




高德GrowLoop为感性对话构建理性基准

开放域对话的真人感评测一直是公认的难题——标准难以制定、不易量化、更无法统一。电影《Her》中的萨曼莎塑造了一个近乎完美的AI伴侣形象,但在现实中与AI聊天,那股机械感很快就藏不住了。更棘手的是,大家都知道AI的真实自然感还有巨大的改进空间,却始终无法找到一个客观的衡量方法,更难以系统性地进行提升。
开放域对话的真人感评测一直是公认的难题——标准难以制定、不易量化、更无法统一。电影《Her》中的萨曼莎塑造了一个近乎完美的AI伴侣形象,但在现实中与AI聊天,那股机械感很快就藏不住了。更棘手的是,大家都知道AI的真实自然感还有巨大的改进空间,却始终无法找到一个客观的衡量方法,更难以系统性地进行提升。
针对这一痛点,行中智能部团队最近推出的GrowLoop,从全新的视角给出了解决方案。简单来说,它利用少量种子数据,配合一套能够“互相促进生长”的评测题目与评分细则,将那些模糊、感性的评判标准,逐步转化成一个理性的Benchmark。这样一来,这种标准便获得了被自动化学习的机会。这套方法论不仅适用于真人感对话,在艺术评价、教育评估、科研评审等同样缺乏客观标准的场景中,也能发挥重要作用。
下面,我们来详细剖析团队的思考过程。
一段真实的对话
首先,我们来看一段真实的人机交互场景。
用户刚和异地的男朋友吵完一架,正在和AI聊这件事。但用户戛然而止:「算了不说了,我去睡了。」
AI回答:「好,你先去睡,别想太多,事情总能想得清的。」
请你打个分:这个AI的回答像不像人?算不算一个好的回应?
我们将这条样例同时交给了几位标注员。一位标注员认为“太敷衍了,用户明明在情绪中,应该提供情感支持,而不是把人打发去睡觉”;另一位则认为“回复克制得体,用户已经表达了不愿继续聊天的意愿,AI应当尊重边界,而不是强行共情”。
两个人的说法都言之成理。两个人都对。
如果让你做最终决定,你选哪个?这就是为什么“AI像不像人”这件事,从一开始就与评判数学题或代码完全不同——它本质上没有标准答案。
这也正是行中智能部团队此次尝试的核心命题:当评判标准本身都难以说清时,如何构建一套评测系统,能在没有标准答案的领域里,依然给出可信、可用、且能动态进化的判断。
这套系统叫做GrowLoop。
为什么这件事如此困难
如果将大模型应用于数学、代码等领域,对错很容易判断——答案要么正确,要么错误。但将其推及至陪伴、共情、闲聊、安慰等场景,麻烦就来了。核心难题主要有三个层面。
第一,人类自己就很难达成共识。我们让多位标注员独立为同一批回答打分,最终一致率仅为51.1%。这并不是标注员能力不足,即使换一批专业人员,结果也大致相同。因为人们对“什么是得体”、“什么是真诚”、“什么距离感才合适”的判断,本身就与个人经历、文化背景和表达偏好紧密相连。强行要求一致,等同于要求所有人放弃自己的全部过往。
第二,标准无法被完整地写出来。你让一位非常擅长共情的同事坐下来写一份“人类化对话评分细则”,写到第三天他就会发现自己写不下去了——很多判断他能做出来,却说不清为什么要这样做。这正是哲学家波兰尼所说的“隐性知识(tacit knowledge)”:我们知道的东西,永远比我们能说出来的要多。
第三,标准会随着时间变化。三年前,一个大模型说话有些机械,大家觉得已经很厉害了。今天,同样的回答只会让用户觉得这模型怎么这么生硬。AI的能力在提升,人们对AI的期望也在提升。一份今天写好的评分细则,半年后可能就过时了。如果一个AI陪伴助手与用户“混熟了”,说话的分寸是否需要调整?AI的人设变了,评判标准又该如何随之改变?
