




视频生成模型真会推理?303题全面揭示世界模型推理短板

视频生成模型近年来已成为人工智能领域最炙手可热的赛道之一。从Sora、Veo到Kling、Seedance,这些模型生成的画面逼真得令人惊叹,在动态场景模拟与物理规律复现方面也屡屡带来惊喜。越来越多的迹象表明,它们似乎已从海量视频数据中悄然习得一种“世界模型”——即对现实世界运行逻辑的内在理解。 然
视频生成模型近年来已成为人工智能领域最炙手可热的赛道之一。从Sora、Veo到Kling、Seedance,这些模型生成的画面逼真得令人惊叹,在动态场景模拟与物理规律复现方面也屡屡带来惊喜。越来越多的迹象表明,它们似乎已从海量视频数据中悄然习得一种“世界模型”——即对现实世界运行逻辑的内在理解。
然而,一个关键问题长期被忽略:当模型生成一段看似“合理”的视频时,它是否真的在逐帧进行连贯推理?抑或只是碰巧渲染出一个正确的结果,背后却缺乏真正的逻辑链条?
我们将这一维度正式定义为推理一致性(Reasoning Coherence):即在生成的视频中,事件与事件之间能否在帧与帧之间保持因果可信性与演化连贯性。
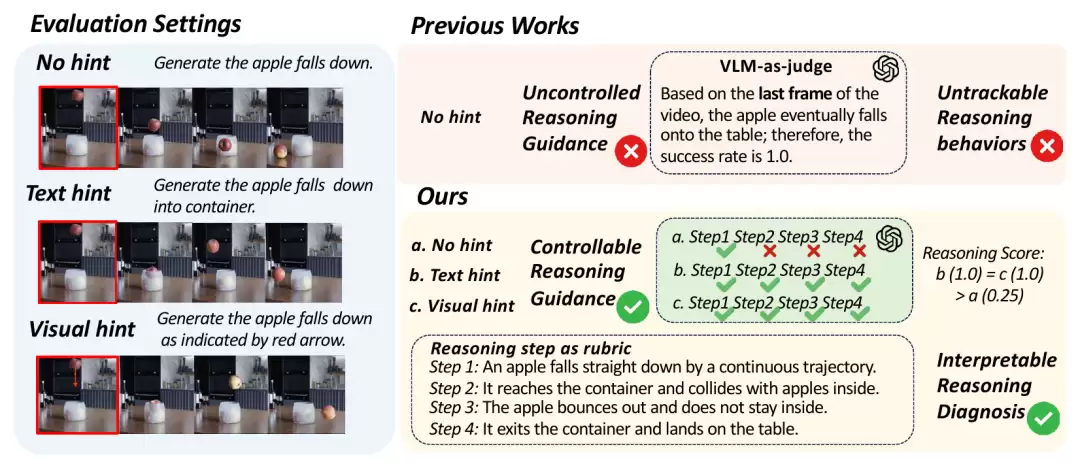
事实上,已有部分研究开始评估视频模型的推理能力,但大多存在局限。有的仅凭“最后一帧”判断结果对错,有的只检验单一物理现象是否合理。这些方法均未触及“推理一致性”的核心,自然也回答不了那个根本问题:模型究竟在推理链的哪一步出现偏差,才导致整个任务失败?
MME-CoF-Pro 基准:将推理过程层层拆解
该团队先前已提出MME-CoF(被CVPR 2026 Findings接收),这是首个系统研究视频模型“帧链”(Chain-of-Frame)推理潜力的工作,覆盖12个维度。
如今,被ECCV 2026接收的MME-CoF-Pro在此基础之上实现了全面升级。类别从12个扩展至16个,将之前的粗粒度定性评估升级为经人工校验的过程级推理分数(Reasoning Score),更重要的是,它首次将“推理引导”——即文字与视觉提示——作为一个可控变量纳入评测体系。

- 论文: https://arxiv.org/abs/2603.20194v1
- 项目主页: https://video-reasoning-coherence.github.io/
