




Vidu S1发布 实时交互视频生成时代开启

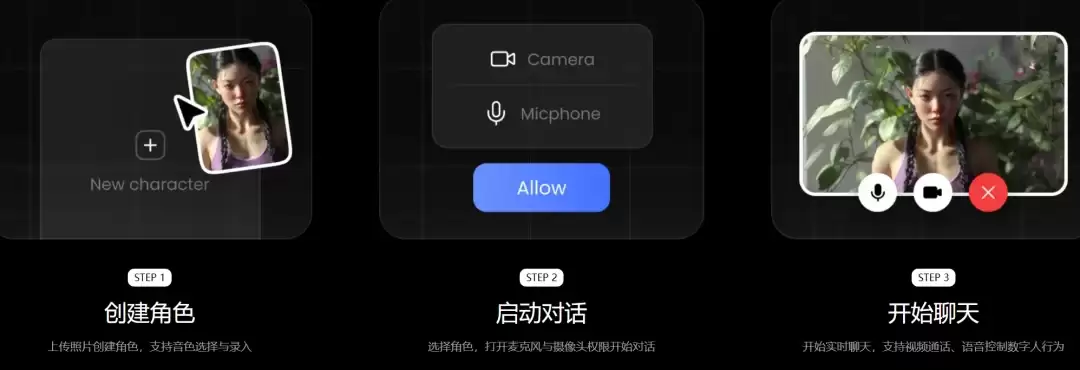
ViduS1是生数科技发布的实时交互视频模型,支持语音实时控制、无限时长生成、540P分辨率及25FPS实时输出,可在消费级显卡运行。用户上传图片即可创建可对话的数字角色,实现从离线生成到实时交互的范式转变。
先说一个核心观察:视频生成大模型的竞争风向正在悄然转变。过去一年,各家比拼的是分辨率多高、时长多长、动作多稳,用户输入提示词,模型吭哧吭哧算完,然后吐出一段固定长度的视频——这几乎成了行业默认流程。
但新的场景正在提出截然不同的要求。视频通话、实时陪伴、虚拟偶像、互动直播,这些场景里用户会不断提问、打断、引导角色做出新反应;而角色需要在对话中持续理解语音、调整动作、维持形象,并且把新的反馈实时呈现在画面里。换句话说,视频模型不再只负责“生成得好”,还得随时听得懂、马上有反应、长时间不掉线。
正是在这个节点上,生数科技把Vidu S1带到了实时交互这条新路线上。
在今天举行的2026全球数字经济大会上,生数科技创始人朱军正式发布了这款全新实时交互模型Vidu S1。由朱军教授的00后博士生张金涛担任负责人,团队完成了全链路研发。Vidu S1的目标很明确:让视频模型从“离线成片”走向“可对话、可响应、可持续在线的实时交互”。其核心能力包括语音实时控制视频生成内容、无限长实时生成、540P(960×540)+ 25FPS(最高支持42FPS)实时交互,以及自定义初始图像与音色。更难得的是,这套能力在消费级显卡上就能跑起来。
