




企业AI落地关键在数据底座而非大模型

企业级AI的竞争格局正悄然发生转变。过去两年,焦点集中在模型参数、算力规模和API调用量上;但进入2025年,行业逐步形成明确共识:真正的增长瓶颈已从模型层转移至数据底座层。 刚刚观看了OceanBase AI数据库线上发布会,感触颇深。这场发布回应了一个非常实际的问题:当数据库的主要使用者从人变为
企业级AI的竞争格局正悄然发生转变。过去两年,焦点集中在模型参数、算力规模和API调用量上;但进入2025年,行业逐步形成明确共识:真正的增长瓶颈已从模型层转移至数据底座层。
刚刚观看了OceanBase AI数据库线上发布会,感触颇深。这场发布回应了一个非常实际的问题:当数据库的主要使用者从人变为Agent时,企业的数据底座究竟该朝哪个方向演进?
先分享几个核心判断:企业AI向前推进,卡点已逐渐从模型本身转移到数据层面。上下文是否完整、非结构化数据能否纳入治理、搜索结果是否准确、Agent试错是否会对生产环境造成污染——这些问题若无法有效控制,AI应用很难真正落地到核心业务流程。
过去我们讨论数据库,高频词汇往往是高并发、事务、容灾、成本和性能。进入Agent时代,问题维度骤然增加:
- Agent需要理解业务上下文
- Agent需要处理文档、图片、语音、视频等多模态数据
- Agent需要随时调用实时业务数据
- Agent会尝试、会修改数据、可能破坏环境
- Agent数量可能从几十个扩展到数百万乃至上千万个轻应用和小任务
这时,数据库如果仍只是供人类点开后台查表的地方,显然难以胜任。OceanBase此次给出的主方向非常清晰:
OceanBase AI 数据库 = 湖库一体 · 多模态 · AI 原生
一句话总结:OceanBase的目标是为企业Agent打造一套真正能投入生产的数据底座。它对AI数据库的定义,核心浓缩为四个词:一体化、多模态、Agent友好、开放。

为什么企业AI最终会卡在数据上
过去三年,企业AI预算大量投向模型和算力——购买模型、接入API、搭建知识库、部署智能客服、上线Copilot,这些方向异常火热。但真正进入业务流程后,许多项目会遭遇一个尴尬局面:大模型越来越强,业务价值却常常卡在数据环节。
