




神经网络幂律定律与稀疏表示归纳偏置机制

这篇内容源自 Iliad Fellowship 项目,由 Dmitry Vaintrob 指导完成。 太长不看版: 幂律(即“重尾”)分布与正态分布类似,背后同样存在某种“通用性定理”作为支撑。在机器学习领域,诸多现象都遵循幂律分布,其中权重矩阵的谱分布最为稳健、也最值得深入探讨。本文的核心观点是:
这篇内容源自 Iliad Fellowship 项目,由 Dmitry Vaintrob 指导完成。
太长不看版: 幂律(即“重尾”)分布与正态分布类似,背后同样存在某种“通用性定理”作为支撑。在机器学习领域,诸多现象都遵循幂律分布,其中权重矩阵的谱分布最为稳健、也最值得深入探讨。本文的核心观点是:幂律可视为“稀疏性”概念的自然延伸,通过调节名为“尾指数”的参数,它能够在真正的稀疏与高斯式的稠密之间自由切换。最后,文章将探讨这一观察与神经网络所习得的“稀疏 / 离散 / 因子化”表示之间可能存在的关联。
事先声明:这并非一篇圣塔菲学派式的布道文(鼓吹幂律或“黑天鹅”),风格截然不同。
目录
- 1. 广义中心极限定理:幂律分布的“通用性”根源
- 2. 神经网络中的幂律现象——或许是理解表征学习的一把钥匙
- 2.A. HTSR:权重矩阵谱的相变,以及不依赖数据预测泛化
- 2.B. BBP 相变:学习的“量子”
- 2.C. HTSR:BBP 相变的延伸
- 2.D. 训练中的重尾证据:优劣参半,我无法确定它们是否真正重要
- 3. 尾指数 α:稀疏性与可压缩性的平滑指标
- 3.A. α 如何刻画重尾数据的可压缩性
- 3.B. α-稳定噪声如何使离散码本成为最优解
- 3.C. 重尾噪声:将模拟信号转化为离散码本的一种机制
- 4. 总结
- 5. 参考文献与推荐阅读
1. 广义中心极限定理:幂律分布的“通用性”根源
正态分布之所以至关重要,核心在于“中心极限定理”。简单来说,如果某个现象是大量微小独立效应的叠加,那么最终将呈现一条钟形曲线。身高便是一个典型例子:许多基因各贡献微小效应,因此在人群中身高分布近似正态,因为每个人相当于从身高等位基因中进行了无数次近乎独立的随机抽样。
然而,这里存在一个陷阱。
通常形式的“中心极限定理”要求随机变量的方差有限,否则该定理不成立。若方差无穷大,则需要引入“广义中心极限定理”,此时得到的是所谓 Lévy α-稳定分布。如果底层现象是 α-稳定的,那么将它们叠加,经过适当缩放后结果仍是 α-稳定的。正态分布只是 α=2 的一个特例,而 α 的取值范围实际上是从 0 到 2。
