




所有AI都在理解世界,这家公司却在理解你

5月底,一家名为Clipto AI的企业发布了一款端侧产品,上线首日便斩获Product Hunt全球第一。该产品是一款多模态搜索工具,用户只需用自然语言输入一句话,就能在数TB的视频、音频、图片和文档中精准定位所需内容。然而,Clipto的愿景远不止于搜索。过去几年,大模型在生成能力上取得了飞跃式
5月底,一家名为Clipto.AI的企业发布了一款端侧产品,上线首日便斩获Product Hunt全球第一。该产品是一款多模态搜索工具,用户只需用自然语言输入一句话,就能在数TB的视频、音频、图片和文档中精准定位所需内容。
然而,Clipto的愿景远不止于搜索。
过去几年,大模型在生成能力上取得了飞跃式进展——写代码、绘图、制作视频,内容生产的效率被推升至前所未有的高度。但与此同时,另一个问题却日益突出:人们创造和存储的数据越来越多,反而越来越难以被重新利用。电脑里堆满了会议录音、直播回放、播客访谈、采访素材、项目文档和截图。对于记者、创作者、律师、研究员这类知识工作者而言,真正消耗时间的往往不是生产内容,而是从海量素材中检索出想要的信息。
在Clipto创始人康洪文看来,这暴露的并非单纯的搜索问题,而是AI缺失了一层关键基础设施。他将这层基础设施称为Memory Layer(记忆层)。AI一直在构建世界模型,却缺少用户模型;智能体越来越聪明,但因为缺失记忆,始终无法真正理解用户。
而从视频理解研究,到AIGC创业,再到如今押注AI记忆层,康洪文过去二十年的经历,某种程度上也对应着AI技术演进的一条隐藏主线:从理解内容,到生成内容,再到组织内容。
从搜索工具到记忆层:Clipto试图解决什么痛点?
在康洪文的定义中,Clipto并非一款简单的多模态搜索工具,而是连接个人数据与智能体生态的“记忆层”。“过去十年,AI一直在构建世界模型,但缺少用户模型。每个人的数据都散落在自己的设备中,尚未转化为AI可以持续理解和调用的个人上下文。”他这样概括行业的空白,“如果没有长期记忆,再聪明的智能体也无法真正理解用户。搜索只是起点,Clipto的最终目标是打造AI时代缺失的记忆层。”
Clipto给出的解决方案,是一套完全在本地运行的多模态记忆构建逻辑:用户将本地的视频、音频、图片和文档等多模态数据导入后,系统会依托设备自身的AI算力与自研端侧多模态大模型,对所有文件完成感知理解、结构化解析与向量化处理,最终构建起含有认知图谱、实现时空对齐的个人记忆系统。
实际使用时,用户只需用自然语言描述需求,端侧大模型会先完整解析查询的意图与上下文,再通过本地搜索智能体在数秒内完成精准定位——无论是特定人物、场景、对白,还是完整的事件段落,都能直接命中对应的文件与时间点。
不止于检索召回,Clipto真正打通了底层大模型与上层智能体之间缺失的记忆通路。在TB级的私有数据之上,用户可以以对话形式提问,让AI回答任何与本地记忆相关的问题,或基于已有内容自动生成摘要、总结与内容梳理。
而所有这些运算与处理,全程都不会离开用户的本地设备。这一方面省去了海量数据上传、调用云端模型产生的高额Token成本;另一方面,对于包含商业机密、敏感信息的工作素材,以及移动办公、断网等特殊场景,数据不出设备本身就是一道刚性的安全与可用性门槛。
康洪文认为,过去的软件更多解决的是“存储”问题,却没有真正理解内容。Clipto的核心,就是利用本地多模态模型把视频、音频、图片和文档转化为AI能理解的数据结构,让用户从“搜索文件”变成“搜索记忆”。在他看来,搜索只是第一步,更重要的是建立一套能够持续积累个人上下文的Memory Layer。过去十年,AI构建的是关于世界的知识库;未来,AI需要进一步理解每个用户的个人知识和经历。