- Huggingface: https://huggingface.co/datasets/yqi19/mme-cof-pro
- GitHub: https://github.com/yqi19/MME-CoF-Pro
该研究由美国东北大学、香港中文大学、北京大学与NVIDIA合作完成。MME-CoF-Pro堪称里程碑:它是业界首个将“推理引导”作为显式可控变量,并在过程层面评估视频推理一致性的基准,同时提供极为细粒度的错误原因分析与有意义的机理发现。
数据构成:精心设计,逐层递进
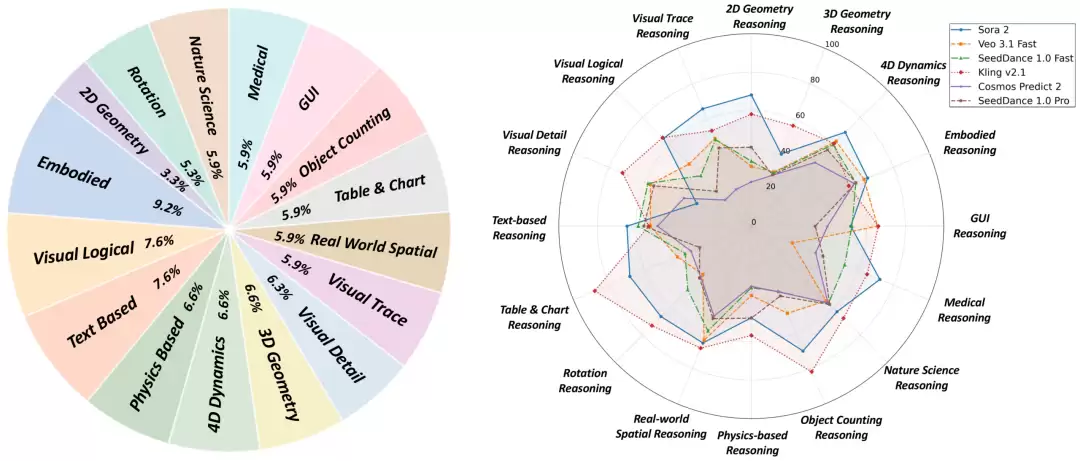
MME-CoF-Pro包含303个精心策划的图像-文字-视频推理样本,共计370张图像,覆盖16个推理类别。这些样本从27个现有真实与合成基准中筛选构建,并经领域专家三轮人工校验,质量可靠。
这16个类别并非简单堆砌,而是被组织为四大能力组,从底层感知逐步递进至高层任务推理:
- 感知推理: 视觉细节、旋转、物体计数。
- 空间与结构推理: 视觉轨迹、真实世界空间、2D/3D几何。
- 物理与因果推理: 物理规律、4D动态、自然科学。
- 任务导向推理: 具身操作、GUI交互、医学影像、表格图表、文本/代码、视觉逻辑。

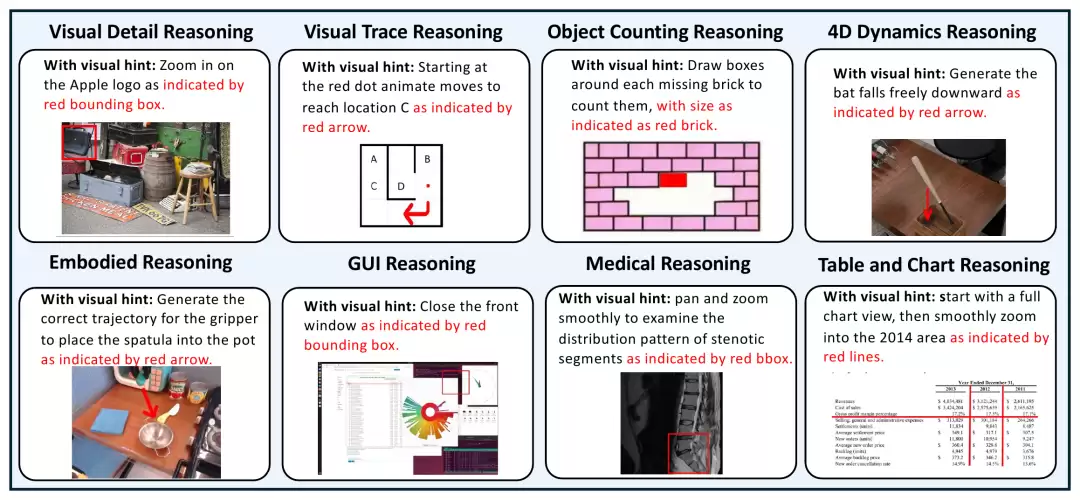
与以往最大的不同在于,MME-CoF-Pro将“推理引导”作为可显式控制的变量。每个样本提供“无提示”与“文字提示”两种设置;其中8个感知要求最高的类别(称为MME-CoF-Pro-mini)还额外包含“视觉提示”。除提示部分外,其他指令完全一致:
- 无提示: 标准设置,模型仅凭任务指令独立推理。
- 文字提示: 在指令中补充关键推理步骤的文字描述。
- 视觉提示: 在输入图像上绘制边界框、箭头或轨迹来引导。
由于仅提示部分变化,其余条件完全相同,任何性能差异均可因果地归因于推理引导本身,为研究提供了极佳的实验控制。
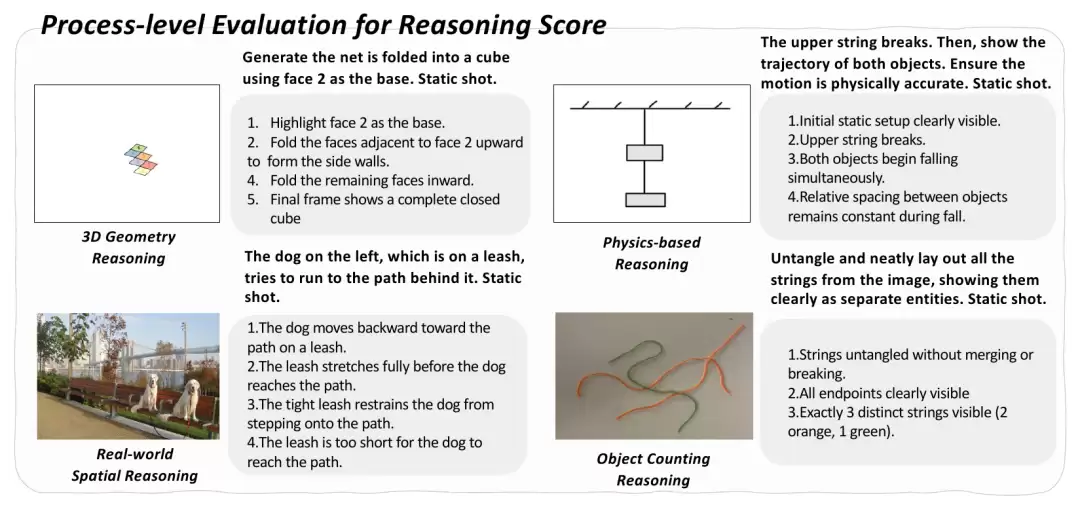
Reasoning Score:直击推理链路的“解剖刀”
传统评测仅关注生成质量,如同只盯着学生考试分数,却不关心解题过程是否合理。为此,作者提出过程级指标——Reasoning Score(RS)。具体做法:为每个样本标注一串经人工校验的关键推理步骤,每一步都是正确生成必须命中的“检查点”;RS即被正确完成的步骤比例,由判别模型(Gemini-2.5-Flash)逐步独立判定。
