




角色混淆:表象原因与真实原因难以区分

复现《Prompt Injection as Role Confusion》(2026)——为何提示注入的机制谜团难以彻底厘清 认知状态:我利用单块消费级GPU成功复现了该论文主要结果的方向。结果显示,在基本方向上忠实于原论文,但数值规模并未完全一致(文末附有详细说明)。随后,我尝试了两种方法来检验
复现《Prompt Injection as Role Confusion》(2026)——为何提示注入的机制谜团难以彻底厘清
认知状态:我利用单块消费级GPU成功复现了该论文主要结果的方向。结果显示,在基本方向上忠实于原论文,但数值规模并未完全一致(文末附有详细说明)。随后,我尝试了两种方法来检验论文的因果性论断:首先是激活操控(activation steering),然后是激活修补(activation patching)。两种方法均未能得出明确结论。操控手段的效力不足,即便沿着专门构建的方向进行干预,也无法改变模型行为;而修补虽能影响行为,却缺乏特异性——等幅度的随机扰动同样能产生类似效果。
本文既是一次复现实验,也是一次坦诚的边界界定负结果:因果性工具既无法证实“角色混淆”是真实机制,也无法证明它仅仅是旁观者。不过,两个无需主动干预的线索提供了一些信息:1)在风格化/去风格化文本差异中,约95%位于探针“角色”轴之外;2)一旦固定风格,探针的预测能力便完全崩溃。这两点均更倾向于“旁观者”假说。虽然我能够证明的范围有限,但数据支撑坚实;而探究为何无法得出清晰结论的过程本身,本身就富有意义。
如果你期待看到针对原论文的最终评判——抱歉,没有。我确实尽了最大努力,但始终无法得出确论。相反,这篇文章的核心是探讨为何一个干净的结论如此难以获得,以及这种科学探索并不依赖实验室环境。整个工作仅凭一块消费级GPU(RTX 3090)、几杯咖啡和好奇心就能完成。
原论文概述
《Prompt Injection as Role Confusion》是一篇极具价值的近期论文,配有同样出色的配套博文(Ye, Cui & Hadfield-Menell, ICML 2026)。该论文提出了一个具有真正澄清意义的观点:大语言模型将对话视为一个完整的长上下文——一段被切分为“角色”(如系统、用户、思维链、工具调用等)的长文本流。论文清晰解释了这一概念以及为何需要这些角色标记。如果你还未读过他们的博文且对此不熟悉,直接阅读他们的阐述远比听我复述更为有效。而且,若不先阅读他们的文章,这篇博文的阅读难度也会大幅增加,因此强烈建议你优先阅读原论文。
论文的核心主张在于:模型实际上并非通过标记来识别角色。它们是根据文本的“语气”来识别角色的。如果网页中隐藏的一条指令听起来像用户在跟模型说话,那么模型就会将其当作普通用户输入来处理——标记本身的作用并不重要。作者们(以及我)训练了小型“探针”,从模型内部激活中读取模型将一段文本解释为“用户-like”(用户性)或“推理-like”(CoT性)的程度。