中心极限定理要求方差有限:对独立同分布的 Xᵢ,均值为 μ,方差为 σ²,那么 (1/√n) Σ (Xᵢ - μ) 在分布上收敛于正态分布 N(0, σ²)。
但对于那些方差无界(甚至均值也不存在)的随机变量,存在一个更广泛的版本。这些更一般的分布被称为稳定分布,非高斯的部分带有尾指数为 α 的幂律尾巴:大致而言,密度函数的尾部 ~ C / x^(α+1)。
封闭性与广义中心极限定理(简而言之):稳定分布的含义是,独立同分布样本的和仍然属于同一家族,即 X₁ + X₂ ~ 2^(1/α) X(在对称、单位尺度的情况下)。高斯是 α=2,因此对零均值的高斯变量求和,直接累加方差即可。
广义中心极限定理:对具有幂律尾巴(P(X > x) ~ x^(-α),0 < α < 2)的随机变量求和,只要均值存在就对数据进行中心化,并用 n^(1/α) 而不是 √n 进行归一化,最终收敛于 α-稳定分布 Sα。尾指数变为稳定性指数。常见例子:α=2 为高斯,α=1 为柯西,α=1/2 为“那个”Lévy 分布(尽管整个 α-稳定家族常被称为 Lévy 分布)。注意,Sα 的实际分布函数通常很难显式写出,因此在幂律世界里一切操作都依赖特征函数。在对称、中心化的情况下,Sα 的特征函数为 exp(-γ^α |t|^α),其中 γ 是尺度参数。
帕累托分布与 α-稳定分布并不等同,但它作为理解尾指数的最干净玩具模型。帕累托法则——“80% 的结果由 20% 的原因导致”——实际上对应于帕累托尾巴中 α≈1.16 这一精确数值。指数 α 控制着“罕见事件在均值中占多大比重”,当 α→1 时,几乎全部质量都由有限次极端抽取承担。
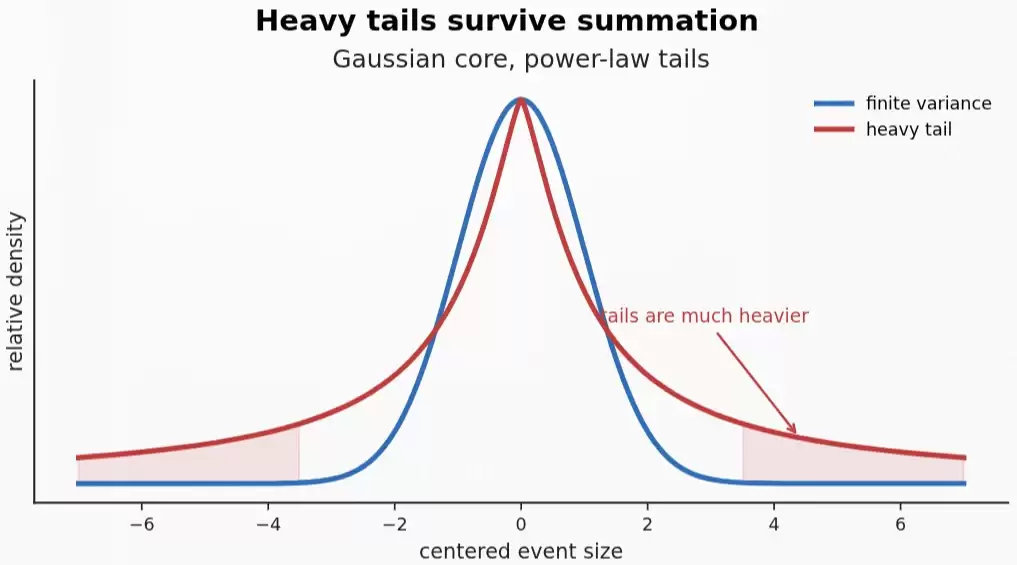

图:在相同空间尺度下模拟的布朗运动(左)和重尾 Lévy 运动(右)路径对比。布朗路径由大量幅度相近的步长组成,而 Lévy 路径则被少数大跳跃主导。图片来自维基百科。
2. 神经网络中的幂律现象——或许是理解表征学习的一把钥匙
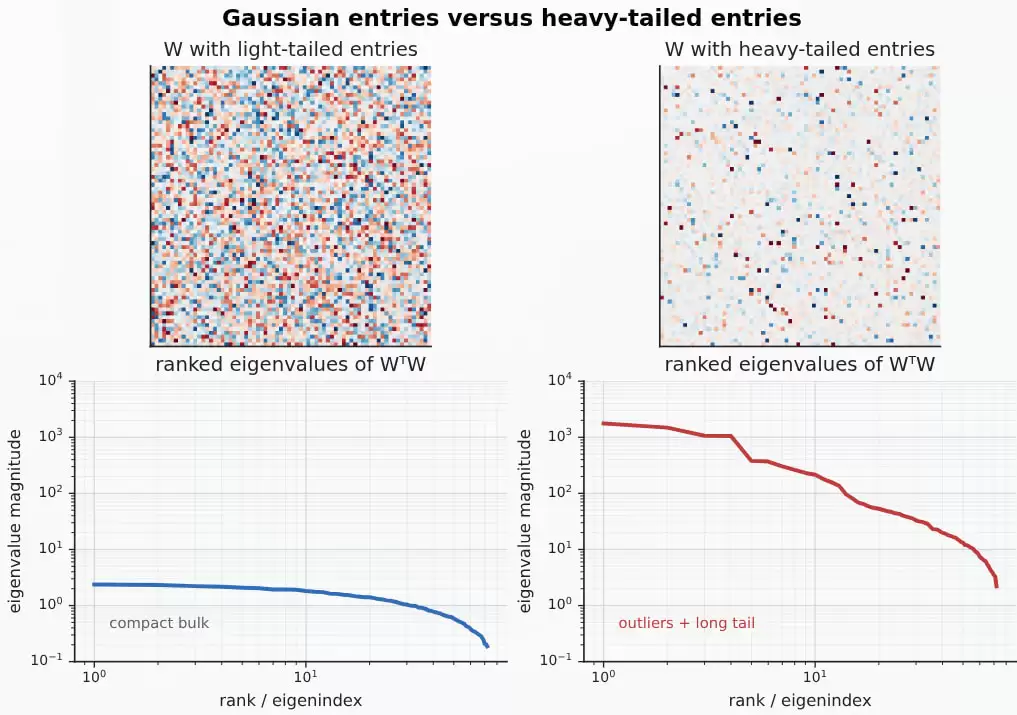 图:高斯分布元素矩阵与重尾分布元素矩阵的对比。WᵀW 的谱是诊断的关键:它记录了权重空间中各个方向的强度与分布情况。
图:高斯分布元素矩阵与重尾分布元素矩阵的对比。WᵀW 的谱是诊断的关键:它记录了权重空间中各个方向的强度与分布情况。
2.A. HTSR:权重矩阵谱的相变,以及不依赖数据预测泛化