这意味着数字人的创建流程被彻底改写了。
过去,制作一个数字人像在完成一个小型项目:准备素材、建模或训练、再对口型、调整动作和形象,周期从几分钟到一天不等。而Vidu S1走的是纯粹的生成式路线,省去了离线建模和角色训练环节。用户只需上传一张首帧图,模型就能快速理解角色的身份、外观和风格,并在交互过程中实时生成表情、口型、动作与姿态;再结合自定义音色,角色形象和声音的统一下,整个流程变得异常轻快。
我们也提前体验了一把实际效果。比如上传一张最近爆火的负鼠表情包,简单设置后,一个会说天津话的负鼠角色就出现在了屏幕里。它不仅能接话、顺着话题往下聊,还能听懂动作指令:你让它比赞、摸鼻子、眨眼睛,它都能在画面里实时做出对应动作。
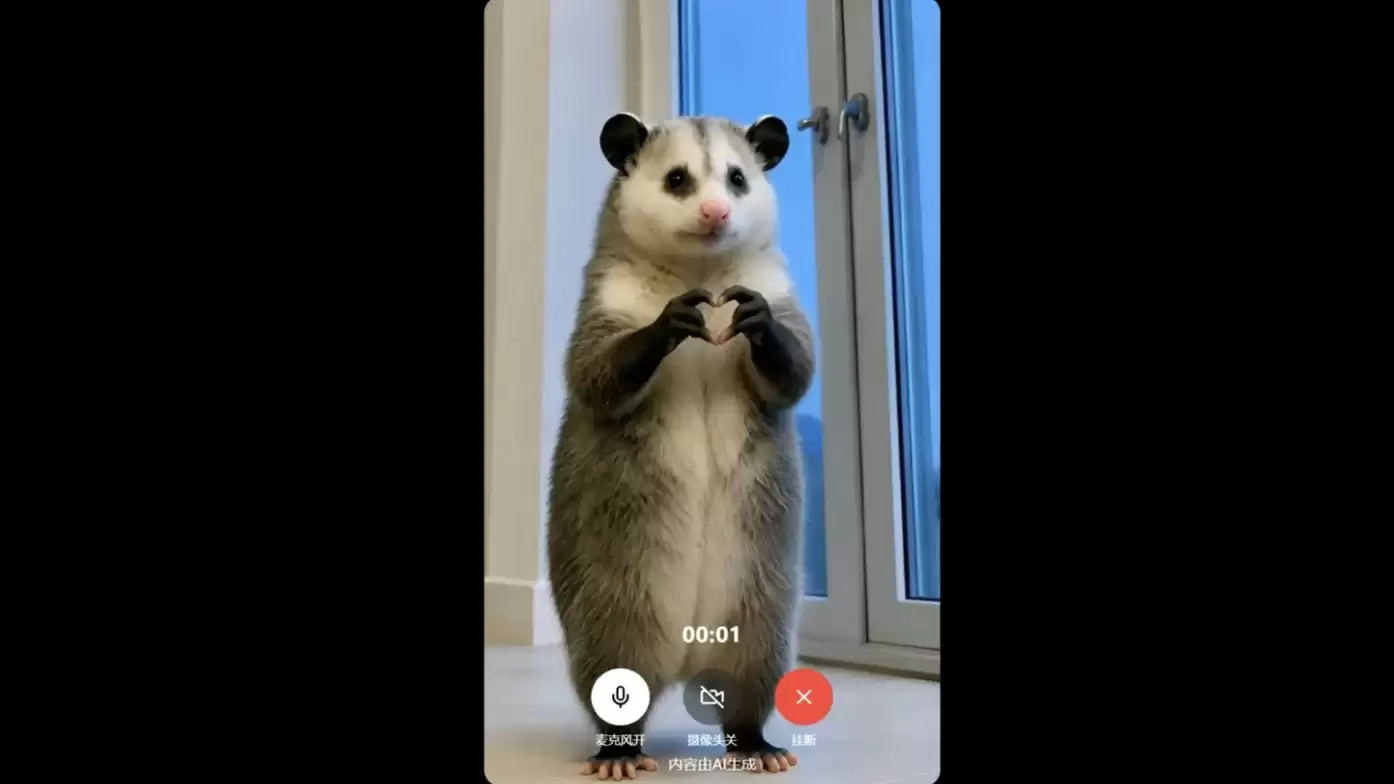
这正是Vidu S1最值得关注的地方——它不是在已有视频生成能力上做常规升级,而是为实时交互式视频模型确立了一个新的技术基准。生成质量当然重要,但仅仅是起点,能否实时交互,正在成为新的分水岭。
从离线生成到实时交互:Vidu S1定义视频生成模型新基准
从离线播放到双向互动:交互范式的根本转变
过去视频生成模式可以概括为三步:用户输入提示,模型推理计算,然后一次性输出一段音视频。这套逻辑本质上是一次性内容交付,用户在生成过程中没有介入和修改的空间。
但Vidu S1想改写这个规则。它支持通过语音甚至摄像头画面与角色进行实时对话。用户说一句话,模型立刻理解语义并同步生成对应的视觉反馈——注意,这不是先生成完整视频再播放,而是像视频通话一样,边理解、边生成、边输出。用户随时改变指令,模型也会随之调整下一步的画面内容,不需要重新发起一次生成请求。