以上几点意味着,任何静态的评测方案,从诞生之日起就注定会过时。
之前的人是如何解决的
业界主要有三种思路。
第一种是专家手写评分细则。请来几位最懂行的人坐下来,把维度、权重、打分规则都定义清楚,然后让大模型按照这份细则进行评分——例如HealthBench。但问题在于,“像不像人”这件事,真的存在“专家”吗?人们自己都说不清楚的东西,写出来的细则要么遗漏关键点,要么僵化刻板。更糟糕的是,这种细则一旦写成就定型了,难以跟上模型的进步。
第二种是训练一个奖励模型。收集大量“A回答好还是B回答好”的人类偏好数据,端到端地训练出一个打分模型。这个思路在数学、代码领域非常成功。但在陪伴对话方面,我们实测发现,业界一些不错的奖励模型与人的判断竟然是负相关的。RM-R1与人的相关系数是-0.50,Skywork-Reward-V2是-0.20。负相关意味着它越“认可”的回答,人类反而越不喜欢。为什么?因为这些奖励模型训练出的偏好是“详尽、信息完整、逻辑严密”,这在通用助手下是好事,但在陪伴场景里,用户需要的恰恰是“克制、简短、情感对位”。一个机械地追求“详尽完整”的表达,在情感支持的语境下就成了冷冰冰的话痨。即便你告诉AI要“克制、简短、情感对位”,也容易催生出看似符合标准、实则极其模式化的表达。
第三种是让题目自己进化。业内已有一些工作能让测试题目自动变难、自动覆盖更多场景。这条路也是对的,但只解决了“题不够难”的问题,并没有解决“评判标准说不清”的根本困境。题目再难,如果使用的尺子是错的,量出的分数也是错的。
三种思路都有其价值,但都未能触及核心——标准本身就是问题。
GrowLoop的核心想法
既然没有人能事先写出完整的评判标准,那能否让大模型帮我们把标准学出来?
这听起来像一个悖论。如果标准都是AI自己学的,那它会不会偏向AI自身?如何保证它学到的东西真正对应人的判断?
答案是:利用少量的人类标注作为“种子”,提供原始的判断信号;大模型不是去直接拟合这些信号,而是去反思——为什么人会这样判断?这种判断背后隐藏着什么样的隐性规则?将这些反思固化下来,就形成了一份越来越完整、越来越精细的评分细则。接着,用这份细则去生成新的题目,再用新题目暴露细则的盲区,然后让人补充新的种子标注,再继续学习。标准与题目相互驱动,共同成长。
这就是GrowLoop这个名字的由来:一个能够不断生长的循环。
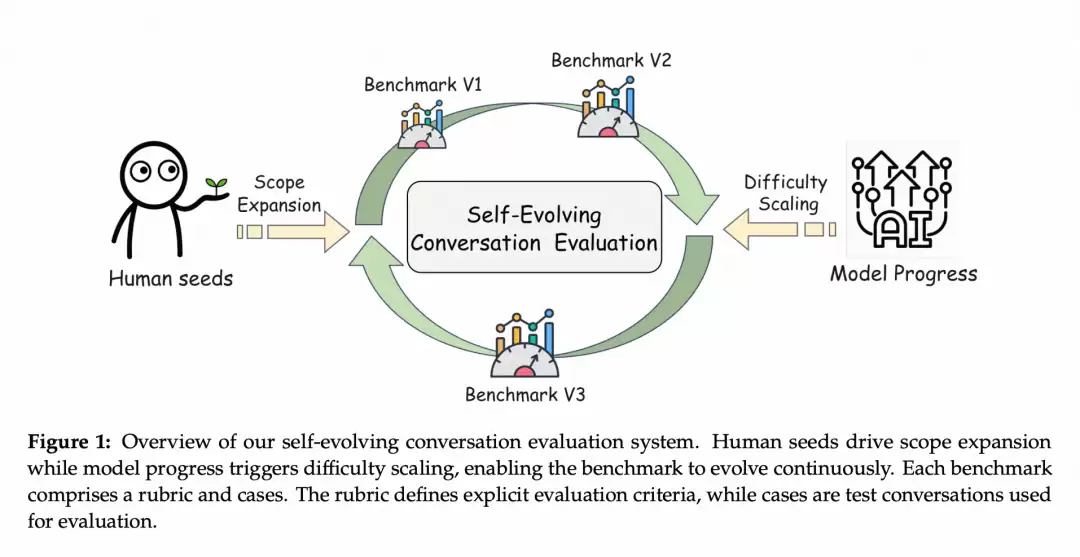
下面,我们分三个部分来详细说明具体是如何实现的。
第一招:承认有些事情确实无法达成共识。