原因很简单:大模型解决的是通用智能问题,企业需要的是业务智能。通用智能会说话、会推理、会生成;但业务智能还需要知道:这个客户是谁、这笔订单进展到哪一步、这份合同是否有风险条款、这个规则当前是否生效、这个用户最近几次交互留下了什么状态、这次操作能否写回生产系统……
这些答案全部藏身于企业数据中。因此OceanBase反复强调一个核心变化:数据库的使用者正从人转变为Agent。
人使用数据库时,多为明确查询:查一条订单、看一张报表、筛一批异常记录。Agent使用数据库时,动作复杂得多:先理解上下文,再混合检索,再调用工具,再写入状态,再根据结果继续下一步,失败后要回滚,成功后要沉淀经验。这便将数据库从后台系统直接推至Agent工作流的核心位置。

OceanBase这次真正想解决的三个问题
第一,企业的数据形态已经改变
过去数据库主要管理结构化数据:表、行、列、字段。现在Agent需要消耗的上下文中,包含合同PDF、客服录音、会议纪要、体检报告、商品图片、行车视频、风控规则、知识库片段、对话记忆、向量、JSON……这些内容如果仍散落在对象存储、文件系统、搜索引擎、向量库、业务库之间,Agent每执行一步都需要跨系统拼接上下文。每拼一次,就多一分延迟;每搬一次,就多一份冗余;每同步一次,就多一个一致性隐患。
第二,企业的数据流动方式也已改变
传统链路通常呈现为:交易库 → ETL → 数仓/数据湖 → 搜索引擎/向量库 → RAG/Agent。这条链路可以运行,但很慢且笨重。Agent产生bad case、用户反馈、执行轨迹后,若需等待数天才能通过离线分析挖出来,再回到线上验证,数据飞轮根本转不起来。OceanBase强调“数据飞轮”概念:Agent产生数据,数据回流优化模型和知识,优化后的能力再服务业务。飞轮转得快,AI才会越用越精准。
第三,Agent会带来新风险
人们修改生产数据前会犹豫,Agent可能直接动手。尤其在企业环境中,Agent将越来越多地执行生产任务——写数据、改流程、调工具、做评测。这时数据库必须为其准备好安全边界:可以试错,但不能污染生产;可以并行,但不能互相干扰;可以失败,但失败后要能快速丢弃、回滚、重来。这也是本次发布最值得关注的地方:它把多模态、混合搜索、数据沙箱、海量逻辑表、开放计算整合进一套架构中统一回应,避免将AI数据库窄化为向量检索。