值得一提的是,Vidu S1还具备一定程度的场景理解能力:当用户开启摄像头,模型能识别画面中的人物数量、动作状态等信息,并据此给出实时反馈。这让交互不再局限于对话本身,也延伸到了对物理环境的感知。
语音指令实时跟随:不只是驱动嘴型,而是驱动行为
数字人技术发展到今天,多数产品仍停留在“音频驱动口型”阶段。这种方式的局限很明显:动作数量有限,组合痕迹明显,用户很容易感觉到这是被安排好的表演,而不是真实的即时反应。
Vidu S1采用实时视频生成技术架构,让模型不仅能听清语音内容,更能听懂语义和情绪,并实时生成与之匹配的表情、手势乃至完整的肢体动作——注意,不是从固定动作库里调用现成片段,而是原生地生成。这背后是自回归扩散模型(AR + Diffusion)路线:模型并非一次性产出完整片段,而是基于已生成的历史画面,结合用户当前的语音、指令等上下文信息,实时预测并生成下一帧内容。这种逐帧生成的方式,天然具备可被实时打断和改写的特性。

语音指令 实时跟随。从「语音驱动口型」迈向「语音驱动行为」,让角色听得懂、动得准、反馈更自然

实时生成 无限时长。全球领先的无限时长,实时互动视频大模型
无限时长实时生成
除了交互式实时生成,Vidu S1还首次实现了无限时长的实时视频生成。即使连续生成数小时,画面仍能保持稳定,不会快速漂移或崩坏。实现长时间连续互动,仅仅“持续生成”还不够,模型还需要在长时间运行中同时保持角色身份稳定、动作自然连贯,并持续接收用户指令、实时做出响应。Vidu S1在这几点上都做到了,率先实现了无限时长的生成式视频互动。