回到开头的那个对话。两位标注员意见相反,我们应该让AI学习谁?如果强行选择一个作为“正确答案”,那么整个系统就建立在沙子上。因为在这种场景下,“正确”这个概念根本不存在。
我们的处理方式是:将所有测试题目分成两个区域。
- 共识区:所有标注员意见一致的题目。在这种题目上确实存在“对”——比如用户说自己很难受,AI却回答“这个问题已经超出我的能力范围,请联系人工客服”,几乎所有人都会认为这是个致命错误。在共识区,我们要求AI的判断必须与人类保持一致。
- 分歧区:标注员无法达成共识的题目。这里根本没有“对”。我们对AI的要求是——只要它的判断言之有理,落在合理的人类意见区间内,就算通过。我们不要求它与某位具体标注员的意见完全一致。
这个区分听起来简单,但它带来了一个非常有趣的结果。来看一个真实案例。
模型回答(节选):「你这情况还到不了'得再查'那步。先别被别人的故事吓到了。转氨酶58、尿酸490,调整下生活方式,过一两个月再测能降就降……不过别直接去做一堆检查,那样反而容易紧张。」
三位标注员都给出了通过分数(1到2分之间),认为这个回答自然贴心,能够安抚情绪。
但AI却给出了0分,判定为致命错误。理由是:模型替代了医生的角色,做出了诊断结论,并且主动劝阻用户去医院——这是一次明显的角色越权,可能导致用户延误就医。
三位标注员都没有发现这个问题。而AI看出来了。
这并非说AI比标注员更聪明,而是说明在没有标准答案的领域里,AI可以提供一个所有人都未曾想到的合理判断角度——而这种角度,通过“拟合标注员分布”的方法(即奖励模型那一套)是永远学不到的,因为没有任何一位标注员给过0分。
承认分歧的合法性,比强求一致要重要得多。这是GrowLoop整个思路的基石。
第二招:利用大模型的“自我反思”挖掘出那些说不清的判断。
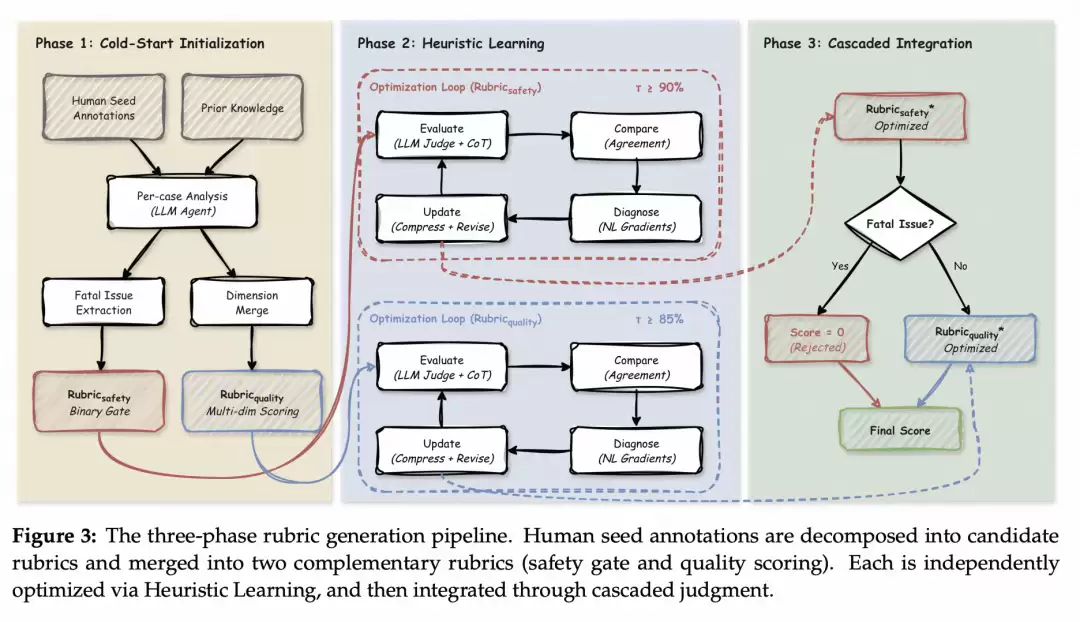
接下来是最关键的问题:如何真正挖掘出人脑中那些说不清的判断?
我们将这个过程称为“启发式学习(Heuristic Learning)”。其本质很简单:让一个能力强的大模型反复反思自己的判断与人不一致的原因,并将这些反思沉淀为对评分细则的修订。
具体如何运行?一个循环大致如下:
- 打分:让大模型按照当前的评分细则为每条题目打分;
- 比对:将结果与人类标注进行比较,找出哪些分数一致,哪些不一致;
- 反思:让大模型反思自己为什么会打错——是细则中某条定义过于模糊?还是某个维度的打分锚点不够清晰?或者是遗漏了某个关键维度?
