




SERL算法篇让机器人真机强化学习从难用到可复现

【机器人 强化学习】SERL:让实体机器人强化学习从“难以操作”迈向“可复现”的强化学习框架 —— 第4篇:算法解析(DrQ vs VICE) 0x00 概述 0x01 奖励机制与自动化演进:从手工设计的 reward 到自学习的 reward 1 1 成功分类器:借助少量图像训练自动化裁判 1
【机器人 / 强化学习】SERL:让实体机器人强化学习从“难以操作”迈向“可复现”的强化学习框架 —— 第4篇:算法解析(DrQ vs VICE)
- 0x00 概述
- 0x01 奖励机制与自动化演进:从手工设计的 reward 到自学习的 reward
- 1.1 成功分类器:借助少量图像训练自动化裁判
- 1.2 VICE:将奖励分类器融入训练流程
- 0x02 DrQ 与 VICE 的深度对比
- 2.1 DrQ Agent(基于数据正则化的 Q 学习)
- 2.2 VICE Agent(基于事件的反向变分控制)
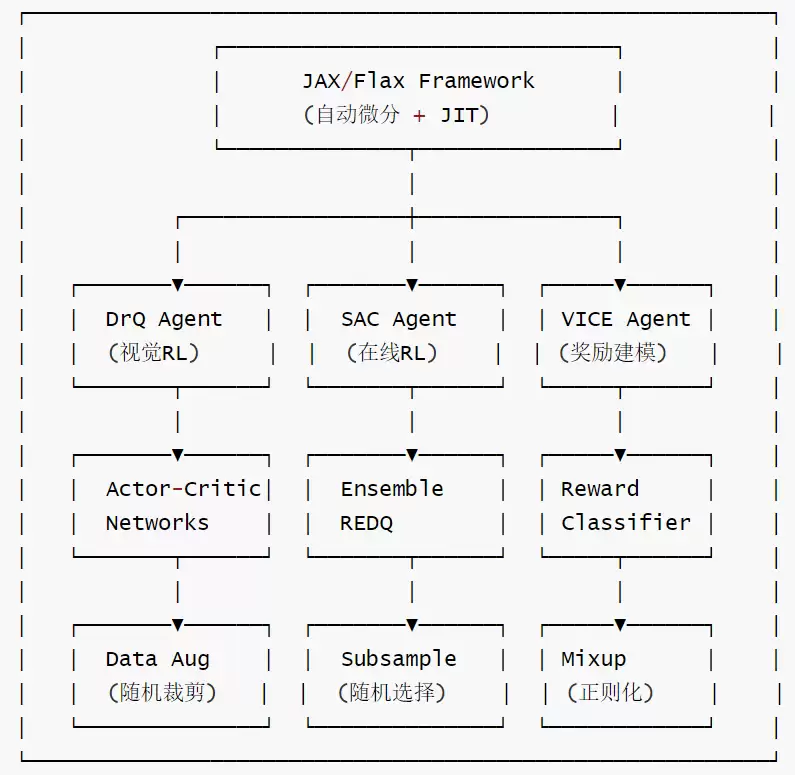
- 2.3 Agent 体系架构
- 2.4 关键特性对比表
- 0x03 DrQ:提升视觉强化学习的稳健性
- 3.1 数据增强的重要作用
- 3.2 视觉编码器的体系结构
- 3.3 算法核心实现
- 0x04 VICE 详解
- 4.1 背景与核心原理
- 4.2 网络架构设计
- 4.3 奖励(Reward)的计算方式
- 4.4 训练逻辑与流程
- 4.5 流程图解
- 4.6 工程实现与防崩坏细节
- 0xFF 参考资料
0x00 概述
本篇内容围绕两个核心算法模块展开:DrQ 和 VICE。前者着力解决机器人通过视觉感知世界时面临的图像特征泛化难题,后者则应对真实环境中无法直接编写奖励函数的困境——让机器人自身具备评判“成功”的能力。
- DrQ 聚焦于提升视觉输入的稳健表现,确保策略不会因光照变化或背景干扰而轻易失效。
- VICE 提供自动化的奖励信号,让机器人从“成功的视觉表现”中学习如何进行自我评估。
值得注意的是:本系列文章的最终目标是通过解读一系列相关项目与算法,来深入剖析、分析并反向推导 LWD(Learning while Deploying)这篇论文的内在机理与潜在实现路径。之所以从 SERL 入手,是因为 SERL、HIL-SERL 以及尚未开源的 SOP 均出自罗剑岚博士团队,从中可以窥见作者的研究思路与发展脉络。本文依然基于工程实现与论文内容进行反向推导,欢迎读者批评指正。
0x01 奖励机制与自动化演进:从手工设计的 reward 到自学习的 reward
真实机器人任务中的奖励设定是 SERL 重点关注并攻克的核心问题之一。部分任务可以直接利用机器人状态信息来定义奖励,例如 PCB 插装操作:可以根据末端执行器或目标物体的位置设计一个简单的二元分类器,接收状态观测 s,输出一个二元“事件”e 是否发生的概率,对应任务是否成功。此时奖励由 r(s) = log p(e|s) 给出。
然而,更多任务需要从图像信息中判断任务是否完成。比如“线缆是否正确卡入卡槽”“物体是否被准确放置到指定容器中”,仅依赖状态变量难以清晰描述,手工设计一套良好的奖励函数本身既耗时又需要深厚的领域知识。
SERL 支持以下三类奖励方式:
- 手工设计奖励:适用于状态信息足以直接判断任务成功与否的场景
- 二分类成功判别器:利用成功与失败的图像样本训练分类器
- VICE:将奖励分类器的训练与强化学习过程相结合,在训练过程中利用策略产生的负样本来迭代更新分类器
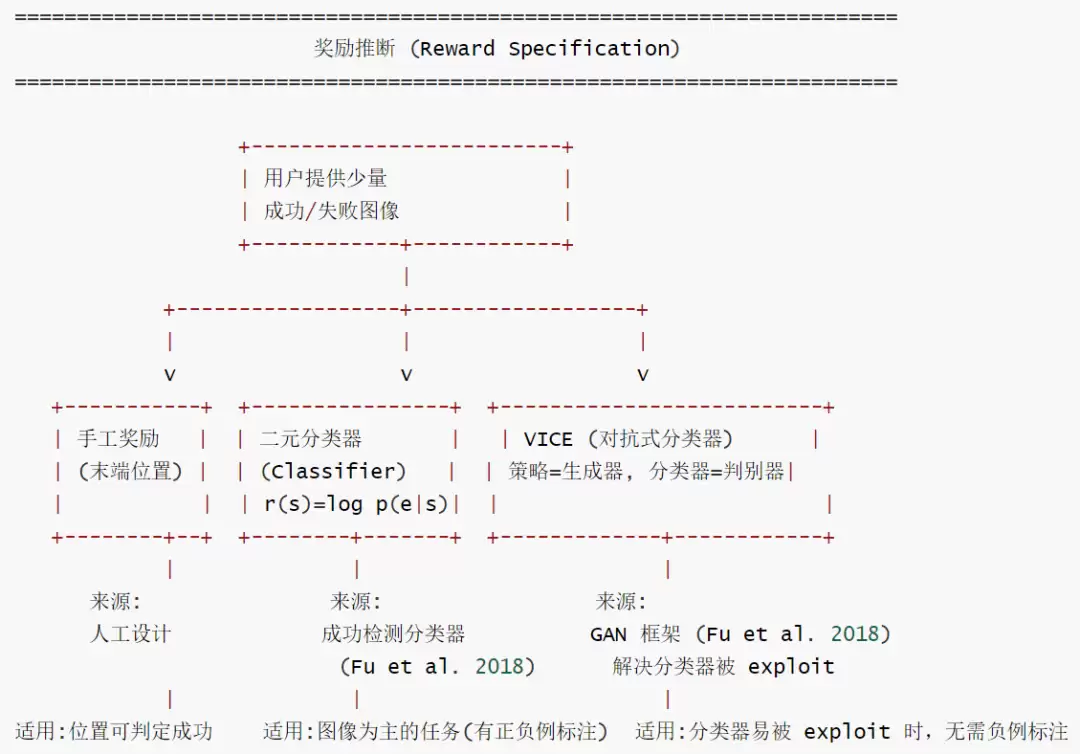
1.1 成功分类器:借助少量图像训练自动化裁判
用户可以采集少量成功与失败的图像样本,训练一个轻量级的视觉分类器。该分类器在训练过程中输出成功概率或二值化的奖励信号。换句话说,用户只需定义成功与失败的样本,系统便能在训练过程中自动生成奖励,实现自动裁判(Success Classifier):
成功分类器是专为离线训练设计的简洁端到端结构:
- 架构:基于轻量级视觉分类器,利用少量正负样本图像进行快速预训练。
- 职责:在训练过程中实现奖励自动化,使系统具备无人值守的自我优化能力。
- 流程:先收集正/负样本 pkl 数据,通过 BCE 损失函数训练冻结的 ResNet-10 骨干网络和可训练的 MLP 头部,保存模型检查点,随后将其加载到环境包装器中作为固定的奖励函数。
需要明确:SERL 并非完全不需要奖励,而是提供了工具让奖励的定义过程更加便捷和自动化。其目标并非消除奖励设计,而是降低奖励工程开发的成本。
1.2 VICE:将奖励分类器融入训练流程
VICE 将奖励学习过程视为类似生成对抗网络(GAN)的机制:策略扮演生成器的角色,不断产生新的状态样本;奖励分类器则扮演判别器,判断哪些状态属于成功事件。如此一来,随着策略分布的变化,分类器可以利用策略生成的新负样本持续进行训练,避免仅在初始数据集上出现过拟合。