这里的主要机器学习动机是“重尾自正则化”(HTSR)及其相关的 WeightWatcher 分析。Mahoney 有一个看起来非常酷的演示(可能更偏教学性)。他们的核心论点是:神经网络中的权重矩阵在训练过程中通常经历几个谱层面的阶段:
- 初始谱接近随机高斯矩阵的 Marchenko-Pastur bulk(大块连续谱)。
- 第一个学习到的信号以 BBP 式的尖峰形式从该 bulk 中分离出来。
- 最终,累积了足够多的信号方向,谱看起来不再像“bulk 加几个尖峰”,而更像一个重尾谱。
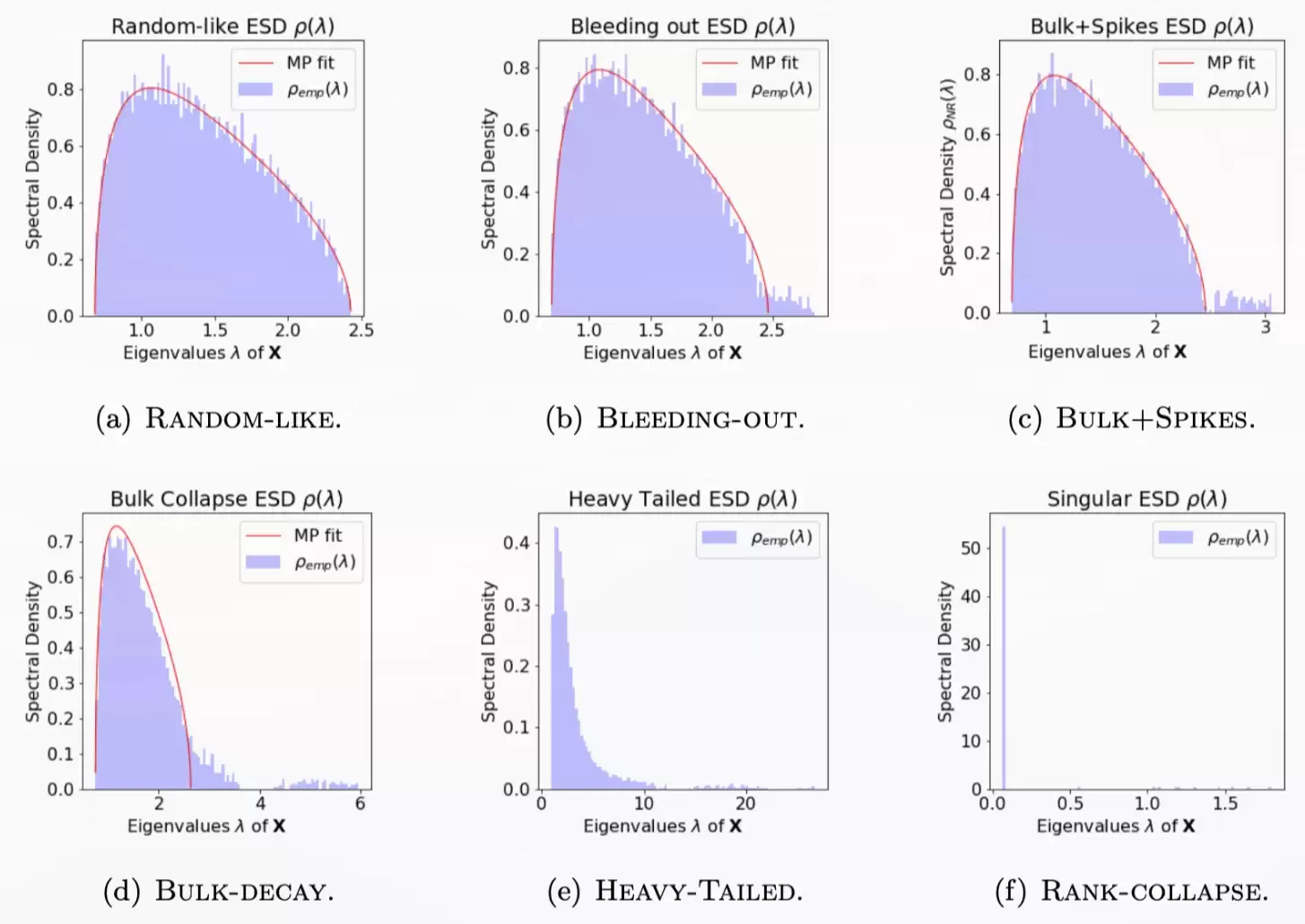
图:HTSR 故事的一个简化版本:初始看似随机的谱逐渐发育出分离的信号方向,然后演变成一个广阔的重尾谱。图片出处同上。
Martin、Peng 和 Mahoney 的工作表明,仅凭谱的尾指数就能预测模型泛化性能的趋势,并且完全不需要访问训练数据或测试数据。正是这一观察引起了我的兴趣。值得强调的是,这是一种更像“水星近日点进动”式的理论建构——他们的测量并不能最终证明这个过渡在神经网络中每个地方都清晰一致地发生。我认为他们的测量很有启发性,但在理论上更多是受直觉引导。
图片出处同上。
为了更清晰地说明机制,我先快速总结一下 BBP 相变的概念(本身也值得了解),他们的理论正是建立在此之上。
2.B. BBP 相变:学习的“量子”
BBP 相变是在随机协方差矩阵中寻找低秩信号时出现的相变。可以通过不同模型来阐述,这里我们考虑神经网络的权重矩阵,具体看其 Gram 矩阵 WᵀW。当信号强度超过某个阈值时,信号会以一个分离的尖峰特征值形式“蹦”出来。用公式表示:
WᵀW = β u uᵀ + MᵀM
这里 M 是一个元素独立同分布的高斯随机矩阵,β u uᵀ 是一个强度为 β 的秩 1 信号。直观地说,只有当信号强度 β 高于一个阈值 β_crit 时,你才能“看见”它。
这本身作为一个学习诊断器就值得了解。BBP 有点像“经典”或“线性”学习阶段:很容易判断模型是否学到了某件事 X,以及知识 X“在”哪里(就在对应的特征向量中)。甚至可以将线性回归的正则化项视为尖峰(信号)与噪声的分界线。如果存在一个清晰的间隙,那就再好不过了。
但是,如果你想学太多的东西,导致出现了太多“尖峰”(rank(M) ~ n 就是 BBP 的舒适区),这个相变的概念就不那么清晰了。
2.C. HTSR:BBP 相变的延伸
HTSR 讨论的就是当所有东西都变成“尖峰”时会发生什么。他们通过实证,对每层谱的尾部用尾指数 α 进行拟合,并证明一个聚合后的 α 可以预测泛化,而无需访问留出数据。
为什么这能行?它有效又意味着什么?