540P+25FPS背后:实时交互拼的是模型与系统协同
在实时交互场景下,分辨率和帧率是直接决定用户体验是否流畅的关键门槛。视频通话、直播互动这类场景对模型的要求是持续输出、快速响应,并且在长时间运行中保持帧率稳定——任何一次卡顿或延迟都会被用户直接感知。
Vidu S1给出的答案是540P(960×540)分辨率、25FPS帧率(最高支持42FPS)的实时生成能力,在同类实时交互方案中处于行业前列。

540P + 25 FPS 实时交互。支持 540P + 25 FPS 的高分辨率实时视频互动生成 (最高支持 42 FPS)
要实现这样的指标,背后离不开模型架构和系统工程两个层面的协同优化。在模型侧,Vidu S1基于生数科技的TurboDiffusion推理加速框架,通过少步生成、低比特注意力SageAttention、稀疏注意力SLA和SpargeAttention等技术,大幅降低单帧生成所需的计算成本,在消费级显卡上就能跑起来。在系统侧,Vidu S1基于TurboServe推理部署引擎,实现高效的推理请求调度,持续记录用户输入、角色状态和历史画面,并根据交互状态动态调度计算资源。
这种协同优化,让Vidu S1实现了从“把视频生成得更快”,到“让视频持续在线、稳定输出、实时响应”的关键跨越。