这种设计使得奖励系统能够自适应地跟随策略的进化。在初始阶段,分类器基于人类标注的样本进行训练;随着策略能力的提升,分类器可以从策略实际产生的经验中学习到更细粒度的成功模式,从而实现奖励信号的持续优化。
VICE 采用在线训练模式,支持 return_encoded 和 classify_encoded 两种工作模式。VICEAgent 继承自 DrQAgent,分类器被嵌入 Agent 内部,与强化学习训练过程交替在线更新。额外采用的正则化技术包括 Mixup、标签平滑(Label Smoothing)以及梯度惩罚(Gradient Penalty)。
0x02 DrQ 与 VICE 的深度对比
在具身智能与强化学习的语境下,DrQ 和 VICE 是两套针对不同核心痛点的经典 Agent 架构。简单来说:DrQ 旨在让机器人“看得更清晰”,而 VICE 致力于让机器人“判罚得更精准”。
- VICE(如同上帝之眼):解决“是否达到目标状态”的问题,通过分类器提供平滑且客观的奖励信号。
- 视觉鲁棒性(DrQ):通过随机裁剪操作,对当前状态 s 和下一状态 s' 使用不同的偏移量,强制网络学习物理特征而非像素坐标;共享编码器使 Actor 和 Critic 共用 ResNet-10 骨干网络,加速特征收敛。如此一来,视觉处理与硬件控制实现了“眼手协同”。
2.1 DrQ Agent(基于数据正则化的 Q 学习)
用途:解决从图像直接学习动作(Pixel-to-Action)过程中的样本效率与泛化问题。
- 痛点:如果直接将原始图像输入给强化学习模型,机器人很容易陷入“只看局部”的困境,甚至因光线轻微变化而完全丧失执行能力。
- 核心特色:图像增强(Data Augmentation)与一致性约束。具体做法是:每当机器人看到一张图像,DrQ 会在后台生成该图像的若干个“微调版本”(例如随机裁剪 4 个像素、轻微调整亮度),然后强制要求模型对这些“微调版本”预测出的 Q 值保持一致。
- 优点:极强的稳定性——相当于在训练过程中为机器人佩戴了各种“滤镜”,强迫模型学会洞察事物的本质特征;极高的样本效率——即便数据量有限,通过图像增强也能学习到稳健的特征表示。
2.2 VICE Agent(基于事件的反向变分控制)
用途:解决“自动定义奖励(Reward)”的问题,尤其适用于那些难以用数值精确描述的“事件”。
- 痛点:例如,如何告诉机器人“盖子已经盖紧”?很难通过代码计算精确的角度变化。
- 核心特色:逆向学习(Inverse RL)结合事件判定。开发者向机器人展示一系列“成功的快照”(例如 20 张盖好盖子的照片)。VICE 通过这些图像训练一个判别器。在机器人自主尝试时,VICE 会根据当前画面与这些成功快照的“相似程度”,自动生成一个介于 0 到 1 之间的分值。
- 优点:零代码定义奖励——只要提供成功的图像,就拥有了奖励函数;“事件”驱动的逻辑——核心思想是“只关注结果状态”,非常适合解决那些结果明确但过程复杂的任务,例如扣上纽扣。
2.3 Agent 体系架构
在 SERL 中,SACAgent 是核心基类。
2.3.1 SACAgent 核心机制
| SACAgent 核心机制 | 功能描述 |
|---|---|
critic_loss_fn() | 实现 Clipped Double Q 机制、集成最小值计算,并可选支持 entropy backup |
policy_loss_fn() | 标准 SAC Actor 目标函数:Q - α·logπ |
temperature_loss_fn() | 通过 Lagrange 乘子实现自动温度调节 |
update_high_utd() | 关键优化环节:采用 UTD ratio 进行多次 Critic 更新和 1 次 Actor 更新,借助 jax.lax.scan 实现 JIT 内循环 |
update() | 支持选择性更新子网络(通过 networks_to_update 参数控制) |
2.3.2 继承体系
DrQAgent 和 VICEAgent 都是 SACAgent 的子类。这意味着它们复用了 SAC 的所有稳定机制(双 Q 网络、熵自动调节),仅在输入端增加了一层图像处理逻辑。
DrQAgent 的增强特性(drq.py):对观测值(observations)和下一观测值(next_observations)执行随机裁剪数据增强;支持 3 种编码器:小型编码器(4 层 CNN)、ResNet(从零训练)和预训练 ResNet(ImageNet 预训练 ResNet-10 冻结 + 可训练汇聚头部)。
VICEAgent 的奖励学习机制(vice.py):使用二元分类器替代手工设计的奖励函数;训练技巧包括 Mixup、标签平滑和梯度惩罚(用于防止 GAN 模式崩塌);推理时:若 sigmoid(logit) >= 0.5,则奖励为 1,否则奖励为 0。
继承关系如下:
SACAgent (sac.py:21)
├─create_pixels()→ 像素输入,支持共享/独立编码器
└─create_states()→ 状态输入,无编码器