有两种有用的思路。一种看法是,这不过是信号传播的一种度量:光谱范数本身已经是一个不错的泛化预测指标,幂律拟合可能只是因为它多了一个可拟合的参数,所以拟合效果更好。
另一种则是理论层面的看法:我们知道 BBP 尖峰在本体论上是稳健的,并且“有意义”,而幂律谱看起来很像“所有东西都变成了 BBP 尖峰”的极限情况。我们正处于一个 BBP 不再能清晰适用的区间,但绝对离高斯世界很远。
更进一步,从信息论的角度看,幂律分布是稀疏性在更嘈杂环境下的自然推广:尾巴越轻,稀疏性就越温和;而在尾重无限大的极限情况下,我们又回到了传统的“非零元素计数”的稀疏概念。如果你接受这个观点,事情就好理解了——我们都喜欢稀疏性!这差不多就是“简单性”。因此,幂律谱很可能就是神经网络实现奥卡姆剃刀原则的机制性标志。这可能提供一种方法,来衡量一个神经网络是更倾向于“记忆”还是“泛化”,并可能为神经网络中的“知识”描绘出新的本体论。
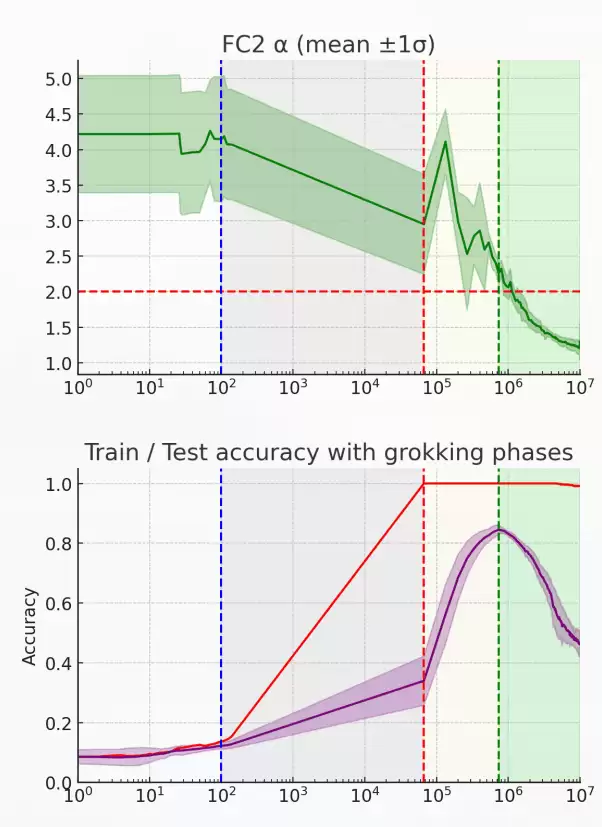
机械可解释性研究者可能也会对此感兴趣:一篇关于“反-grokking”的论文也表明,拟合出的 α 可以作为一个诊断指标:反-grokking 对应着平均 HTSR 层级质量指标 α 偏离 2,在他们实验中,α ≈ 2.5 被视为一个警告信号。
图片出处同上。
2.D. 训练中的重尾证据:优劣参半,我无法确定它们是否真正重要
许多关于激活值、梯度大小或批次噪声的重尾说法,现在看来都像是次要现象。《Outlier Features》那篇论文表明,其中一些现象可以通过架构调整来缓解;《Attention Sinks》则暗示,某些看似重尾的行为其实只是相对简单的信号伪影。
我仍然相信权重 SVD 谱在结构上是重要的。数据 Gram 谱的故事有 Ruderman 的自然图像统计以及 Maloney、Roberts & Sully 的可解神经缩放模型支持,但这些都不过是“幂律入,幂律出”——虽然正确,但缺少我想要的深层结构联系。不同来源的幂律谱可能导致对神经网络完全不同的心智模型。
LessWrong 上那篇《Basic facts about language models during training》是很有用的实证参考。下面这张来自他们的图表可以作为一个例子:
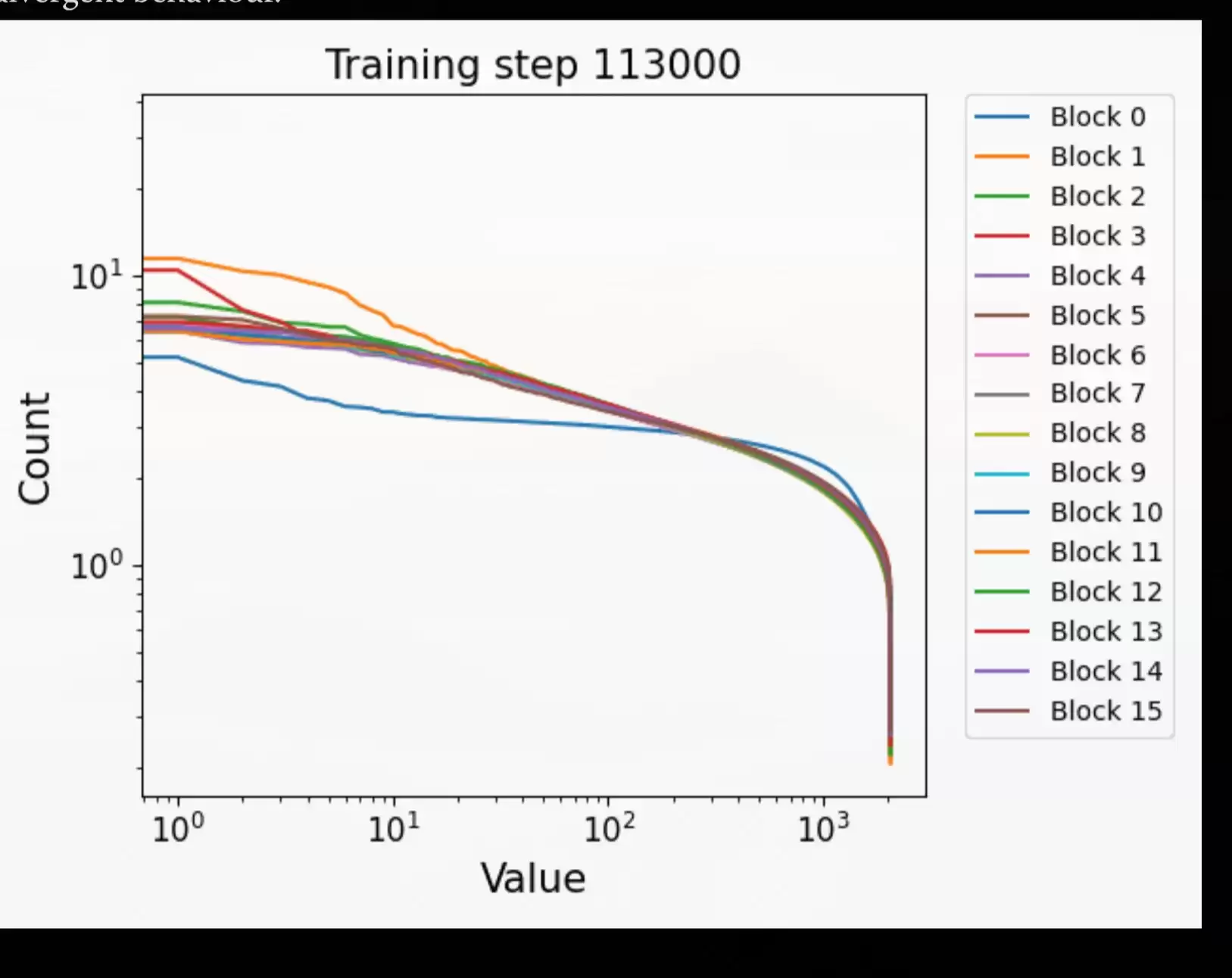
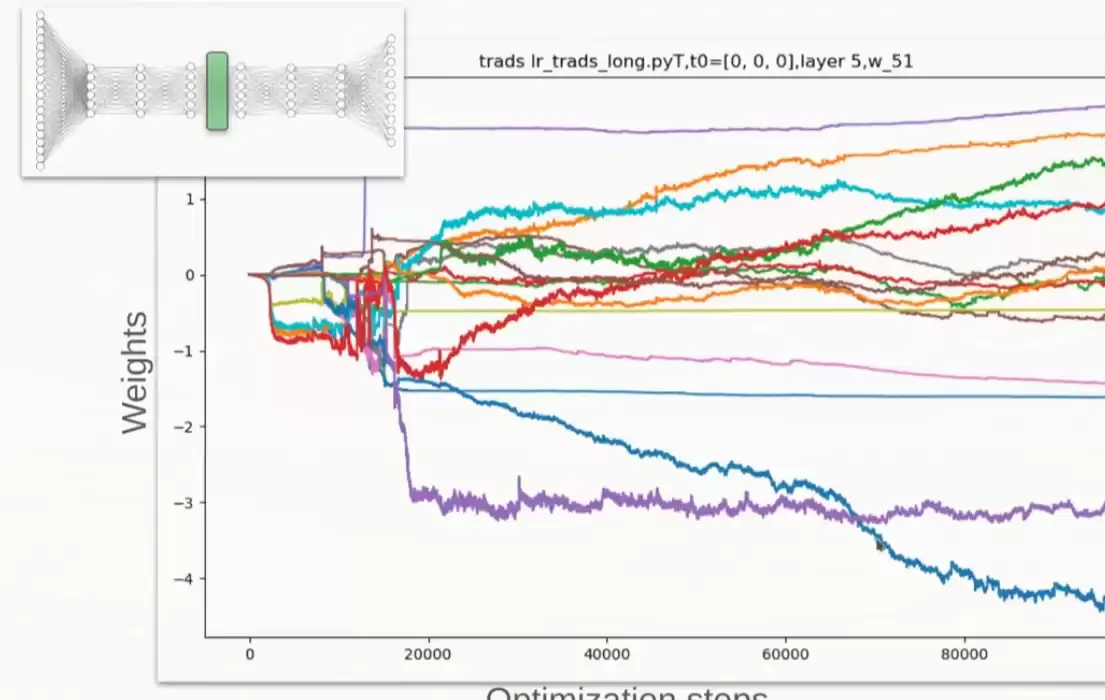
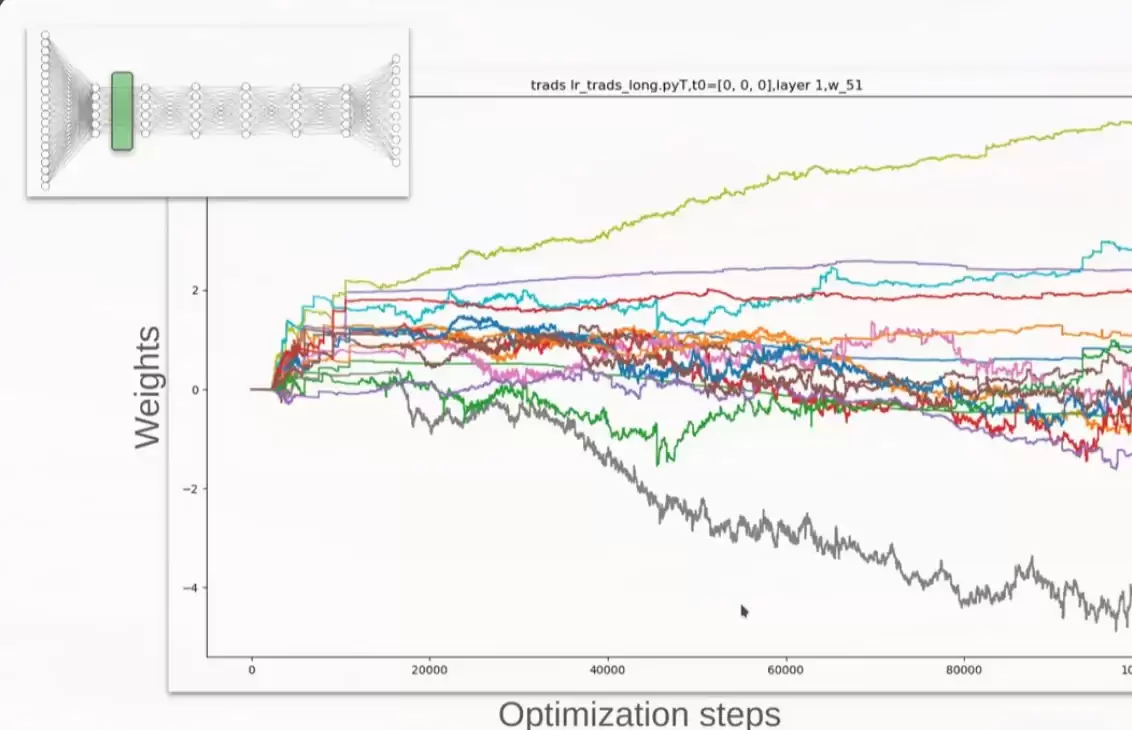
Wesley Erickson 的讲座《Hea vy-tailed Noise & Stochastic Gradient Descent》也相当不错,正是它启发了我往这个方向思考。讲座里也很好地讨论了关于重尾噪声的争论。下面两张截图可以感受一下(为了不拍到演讲者的脸,裁剪得有点奇怪)。
3. 尾指数 α:稀疏性与可压缩性的平滑指标
