




浙江理工马啸与南大李武军课题组联合提出EMCES

针对扩散模型样本增强缺乏可控性的问题,浙江理工大学与南京大学联合提出EMCES方法,将情景记忆引入可控扩散模型,引导高质量样本合成。实验表明,该方法可提升下游强化学习性能,且基于哈希的状态表示在不损失性能前提下使存储与时间成本分别降低约8000倍和25 5倍。
强化学习在游戏智能体、具身智能、大语言模型等多个前沿领域确实取得了一系列令人瞩目的突破。然而,当我们将目光转向真实应用场景时,一个核心难题始终难以绕过——高质量样本的获取不仅成本高昂,还可能伴随各种风险。正因如此,样本增强技术成为缓解这一困境的重要途径之一。
近年来,扩散模型凭借其强大的分布建模能力,吸引了广泛关注。研究者们顺势提出了基于扩散模型的样本增强方法,例如 SynthER [1] 便是其中代表,它通过合成高保真样本来扩充训练数据。听起来很理想,对吗?
但问题在于:合成样本虽能模拟真实环境的动态,是否真的最有利于智能体的策略学习?为此,论文专门设计了一项实验,采用经典的离线强化学习算法 TD3+BC [2],在合成样本集上训练智能体并评估其表现。实验选择在 D4RL 基准 [3] 的 Hopper 环境的 medium-expert 样本集上进行。该数据集包含约 200 万条直接从环境预先采集的样本,而合成样本集由 SynthER 生成,规模从 10 万条到 500 万条不等。
结果如下图所示(原论文图 1b)。
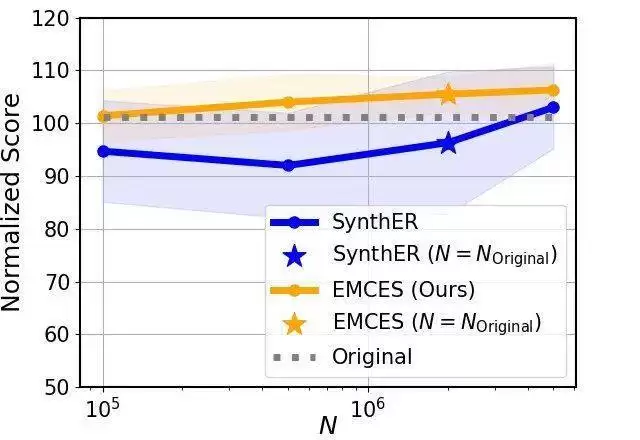
从图中可以清晰看出,只有当合成样本集的规模远大于原始样本集时,它才有机会充分覆盖高质量样本区域,进而提升策略性能。换句话说,目前的扩散模型样本增强方法仍存在明显局限——其合成过程缺乏有效的可控机制,难以优先合成那些对策略学习更有价值的高质量样本。
为解决这一难题,浙江理工大学马啸讲师与南京大学李武军教授课题组联合提出了一种高效样本合成新方法——EMCES。该方法的核心理念是将情景记忆机制引入可控扩散模型,借助情景记忆引导高质量样本的合成,从而提升下游强化学习算法的表现。
据我们所知,EMCES 是首个将情景记忆引入可控扩散模型,并用于指导强化学习样本合成的工作。此外,论文还提出了一种基于哈希的状态表示方法,用于提升情景记忆的存储与检索效率。实验结果表明,在保持下游强化学习算法性能不变的前提下,存储开销降低了约 8000 倍,时间开销降低了 25.5 倍。
这项研究已被 ICML2026 接收。南京大学李武军教授为通讯作者,浙江理工大学马啸讲师为第一作者,南京大学硕士生李天为参与作者。

论文标题:Episodic Memory-Guided Controllable Experience Synthesis for Reinforcement Learning
论文地址:https://openreview.net/forum?id=mjYcL7esQO
1. 方法简介
情景记忆在人类大脑中扮演着举足轻重的角色,它使我们能够快速学习并高效利用过往经验。受此启发,在强化学习领域,情景记忆可以存储、整合并检索有价值的历史经验,让智能体直接访问高质量的过往信息,从而显著提升样本效率。
基于这一思想,EMCES 利用情景记忆来存储历史经验中的高价值信息,并为可控扩散模型设计控制条件,引导其合成更高质量的样本。具体而言,EMCES 包含三个核心组件:基于情景记忆的可控扩散模型、基于情景记忆时序差分误差的优先条件采样策略,以及基于哈希表示的情景记忆机制。
下面这张图展示了 EMCES 的完整架构:
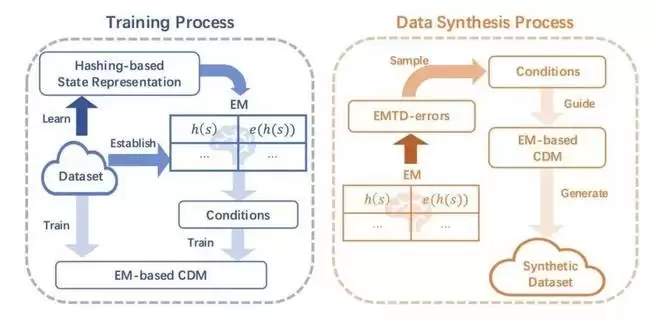
1.1 基于情景记忆的可控扩散模型