└─ DrQAgent (drq.py:23) 继承 SACAgent
├─create_drq() → 支持小型 / ResNet / 预训练 ResNet 编码器
├─data_augmentation_fn() → 随机裁剪增强
├─update_high_utd() → 高 UTD 比率训练(关键优化)
└─update_critics() → 仅更新 Critic
└─ VICEAgent (vice.py:26) 继承 DrQAgent
├─create_vice() → 额外创建 VICE 分类器网络
├─update_vice() → BCE 损失 + Mixup + 标签平滑 + 梯度惩罚
├─vice_reward() → 用分类器替代手工奖励
└─update_high_utd() → 使用 VICE 奖励替换环境奖励
2.4 关键特性对比表
| 特性 | DrQ Agent | VICE Agent |
|---|---|---|
| 主要任务 | 视觉表征学习(透彻理解图像) | 奖励函数自动生成(精准打分) |
| 核心技术 | 随机裁剪、平移(数据增强) | 基于正负样本的对抗学习 / 判别 |
| 解决的核心难题 | 图像噪声、过拟合、泛化能力不足 | 奖励函数难以手工设计、信号稀疏 |
| 在 SERL 中的定位 | 作为视觉主干(Backbone)的增强模块 | 作为自动裁判(Reward Classifier)的原型实现 |
0x03 DrQ:提升视觉强化学习的稳健性
真实机器人通常依赖图像观测。如果直接使用原始像素进行训练,视觉过拟合问题会非常严重。DrQ 的核心思想是对图像进行数据增强,例如随机裁剪,使策略不再记忆固定的像素位置,而是学习到更鲁棒的视觉特征。SERL 的DrQAgent在 SAC 基础上增加了图像增强功能和视觉编码器支持。
3.1 数据增强的重要作用
DrQ 最重要的特性是随机裁剪(random crop)数据增强。这一特性在真实机器人环境中尤为关键:
- 视觉正则化:阻止模型记忆绝对的像素位置,强迫其学习鲁棒的空间特征
- 对真实世界的适应性:真实环境中光照、背景、物体位置都会发生微小变化,数据增强使模型天然具备对这些变化的泛化能力
为什么 DrQ 在 SERL 中不可或缺?如果没有 DrQ 的数据增强,机械臂只要位置发生些许偏移,或者光照条件有所变化,强化学习任务就可能失败。DrQ 通过随机裁剪,使网络学会关注“物体本身”,而非“物体在图像中的绝对坐标”。在 update_high_utd 中可以看到,DrQ 在进行高 UTD 更新之前,会先执行一次数据增强。从细节来看,由于 batched_random_crop 是在 JAX 内部实现的,运行在 GPU 上,相比在 CPU 上完成增强后再传输给 GPU,这种设计显著节省了数据传输的开销。
论文实验中采用 ImageNet 预训练的 ResNet-10 作为视觉骨干网络,并连接到 MLP。观测数据包含相机图像和机器人本体信息,例如末端位姿、速度、力与力矩等。
3.2 视觉编码器的体系结构
3.2.1 EncodingWrapper(特征融合)设计
EncodingWrapper是 SERL 处理视觉和本体感知输入的核心封装组件:
- 支持多图像键(字典形式的编码器集合)
- 帧堆叠处理:
rearrange(image, "T H W C -> H W (T C)")和rearrange(image, "B T H W C -> B H W (T C)") - 本体感知融合:Dense 层 → LayerNorm → tanh 激活 → 拼接
stop_gradient支持:允许冻结视觉编码器- 将视觉像素信息与本体感知(如关节角度)进行拼接。视觉告诉我们物体在哪里,本体感知告诉我们手在哪里。“眼手协同”是精细操作的前提。
编码器选项:
- SmallEncoder:4 层卷积(32→64→128→256)+ Spatial Softmax + 瓶颈层
- ResNet-10(从零训练):10 层 ResNet + 空间可学习嵌入
- PreTrained ResNet-10:ImageNet 预训练且冻结 + 可训练汇聚头部
Spatial Softmax / Spatial Learned Embeddings是一个关键设计:它们将卷积特征图转换为空间坐标的加权期望值,在保留空间信息的同时大幅降低维度。相比全局池化,这种方法能更好地保留空间位置信息,对机器人视觉任务至关重要。
3.2.2 视觉-本体感知融合详解
在 SERL 中,观测数据结构如下:
observations = {
"image1": (T,H, W, C), # 相机1图像帧栈
"image2": (T,H, W, C), # 相机2图像帧栈
"state": (T, D), # 本体感受 (tcp_pose, tcp_vel, gripper, force, torque)
}
EncodingWrapper的处理流程如下:
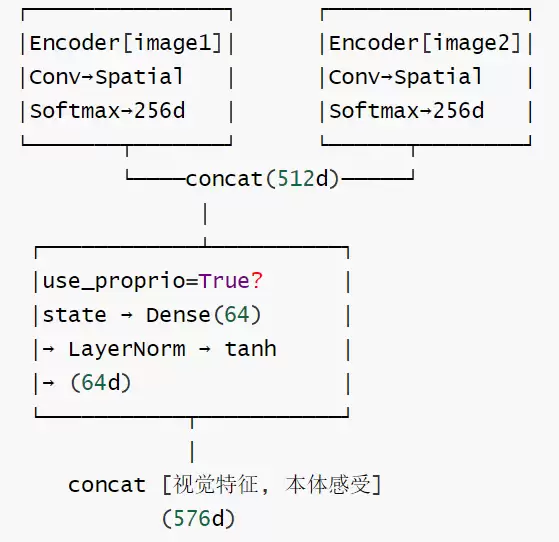
Late Fusion 设计:视觉和本体感受各自独立编码,最后进行拼接。这并非 Early Fusion,而是基于深刻的设计考量:
- 模态异质性:图像是 2D 空间信号,适合卷积处理;state 是 1D 向量,适合全连接层处理
- 梯度隔离:Late Fusion 允许对视觉编码器施加
stop_gradient,冻结视觉特征,仅训练本体感受分支 - 本体感受的 LayerNorm + tanh:state 各维度的量纲差异较大(位置 vs 速度 vs 力),归一化到统一尺度,并限制其范围以防止梯度爆炸
3.2.3 多任务接口预留
代码中预留了但尚未启用的多任务接口:
| 功能 | 状态 | |
|---|---|---|
| GCEncodingWrapper | 基于目标的条件:观测目标图像融合 | 代码存在但未被任何 Agent 使用 |
| LCEncodingWrapper | 基于语言的条件:观测语言指令融合 | 代码存在但未被任何 Agent 使用 |
这些接口为未来的多任务学习或条件策略扩展预留了空间。
3.3 算法核心实现
3.3.1 DrQAgent 网络架构
由于 DrQAgent 继承自 SACAgent,其网络架构基本相同,但存在以下关键差异:
| 特性 | SACAgent | DrQAgent |
|---|---|---|
| Actor架构 | 编码器 + MLP[256,256] | 相同 |
| Critic架构 | 编码器 + 集成 MLP[256,256]×2 | 相同 |
| 数据增强 | 无 | 随机裁剪(4像素填充) |
| 训练稳定性 | 标准 SAC | 增强处理用以提升泛化能力 |
3.3.2 编码器选择
DrQAgent 支持多种编码器类型:
- SmallEncoder:轻量级 4 层卷积网络
- ResNet-10:中等深度的 ResNet
- ResNet-10-Pretrained:ImageNet 预训练的 ResNet-10
3.3.3 async_drq_sim.py代码细节
以async_drq_sim.py为例,SERL 的训练流程采用典型的异步 actor-learner 架构:
1. Learner 初始化阶段:创建 TrainerServer,注册 replay buffer,等待数据填充
2. Actor 初始化阶段:创建 TrainerClient,连接 Learner
3. Actor 循环流程:
- 采样动作(前 N 步随机执行,之后采用策略)
- env.step()→ 收集 transition →data_store.insert()
- 定期执行client.update()→ 推送数据
- 定期执行evaluate()→ 发送统计信息
4. Learner 循环流程:
- 等待 buffer 填充至training_starts
- 发送初始网络参数给 Actor
- RLPD 50/50 采样策略:batch 中一半来自 demo_buffer,另一半来自 online replay_buffer
- 执行update_critics()× (UTD-1) 次 → 再执行update_high_utd(utd_ratio=1)× 1 次
- 定期通过server.publish_network()同步参数
- 通过 WandB 记录日志
这种异步架构使得机器人控制的高实时性要求与训练的高吞吐量要求得以解耦,互不干扰。
3.3.4 drq.py 逻辑流程图

3.3.5 drq.py 代码拆解
- 数据增强(data_augmentation_fn):这是 DrQ 的“灵魂”所在。它对 observations 中的每一个像素键(pixel_key)执行 batched_random_crop。其原理是:即便图像仅位移了 1-2 个像素,对神经网络而言也是全新的输入。这相当于为有限的数据池注入了活力,极大地提升了模型的泛化能力。
def data_augmentation_fn(self, rng, observations):
for pixel_key in self.config["image_keys"]:
observations = observations.copy(
add_or_replace={
pixel_key: batched_random_crop(
observations[pixel_key],
rng,
padding=4,
num_batch_dims=2
)
}
)
return observations
训练时,会对当前观测和下一观测进行数据增强。
def update_high_utd(self, batch, utd_ratio, pmap_axis=None):
# 训练时对观测和下一观测进行数据增强
rng, obs_rng, next_obs_rng = jax.random.split(rng, 3)