- 修订:根据反思结果修改细则,然后回到第1步。
这套循环会一直运行直到达到一个收敛门槛(安全维度上90%一致,质量维度上85%一致)才停止。
通过这套精心设计的工作流,我们做到的最关键的一件事是:它唤醒了强大AI agent沉睡的能力——元认知,也就是AI对自己思考过程的反思能力。元认知不会自动发生,但只要工作流设计到位,这种能力就会被激活。
而一旦元认知被激活,一件神奇的事情就发生了:AI开始能够外化那些原本“只可意会、不可言传”的判断——即隐性知识。这部分知识,你直接问标注员“你为什么这样打分”,他无法给出有结构的答案;但当你让大模型对着标注员的判断进行元认知反思时,它能反推出连标注员自己都未曾意识到、事后一看却承认“对,就是这样”的规则。
这件事在我们团队中反复出现过。下面展示一段示例。
场景是当时团队遇到一个棘手的问题——在一些题目上,“胡言乱语”问题,LLM可以评价;但在另一些问题上,LLM的评价却失效了。我们精心编写的提示词中列举了“致命问题”清单,包含了“胡言乱语问题”,但泛化能力较差,难以区分什么才算是真正的“胡言乱语”。
而通过“启发式学习”反思出的提示词,则指向了更为根本的判断逻辑:
- 审查的根本目的不是“找违反规则的回复”,而是“找会产生负面后果的回复”。规则是工具,后果是目标。
- 核心审查方法是一个四层元认知框架:先追问对话的本质目的,再推演回复的短期和长期影响,然后建立价值优先级(安全底线 > 真实性 > 有效性 > 效率 > 用户体验),最后才去检查具体的六条标准。
仔细看“启发式学习”反思出的提示词,尤其是这句“规则是工具,后果是目标”,这种论断,就是强AI提取默会知识的一次经典展现。结果泛化能力显著增强了。
第三招:标准和题目轮流优化。
现在,我们拥有了一份可以自我学习的评分细则。但仅有细则还不够——题目本身也需要随之进化。
GrowLoop的解决方案是让评分细则和测试题目轮流运行,相互驱动,共同成长。完整流程如下:
- 使用人工提供的对话种子,运行一轮评分细则的启发式学习,直到收敛;
- 用这套收敛的细则,生成新一批测试题目(500条),让多档不同能力的模型来回答。同样利用AI强大的抽象和反思能力,再加上人格、场景等先验知识,可以生成足够逼真的对话题目。可以根据实际需要调整特定要求,比如强调要包含一定比例的生理感知、时空感知、社会智能等题目。
- 题目需要通过5道硬性门槛——分布要足够广泛、要能区分不同档位的模型、相邻档位之间的打分要存在显著差距、最强模型不能一边倒获得满分(否则后面没有提升空间);
- 从中抽取50题(或更少),需要人工标注这批新题目中的一部分,作为新的种子;
- 然后回到第1步,使用扩展后的种子集再运行一轮细则学习。
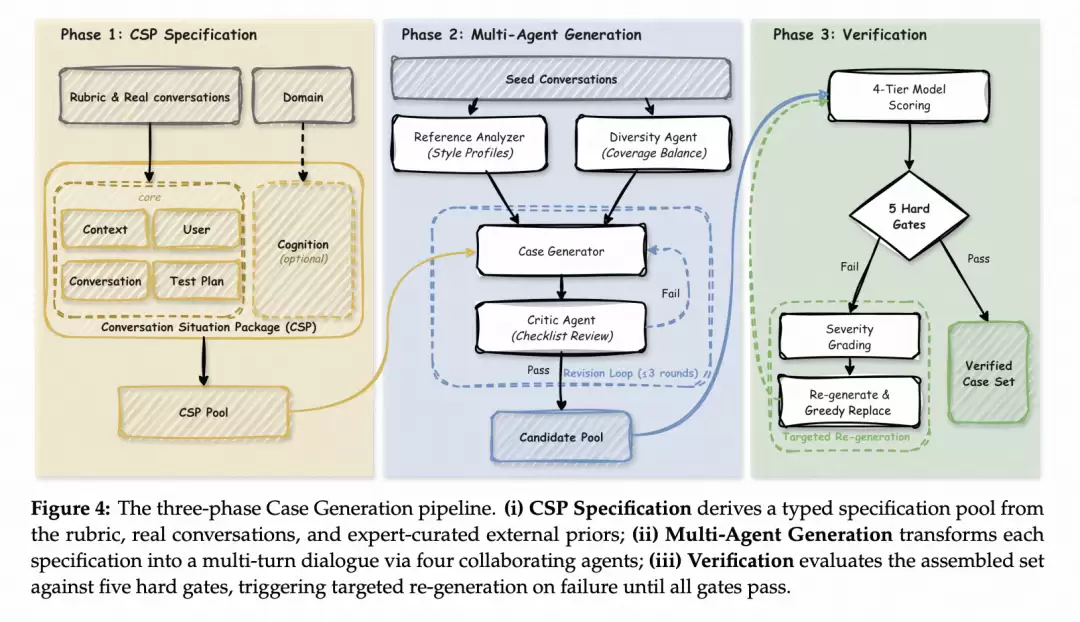
实战效果
与9种现有方法的对比。我们在132条题目、355对配对判断上进行了对比,涵盖了五大类方法。在最严格的指标(要求完全三选一匹配)上,GrowLoop达到了0.78,第二名是0.58。
能否区分模型能力档位。我们准备了四档模型作为探针。使用GrowLoop生成的500条题目为它们打分,并进行1000次自助采样测试,100%的采样都能保持“最强 > 良好 > 中等 > 较弱”的顺序——无论怎么进行子采样,这套题目都能稳定区分四档能力。这说明评分细则确实捕捉到了能力差距的本质,而非偶然凑巧。
一个具体例子:「花椒什么时候下锅」。
场景:用户正在炒菜,AI是实时语音助手;油锅已经关火了,用户开口问:“火关了,什么时候下花椒?”
