的Dropout、BN与数据预处理方案详解

深度学习训练中,通过随机失活实现正则化,防止过拟合;数据预处理采用均值减法、归一化、PCA及白化可加速收敛;批归一化对每层数据预处理,加速训练并降低对其他正则化的依赖。预处理统计量需在训练集计算再应用于验证和测试集。
在深度学习训练过程中,如何防止模型过拟合、加速收敛,一直是大家关心的核心问题。下面几种常用技术虽然听着基础,但用好了能让模型训练事半功倍。
一、随机失活(Dropout)
具体做法其实很直观:训练时,让每个神经元以超参数 的概率被激活,或者直接被置为 0。示意图如下:
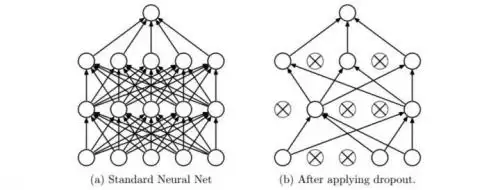
Dropout 可以理解为 Bagging 的一种极限形式——每个“模型”都在一种特定的子网络结构下训练,而所有子网络又通过共享参数互相耦合,这就带来了高度正则化的效果。换个角度看,训练过程中的随机失活,相当于对完整的神经网络不断抽样出不同的子集,每次只基于当前输入更新这个子网络的参数。当然,数量巨大的子网络们并非完全独立,因为它们共享着相同的参数。而在测试阶段,我们不再使用随机失活,而是对所有子网络的预测结果做模型集成(model ensemble),算出一个平均预测值。
为什么要设计 Dropout ?其实有两个很有意思的动机。一个是生物学上的类比:物种为了生存往往会过度适应所处的环境,一旦环境突变就可能面临灭绝,而性别的出现让后代有了更多变异,从而能适应新环境——Dropout 就扮演了类似的角色,防止模型对训练数据过度“适应”。另一个是正则化思想:通过减少神经元之间复杂的共适应关系,强制网络不依赖于特定神经元,从而提高整体鲁棒性。
想深入了解的话,建议直接去读论文原文,虽然是英文的,但细节更透彻,会很有收获。
二、图像数据的预处理
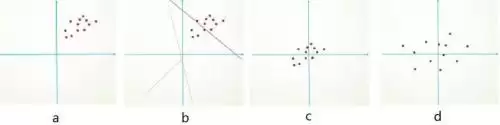
为什么要做预处理?从二维数据的角度切入会比较好理解。图像数据各维度之间往往是高度相关的,分布可能像下图 (a) 那样(简化为二维)。由于初始化时参数通常都是零均值的,刚开始拟合的曲线 基本会经过原点附近(因为 b 接近 0),如图 (b) 的红线虚线所示。网络得经历很多轮学习才能逐步逼近理想的目标曲线(紫色实线),收敛速度自然慢。如果先对输入数据做减均值处理(图 c),收敛就会明显加快。更进一步,再做去相关操作,数据变得更容易区分,训练速度又能再上一个台阶(图 d)。
下面介绍几种基础的预处理方法:
归一化处理
均值减法(Mean subtraction):对每个独立特征减去其平均值,几何意义就是把数据云的中心挪到原点(每个特征数据减去该特征的平均值)。
归一化(Normalization):先做零中心化(zero-centered),再让每个维度除以其标准差。
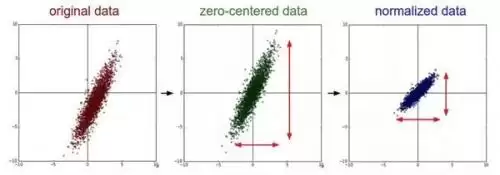 (左侧是零中心化,右侧是归一化)
(左侧是零中心化,右侧是归一化)
PCA 和白化(Whitening)
白化:输入是经过特征基准转换后的数据,然后每个维度除以其特征值来归一化数值范围。几何解释是:如果数据服从多维高斯分布,那么白化后数据将变成均值为零、协方差矩阵相等的分布。
特征向量是按特征值大小排列的,我们可以利用这个特性做降维——只取前面占比大的小部分特征向量,丢弃那些方差很小的维度。这就是主成分分析(PCA)降维。
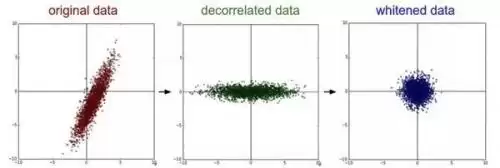 (中间是经过 PCA 操作的数据,右边是白化)
(中间是经过 PCA 操作的数据,右边是白化)
需要注意:前面说的零中心化和 PCA 有些相似,但区别在于 PCA 会把数据变换到数据协方差矩阵的基准轴上(协方差矩阵变成对角阵),是轴对称的;而简单的零中心化并不具备轴对称特性。另外,PCA 的主要用途是降维预处理,零中心化则没有降维作用。
一个常见错误:任何预处理策略(比如计算数据均值)都只能在训练集上计算,然后应用到验证集或测试集。比如说,先算出整个数据集的图像均值,所有图片减去这个均值,再划分训练/验证/测试集——这是错的。正确做法:先划分数据集,只在训练集上计算均值,然后每个子集(训练/验证/测试)都减去这个均值。
三、Batch Normalization

原论文中,作者为了计算稳定性,又加了两个可训练的参数,相当于把数据“还原”回一定的表达范围。说白了,就是对每一层的数据都做一次预处理。示意图如下:
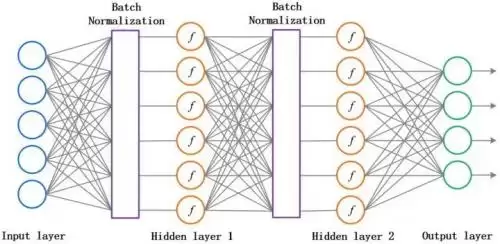
Batch Normalization 的好处很直接:加速收敛,这样学习率可以适当调大,训练速度提升;同时过拟合现象能得到缓解,所以可以降低 Dropout 的使用比例甚至不用,L2 正则化系数也可以减小,训练速度进一步得到提升。换句话说,它降低了对其他正则化手段的依赖。
要注意的是,Batch Normalization 和 PCA 加白化有一定类似——结果都能让数据零均值、单位方差,并且弱化相关性。但在深度神经网络中,一般不会直接用 PCA 加白化,原因很简单:白化需要计算整个训练集的协方差矩阵、求逆,计算量巨大,而且反向传播时白化操作不一定可导。细节还是建议去读 BN 的原论文,非常值得反复琢磨。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:深度学习模型中的Dropout、BN与数据预处理方案详解要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看