obs = self.data_augmentation_fn(obs_rng, batch["observations"])
next_obs = self.data_augmentation_fn(next_obs_rng, batch["next_observations"])
batch = batch.copy(
add_or_replace={
"observations": obs,
"next_observations": next_obs,
}
)
# 调用父类SAC的更新
return SACAgent.update_high_utd(new_agent, batch, utd_ratio=utd_ratio, pmap_axis=pmap_axis)
update_critics 方法中也有类似的调用:
def update_critics(self, batch, pmap_axis=None):
# 数据增强
obs = self.data_augmentation_fn(obs_rng, batch["observations"])
next_obs = self.data_augmentation_fn(next_obs_rng, batch["next_observations"])
# 仅更新Critic网络
new_agent, critic_infos = new_agent.update(
batch,
pmap_axis=pmap_axis,
networks_to_update=frozenset({"critic"}) # 只更新Critic
)
- 编码器选择(create_drq):它提供了灵活的配置选项:
- small:简单的卷积层,适合简单任务。
- resnet:标准的 ResNet-10,是 SERL 的主力方案。
- resnet-pretrained:加载预训练权重(通常为 ImageNet 预训练),适合复杂度较高的视觉场景。
- 选择较小模型的优势:在高 UTD 场景下,计算机通常受限于带宽和前向传播速度。如果模型过大,GPU 每秒无法完成那 20 次更新,整个训练过程可能从“20 分钟学会”变成“2 小时学会”。在机器人领域,实时性(Speed)往往比模型深度(Depth)更为关键。
- 随机种子(随机裁剪偏移量):在计算数据增强时,它对 observations 和 next_observations 使用两个不同的随机种子(obs_rng 和 next_obs_rng)。
- 使用不同种子的优势:如果 s 向左偏移,s' 向右偏移,会产生类似“抖动”的效果。这迫使网络理解:无论目标在图像中的哪个角落,无论视角如何晃动,动作与状态之间的物理逻辑始终不变。这极大地增强了策略的“空间不变性”。
- 使用相同种子的劣势:如果对 s 和 s' 使用相同的偏移量(例如都向左上角移动 4 像素),即使位置发生了变化,s 到 s' 的相对位置并未改变,机器人学到的将是一种“死板的平移”。
- 共享视觉编码器(Shared Encoder):在 create_drq 中,shared_encoder 默认设置为 True。如果设为 False(即 Actor 和 Critic 各自使用独立的视觉网络),其他势如下:
- 特征一致性:Actor 需要知道“杯子在哪里?”,Critic 需要判断“手抓到杯子的价值有多高?”。它们关注的是相同的物理特征。让它们共用一个 ResNet,犹如让两个学生共享一本最好的教科书。一个学生(Critic)学得快,他所理解的知识点会通过梯度回传,帮助另一个学生(Actor)也快速进步。
- 极速收敛:视觉特征的学习是强化学习中最慢的环节。由于 Critic 接收的是明确的奖励信号,其视觉头的训练速度通常快于 Actor。搭便车效应:Actor 直接使用 Critic 已经训练好的视觉特征,只需学习如何将其映射到动作即可。这能够节省 50% 以上的训练时间。
- 节省显存:ResNet 的显存占用较大。在 UTD=20 时,显存消耗非常显著。共用一个编码器可以腾出更多空间用于更大的 Batch Size。
0x04 VICE 详解
vice.py 是 SERL 中一个非常高级的组件,实现了 VICE(Variational Inverse Control with Events)算法。其核心任务是:当机器人缺乏明确的奖励信号时,通过观察“成功图片”来实现自我评分。这在真实机器人的部署场景中极其重要,因为现实世界中你无法编写一个完美的数学公式来判断“杯子是否抓稳了”。
VICE 通过将策略访问过的所有状态以负标签的形式添加到分类器的训练集中,并在每次迭代后更新分类器,从而解决该问题。这样,强化学习过程类似于生成对抗网络(GAN),其中策略充当生成器,奖励分类器则充当判别器。
4.1 背景与核心原理
VICE 是 RLPD 的“心跳”所在。在 train_rlpd.py 这类算法中,演示数据只是素材,而 VICE 生成的奖励才是灵魂。没有奖励,机器人就失去了进化的动力。
4.1.1 动机:为何需要 VICE?