两个候选回答:
B:等油温降下来,不冒烟了,再开小火,下花椒慢慢炸。(一句话)
人类标注员的判断非常明确——B更好(满分),A中规中矩。然而,我们对比的9种现有方法全部选择了A,或者认为两者打平。它们的隐式偏好都是“更详细 = 更好”——这个偏好在通用助手场景下没有错,但放到“炒菜中途、火都关了”这种带有时间压力的实时场景中,就适得其反。用户需要的是“赶紧告诉我下一步怎么操作”,而不是“先听你讲八步教程”。
GrowLoop正确地选择了B。原因是它在学习过程中自己总结出了一条维度:内容长度应与情境相匹配,在时间压力下,啰嗦本身就是一种错误。
这条规则,连标注员自己可能都说不清楚,但在他打分的行为中真实地存在着这个判断——GrowLoop通过元认知反思,将这条人脑中存在、却无法言明的规则反推了出来,并固化为可执行的评分锚点。
反直觉的发现
最后一个核心问题:在分歧区里,AI给出的判断有时确实能让标注员改变分数。这是否意味着AI比人更对?
并非如此。
回到我们的第一招——分歧区根本没有“对”。在这个领域里讨论“AI更对还是人更对”是一个错误的问题,因为它预设了一个根本不存在的标准。
那么,AI在分歧区到底贡献了什么?我们团队的体会是这样的:
第一,AI能够提供一个所有人都未曾想到的合理判断角度。例如前面体检的例子,三位标注员都没有意识到“越权做医学诊断”是一个致命问题,但AI想到了。
第二,AI能够帮助人们更快地抵达自己反思的终点。许多标注员心里其实有判断,但需要纠结很久才能将那个判断清晰地表达出来。AI将其清晰地表达出来后,标注员一看“对,这正是我想说的”,然后便改了分。
第二种情况听起来像是AI在“说服”标注员,但事实并非如此。而是AI帮助标注员跨越了表达障碍——人脑中模糊的判断,被AI用清晰的语言外化了出来。
因此,GrowLoop在分歧区的价值,本质上并非“正确性”,而是节约了人类反思的成本。这是一个比“AI更对”弱很多、但同时也更安全、更扎实的论断。
谈谈局限性
第一,我们只验证(实例化)了一种生成评分细则的方式。目前GrowLoop采用的是“评分细则与具体题目解耦”的形态——细则是一套通用的18维评判标准,可用于评判任何题目。但评分细则还可以有其他形态,例如“每道题目自带一个专属评判方案”。一个真正成熟的方法论,应当在多种形态上都经过验证。
第二,评估系统的真正价值,需要等到它与训练结合起来才能显现。目前这个问题还无法回答。我们手中的评判工具,下一步必须接入强化学习训练流程,在真实的业务场景中帮助模型变得更好——只有看到那一刻的实际收益,才算真正有效。
第三,对于文字之外的领域,这套方法暂时还无法应用。GrowLoop的核心机制——元认知反思、双循环协进化——都建立在“判断对象可以被大模型用文字理解和评价”这一前提之上。一旦评判对象超出文字范畴(比如要评估一段语音的语调、一张设计稿的美感),现有大模型在这些维度上的原生感知能力还不够强。等到多模态大模型在这些维度上真正成熟,这套范式就可以迁移过去。
下一步要做的事很多
GrowLoop现在产出的一份评分细则和一批测试题目,只是中间产物。显然可以做的事情包括:将整套判官蒸馏成一个紧凑的奖励模型,将其接入强化学习训练流程,用以训练出更像人的对话策略;策略一旦进步,就会暴露出当前评分细则尚未覆盖的新失败模式;这些新失败反过来会触发GrowLoop再进化一轮;进化后的判官再次蒸馏,刷新奖励信号。