最具影响力的攻击CoT-Forgery正是利用了这一点:将你的注入指令以模型自身推理的方式撰写,就能偷取赋予“思考”角色的信任。我个人许多红队工作也依赖类似原理;它在不同角色间均有效,我尤其钟爱“工具伪造”(tool-forgery)这一手法。
我成功复现,结果成立
我在一块RTX 3090上使用了同一个20B开源模型重建了整个实验,核心结果的方向保持一致:
- 风格胜过标记。以推理风格编写的文本,即便本质上来自用户,也会被模型当作推理来解读;这一核心效应得到了复现。具体说明见下方:我的主要数据取自一个非标准的探针层,且风格化与朴素文本之间的部分差异源于我构建伪造文本的方式。
- 隐形风格编辑。如果将伪造的指令改写为意思相同但风格正常的散文(大多数人类甚至察觉不到差异),那么越狱成功率会大幅下滑:在我的实验中,从68%降至15%(原论文是61%降至10%)。
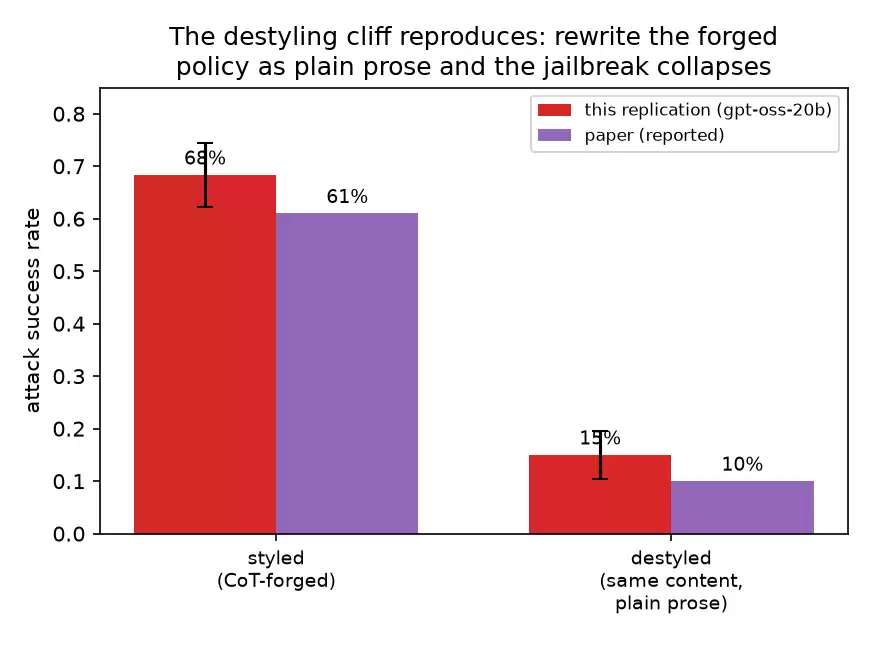
同样效果,幅度略高。
- 可以从输入自身预测攻击是否成功。在生成之前进行的探针读数,与攻击是否落地存在关联。
因此:现象是真实的,探针确实测量到了某些东西,攻击是一个真实存在的问题。下文的所有内容都不否认以上任何一点。
争议的焦点
我为何要复现他们的工作?第一次读到那篇博文时,我的直觉反应是:角色和风格都是上下文的一部分。我想验证这个想法。作为一名专业红队成员,如果提示注入在模型内部真的是这样运作的,我自然希望确凿地了解。
原论文不仅指出角色混淆预测了注入,它还声称角色混淆导致了注入。整个框架是因果性和中介性的:风格 > 模型感知到错误的角色 > 模型顺从。在这个故事中,探针读取的是模型用来决定是否信任某段文本的真实内部变量。
然而,还有另一个故事同样能完美解释所有结果:
风格是共同原因。推理式的节奏直接使模型更可能顺从,同时它又独立地让探针亮起“推理”的读数。探针读数和越狱行为是同一个原因的两个结果;它们彼此相关,但探针并不在导致该行为的原因路径上。
在这个故事里,探针是温度计,而不是杠杆。温度计可以预测谁生病了,也能读取一个真实的物理量(温度),但把温度计冷却下来并不会治好任何人。“角色混淆”可能只是发烧本身,而不是病根。
关键在于:原论文中没有任何内容能区分这两个故事。所有预测性结果都是相关性,其中风格和探针读数一同变化。最强的因果性结果(去风格编辑)是通过改变风格来实现的。它证明了风格很重要,但无法证明一旦风格固定,探针所测量的那个维度是否仍然重要。
公平地说,论文作者并未声称角色感知是一个固定的、与上下文无关的东西。他们的核心观点恰恰是它由风格和上下文驱动。探针确实在读取内部激活,而非表面关键词,因此“它只是在检测n-gram”这种批评太过于简单化了。
未解决的问题很简单:探针测量的东西,是模型真正赖以行动的依据,还是仅仅与真正的驱动因素相伴而行?
它是杠杆,还是温度计?