在仿真环境(如 MuJoCo)中,奖励函数很容易编写:奖励 = - 距离。但在真实世界中:你如何得知机械臂末端距离杯子还有几厘米?(除非安装了极其昂贵的外部捕捉系统)。你又如何判断线缆是否已经进入槽位?
VICE 的思路是:人类只需向机器人展示几张“任务成功”的照片(Goal Images),剩下的让机器人自己去领悟。
4.1.2 变分推断(Variational Inference)
变分推断是一种“用简单模型逼近复杂真相”的方法。其核心逻辑是:真相过于复杂,无法直接计算——就像你(未经美术训练)无法直接画出某位美女的真实容貌;构建一个简化模型——用简单的几何形状(椭圆、柳叶眉、杏仁眼)构建一个“标准模型”;调整模型参数——根据观察到的线索,不断调整模型的参数(脸型的长宽比、眉毛的弧度等);优化目标——让简化模型“最好地解释观察到的线索”;结果——简化模型虽非真容,但已非常接近。
一句话总结:变分推断就是“用一个可调节的简化模型,去逼近一个复杂但无法直接计算的真相”。
贝叶斯推断的困境
在贝叶斯统计中,我们想要计算后验分布:p(z|x) = p(x|z) * p(z) / p(x)。其中:z 是隐变量(例如女子的真容),x 是观测数据(例如你看到的线索),p(x|z) 是似然(给定真容,看到线索的概率),p(z) 是先验(对真容的初始假设),p(x) 是证据(看到线索的总概率)。问题在于:p(x) 需要对所有可能的 z 进行积分,这在复杂模型中几乎无法计算。
变分推断的解决方案
既然无法直接计算 p(z|x),那就用一个简单的 q(z) 来逼近它。目标:找到最佳的 q(z),使其尽可能接近 p(z|x)。ELBO = E_q[log p(x,z)] - E_q[log q(z)],最大化 ELBO 等价于最小化 q(z) 和 p(z|x) 之间的 KL 散度。
4.1.3 VICE 原理
VICE 是一种“从专家示范中学习评判标准”的方法。VICE 并非教你“如何行走”,而是教你“什么才算走到了目的地”。一旦你明确了目的地的特征,你自然就知道该往哪个方向努力了。
它的核心逻辑是:不直接学习“怎么做”,而是学习“什么才算做好”——你不需要告诉机器人具体操作步骤,也不需要提供完整的示范路径。通过观察大量专家示范(成功案例)和非专家示范(失败案例)——你只需给它展示一堆“成功长什么样”的图片(goal state examples)。“事件”的定义来自于你提供的成功状态样本,并不需要完整的示范轨迹。利用变分推断训练一个分类器,输出“当前状态是成功状态的概率”,以此作为奖励信号。然后用这个分类器来评估“这个状态有多像成功”,将这个“像成功的概率”作为奖励信号,来训练强化学习。目标不再是“最大化累积分数”,而是“让某个事件(event)发生的概率最大化”,事件发生的关键状态越多,奖励就越高。
4.1.4 对抗性进化:猫鼠游戏
VICE 将强化学习转变为一个“博弈游戏”。
- 准备正样本:你手动将机器人摆放到成功位置,拍摄 20 张照片。这些照片的标签设为 1。
- 准备负样本:机器人在环境中自主探索时拍摄到的照片。这些照片的标签设为 0。
- 训练判别器:训练一个二分类神经网络(Binary Classifier),输入一张图像,输出“它看起来像成功照片的程度”。
- 生成奖励:Reward = Classifier(当前图片);机器人会发现:“只要我执行的动作让画面越来越接近那 20 张照片,我的得分就越高。”
VICE 实际上是一个类似 GAN 的结构:分类器(猫)努力区分“真正的成功”和“机器人自以为成功的动作”;机器人(鼠)努力做出让分类器认为是“成功”的动作。随着训练的持续,分类器变得越来越挑剔,机器人也随之变得越来越精准。
如果 VICE 出现故障:在线试错的数据被 VICE 判定为 0,人类演示的数据也被 VICE 判定为 0。结果:Critic 只能接受这个事实——“这个世界没有奖赏,做什么都是徒劳”,Q 网络随之萎缩至 0。此时,Actor 唯一的方向指引只剩下那个额外的 BC Loss。因此,在 VICE 失效的情况下:如果没有 BC Loss,机器人会彻底失去方向;如果有 BC Loss,机器人会退化成一个笨拙的模仿者,不再具备进化的动力。
4.2 网络架构设计
VICE Agent 在标准的 Actor-Critic 架构基础上增加了基于视觉的奖励分类器,实现了从人类演示到稀疏奖励的迁移学习。
| 组件 | 编码器 | 主干网络 | 输出 | 特殊设计 |
|---|---|---|---|---|
| Actor | SmallEncoder/ResNet | MLP [256,256] | 动作分布 | tanh_squash |
| Critic | 共享Actor编码器 | 集成 MLP [256,256]×2 | Q值 | 双Critic |
| Temperature | 无 | Lagrange 乘子 | 标量温度 | 自动调节 |
| VICE Classifier | 独立编码器 | MLP [256] | 二分类logit | 预训练 + 微调 |
核心组件架构如下:
Actor 网络:
policy_def = Policy(
encoder=encoders["actor"], # 视觉编码器
network=MLP(**policy_network_kwargs), # [256, 256]
action_dim=actions.shape[-1],
tanh_squash_distribution=True,
std_parameterization="uniform",
)
Critic 网络:
critic_backbone = partial(MLP, **critic_network_kwargs) # [256, 256]
critic_backbone = ensemblize(critic_backbone, critic_ensemble_size)(
name="critic_ensemble" # 默认2个Critic
)
critic_def = partial(Critic, encoder=encoders["critic"], network=critic_backbone)