(3.A 和 3.B 小节(不含 3.C)主要由 LLM 根据要点生成。)
3.A. α 如何刻画重尾数据的可压缩性
大自然并不信仰绝对的“零”(更准确地说,不相信浮点数的绝对相等)——我们所有的度量都必须是平滑的。那么,不依赖某个值恰好为零的“稀疏性”的“平滑”版本是什么?显然,小的偏差应该比大的东西更不重要。而且这种关系应该是相对的:一个在元素大多为 0.001~0.005 的矩阵中的“2.35”,与一个在元素大多为 1.000~2.000 的矩阵中的“2.35”,意义完全不同。
假设你有一个按大小排列的列表 |a_i|,长度为 n。先不考虑复杂的编码:稀疏性的操作性定义就是“每多表示一个模式,能减少多少误差?”如果从大到小排列的这些幅度服从幂律分布,那么:
||a||² - ||a_top_k||² ~ C · k^(-(α-1)) (k ≫ 1, α > 1)
这里的 ||a - a_top_k||² 就是保留前 k 个模式后剩下的 L2 误差。这是核心结论:当 α > 1 时,最佳 k 项近似的误差随 k 幂律衰减。
对于平方误差,α=1 是临界点,所以 α=2 也是高斯 / 可压缩性的阈值。这和广义中心极限定理里的方差有限边界是同一个阈值。若 α < 2,一小部分固定的顶级模式就能捕获平方质量的一个非零比例,并且随着 n 增长,任何固定比例的顶级模式都能捕获越来越大的比例。若 α > 2,分布就是稠密的,或者说在 L2 意义上是“边际的”。
随着尾巴越来越重(α → 1),只保留少数几个模式后的误差几乎为零。在这个极限下,我们又回到了传统的稀疏定义:只有 O(1) 个条目真正重要。所以,α 在 0 到 2 之间的数据,正好在真正的稀疏和最低限度的可压缩性之间光滑地插值。
3.B. α-稳定噪声如何使离散码本成为最优解
其机制如下:高斯信道(α=2,功率约束 E[X²] ≤ P)的最优输入是连续型的(一半艾略特,一半施诺—总之是连续高斯)。但在 α-稳定噪声下(α < 2),方差是无穷大的,因此普通的功率不再是信号强度的天然度量。Fahs 和 Abou-Faycal 研究了在分数阶矩输入约束(如 E[|X|^p] < ∞, p < α)下的 α-稳定加性噪声信道。他们关于支撑集 / 离散性的更广泛结果表明,适当的超对数成本约束可以迫使容量达到的输入分布成为有界、离散的。链条是这样的:重尾信道噪声 → 改变了输入成本几何 → 离散字符集可能变成最优解。
3.C. 重尾噪声:将模拟信号转化为离散码本的一种机制
(注:我觉得这仍是一个有趣且看似合理的想法,但我只押 30% 的概率认为它确实有实用价值。我现在还在积极思考这个问题。)
在一个有高斯噪声且受总功率约束的信道中,发送模拟数据是最优的。但在重尾噪声和适当的输入成本约束下,最优解决方案反而可能变成一个离散码本。试想,如果 Lévy 类噪声在机器学习中相当普遍,那么……嗯……残差流就是一个带有 Lévy 类噪声的信道,沿着它进行通信可能更偏好离散码本。这提供了一种预测 SAE 特征的机制——不仅如此,我们或许还能用这个模型预测它在什么时候会失效。