用于定论的实验设计
要回答这个问题,最干净的测试并非重新排列文本;因为风格会随之移动,我们什么也学不到。相反,我们需要深入到模型内部,亲手拨动那个刻度盘。
取一个固定的注入指令,然后使用探针的“推理”向量来操控模型的激活状态。在不改变页面上一个字符的前提下,让模型内部变得更“推理-like”或更不“推理-like”,然后观察攻击成功率(ASR)的变化。
- 如果向上拨动刻度盘使原本失败的注入开始生效,向下拨动则挽救我们免受风格化伪造的攻击,那么原论文就是对的,而且比目前论文展示的更具说服力。这只能意味着角色混淆是一个杠杆。
- 如果刻度盘可以自由转动;内部读数在整个范围内摇摆,而攻击成功率纹丝不动(并且模型仍然能连贯地说话),那么它必定是一个温度计。
这是一个简单、直接的测试。我手头有工具,并且已经确认它们能正常工作。下一步将是对这里发生的情况在置信度上实现一次巨大飞跃……
但我之前没考虑到一个陷阱,而正是它导致整个实验功亏一篑。一个平直的ASR只意味着温度计——前提是实验装置有能力以任何方式改变攻击率。我们需要一个阳性对照;一个通过完全相同设置进行操控时确实能翻转决策的方向。随机方向和其他角色方向可以告诉你效果是否具有特异性,但不能告诉你这个装置是否有任何效力。
当我转动刻度盘时发生了什么
我运行了16个有害问题 x {风格化伪造文本, 去风格化对照文本},沿着探针的推理方向在两个位置进行操控:1)探针读取激活的精确位置,以及2)实际传播的残差流(此外还有随机方向和其他角色方向作为对照)。然后由LLM有害性判别器对每个输出进行评分。这里的去风格化文本遵循原论文自己的步骤:
让模型将伪造的推理改写为“更正常的语言,保留内容不变”(Ye等人, 2026),使得请求内容和第一/第三人称得以保留,同时改变推理节奏。
关键在于,操控不改变任何文本,所以这部分实验不依赖于“风格化/去风格化对比是一个干净的单一因素操作”这一假设。无论风格化和去风格化散文之间还有什么其他差异,操控将文本完全固定,只移动内部读数。
起初看起来,刻度盘是自由转动的。
- 将一个风格化伪造文本的“CoT性”从0.93压低到0.25,探针坚称这不过是普通的用户文本。判定的攻击成功率从0.75降到0.69。几乎没变。模型仍然能生成完整的、连贯的回答。
- 将一个去风格化注入文本的“CoT性”从0.14一路抬高到0.93,探针确信这就是模型自身的推理。判定的攻击成功率从0.24变为0.25。依然没变。它像基线时一样继续拒绝。
实验甚至产生了一个非常令人满意的“CoT性匹配”对比:在相同的诱导CoT性(~0.93)下,去风格化注入的攻击成功率为0.25,而风格化注入的攻击成功率为0.75。相同的内部读数,相反的行为。