Temperature 网络:
temperature_def = GeqLagrangeMultiplier(
init_value=1.0,
constraint_shape=(),
constraint_type="geq", # 大于等于约束
)
VICE Reward Classifier:
vice_def = BinaryClassifier(
pretrained_encoder=pretrained_encoder, # 预训练ResNet
encoder=vice_encoder_def, # 独立的编码器
network=MLP(**vice_network_kwargs), # [256]
enable_stacking=True,
)
另外,VICE 使用独立的编码器。
# VICE使用独立的编码器
vice_encoders = {
image_key: SmallEncoder(
features=(32, 64, 128, 256),
kernel_sizes=(3, 3, 3, 3),
strides=(2, 2, 2, 2),
padding="VALID",
pool_method="a vg",
bottleneck_dim=256,
spatial_block_size=8,
name=f"vice_encoder_{image_key}",
)
for image_key in image_keys
}
4.3 奖励(Reward)的计算方式
在 VICEAgent 中,奖励的计算依赖于一个学习到的二分类器(即 vice 网络),该网络用于区分专家/目标状态与智能体的观测。具体计算过程如下:
- 前向传播与 Sigmoid 激活:将 next_observations 输入 vice 网络(一个 BinaryClassifier),并通过 sigmoid 函数将输出映射为 0 到 1 之间的概率分数。此过程由 vice_reward 方法实现:
rews = nn.sigmoid(
self.state.apply_fn(
{"params": self.state.params},
observation,
name="vice",
train=False,
)
)
- 二值化(阈值截断):在 Critic 更新阶段(如 update_critics 和 update_high_utd 方法中),连续的概率分数会被转换为离散的二值奖励。若概率分数大于或等于 0.5,则奖励设为 1.0,否则为 0.0:
rewards = (self.vice_reward(next_obs) >= 0.5) * 1.0
- 数据增强:在计算奖励前,会先通过 data_augmentation_fn 对 next_observations 进行数据增强,以提升奖励信号的鲁棒性。
- 总结:奖励本质上是一个二值指标(1.0 或 0.0),其取值取决于 vice 分类器是否将 next_observation 判定为属于目标/专家状态分布(即 sigmoid 输出的概率 ≥0.5)。
4.4 训练逻辑与流程
在 VICEAgent 中,BinaryClassifier(在代码中实例化为 vice 网络)的训练逻辑主要集中在 update_vice 方法中。其训练过程使用二元交叉熵(BCE)损失,并引入了 Mixup、标签平滑(Label Smoothing)和梯度惩罚(Gradient Penalty)等正则化技术来防止 GAN 模式崩溃。
具体训练步骤如下:
数据准备与标签平滑(Label Smoothing): - 假设 batch 的后半部分为目标图像(正样本,标签为 1),前半部分为普通观测(负样本,标签为 0)。 - 对图像进行数据增强(通过 data_augmentation_fn),并将原始图像与增强后的图像拼接。 - 应用标签平滑技术处理标签:y_batch = y_batch * (1 - 0.2) + 0.5 * 0.2,以缓解大 logits 带来的数值问题。
特征编码: - 使用 encode_images 方法将拼接后的所有图像通过 encoder 提取为特征向量(embeddings)。
Mixup 正则化: - 在特征空间中对 embeddings 和标签进行 Mixup 操作(通过 mixup_data_rng),生成混合特征 mix_encoded 和对应的混合标签。 - 定义 mixup_loss_fn,计算混合特征通过 create_classifier 初始化网络权重后的 BCE 损失:bce_loss = λ_θ * bce_loss_a + (1 - λ_θ) * bce_loss_b。
梯度惩罚(Gradient Penalty): - 在 Mixup 生成的特征之间进行随机插值,生成用于计算梯度惩罚的数据 gp_encoded。 - 定义 gp_loss_fn,计算 BinaryClassifier 对 gp_encoded 输出的梯度。 - 计算梯度惩罚项:grad_penalty = mean((grad_norms - 1) ** 2)。 - 最终的总损失为:bce_loss + 10 * grad_penalty。
参数更新: - 构建 loss_fns 字典,将 gp_loss_fn 指定给 vice 网络,其他网络(actor, critic, temperature)的损失设为 0。 - 调用 new_agent.state.apply_loss_fns 执行梯度计算,并使用对应的优化器更新 BinaryClassifier 的参数。
总结: BinaryClassifier 是在特征编码空间中进行二分类训练的,并通过 Mixup 和梯度惩罚来平滑决策边界,从而提高 VICE 奖励信号的稳定性和鲁棒性。
4.5 流程图解
在 SERL 的流程中:当你向机器人提供动作示范时,你给出的只是一系列动作序列。当这组数据被存入 demo_buffer 时,其 reward 字段通常并非由你手动输入。那么它是如何被标注的?在 train_rlpd.py 中,当你采样出一个 Batch(包含演示数据)时,系统会执行以下逻辑:
- 获取图像:取出演示数据中的那一帧图片 s。
- 通过分类器:将图片 s 输入 VICE 分类器。所有数据(无论由谁生成)都必须经过 VICE 的“安检”。只有 VICE 判定为成功,该数据才算成功。
- 重新评分:分类器返回一个分数(例如 0.95)。
- 填入 r:这个 0.95 就成为该条演示数据在当前时刻的奖励 r。
VICE Agent(自奖励分类器)流程图如下:
- Mixup 与标签平滑:应对极少量样本(可能仅有几十张成功图片)带来的过拟合问题。
- 梯度惩罚 (GP):借鉴 GAN 的技巧,确保奖励函数不仅准确,而且梯度连续,有利于强化学习优化。
- 无需复位:允许机器人在缺乏外部传感器(如压力传感器、红外对管)的情况下,仅凭视觉确认任务是否完成。

4.6 工程实现与防崩坏细节
4.6.1 分类即奖励(vice_reward)
在 sac.py 或 rlpd.py 的运行过程中,VICE 的核心合作伙伴是 Critic。它们的协作方式如下:环境提供一张图 s';VICE 随即判断:“根据我的评估,这张图值 0.8 分”;Critic 拿着这个 0.8 分,代入贝尔曼公式:Q = r + γ Q_next;Actor 看到 Q 值很高,就知道刚才的动作是正确的,以后应多执行。
VICE 本质上就是一个“奖励函数生成网络”,它判断的是当前瞬间的好坏,将“判断任务是否成功”转换成了一个二分类问题。其逻辑是:如果当前画面 s' 在分类器看来与成功画面很相似,Sigmoid 输出接近 1.0,机器人就能获得高分。
def update_critics(
self,
batch: Batch,
*,
pmap_axis: Optional[str] = None,
) -> Tuple["DrQAgent", dict]:
rewards = (self.vice_reward(next_obs) >= 0.5) * 1.0
batch = batch.copy(add_or_replace={"rewards": rewards})
解读:VICE 会在每次更新之前,实时改写 Batch 里的奖励字段。它将连续的概率值转换为 0/1 的二值奖励。这意味着只要机器人将物体放到了“看起来成功”的位置,它就能立刻获得 1 分。
类比:VICE 就像你体内的“多巴胺”——当你看到巧克力(成功图片),大脑立刻分泌多巴胺,告诉你“这个瞬间真棒”。Critic 则像是你的“理财顾问”——它根据你当前的多巴胺水平,预测你这辈子最终能否获得幸福。
4.6.2 策略与效果
VICE 的优越性:作为一个深度网络,它学到的是“特征空间的相似性(比如插头和插座的咬合关系)”,这种特征具有极强的泛化能力和抗噪声能力。为什么像素差异不可行?因为物理上的“像素差异”和语义上的“任务成功”完全是两回事。举例:插头距离插座 1 厘米,与插头插入但偏了 1 厘米,像素差异可能很小,但物理状态(成功 vs 失败)却截然不同。
SERL 的策略:通常会先利用之前提到的行为克隆(BC)让机器人做出一些看起来像样的动作,从而为 VICE 提供高质量的“正样本”和“对比样本”。只有评价体系稳定了,强化学习的高速更新(UTD=20)才有实际意义。
4.6.3 工程上的“防崩盘”设计
直接训练分类器在强化学习中很容易崩溃。例如:机器人可能发现只要在摄像头前晃动一下手臂、挡住背景,画面特征就与成功照片非常相似(这被称为 Reward Hacking)。update_vice 函数采用了几个关键技巧来应对这一问题:
- Mixup(数据混合):将图片按比例混合。这防止了分类器只记住几张特定的、死板的图片。例如,它不只简单区分“成功”和“失败”,而是将两张图按比例重叠。用意:让分类器的判断标准不再是非黑即白,而是产生一个平滑的过渡区域,引导机器人逐步靠近目标。
- Label Smoothing(标签平滑):不给满分 1.0,只给 0.9 分。如 y_batch = y_batch * (1 - 0.2) + 0.5 * 0.2。将 1 变为 0.9,将 0 变为 0.1。这使得奖励信号不会过于极端。用意:防止分类器产生极大的梯度,从而“吓跑”机器人。
- Gradient Penalty(梯度惩罚):强制要求分类器的输出对输入的变化是平滑的。惩罚权重的剧烈波动。这使得奖励函数的等高线变得平滑,Actor 沿着梯度方向往上爬时不会“脚滑”。用意:如果奖励函数像悬崖一样陡峭,Actor 根本找不到向上爬的方向。它需要的是一个温和的“斜坡”。
0xFF 参考资料
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:SERL算法篇让机器人真机强化学习从难用到可复现要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Daetama是面向数据科学面试和SQL能力提升的练习平台,已收录超100个覆盖基础到进阶的SQL题目,求职板块与课程模块在开发中,团队保持每周更新节奏,提供系统性刷题与模拟面试场景。
SpeakMulti是一款AI驱动的配音平台,可将YouTube视频翻译成多种语言,保留原始说话者的音色和语调,降低本地化成本。用户提交视频并选择目标语言后,AI自动完成配音,并由专家团队审核,确保准确自然。
需求人群 如果你经常需要从图片中提取文字——例如整理截图内容、翻译图片里的外语文本、识别带有水印的图片信息——那么 Umi-OCR 无疑是一款相当实用的工具。它完全在本地运行,无需联网,对隐私保护极为友好。 产品特色 这款工具的核心亮点都集中在实用性上。截屏识别操作非常顺手,按下快捷键即可框选区域,
艺术创作与人工智能的融合,正在开启一个全新的创作时代。moonlightai 正是这样一款AI绘画工具,能够帮助用户通过人工智能快速生成不同风格的绘画作品——无论你想复刻文艺复兴时期的古典优雅,还是为画作注入梵高般炽热的笔触,甚至从艾沃佐夫斯基的海浪星空中汲取灵感,它都能轻松实现。 需求人群 简单来
- 日榜
- 周榜
- 月榜
热点快看