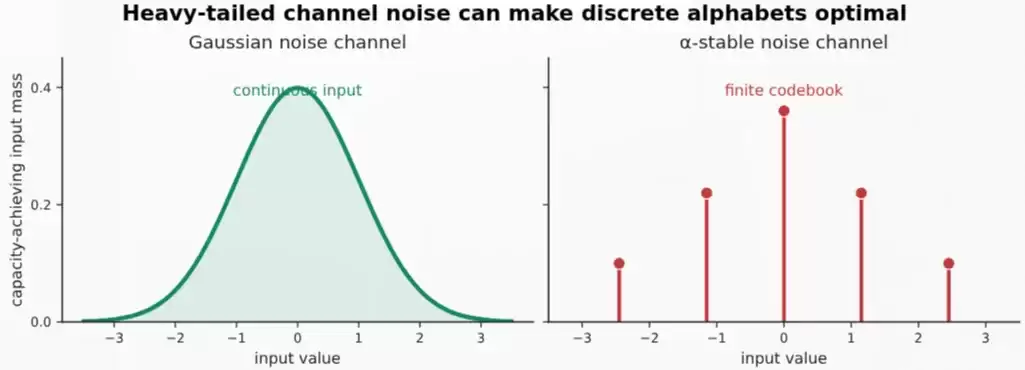 图:在高斯信道中,达到容量的输入是连续的。而在 α-稳定噪声信道和合适的输入成本约束下,达到容量的输入可能变成一个有限的离散码本。
图:在高斯信道中,达到容量的输入是连续的。而在 α-稳定噪声信道和合适的输入成本约束下,达到容量的输入可能变成一个有限的离散码本。
如果这是真的,那意义可就大了(不带讽刺意味):它为“学习系统倾向于离散表示”这一现象提供了通用机制。这个思路足够普遍,甚至可能适用于大脑。
为什么?可以从两个角度来理解。第一,从机制上看:按照这个解释,Lévy 类噪声是在某些情况下让离散码本成为最优的机制。它是我们期望出现离散表示的部分原因。而且,如果能把这种机制研究得更透彻,我们或许就能根据噪声特征信号直接提取出那些表示(就像通过翻转编码比特观察解码结果的变化,来推断对方用的校验码一样)。
第二,从普适性上看:每个人对“人脑和 LLM 的学习方式有多相似”有不同的先验。Lévy 类噪声提供了一个基础,用来构建一个从共同机制出发的叙事:一个对离散表示的先验偏好,可以通过一个在内部优化重尾噪声下通信的学习算法来编码。大致来说,一个学习算法只要恰好属于某个普遍存在重尾噪声的通用性类别,就自然会促进离散码本。这并不难!至少有一些关于重尾突触权重分布和混沌边缘动力学的、与神经科学相关的研究可以佐证,但每次我追问 Claude 这个问题,它都会列出一大堆来回交锋的智力论战,关于如何解读这些数据。所以,要小心。
不管怎样,从康德哲学的角度看,这个观点令人愉悦:那个看似内在于现实的“稀疏”结构,被揭示为不过是智能本身的一种性质。我们不再需要把离散性或稀疏性当作某种奇迹般的属性,强加在那个我们只能通过感知去接触的“自在之物”宇宙上。相反,我们可以将这种结构归因于这样一个事实:在足够广泛的条件下,“离散”的学习者比高斯学习者更高效。不必诉诸无法回答的 Solomonoff 先验,也不必引入“简单性偏差”(为什么宇宙必须是简单的?“简单”到底是什么意思?相信任何根本的简单性都应该归因于感知者,不是更容易理解吗?)。
有两个相关的想法,虽然不完全符合主线论证,但也值得放在桌上讨论:
- 残差流上的 SAE 特征对应着格码(可以参考 MITOCW 的讲义)。
- 元素服从重尾分布的随机矩阵,与稀疏随机图是同构的,而稀疏图也常用于编码理论。这是重尾与稀疏性之间的另一个连接点,与 Lévy 噪声的路径不同。
4. 总结
幂律(“重尾”)分布与正态分布一样,背后有通用性定理作为支撑。我们在机器学习中观察到很多事物都服从幂律分布,其中最稳健、也最值得关注的是权重矩阵的谱。这里试图论证的是,幂律是“稀疏性”概念的一种自然泛化:通过改变尾指数 α,它能在真正的稀疏性和高斯式的稠密性之间连续插值。这为连接谱结构、可压缩性,以及神经网络似乎能学到的因子化或离散表示,提供了一座可能的桥梁。