二十年:从视频理解到视频生成
从履历来看,康洪文几乎参与并见证了过去二十年AI从研究走向产业化的几个重要阶段。
2004年,他进入微软亚洲研究院实习。那时距离深度学习浪潮还有多年,AI更多时候还属于实验室里的研究课题。他参与的项目之一,是帮助Xbox自动分析用户拍摄的大量家庭照片和视频,再从数小时素材中自动提取关键片段,最终生成一段家庭短片。今天听起来似乎稀松平常,但在当时,这几乎已经触碰到了计算机视觉最核心的问题——因为机器必须先理解内容,才能生成内容。它需要知道谁出现了、发生了什么、哪些画面重要、哪些画面可以被忽略。
后来康洪文前往卡内基梅隆大学攻读博士,师从计算机视觉领域传奇学者Takeo Kanade。在那里,他继续研究图像与视频理解,希望让机器人能够通过持续积累视觉经验来理解现实世界。在很多人眼里,视频是一段画面,但视频本质上是一种关于时间、人物、事件和关系的复杂信息结构。理解视频,本质上是在理解现实世界。
2017年,康洪文创办慧川智能,随后推出文字生成视频平台智影。此时移动互联网和短视频行业开始高速增长,大量内容创作者进入市场。新的问题出现了——过去的问题是机器看不懂内容,现在的问题是内容生产效率太低。于是康洪文开始把技术重心从理解延伸到生成。文字生成视频、智能剪辑、数字人……这些后来成为AIGC热门赛道的方向,当时都已经出现在智影的产品探索中。
2020年底,智影被腾讯收购。康洪文加入腾讯,负责腾讯智影团队,继续推动文生图、文生视频和数字人等全栈AIGC产品研发。如果按照行业逻辑继续发展下去,他完全可以继续押注生成式AI。但真正让他产生新思考的,恰恰是生成能力的爆发。当生成越来越容易的时候,一个新的问题开始浮现。内容越来越多了,人们开始拥有海量视频、海量录音、海量文档。新的瓶颈变成了管理。AI解决了创造内容的问题,却没有解决理解个人内容的问题。当越来越多的信息被记录下来,人们反而越来越难找回自己需要的信息。这让他意识到,也许行业忽略了一个更底层的问题:在生成之前,需要理解;在理解之后,还需要记忆。而AI的下一步,可能正是记忆。
AI的下一层竞争,为什么会是Memory
在康洪文看来,智能体真正走向成熟之前,还有一个问题必须先解决——记忆。今天的大模型已经足够聪明,它们能够写代码、做分析、生成报告,甚至替用户完成部分工作流程。但无论模型能力多强,它始终存在一个天然缺陷:它不了解用户。每次打开一个新的AI产品,都像是在和一个失忆的人重新认识——你需要重新介绍自己是谁、正在做什么、过去做过什么。而一旦对话结束,这些上下文又会消失。
整个AI基础设施缺失了一层关键能力——缺少用户模型。今天的大模型拥有互联网上几乎所有公开知识,却无法真正理解一个具体的人。因为关于这个人的数据并不在互联网上,它们散落在电脑、手机、NAS、网盘、相机、会议记录和各种本地设备之中。对于AI来说,这些信息几乎处于不可见状态。而当智能体开始大规模普及后,这个问题会变得更加明显。今天大家讨论智能体,更多是在讨论它能够帮助用户完成什么任务。但如果未来真的出现数百万甚至数亿个智能体,那么新的问题也会随之出现:这些智能体如何理解用户?它们如何知道用户过去做过什么?又如何共享同一套个人上下文?
康洪文认为,不可能每一个智能体都重新构建一套用户记忆,这既不现实也没有必要。更合理的方式是存在一个独立的Memory Layer。智能体负责执行任务,Memory Layer负责管理用户记忆,所有智能体都能够基于这套统一记忆系统理解用户。这有点类似互联网时代的操作系统——应用程序越来越多,但底层文件系统只有一个。今天的智能体生态,或许也需要一个类似的记忆系统作为公共基础设施。这也是Clipto希望扮演的角色。
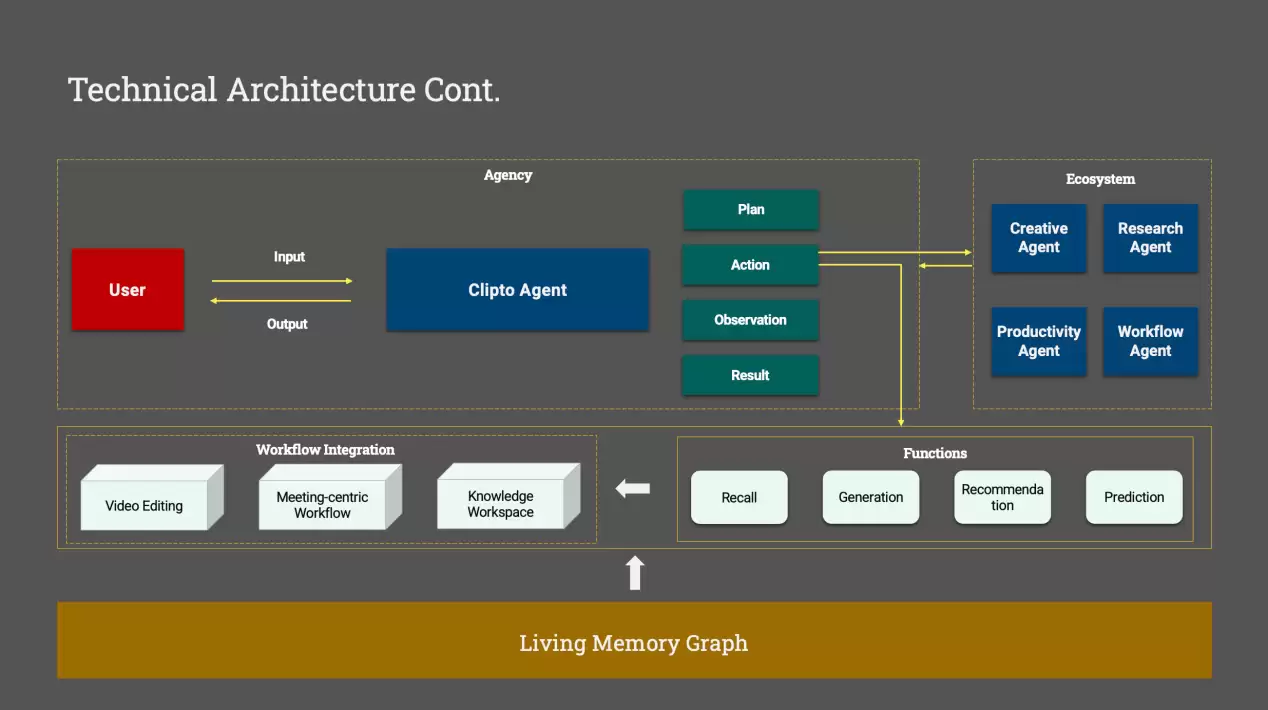
