




英伟达DeepSeek V4推理成本降低80%

英伟达最新发布的Blackwell平台通过全栈推理优化,将DeepSeekV4模型单Token成本降至原来的五分之一,吞吐量提升达20倍。该平台采用三层架构,结合分离式服务与NVLink专家并行等多项创新技术。目前Baseten、Cognition等多家服务商已从中显著获益。
快科技7月2日消息,英伟达正式宣布,其Blackwell平台通过全栈推理软件深度优化,使得DeepSeek V4模型的单Token成本在一个月内大幅削减至原先的五分之一。
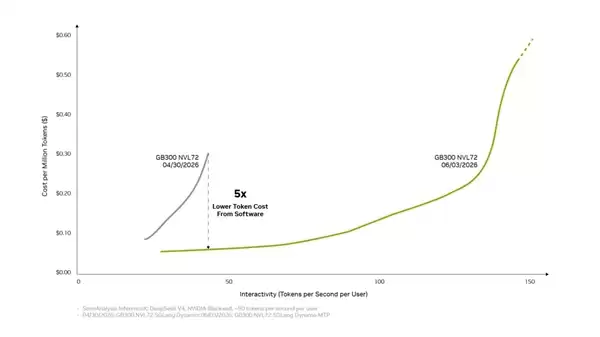
随着企业从AI试验阶段迈向生产级AI工厂,基础设施的决策逻辑已发生根本性转型——评判标准不再单纯依赖芯片的峰值性能,而是聚焦于每元成本、每瓦功耗以及在目标延迟约束下,究竟能高效产出多少有实际价值的Token。
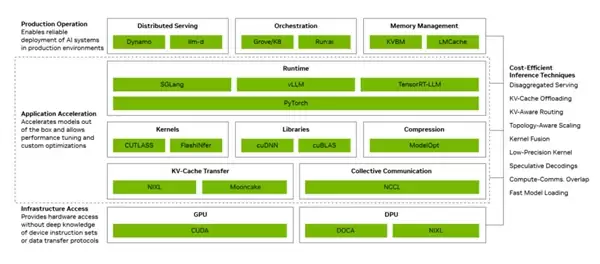
英伟达通过构建三层软件架构实现了Token成本的显著降低。生产运营层负责分布式服务的编排调度与自动扩缩容,应用加速层则借助计算与通信的重叠以及内核融合技术进行运行时优化,基础设施访问层直接与GPU、网络及系统底层能力交互。这相当于为AI推理流程装备了一条智能流水线——每一层各司其职,协同运作,形成合力。
多项创新技术叠加之后,Blackwell平台单GPU的Token吞吐量最高可提升20倍。背后所运用的关键技术包括分离式服务、基于NVLink的大规模专家并行策略、NVFP4精度格式,以及多Token预测机制。简而言之,这一方案几乎将硬件潜能压榨到了极致。
英伟达将单Token成本确立为衡量AI总拥有成本的核心指标,而Blackwell平台已成功将其降至行业最低水平。
多家推理服务商已从中收获显著效益。Baseten借助TensorRT-LLM开源库在Blackwell平台上部署DeepSeek V4 Pro,其每秒Token输出量直接提升了50%。
Cognition则利用Dynamo推理框架高效管理GPU资源,无需从零搭建即可轻松扩展强化学习工作负载。Together AI同样采用TensorRT-LLM,帮助Cursor加速从模型优化到生产部署的完整链路。
开源生态进一步放大了这一全栈架构的优势。PyTorch等主流深度学习框架均原生基于CUDA构建,这意味着最新的研究成果一旦发布,即可立即在NVIDIA GPU上获得运行支持。
DeepSeek V4发布之后,vLLM和SGLang等推理框架迅速为Blackwell平台提供了部署方案,在一个月内实现了高达5倍的性能提升。这正是生态力量的体现——无需等待官方优化,社区力量已自主完成性能加速。

你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:英伟达DeepSeek V4推理成本降低80%要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点万知AI能通过上传错题截图或PDF,自动识别题目、定位错误步骤并归因到具体知识点,生成解析与同类巩固题。支持深度诊断、分层练习及错题集导出,还可设置复习计划按艾宾浩斯曲线推送题目,全程无需手动抄题分类。
产品介绍PPT只需聚焦卖点、场景和案例三页。卖点页通过痛点映射将技术参数转化为客户痛点;场景页用真实动线或客户录音生成直观对比;案例页只保留可验证数据并增强可信度,三者结合有效提升客户信任。
使用[Vocal][Diction]元标签强制开启咬字强化,需并列置于Prompt首尾。配合[Chorus]等段落标签限定执行范围。中文歌词需全角标点、双空行分隔段落、英文方括号标注段名。多音字后加全角括号及无声调拼音以保真。
一份打动投资人的AI商业计划书需回答六个核心问题:具体场景痛点、客户验证、技术护城河、盈利模式、团队落地经验及90天行动。使用“冲突-解法-证据”模板,避免技术架构图,用工作流对比图呈现效率提升,财务预测简洁至现金流转正与盈亏平衡点。
- 日榜
- 周榜
- 月榜
热点快看