在撰写本文的过程中,我思考了很多关于 BBP 相变(学习的量子)和元素独立同分布 Lévy 型的随机矩阵。重尾随机矩阵有很多性质,可以作为机械化地定义诸如“特征”(局域化特征向量、迁移率边、与稀疏图编码的联系)等概念的跳板。但重尾随机矩阵与 Beren 等人发现的轻尾权重矩阵元素是严重矛盾的。我试图拯救 Lévy 元素的故事:由于 Lévy 噪声不是各向同性的,而且其特征基又是明显稀疏的,所以必须提出一个不同于神经元基的新特权基。我试探过 ICA,但说实话,神经元基无疑是特权基,尝试任何其他东西都感觉像是在作弊。
轻尾元素加上幂律谱,在本质上意味着存在大量微小的相关性。一些关于视网膜神经节细胞的实验表明,基于一阶和二阶统计量的最大熵 / Ising 模型可以恢复大量集体结构,相关的研究还认为拟合后的模型可能靠近临界点。这提示我们,更好的思路或许是思考大量低阶相互作用,而不是组织有序的高阶相关性。这个问题将在以后的文章中继续讨论:本质上是从启发 SAEs 的“稀疏感知”机制,转向一种以大量有噪声、重叠的测量为特征的“弱感知”机制。我对这个想法非常兴奋,因为它感觉上更像大脑的工作方式。
5. 参考文献与推荐阅读
- 维基百科:稳定分布 · 帕累托原则 · Lévy 飞行 · Lévy 飞行觅食假说
- Ari Brill, Neural Scaling Laws Rooted in the Data Distribution - arXiv 2412.07942 · LessWrong · code
- Beren Millidge, The Scaling Laws Are In Our Stars, Not Ourselves - beren.io
- Martin & Mahoney, Implicit Self-Regularization in DNNs: Evidence from RMT - arXiv 1810.01075 · JMLR
- Martin, Peng & Mahoney, Predicting trends … without access to training or testing data - arXiv 2002.06716 · Nature Communications
- Hea vy-Tailed Universality Predicts Trends in Test Accuracies … - arXiv 1901.08278
- WeightWatcher - github · weightwatcher.ai · 普及文章: KDnuggets pt.1 / pt.2
- Baik, Ben Arous & Péché, Phase transition of the largest eigenvalue for non-null complex sample covariance matrices - arXiv math/0403022