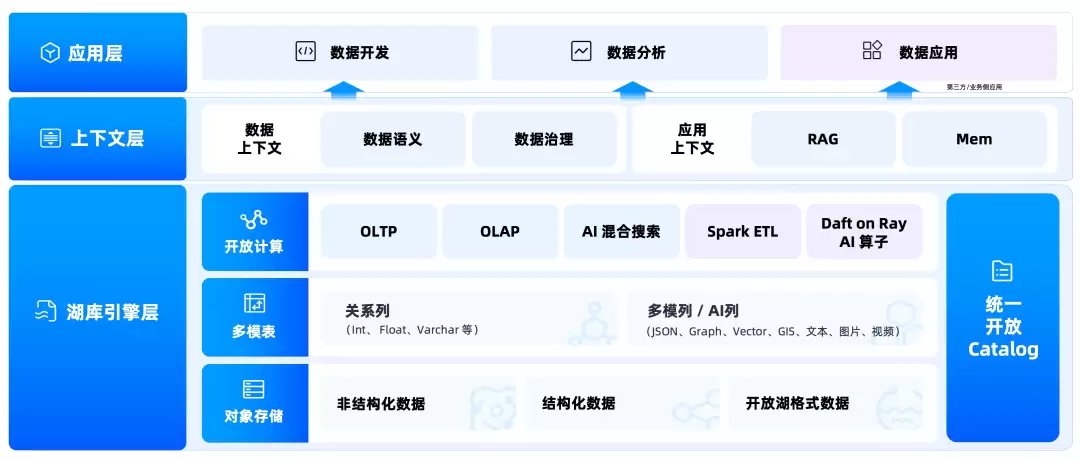
Lakebase:将湖和库放在同一张底座上
OceanBase Lakebase是本次发布中的核心引擎。它面向湖库一体、多模态数据和Agent场景,目标是用一套底座统一管理结构化、半结构化、非结构化数据,同时承载TP、AP和AI工作负载。
这句话听起来有些宏大,但理解起来并不难:企业不希望为了一个AI应用同时维护交易库、数仓、对象存储、搜索引擎、向量库、权限系统、ETL链路、RAG服务等多种组件。Lakebase要做的是将关键数据底座和核心治理能力收敛起来。SQL继续处理在线事务和查询;Spark继续做批量加工;Ray/Daft继续运行AI数据链路;对象存储、S3兼容接口、Iceberg开放表格式继续接入现有生态。
这条路线非常务实。企业的数据平台不会一夜之间重建,真正可行的落地路径通常是先减少系统接缝、减少数据搬运、减少权限割裂,再逐步将高价值场景收敛到统一底座上。
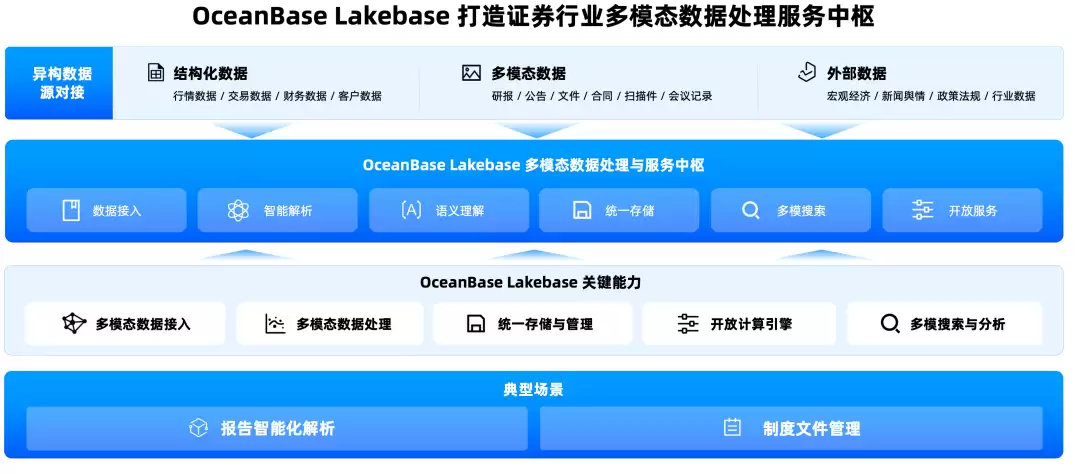
多模态数据管理:让非结构化数据拥有正式身份
本次最令人眼前一亮的设计是多模表和AI列。过去企业中的非结构化数据,多数情况下只是附件——合同PDF放在对象存储,图片视频放在文件系统,文本摘要写入业务库,向量存入向量库,权限单独做一套。业务上明明是同一个对象,技术上却被拆分成多份。Agent要理解它,必须从多个系统将这些碎片拼接回来。
OceanBase的多模表希望解决这个问题。一张表中可同时存放结构化字段、文本、图片、音频、视频、JSON、LOB、向量。例如一张合同表,可以同时包含:
合同编号
合同 PDF
合同正文
关键条款 JSON
摘要向量
风险标签
审批状态
权限信息
用户看到的仍然是一张表,但非结构化数据已进入同一套事务、权限、元数据、版本和生命周期管理。企业AI不缺文件,缺的是能被统一治理、统一检索、统一计算的数据资产。