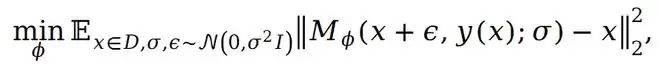





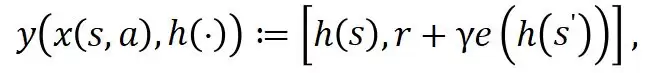

1.2 基于情景记忆时序差分误差的优先条件采样策略
尽管基于情景记忆的可控扩散模型本身已能直接用于样本合成,但其核心优势在于能以可控方式合成高质量样本。直观上看,样本合成过程不仅应符合底层样本分布,还应进一步优先合成那些对智能体策略学习更具价值的样本。

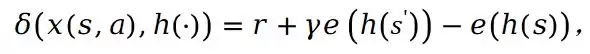

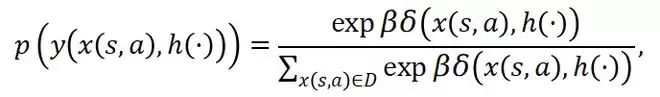

1.3 基于哈希状态表示的情景记忆

在情景记忆机制的具体实现上,论文沿用了团队前期工作 [5] 中的 KD-树方法。其对应的存储复杂度、检索时间复杂度和构建时间复杂度如下:
![]()