- Fahs & Abou-Faycal, On the capacity of additive white α-stable noise channels - IEEE Xplore (ISIT 2012)
- Fahs & Abou-Faycal, On Properties of the Support of Capacity-Achieving Distributions for Additive Noise Channel Models with Input Cost Constraints - arXiv 1602.00878
- Elhage et al., Toy Models of Superposition - transformer-circuits.pub
- 压缩感知 / weak-ℓp-压缩性: Candès, Donoho (经典文献)
- Bondarenko et al., Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing - arXiv 2306.12929
- Xiao et al., Efficient Streaming Language Models with Attention Sinks - arXiv 2309.17453
- Maloney, Roberts & Sully, A Solvable Model of Neural Scaling Laws - arXiv 2210.16859
- Ruderman, The statistics of natural images, Network: Computation in Neural Systems 5 (1994) 517–548 - DOI 10.1088/0954-898X_5_4_006
- Late-Stage Generalization Collapse in Grokking: Detecting anti-grokking with WeightWatcher - arXiv 2602.02859
- Yoon et al., Edge of chaos and a valanches in neural networks with hea vy-tailed synaptic weight distribution - arXiv 1910.05780
- Schneidman et al., Weak pairwise correlations imply strongly correlated network states in a neural population / Ising models for networks of real neurons - arXiv q-bio/0611072
- Tkačik et al., Searching for collective beha vior in a network of real neurons - arXiv 1306.3061