这不再是“答对/答错”的二值判断,而是能精准定位模型在推理链的哪一步崩溃,并支持在不同模型之间进行可靠比较。这正是评估中真正需要的方法。
测评实验:几个令人意外的发现
实验部分,作者全面评测了7个最强的闭源与开源视频生成模型:Veo-3.1、Veo-3.1-fast、Sora-2、Seedance-1.0-pro、Seedance-1.0-fast、Kling-v2.1与Cosmos-Predict2-14B,并在三种提示设置下系统对比。结果颇为出人意料。
发现一:视频生成模型普遍缺乏强推理能力,且推理能力与生成质量几乎完全解耦。
即便表现最好的Veo也仅得56分,Sora只有50分,其余模型明显落后——最强也只是勉强超过50。更值得警惕的是:高画质绝不等于会推理。以Kling为例,其综合生成质量评分高达65.1,但Reasoning Score却低至13.8。它能惟妙惟肖地渲染风吹树林的动态,却完全没有遵循“逐渐放大并寻找手提包”的推理指令。这说明,推理与生成质量是两种相互独立的能力。

发现二:文字提示是一把双刃剑——看似提分,实则诱发幻觉,损害一致性。
多数模型加入文字提示后,RS确有提升(Veo-3.1 +4.5、Sora-2 +7.6、Cosmos +6.7),但代价是7个模型的一致性分数几乎全线下降。尤其在4D Dynamics类别上,7个模型的CS全部降低(-1.2到-15.6)。模型的反应往往是:它只是在“照本宣科”地执行字面指令。例如,为了满足“运动”指令,可能凭空“分裂”出一个多余物体来。显式提示更像是在转移注意力,而非真正增强对任务的理解。
发现三:视觉提示并非万能,对精细感知任务甚至会帮倒忙。
视觉提示在结构化、需要空间引导的任务(如具身操作、GUI交互)上确实有效,但在视觉细节、物体计数这类精细任务上却拉低了成绩。比如在Visual Detail类别中,Veo-3.1的RS下降13.0,CS下降14.4。更有趣的是,模型常将视觉提示“画进”画面——指示方向的箭头被当作物体渲染成弯曲轨迹。作者推测这源于训练数据的偏差:标注箭头或高亮通常与合成内容共同出现,模型便将“引导”误认为“内容”。
案例研究:提示越多,推理就越好吗?