AI列也很有特点——它相当于让数据库内部长出一条语义加工线。原始数据进入后,可在库内生成摘要、标签、特征、向量等结果。对一张表中的多行数据做embedding或打标,AI列可以保证使用同一套算法,并且要么全部成功,要么全部失败。懂RAG的人应该明白这个细节的分量:向量化任务中途挂了,一半旧向量一半新向量,后续召回质量会变得很不确定。数据库愿意认真处理这种一致性细节,说明它面向的是生产场景,而不只是Demo场景。

混合搜索:别把数据库该干的活全丢给模型
现在做企业RAG,大家越来越清楚一件事:单纯向量检索很容易翻车——语义相似并不代表业务正确。一个生产级Agent查找资料时,往往需要同时满足多种条件:语义接近、关键词命中、结构化条件符合、权限范围正确,以及时间、部门、客户、状态一起参与过滤。
如果将所有候选都丢给大模型让模型自己判断,成本高、速度慢、结果也容易不稳定。更好的分工应该是:数据库先做过滤、索引、权限、一致性和粗排,模型再处理真正高价值的候选。OceanBase对混合搜索的表述很精确:一条SQL组合执行,多路召回与粗排在引擎内统一完成,模型只处理高价值候选。关系过滤、全文搜索、向量搜索、图搜索组合起来,先把全量数据缩小为候选集,再交给模型精排。
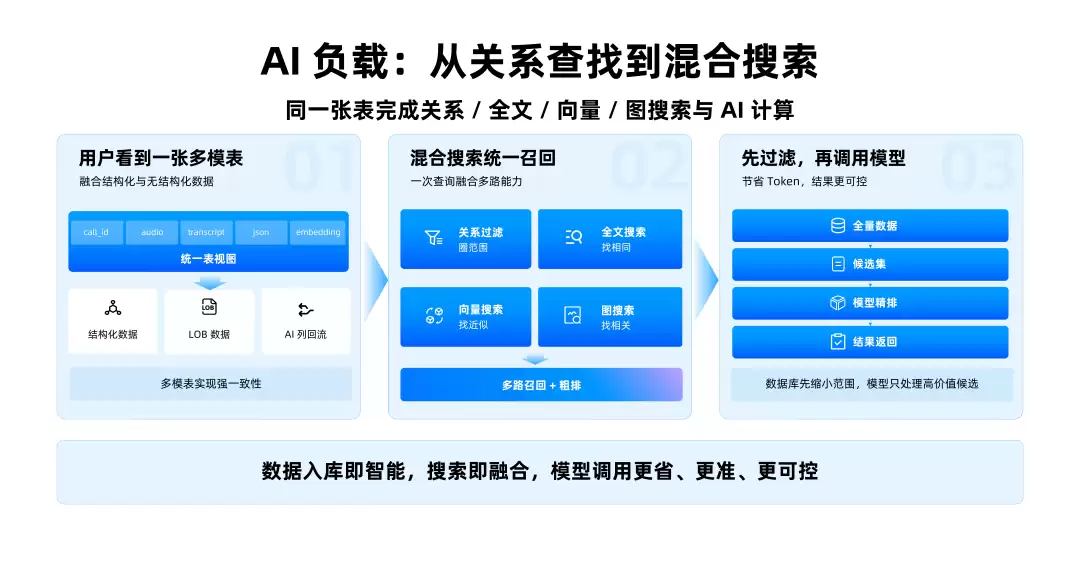
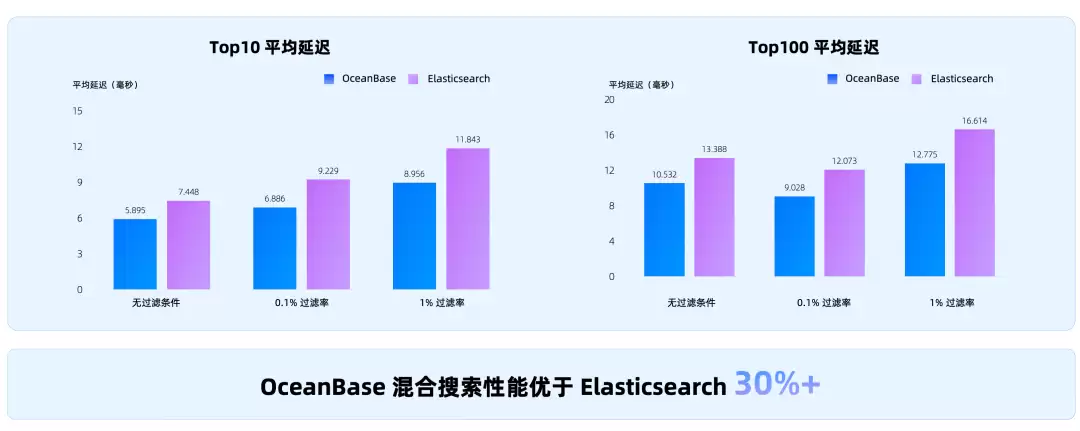
这样做不是为了炫技,而是为了解决企业AI中非常实际的问题:让上下文更准确,让token更节省,让权限更可控。在VectorDB Benchmark上,同等召回率下,OceanBase的向量性能优于Milvus、PGVector、Elasticsearch。
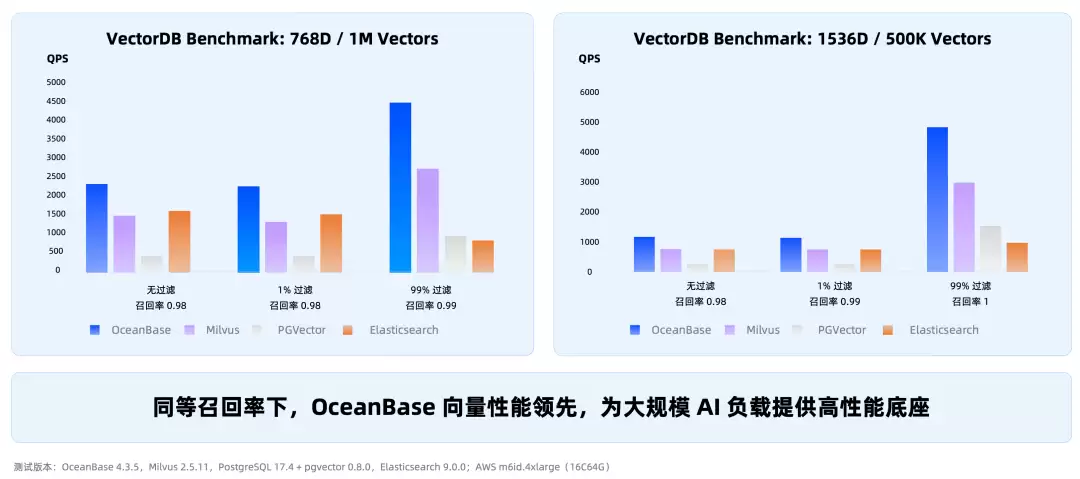
在MSMARCO数据集上,OceanBase混合搜索性能优于Elasticsearch 30%以上。
Agent友好:允许AI安全地犯错
根据实际落地经验,企业真正担心的并不是“Agent会不会干活”——它太敢于干活,反而才是风险。人类工程师改库之前会备份、会评审、会询问同事;Agent很可能一边推理一边执行,直接改动环境。
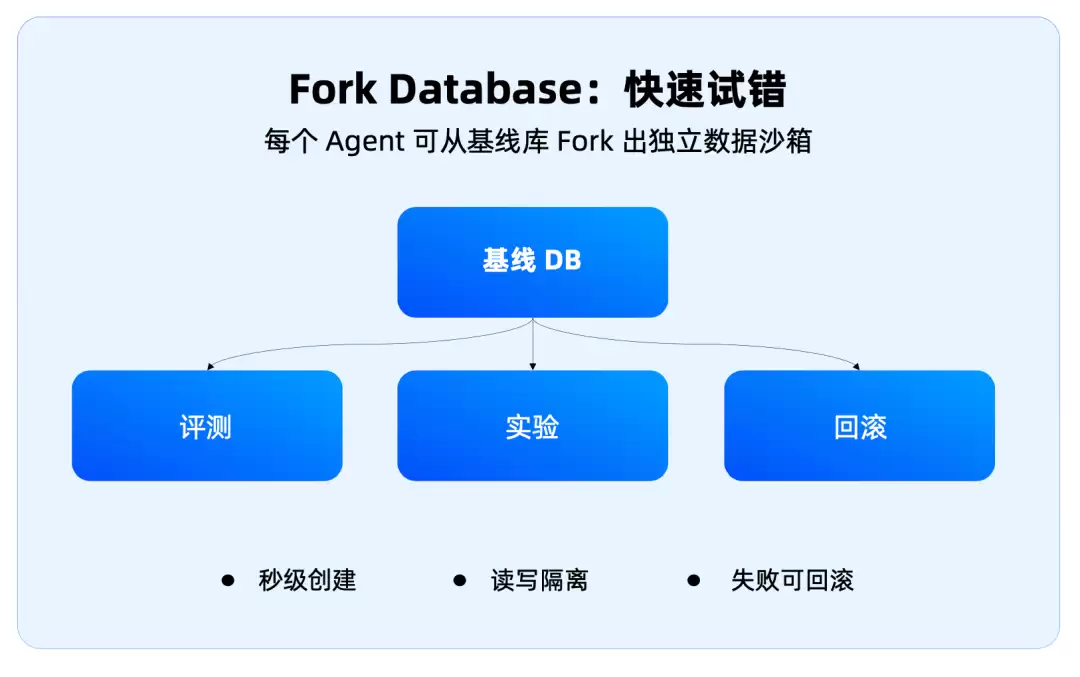