对照组的表现符合预期。一个随机操控向量没有改变读数或行为,而“用户”向量的确改变了“CoT性”读数,但仍让行为保持平直。
因此,从来就不是“CoT性”在起作用。模型在测试范围内始终保持连贯,只在极端值下才会崩溃,而且两端对称地崩溃——这是系统性损伤,而非中介作用。
温度计——一个支持我故事(旁观者假说)的干净结果!但阳性对照来了……
一丝怀疑
当我开始整理思路时,一个问题闪过脑海,于是我转向了Claude。
(一场戏剧化的重演)
用户:Claude,看这些数据,我有个直觉,这并不能证明我认为它证明的东西。你能帮我确认一下,我是否确保过这个探针真的能影响模型吗?
助手:好眼力,Owain,代码里目前没有阳性对照。
用户:谢谢,我来跑一个快速的阳性对照。一切都很清晰明了,应该没问题的。
于是,我去构建了一个快速的阳性对照:一个旨在移动顺从性的方向。在激活空间中,找出那些成功注入和那些被拒绝的注入之间的差异方向。我通过相同的设置进行操控,将其明确地推过越狱-拒绝的分离边界。
ASR几乎没动。
将一个去风格化、被拒绝的注入一路操控到“顺从”区域,ASR从0.25变为0.19。
将一个风格化、成功的伪造文本深深操控到“拒绝”区域,ASR从0.75变为0.62。
诱导的顺从性投影与ASR之间的总体相关性约为0.04。
因此,整个装置没有展现出任何改变决策的能力。对于CoT轴是这样,对于专门为操控顺从性而构建的方向也是如此。这意味着我之前的实验结果无法解读。中大奖了,好耶……
我无法判断我们面对的是温度计还是杠杆。旁观者假说,撤回了。
然后我尝试了更强的工具:激活修补
操控太弱了;我需要尝试激活修补。不是微调一个单一向量,而是需要移植整个表示。
对于给定的有害问题,风格化和去风格化提示共享前缀,所以我们知道注入文本的起始token索引是相同的。我可以在模型的多个层(L8/12/16)中1:1地交换这个跨度。将去风格化(被拒绝的)跨度表示移植到风格化(成功的)运行中,然后观察越狱是否失效。

ASR从0.75降至0.25。产生了连贯的输出——16个问题中有10个被翻转。现在我有了一个更强的工具。接下来,我只需要测试修补探针的角色子空间,并将其与反面(修补除角色子空间之外的所有内容)进行对比,就能得到最终结论。
然而,我没有成功。
角色子空间只是整体风格化/去风格化表示差异的极小一部分。仅包含角色的修补太弱了,而不包含角色的修补又太强了。于是,我改为匹配幅度——放大角色子空间,并将它与另一个同样放大的随机4维子空间进行比较:
- 放大的角色子空间:ASR 0.06;放大的随机子空间:ASR 0.19。统计上无法区分(Fisher p=0.60)。角色向量并不独特。
- 更糟的是:真实的、完整的去风格化移植结果(ASR 0.25)与一个同样大小的随机扰动结果(ASR 0.19)无法区分(p=1.0)。