Living Memory Graph
在康洪文的判断里,未来的AI架构很可能会形成两层基础设施:一层是Intelligence Layer,负责理解世界;一层是Memory Layer,负责沉淀用户的个人知识、上下文和长期记忆。前者主要由云端大模型提供世界知识,后者则建立在用户持续产生的个人数据之上。两者共同构成真正意义上的Personal AI。这也是为什么他并不认为所有AI能力最终都会迁移到云端。
过去几年,整个行业几乎都在争夺云端大模型市场——OpenAI、Google、Anthropic,以及国内的大模型公司,竞争焦点始终围绕着模型能力展开。但与此同时,另一种趋势也在出现。Apple M系列芯片不断提升神经网络算力,NVIDIA开始推动AI PC,微软推出Copilot+ PC。越来越多计算能力正在回到用户设备本身。AI的计算结构正在发生变化——过去,大部分AI能力运行在云端;未来,随着个人数据越来越重要,越来越多与记忆相关的能力将运行在用户设备上,而推理和世界知识仍将持续受益于云端大模型。
因为用户最重要的数据本来就存在本地——采访记录、合同文件、财务资料、创作素材、家庭照片。这些内容既不适合频繁上传云端,也很难完全依赖云端处理。更重要的是,数据规模本身正在迅速膨胀。对于影视制作团队来说,一个项目可能产生数十TB甚至上百TB视频素材;对于媒体机构而言,几年时间积累下来,同样会形成庞大的内容资产。在这种情况下,云端不一定是最优解。本地理解、本地索引、本地推理,反而开始具备新的价值。
不过,康洪文并不认为未来属于“纯本地AI”。他强调,Memory Layer最终依然会是一个云端与本地协同的体系。因为记忆本身并不等于存储,真正重要的是组织、关联和调用。用户的数据可能分散在不同设备和平台上——电脑里有文件,手机里有照片、视频,云盘里还有另一部分资料。未来的记忆系统,需要把这些原本割裂的数据重新连接起来,最终形成一个能够被AI理解、查询和调用的个人知识网络。
而这也是康洪文过去二十年思考不断演化后的结果。在微软亚洲研究院,他研究机器如何理解视频;在智影时期,他研究机器如何生成内容;而到了今天,他开始思考一个新的问题:当AI已经能够理解内容、生成内容之后,谁来组织内容。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:所有AI都在理解世界,这家公司却在理解你要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点8月21日,OpenAI首次开放企业客户用自有数据微调旗舰模型GPT-4o,支持文本数据,训练约1-2小时。此前仅可微调较小模型,此举大幅降低定制门槛,无需第三方服务,企业可快速实现个性化AI应用。
免费AI旅行规划工具,可快速生成个性化定制行程,适合个人与家庭出行。能处理开放式问题,提供全面路线、亲子活动和悠闲节奏方案,并支持在线预订机票住宿,同时提供丰富旅行灵感及详细攻略。
需求人群 首先,这类工具主要面向哪些用户?答案很明确——任何投放Google广告、因无效点击和恶意竞争而焦头烂额的广告主。核心痛点集中在以下三个方面: 保护Google广告免受恶意点击侵害,简单说就是防止竞争对手或机器人白白消耗你的广告预算。 确保广告预算仅用于真实用户的互动,每一分钱都必须具备真实
说到结构化数据的交互式搜索,许多团队都面临一个尴尬的局面:数据整理得井井有条,但用户想要查询信息,还得编写复杂的查询语句。有没有一种方式,能让用户直接用自然语言提问,系统就能自动理解并返回精准结果?答案是肯定的——Microsoft Knowledge Exploration API正是为此而设计的
- 日榜
- 周榜
- 月榜
热点快看