因此OceanBase这次提到的Fork Database、Copy-on-Write、Diff/Merge非常关键。它本质上是将代码世界的分支工作流搬进了数据库世界:Fork——为Agent创建一个独立的数据沙箱;Diff——查看它到底做了什么改动;Merge——确认无误后合并;Rollback——失败后快速回到原状态。
以蚂蚁阿福为例——这是一个服务上亿用户的AI健康应用,回答的准确性至关重要。它需要持续发现bad case、修复问题、重新评估,也就是一套生产级Agent评测工程。问题是,评测过程会改流程、改策略、改数据,这些操作不能污染线上生产数据。为了保证评测稳定,又需要克隆线上数据,甚至还要复制Memory、RAG、行为数据。在AI coding加速之后,十几个feature分支以周为单位并行迭代,如果每个分支都完整复制一套环境,成本和管理复杂度都会很大。
OceanBase Branch的解法是像代码分支一样创建数据库沙箱,可以毫秒级创建,内部目标是5分钟内拉齐一个评测环境,用完直接销毁。Agent改错了,就丢弃这个分支,重新从main拉一个出来。这才是生产级Agent需要的数据训练场。它的价值就是把犯错的影响圈定住。
Fork Database解决了单个Agent的安全试错问题,而逻辑表则解决了海量Agent的低成本并行问题。

海量逻辑表:AI时代的海量,可能是小库太多

另一个值得关注的案例:蚂蚁灵光在短短几个月内承载了3000多万个闪应用;妙思这类面向内部员工的平台也上线了上万个应用。这些应用有一个共同特点:平均每个应用的表里只有百余行数据。这和过去我们理解的海量很不一样——以前说海量,往往是单库大、单表大、并发高。Agent时代还有一种新的海量:库很多,表很多,应用很多,但每个都很小,绝大多数时间处于休眠状态。99%的应用创建后沉睡,但需要保留;少数被唤醒时,又要秒级响应。
如果每个Agent、每个轻应用都建立自己的物理表,schema将会爆炸。OceanBase给出的能力是逻辑表:每个Agent看起来拥有独立表和独立边界,底层通过逻辑隔离将大量表收敛到共享物理资源中。再配合共享资源池、按需唤醒、闲时资源归零,才能支撑海量Agent低成本并行运行。