540P + 25FPS(最高支持42FPS)让实时视频生成模型具备了进入视频通话、直播、实时陪伴、互动游戏乃至XR场景的基础能力门槛。这些场景对延迟稳定性和长时间在线能力的要求,是传统离线生成模型完全无法满足的。
自定义角色:支持任意图片与音色进行数字人创建
用户在体验页面中可以上传图片创建自己的角色。无论是真人形象、动漫人物、萌宠,还是游戏角色和其他虚拟形象,都可以作为初始角色使用;声音层面,用户也可以选择系统音色,或录制自己的声音进行定制。普通用户可以用宠物、插画或自创人物生成互动角色;企业则可以通过API,将品牌IP、虚拟客服、数字主播、游戏NPC或教育陪练接入自己的业务。
一手测试:女孩、学长、狐妖、蒙娜丽莎,都被Vidu S1「唤醒」了
更重要的是,Vidu S1已经开放试玩,支持自定义初始图像实时互动,同时开放了API平台。实际效果如何?我们亲自上手体验了一番。
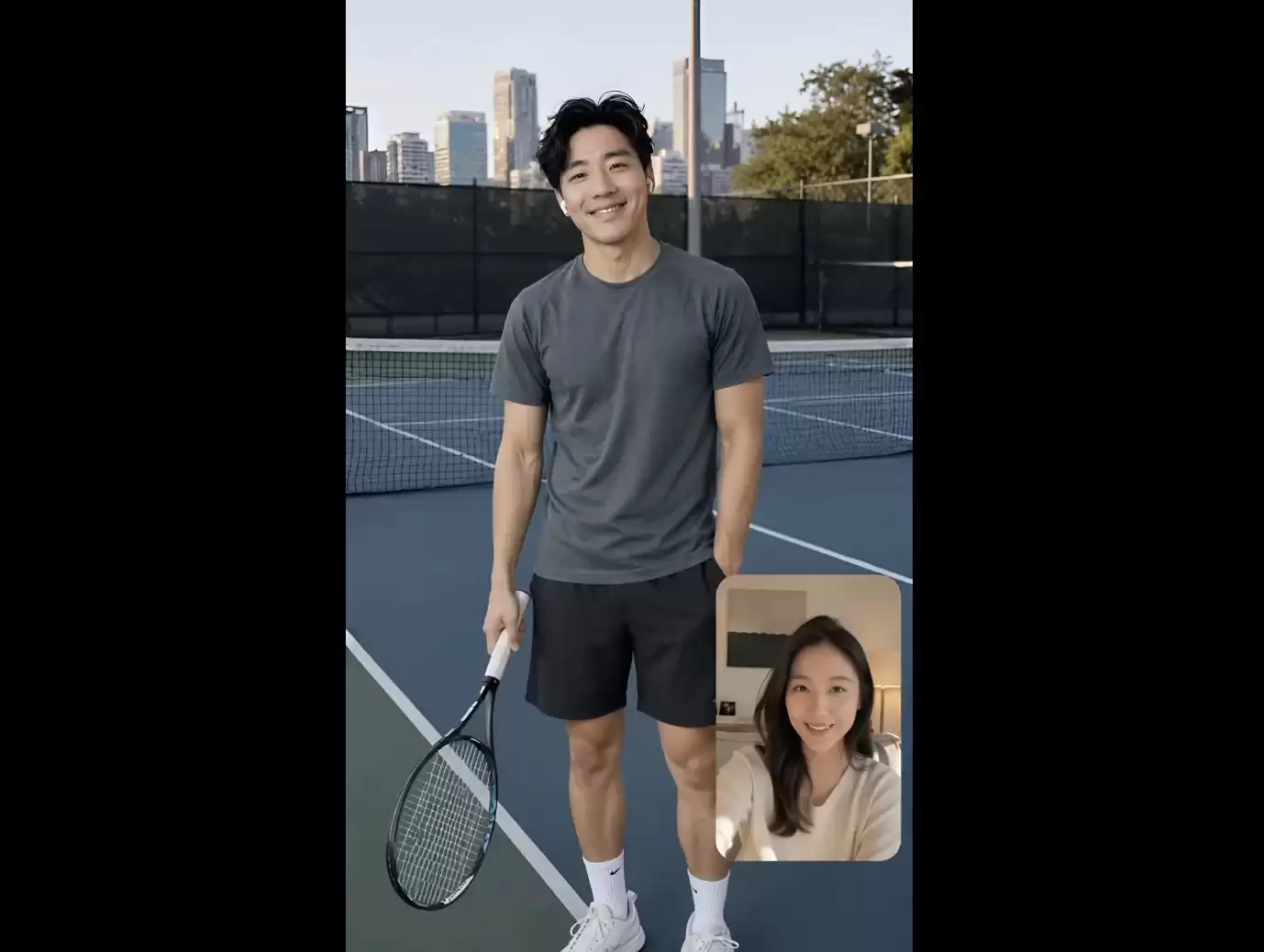
首先从预置角色开始测试。选定角色后,通过麦克风直接发出语音指令,角色会在画面中实时回应,并根据对话内容实时生成表情、口型和动作反馈。比如当我们要求“举起网球拍”时,数字人自然调整身体姿态,抬手完成挥拍动作。
又比如,发出“双手放在胸前比&心”的指令后,数字人响应很快,手部位置、身体姿态和表情衔接都比较自然。语音在这里已经延伸为角色行为生成的控制信号。
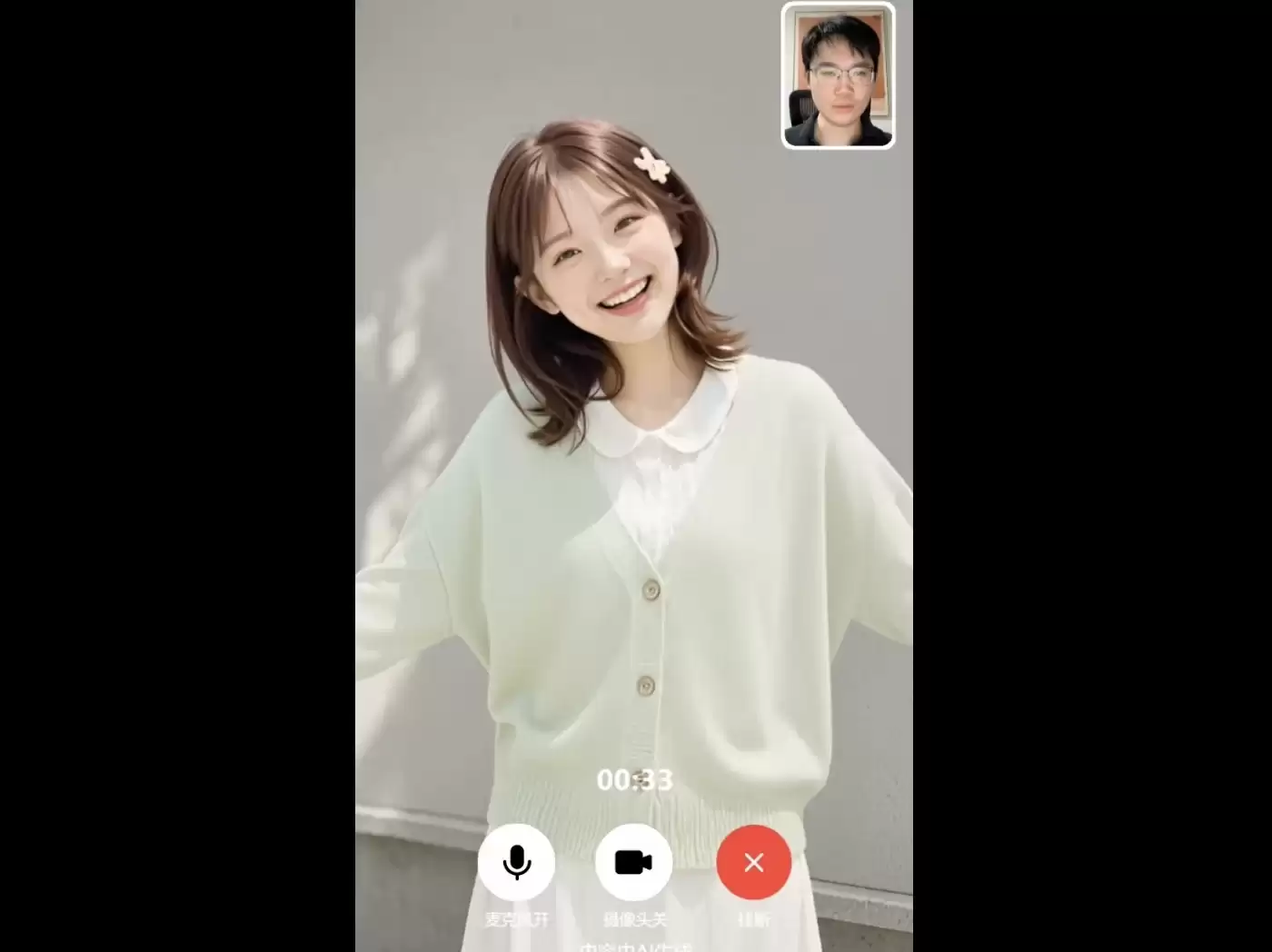
在闲聊场景中,数字人回应时语气自然,节奏与真实交流相符,会顺着用户的问题继续展开,也会根据语境调整表情和状态。这种自然接话的能力,让角色更有在场感。我们临时提出推眼镜、撩头发等更细的动作要求,也都较好地完成了。