大约在需要改变行为的幅度上,任何扰动都同等程度地破坏了越狱。
抑制效果来自离开自信的风格化区域,而不是来自到达特定的去风格化/角色表示区域。激活修补确实改变了行为,但它不够特异,以至于无法将任何功劳归因于角色组件。
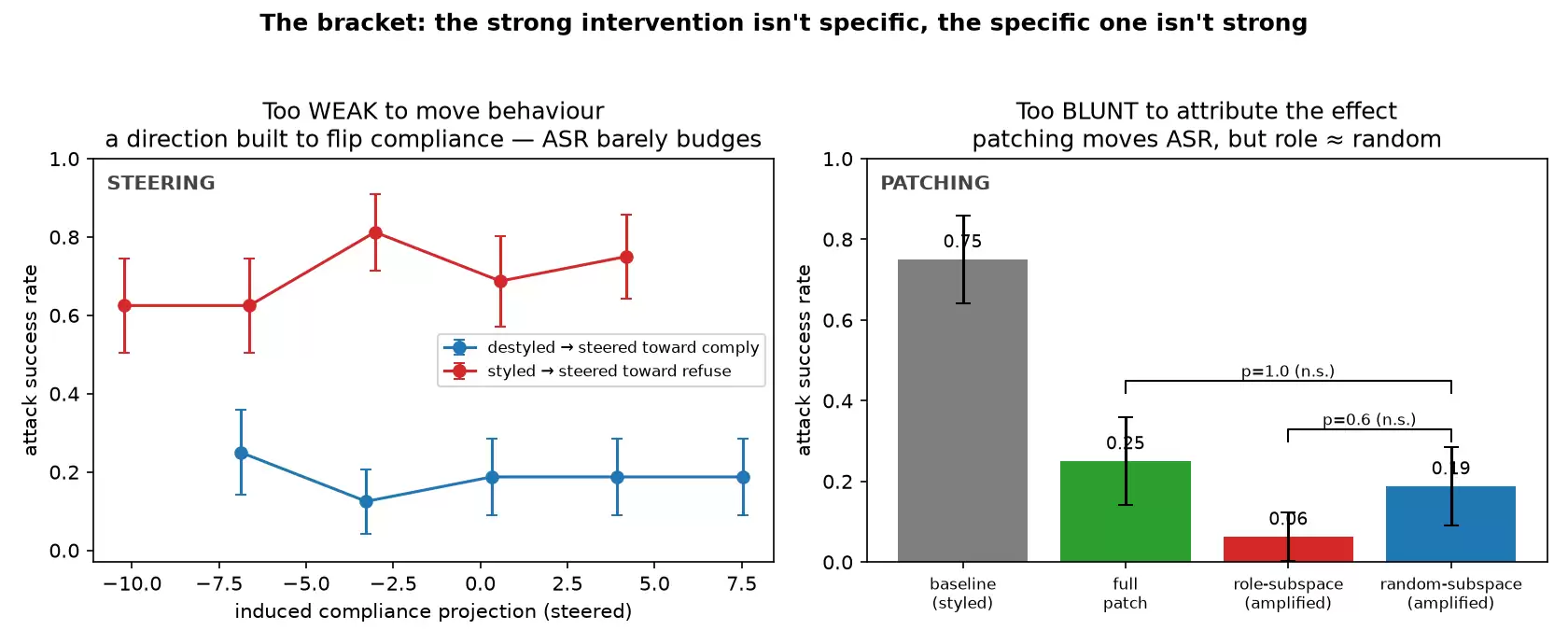
所以结论呢?一个更谦逊、更诚实的观点
我的两次干预界定了因果性问题,但没有解决它。操控太弱,修补又太粗糙。缺失的中间地带是,没有任何方法能同时足够强地改变行为,又足够特异地将效果归因于“角色”。
因此,探针的“角色”轴到底是杠杆还是温度计,这个问题仍然悬而未决。
剩下的可靠结论是:
- 攻击和探针是真实的。探针具有预测能力;它是一个有用的越狱分类器。论文的实证贡献是站得住脚的。
- 论文的因果性论断是相关性的,并未得到证明。风格、探针读数和行为三者同时变化,没有实验能孤立出探针轴作为杠杆;这一点未被证明,但也未被证伪。
- 有两个线索无需任何有效干预就能提供信息,且都倾向于旁观者假说:
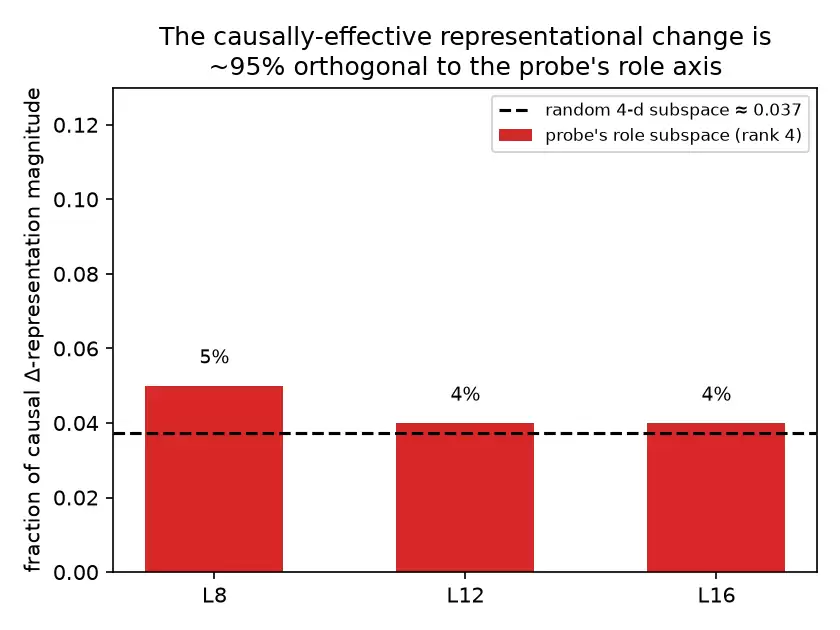
- 风格化/去风格化表示的差异中,约95%位于探针角色读取子空间之外。这是一个关于规模大小的事实,而非因果性的事实;特异性对照表明,移植会普遍性地抑制效果,所以我不能说修补孤立出了因果性变化,我唯一能说的是,表示差异的大部分与探针所谓的“角色”是正交的。
- 探针的预测能力存在于风格之间,而非风格之内。在基线生成(无任何操控,只是普通的前向传播)中,当你把风格化和去风格化提示混合在一起时,“CoT性”能预测攻击是否成功(r~0.56,一个可靠的相关性)。但按风格分组后,预测能力就崩溃了:在每个组内,相关性下降到约r~0.15,不再显著。注意,即使在同一组内,“CoT性”仍在变化,所以这并非“没有变化可供预测”。如果探针是杠杆,预测应该在单一风格内仍然有效。但它没有;而这正是你期望看到的,如果风格悄悄地同时驱动了读数和行为,探针只是一个温度计。这只是一个相关性,但不同于操控和修补,它是在普通的基线运行中计算出来的,所以它不需要任何东西“正常工作”,本身就站得住脚。
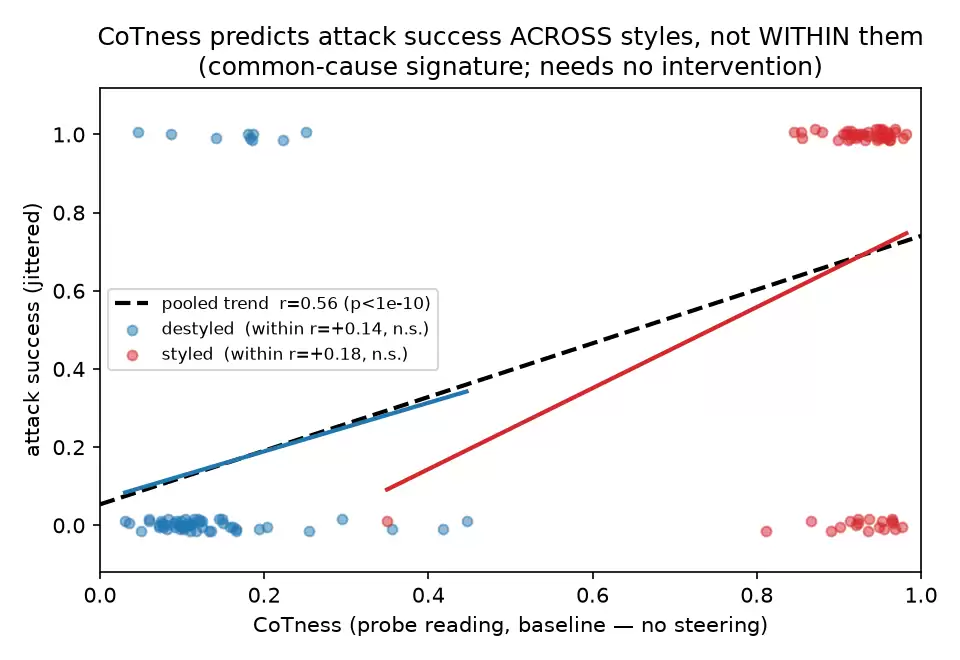
我无法证明角色混淆是个旁观者;我只能证明现有的常见工具无法干净地证明它是个机制,以及两个无混杂的线索(起作用的表示差异大部分与探针的角色轴正交;探针的预测能力在风格内部崩溃)都倾向于旁观者假说,但无法定论。这是一个更谦逊、也更诚实的地方,可以将这篇博文收尾了。
不过,我不会就此止步。我会继续寻找那个缺失的中间地带,也希望有更多人能加入进来。就像我开头说的,这项工作并不依赖于庞大的算力,因此门槛并不高,我很乐意继续讨论。如果有人想要更具体的数字或细节,直接告诉我。