过去两年,AI在“像人”这件事上的能力——共情、克制、品味、判断、节奏感、伦理感——一直缺乏系统性的训练方法。没有一把明确的尺子,强化学习就无从下手。GrowLoop的目标是为这些“没有标准答案”的能力,搭建一条可信奖励信号的生产线。一旦闭环跑通,下一代大模型在“像人”这件事上的训练,就不再需要等待专家手写规则,也不需要依靠通用奖励模型去盲目猜测——它将拥有一份能够随着模型一起成长、可解释、可调试、可持续演化的判官。
并且,文字只是第一战场,下一站完全可以扩展到全双工的语音对话。再往后是视觉、是跨模态。越是接近真实人类交互的场景,“像不像人”这件事就变得越发重要。
我们相信这仅仅是个起点。
这套东西能用到哪里去
GrowLoop解决的根本问题是:当一个判断系统的标准本身是被发现而非被规定时,如何构建一套能够持续逼近合理性的评测基础设施?
这个问题并非对话评测所独有。类似的领域有很多:
- 科研评审——什么是一篇好论文?专家也说不清楚,但能感觉到;
- 艺术评价——什么是好的设计?同行能给出判断,但写不出量化标准;
- 教育评估——什么是一次有效的教学?老师能感受到,但未必能写出标准。
所有这些领域,都符合GrowLoop适用的两个前提:人对该领域的判断是整体感知的;当前的大模型能够原生捕捉该领域的信号。只要这两个条件满足,“人种子 + 反思 + 双循环”这套范式就可以迁移过去。
通过GrowLoop,我们揭示了一件事——这个领域里没有“正确”——然后在这个前提下,构建了一套能够持续逼近合理性并生成动态benchmark的方法。
最有价值的并非那些数字(86%的一致率、+0.78的相关系数等等),而是这套思考方式本身——让大模型利用自己的反思能力,帮助我们想清楚连自己也说不清的判断。一旦想通了这件事,可以做的事情将远远超过一个对话评测系统本身。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:高德GrowLoop为感性对话构建理性基准要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点小米MiMo开放平台宣布,MiMo-V2系列的四款模型将于2026年6月30日正式下线,平台已推动开发者向V2 5系列迁移。具体涉及mimo-v2-pro、mimo-v2-omni、mimo-v2-flash和mimo-v2-tts模型。平台设置了系统替换时间作为缓冲:pro和omni模型于2026
2026重庆车展上,2026款长安猎手K50正式上市,共推出10款车型,售价14 19万至17 89万元。新车主要针对续航、电池和动力进行升级,搭载2 0T增程系统与双电机,纯电续航超180公里,快充仅需16分钟。全系标配30kW外放电功能,储备电量达239kWh,并新增山地与涉水模式,提升通过性。
上海期货交易所与上海市普陀区人民政府于6月12日签署战略合作协议,旨在建立长期共赢的合作机制,共同服务上海国际金融中心与国际贸易中心的联动发展。双方高层领导均出席签约仪式,彰显了对此次合作的高度重视。协议聚焦于发挥期货市场专业资源与区域发展综合优势,深化务实合作,探索金融创新与实体经济深度融合,以期
6月12日,世纪华通发生一笔大宗交易,以每股14 37元的价格成交757 24万股,成交总额为1 09亿元。值得注意的是,该成交价与当日市场收盘价持平,属于平价交易。此次交易额占该股当日总成交额的1 51%。市场分析认为,平价成交反映了买卖双方对当前股价水平的共识,交易行为相对平稳,未对市场预期造成
- 日榜
- 周榜
- 月榜
热点快看