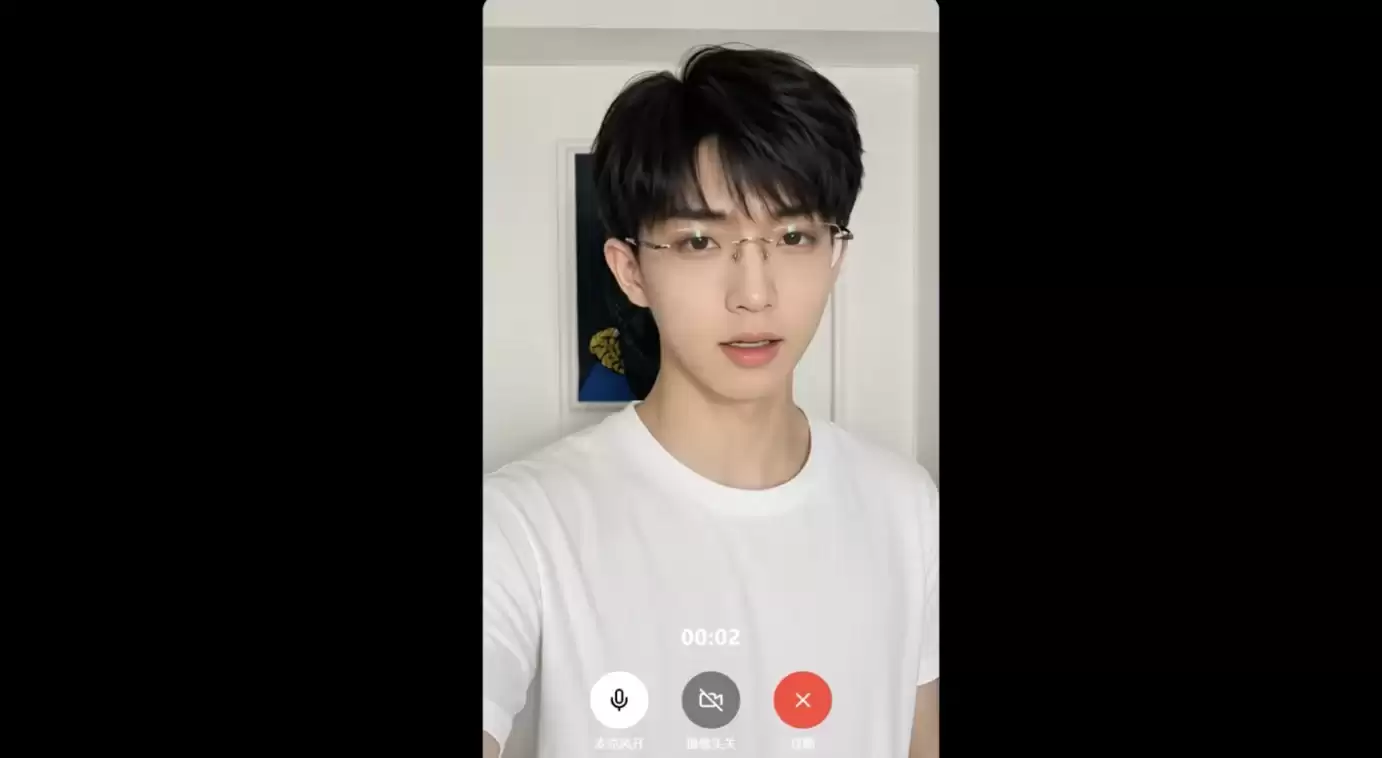
一个角色展现出了极高的交互智能与情绪感知力:不仅对答如流、转承自然,更能主动引导话题、避免冷场,对随机提出的开放性问题应对自如。在指令执行层面,对“比&心”“施法”等动态指令完成度极高;在情感表达上,“生气”等微表情的管理也十分精准到位。
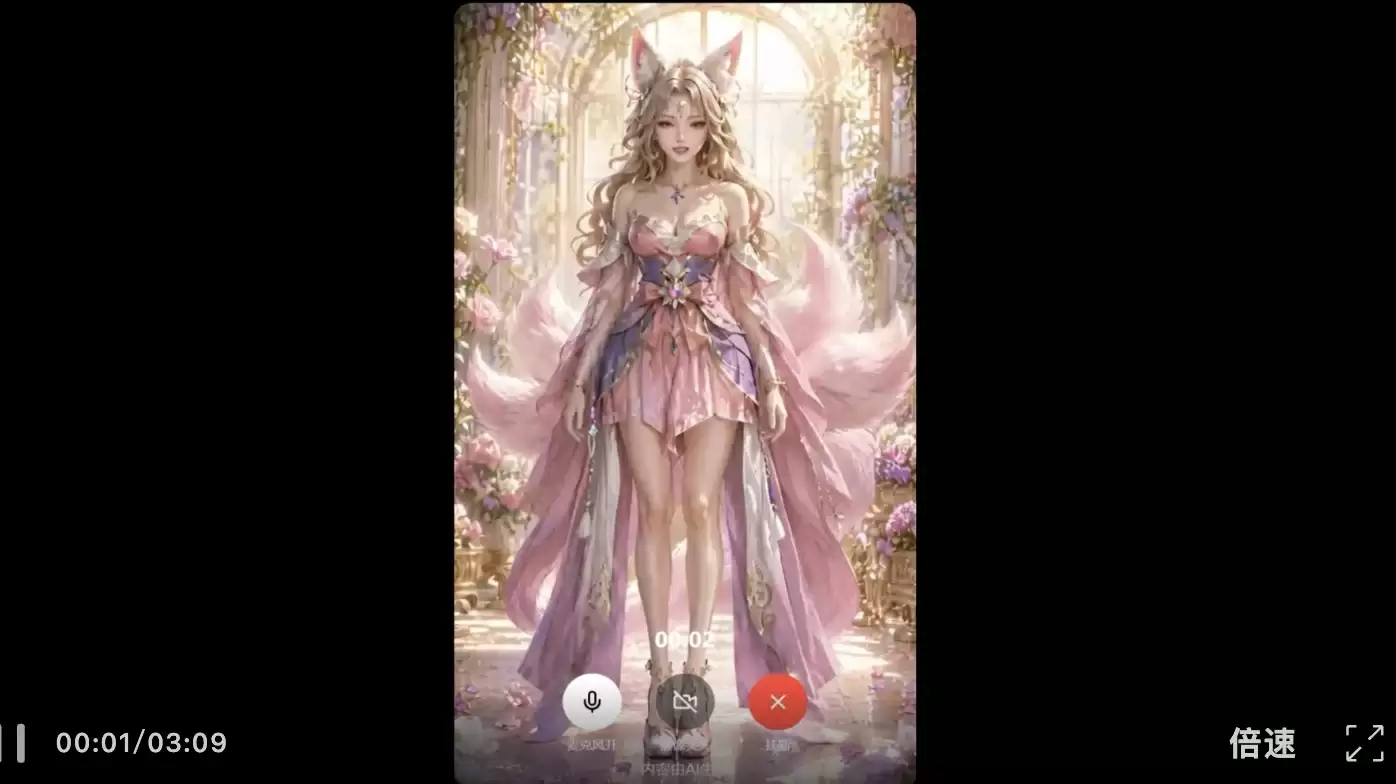
除了预置角色,Vidu S1也支持用户上传图片创建自己的角色。创建过程中,用户可以直接选择系统提供的预置音色,也可以录制自己的声音,让角色在视觉形象和声音上都具备更强的个性化特征。更让人意外的是创建速度:上传图片并完成基础设置后,新角色几乎可以立即进入对话状态。
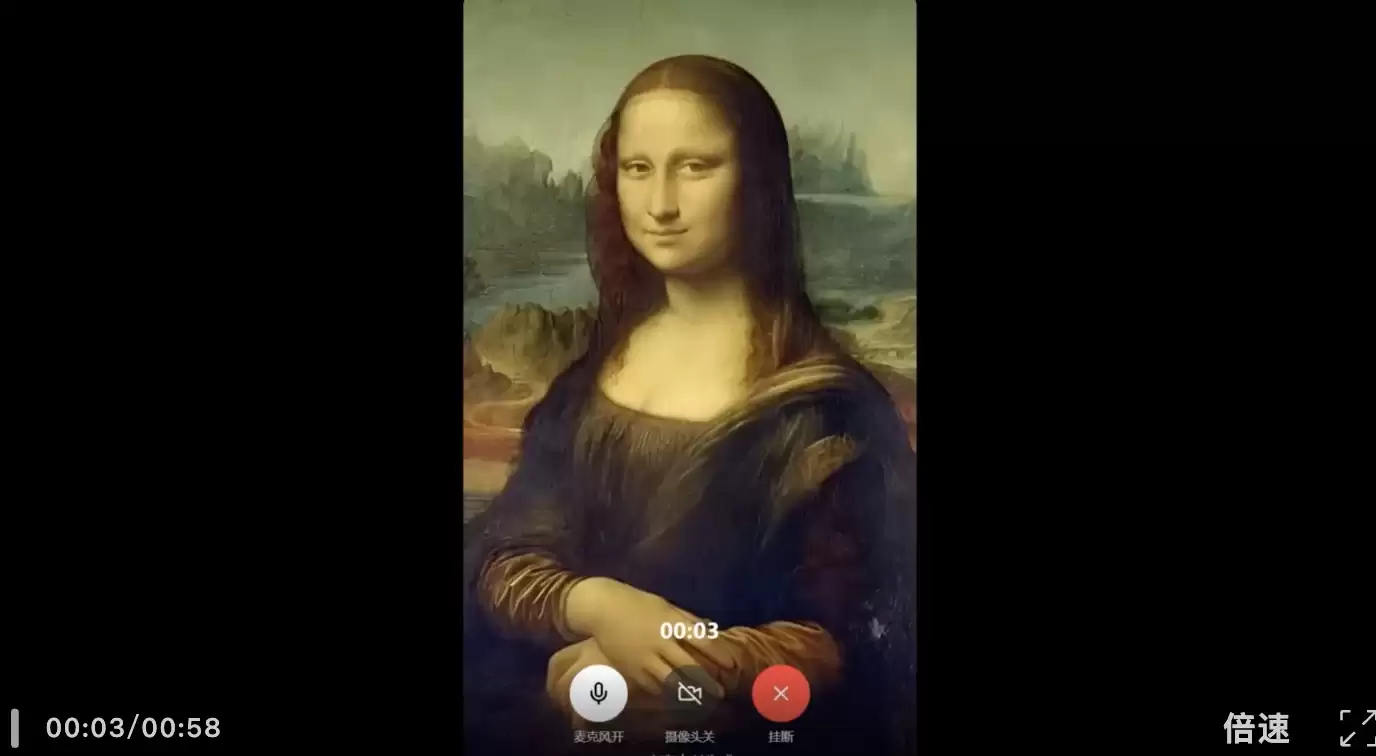
最后,我们上传了一张《蒙娜丽莎》的图片进行测试。进入通话后,画面中的蒙娜丽莎不再只是保持经典微笑,而是可以根据语音输入开口说话,并在对话过程中生成口型、表情和轻微动作反馈,无论是抬手动作还是生气时的表情和语气,都非常自然。
自定义角色可以覆盖真人、动漫、萌宠等常见形象。对于内容创作者来说,这类能力打开了更大的想象空间:一张历史人物画像、一幅插画、一个品牌IP,甚至一张风格化角色图,都有机会被快速变成可对话、可表演、可持续互动的数字角色。
结语:视频生成模型的下一站,是实时交互模型