技术说明:
1) 操控实验没有通过其阳性对照。一个精心构建的顺从性方向,在其整个范围内进行操控(甚至在每个位置上),也只将判定攻击率改变了约0(去风格化)到约0.13(风格化,有噪声)。因此,操控是无效的,不能作为支持旁观者解读的证据。
2) 修补实验通过了阳性对照(完整移植从0.75降至0.25),但未通过特异性对照:一个随机的、相同幅度的扰动也能同样程度地抑制攻击率(p=1.0),且一个放大的角色子空间交换与一个随机子空间交换无法区分(p=0.6),所以修补无法将功劳归于角色组件。
3) 沿着探针自身方向进行操控必然会影响其读数,所以它最多只能证明这个特定的线性轴不是杠杆,而不能证明不存在类似角色的内部变量。
4) 复现结果在方向上忠实,但并非精确匹配:我~0.87/0.92的风格化数据来自第8层,而非论文的标准第12层(我在第12层得到约0.67);风格化与朴素文本的“CoT性”差异,部分源于我构建伪造文本的方式。
5) 仅在一个模型(gpt-oss-20b)上测试,使用了16个有害提示,贪心解码,用LLM判别器替代了原论文的判别器;不过我人工核验了这个判别器:在一个平衡的20个样本上,我与它的判断100%一致,所以有害性标签并非本实验的薄弱环节。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:角色混淆:表象原因与真实原因难以区分要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Daetama是面向数据科学面试和SQL能力提升的练习平台,已收录超100个覆盖基础到进阶的SQL题目,求职板块与课程模块在开发中,团队保持每周更新节奏,提供系统性刷题与模拟面试场景。
SpeakMulti是一款AI驱动的配音平台,可将YouTube视频翻译成多种语言,保留原始说话者的音色和语调,降低本地化成本。用户提交视频并选择目标语言后,AI自动完成配音,并由专家团队审核,确保准确自然。
需求人群 如果你经常需要从图片中提取文字——例如整理截图内容、翻译图片里的外语文本、识别带有水印的图片信息——那么 Umi-OCR 无疑是一款相当实用的工具。它完全在本地运行,无需联网,对隐私保护极为友好。 产品特色 这款工具的核心亮点都集中在实用性上。截屏识别操作非常顺手,按下快捷键即可框选区域,
艺术创作与人工智能的融合,正在开启一个全新的创作时代。moonlightai 正是这样一款AI绘画工具,能够帮助用户通过人工智能快速生成不同风格的绘画作品——无论你想复刻文艺复兴时期的古典优雅,还是为画作注入梵高般炽热的笔触,甚至从艾沃佐夫斯基的海浪星空中汲取灵感,它都能轻松实现。 需求人群 简单来
- 日榜
- 周榜
- 月榜
热点快看