2. 实验结果
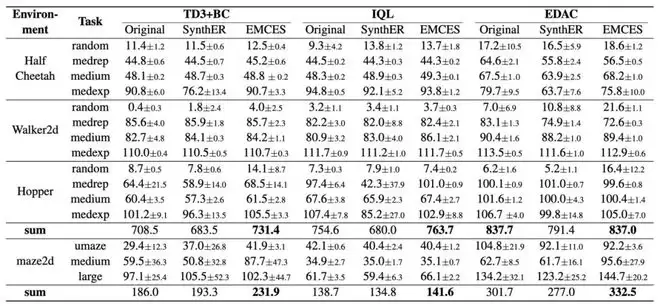
为验证 EMCES 的有效性,论文分别在离线强化学习和在线强化学习两种设定下进行了实验。离线部分选取了 D4RL 基准中的 HalfCheetah、Walker2d、Hopper 和 Maze2D 作为实验环境,并采用 TD3+BC、IQL 和 EDAC 三种代表性离线强化学习算法来评估合成样本集的质量。从下表中可以看出,EMCES 在大多数任务中都显著提升了下游算法的性能,且使用合成样本训练的效果往往能够达到甚至超过直接用原始样本集训练的效果(原论文表 1)。
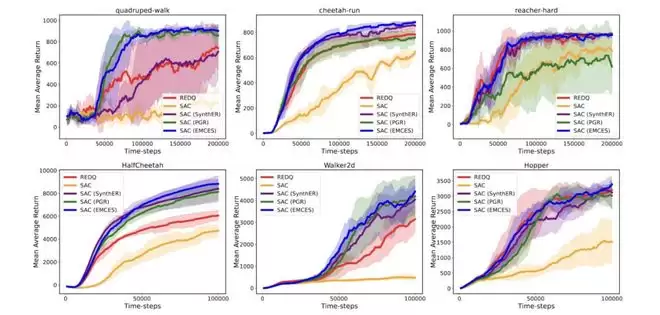
在线强化学习部分,论文选择了 quadruped-walk、reacher-hard、cheetah-run、Walker2d、HalfCheetah 和 Hopper 这 6 个环境来评估 EMCES。在线算法采用 SAC。除了 SynthER 外,还与另一个专注于在线强化学习的样本增强方法 PGR [6] 进行了对比。更多实验细节可查阅原论文。下图结果(原论文图 4)表明,SAC (EMCES) 能持续提升样本效率,并且优于 SAC (SynthER) 和 SAC (PGR),这充分说明 EMCES 合成的数据质量更高。
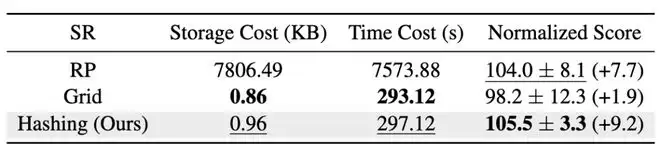
论文还专门探讨了情景记忆中的状态表示方法。在表格(原论文表 4)中,他们总结了 EMCES 在不同状态表示下的归一化分数,括号内数字表示相对于 SynthER 的提升幅度。所有实验均在同一台工作站上进行,配置为 36 核 72 线程的 Intel Xeon Gold 6240 CPU @ 2.60GHz、377 GB 内存和 8 块 NVIDIA GeForce RTX2080Ti GPU。结果清晰显示,EMCES 在所有状态表示下都取得了优于 SynthER 的表现。
这组结果验证了 EMCES 整体框架的有效性。同时,表中还汇报了在不同状态表示下建立情景记忆所需的存储成本和时间成本(包含检索时间和构建时间)。可以发现,基于哈希的状态表示和基于网格的状态表示均能显著降低这两项成本。与基于随机投影的状态表示相比,在不损失归一化分数的情况下,基于哈希的状态表示将存储成本降低了约 8000 倍,时间成本降低了约 25.5 倍。此外,论文还对可控扩散模型的条件设计、采样策略的设计进行了消融实验,更多细节可参考原文。
3. 全文小结
总结 EMCES 的核心优势,主要体现在以下几个方面:
合成过程强可控:EMCES 将情景记忆机制引入可控扩散模型,通过情景记忆构造条件,引导扩散模型合成与目标任务更相关的样本,显著提升了样本增强的可控性。
合成样本质量高:利用情景记忆的时序差分误差来评估样本对策略学习的潜在价值,并在采样时优先关注那些更有价值的样本区域,从而合成出高质量样本。
情景记忆高效:采用基于哈希的状态表示后,情景记忆机制在不降低下游算法性能的前提下,存储开销较已有方法降低了约 8000 倍,时间开销降低了 25.5 倍。
参考文献:
[1] Lu, C., Ball, P. J., Teh, Y. W., and Parker-Holder, J. Synthetic experience replay. In NeurIPS, 2024b.
[2] Fujimoto, S. and Gu, S. S. A minimalist approach to offline reinforcement learning. In NeurIPS, 2024.
[3] Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. D4RL: datasets for deep data-driven reinforcement learning. CoRR, abs/2004.07219, 2020.
[4] Kong, W. and Li, W.-J. Isotropic hashing. In NeurIPS, 2012.
[5] Ma, X. and Li, W.-J. State-based episodic memory for multi-agent reinforcement learning. Machine Learning, 112(12):5163–5190, 2024.
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:浙江理工马啸与南大李武军课题组联合提出EMCES要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点探索AI领域最新动向,DeepSearcher这个创新工具确实值得仔细看看。它的架构、原理和实际应用,到底能为开发者带来什么?下面一步步拆解。 核心要点: 1 DeepSearcher与同类工具的横向对比 2 架构细节与研究流程解析 3 在智能检索生成技术中的独特优势 近期OpenAI的深度研
机器学习听起来像是个黑盒子,其实剥开来看,它的基本过程和日常做AB测试、写量化策略并没有本质区别——无非是定目标、找问题、想方案、动手干、回头看。只是在这个过程里,我们用的工具、思考的角度,以及需要留意的坑,确实有些不同。 1 基本过程 1 1 机器学习的五步流程 把机器学习当作一个闭环工作项来看
想要顺利交付一个机器学习项目,通常可以遵循以下几个步骤来推进。这套流程并非硬性规定,但在大多数实际场景中,按照这个顺序执行能显著减少返工与调试的麻烦。 1) 明确问题 首先要清楚要达成的业务目标。这一步的关键在于:如果公司已经积累了海量数据,就应当基于现有数据来定义目标;如果数据尚未采集,则需要先锁
瑞萨电子最新发布了一款基于SMARC 2 0架构的可扩展模块化系统(SoM)参考设计。该方案整合了10款瑞萨IC产品,涵盖微处理器、电源芯片和模拟器件,专为AI IoT应用中的面部与物体检测、图像处理以及4K视频回放而打造——广泛应用于监控摄像头、检测设备,以及工业和楼宇自动化中的HMI与嵌入式视觉
- 日榜
- 周榜
- 月榜
热点快看