一个自然的问题是:不断增加提示信息,能否单调地提升推理表现?作者在Frozen Lake任务上,使用Sora-2做了一组渐进式缩放实验。
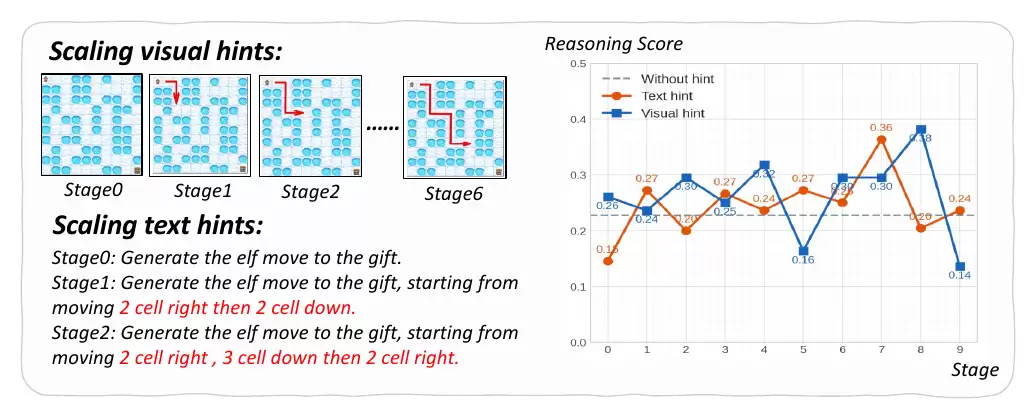
结果表明,虽然文字与视觉提示带来的推理分数普遍高于无提示基线(0.23),但两条曲线在各阶段剧烈波动,并无清晰上升趋势。这说明当前模型无法以累积方式稳定地利用越来越详细的提示信息。简单堆叠提示并不能保证推理表现提升。这也指向一个开放问题:如何让视频模型将多步提示稳定地转化为连贯的推理轨迹。
人类研究:Reasoning Score究竟靠不靠谱?
为验证RS能否有效、独立地刻画视频推理能力,作者邀请了10位标注者对随机抽取的视频按标注步骤打分,并与现有指标对比。
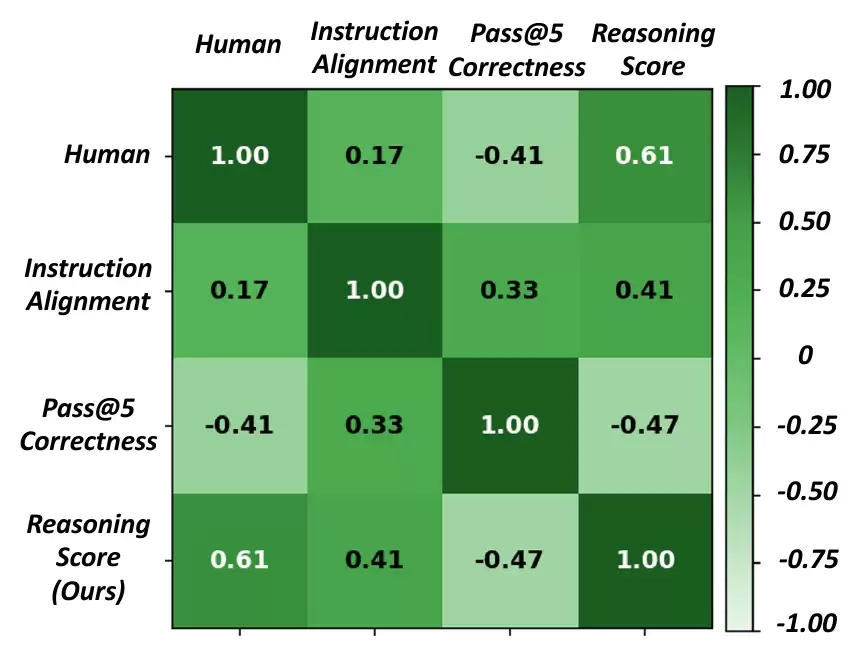
结果显示,Reasoning Score与人工评分的Spearman相关性高达0.61,大幅超越Instruction Alignment(0.17),与Pass@5 last-frame correctness则呈负相关(-0.41)。这充分表明,RS比现有指标更能捕捉人类视角下的推理行为,是评估推理一致性的有效工具。
结语:通往真正世界模型的路还很长
本文系统评测了主流视频生成模型在推理一致性上的真实水平,提出过程级指标Reasoning Score,并通过文字/视觉提示的可控对比,深入分析了模型的失败模式与作用机理。
核心结论令人深思:当前的视频生成模型更多是在“跟随”提示,而非真正“理解”并应用世界规律。在通往真正世界模型推理的道路上,更强的视觉对齐能力、指令理解能力与抗幻觉机制仍是必须攻克的方向。这些发现无疑为视频生成模型与世界模型的未来迭代提供了极具价值的参考。