过去,视频大模型主要服务于内容创作,用户关心的是视频清不清晰、够不够好看。但接下来,视频大模型会进入实时交互场景,用户开始关心模型能否实时听懂需求、能不能马上做出反应、能否长时间保持同一个角色、是否可以接入直播、陪伴、游戏和XR——这些问题,单靠传统离线视频生成无法解决。
实时交互模型让视频从播放对象变成交流对象,数字人也因此从“会说话的形象”走向“可以被语音驱动、感知环境、持续生成行为的在线角色”。这正是Vidu S1想要定义的行业位置。从率先提出钱-ViT架构,到率先发布实时交互模型,生数科技始终走在视频大模型技术演进的前沿。未来,行业竞争将不再局限于视频生成质量,而是围绕实时响应、角色一致性与长期在线能力展开。随着流式视频模型和AI Character的持续发展,数字人也将从内容生产工具,进化为下一代人机交互入口。
[1] TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times.
[2] SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration.
[3] SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention.
[4] SpargeAttention: Accurate and Training-free Sparse Attention Accelerating Any Model Inference.
[5] TurboServe: Serving Streaming Video Generation Efficiently and Economically.
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Vidu S1发布 实时交互视频生成时代开启要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点8月21日,OpenAI首次开放企业客户用自有数据微调旗舰模型GPT-4o,支持文本数据,训练约1-2小时。此前仅可微调较小模型,此举大幅降低定制门槛,无需第三方服务,企业可快速实现个性化AI应用。
免费AI旅行规划工具,可快速生成个性化定制行程,适合个人与家庭出行。能处理开放式问题,提供全面路线、亲子活动和悠闲节奏方案,并支持在线预订机票住宿,同时提供丰富旅行灵感及详细攻略。
需求人群 首先,这类工具主要面向哪些用户?答案很明确——任何投放Google广告、因无效点击和恶意竞争而焦头烂额的广告主。核心痛点集中在以下三个方面: 保护Google广告免受恶意点击侵害,简单说就是防止竞争对手或机器人白白消耗你的广告预算。 确保广告预算仅用于真实用户的互动,每一分钱都必须具备真实
说到结构化数据的交互式搜索,许多团队都面临一个尴尬的局面:数据整理得井井有条,但用户想要查询信息,还得编写复杂的查询语句。有没有一种方式,能让用户直接用自然语言提问,系统就能自动理解并返回精准结果?答案是肯定的——Microsoft Knowledge Exploration API正是为此而设计的
- 日榜
- 周榜
- 月榜
热点快看