这个设计非常务实。因为企业未来不会只有一个超级Agent,更可能是客服、财务、销售、合规、采购、研发、运营等每个部门都有一堆小Agent、小应用、小流程。它们都需要边界,但企业不可能按照每个小Agent一套完整数据库的成本来买单。
真实案例里,灵光为什么需要JSON Table
灵光这个案例也充分体现了Agent时代的数据形态变化。它号称30秒手搓一个AI闪应用,但用户创建出来的应用schema完全不固定。一开始可以把数据全序列化成JSON,塞进KV大宽表。问题来了,SUM、SORT这些数据库算子基本用不上,只能将数据捞回业务层计算,性能很差,多用户权限也难以控制。
另一种办法是为每个闪应用建一张物理表,但几千万张小表会把数据库控制面和存储压垮。灵光的方案是OceanBase JSON Table:闪应用后端接入SDK,用户照常写标准SQL,SDK自动转成JSON写入虚拟表。用户的SQL无需改动,OceanBase侧继续提供索引、SUM、SORT等能力,存储成本也能降下来。如果某个闪应用真的火爆起来,再将该部分JSON Table数据迁移到物理表以获得更佳性能。
DataStudio、DataPilot、PowerMem、PowerRAG:产品家族开始成型
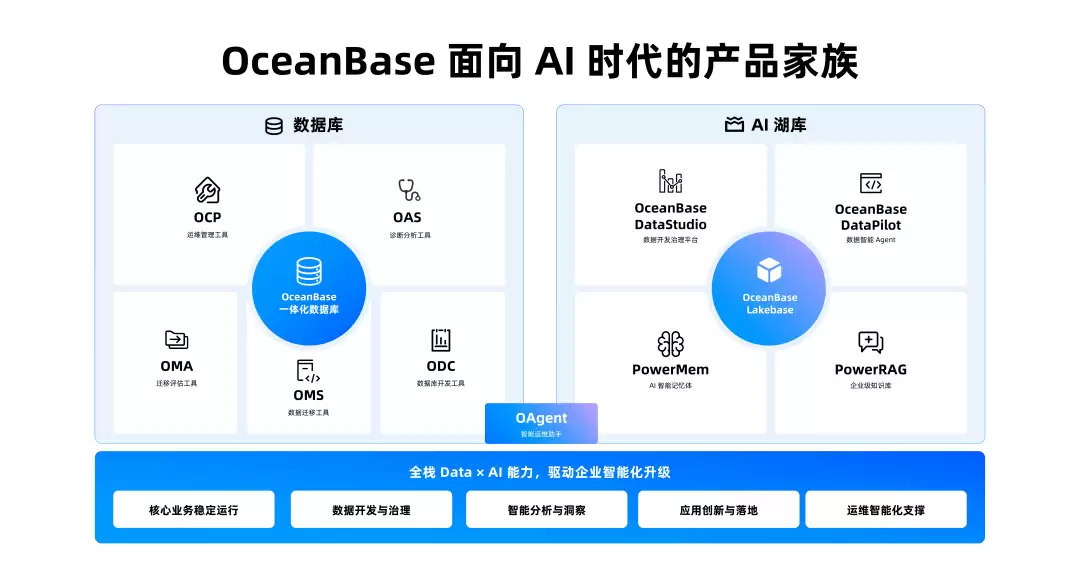
Lakebase是底座,但OceanBase此次发布的是整套产品组合。完整产品体系包括:
- Lakebase:底层湖库一体和多模态数据核心引擎
- DataStudio:面向数据开发、治理、服务发布和资产管理的工作台
- DataPilot:面向业务人员的数据智能Agent
- PowerMem:Agent记忆体
- PowerRAG:企业级知识库
- OSI语义层:帮助Agent理解业务语义、指标口径和上下文图谱
这套组合的方向非常清晰:底层解决数据如何存储、如何计算、如何搜索;中间解决数据语义、治理、记忆和知识;上层解决业务人员如何问数、取数、生成报告和看板。
