




企业大模型选型指南与实用方法

企业可通过提示工程(低成本快见效)、检索增强生成(利用外部数据弥补新事实缺失)、微调(需大量高质量数据支持)或从头训练(最复杂需评估投入产出)等方法提升AI能力,需根据场景与投入灵活组合。
选择合适的大模型,提升企业AI能力,坦白说,这并非一件简单的事。核心其实就围绕几个关键方法:提示工程与上下文添加、检索增强生成(RAG)技术,以及微调模型。这三者各有侧重,企业可以根据自身情况灵活组合,才能真正让大模型为业务服务。
面对生产中部署大模型(LLM)的需求,市面上有不同训练程度、复杂度、成本和质量的模型可供选择。如何从LLM那里获得想要的结果?这里的关键在于,不同的方法对应的场景和投入完全不同。下面来逐一拆解。
提示工程并附加上下文
这是最具成本效益的起步方式。你看,预训练过的LLM在通用自然语言任务上表现已经足够惊艳,甚至只需要一个简短提示——比如一个未完成的句子或一个问题——就能触发所谓的“零样本”学习。但问题在于,用户越是能组织起详细的请求,并附上相应的示例(也就是上下文),模型给出的答案就越精准,越接近用户的预期。如果提示里只包含一个示例,这叫“一次性”学习;包含多个,就是“少量学习”。说白了,你给的“素材”越丰富,AI的“发挥”就越靠谱。
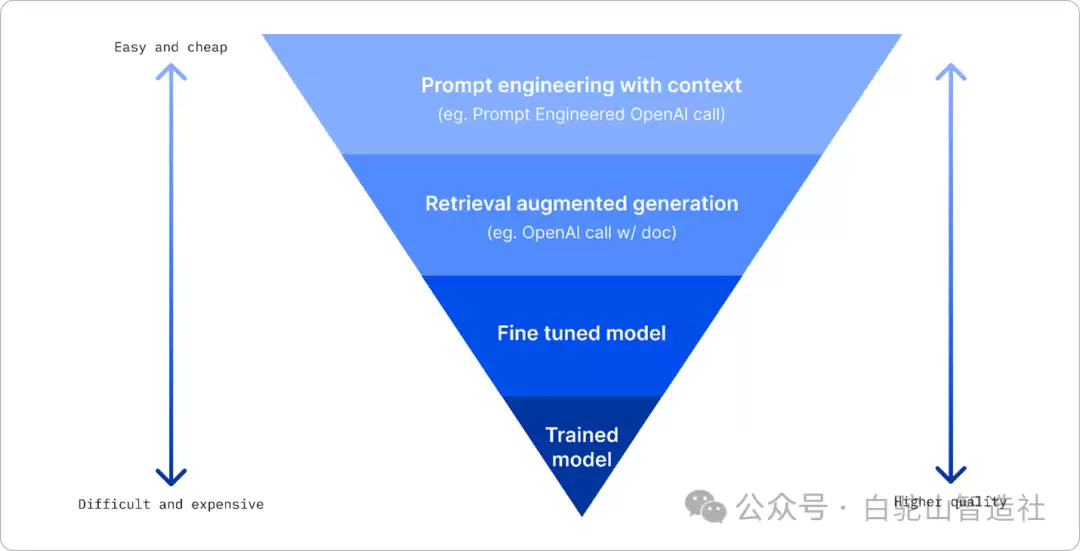
检索增强生成(RAG)
LLM有个天然短板:它只能基于训练时“见过”的数据来作答。这意味着,它对训练之后发生的新事实一无所知,更别说访问企业内部的非公开信息了。如何破局?答案是检索增强生成(RAG)。这是一种在考虑提示长度限制的前提下,利用外部数据(比如以文档块形式存在)来增强提示的技术。具体怎么实现?借助矢量数据库工具,比如Azure矢量搜索,它能从各种预定义数据源中检索出有用的信息块,动态地添加到提示上下文中。
当企业缺乏足够数据、时间或资源去微调LLM时,这个技术特别有用。它能显著提升特定工作负载的性能,同时有效降低模型“捏造”内容的风险——也就是那些脱离现实甚至有害的“幻觉”。

微调模型
微调则是另一条路。它利用迁移学习,让预训练模型“适应”特定的下游任务或解决某个具体问题。和少样本学习或RAG不同,微调的产出是一个全新的模型——权重和偏差都被更新了。这需要一套由输入(提示)和对应输出(完成)组成的训练示例。那么,什么情况下应该优先考虑微调?
首先,企业希望用微调过的、功能相对精简的模型(比如嵌入式模型)来替代高性能大模型,从而在成本和速度上获得优势。其次,延迟是关键考量,某些场景不允许使用过长的提示,或者能从模型学到的示例数量受提示长度限制。最后,企业需要有大量高质量数据、基础事实标签,以及维持这些数据长期更新的资源,才能保证模型持续有效。

训练大模型
从头开始训练一个大模型,无疑是技术栈里最硬核、也最复杂的一环。它需要海量数据、顶尖的研发团队和充沛的计算资源。除非企业拥有极其聚焦的垂直领域用例,并且积累了丰富的领域专有数据,否则一般不建议考虑这个选项。毕竟,投入与产出之间,需要非常谨慎的权衡。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:企业大模型选型指南与实用方法要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点LucidaAI是一款面向企业的AI英语口语教练,通过实时对话提供发音、语法、词汇和流利度的个性化反馈。采用端到端加密并支持合规定制,定价策略注重普及化,旨在以低成本提升团队英语沟通能力。
Screenshot2Code工具能够从截图中自动识别代码,并将其转换为可直接运行的代码。支持Python、HTML及API接口信息提取,帮助开发者快速复用他人分享的代码片段,从而显著提升工作效率。这个工具极大简化了代码复用过程。
SpeakStruct通过可自定义模板将语音转换为结构化数据,适用于会议记录、客户通话等场景。核心功能包括自定义模板、准确转录和随处捕捉,使口语信息直接转化为可用的数据资产。
IzzyAI是一款AI驱动的语音治疗应用,提供全天候服务。通过智能治疗师头像互动,系统评估并治疗五种常见语音语言障碍,融合语音与面部识别技术给予实时反馈。内置综合评估、个性化练习、进展报告及支持性社区,提升治疗效果。
- 日榜
- 周榜
- 月榜
热点快看