DataPilot这一块尤其适合拿给业务团队理解。业务人员不关心底层表结构,也不想等待数据开发排期。他们想问的是:本月经营指标为什么波动?用户增长下降的主要原因是什么?帮我生成一份销售分析报告?搭建一个经营监控看板?DataPilot的关键远不止于自然语言问数,它背后依赖业务对象、计算口径、指标定义、上下文图谱等——这正是OceanBase OSI希望解决的问题:让数据库从记录事实,向理解业务更进一步。
总结
将OceanBase此次发布视为一个信号:企业AI的竞争,正从模型调用层下沉到数据基础设施层。
许多企业前两年忙着选模型、买算力、建知识库,下一阶段真正拉开差距的,很可能是数据底座。谁的数据更完整,谁的上下文更精准,谁的权限更稳固,谁的多模态数据更易治理,谁的Agent更敢进入生产流程——谁就更容易构建出真正可落地的AI应用。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:企业AI落地关键在数据底座而非大模型要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Daetama是面向数据科学面试和SQL能力提升的练习平台,已收录超100个覆盖基础到进阶的SQL题目,求职板块与课程模块在开发中,团队保持每周更新节奏,提供系统性刷题与模拟面试场景。
SpeakMulti是一款AI驱动的配音平台,可将YouTube视频翻译成多种语言,保留原始说话者的音色和语调,降低本地化成本。用户提交视频并选择目标语言后,AI自动完成配音,并由专家团队审核,确保准确自然。
需求人群 如果你经常需要从图片中提取文字——例如整理截图内容、翻译图片里的外语文本、识别带有水印的图片信息——那么 Umi-OCR 无疑是一款相当实用的工具。它完全在本地运行,无需联网,对隐私保护极为友好。 产品特色 这款工具的核心亮点都集中在实用性上。截屏识别操作非常顺手,按下快捷键即可框选区域,
艺术创作与人工智能的融合,正在开启一个全新的创作时代。moonlightai 正是这样一款AI绘画工具,能够帮助用户通过人工智能快速生成不同风格的绘画作品——无论你想复刻文艺复兴时期的古典优雅,还是为画作注入梵高般炽热的笔触,甚至从艾沃佐夫斯基的海浪星空中汲取灵感,它都能轻松实现。 需求人群 简单来
- 日榜
- 周榜
- 月榜
热点快看