




MCP革命:AI时代万物互联技术基石3月最新研究报告

MCP协议:AI时代的万物互联新纪元,开启自主智能体的新时代。核心内容:1 MCP协议的技术本质与基础价值,及其与传统API集成的区别2 MCP架构的深度剖析,包括三层结构与三大核心组件3 MCP服务器开发实践,Python实现详解及开发环境搭建步骤2025年3月,模型上下文协议(Model
MCP协议:AI时代的万物互联新纪元,开启自主智能体的新时代。核心内容:1. MCP协议的技术本质与基础价值,及其与传统API集成的区别2. MCP架构的深度剖析,包括三层结构与三大核心组件3. MCP服务器开发实践,Python实现详解及开发环境搭建步骤
2025年3月,模型上下文协议(Model Context Protocol,简称MCP)已经从概念走向全面落地,成为连接AI与现实世界的核心基础设施。本报告深入剖析MCP的技术架构、开发实践和工业应用,带你看清AI工具生态系统最前沿的发展动态。
一、MCP的技术本质:AI世界的TCP/IP
MCP的定义与基础价值
MCP是一种开放标准协议,旨在标准化AI模型与外部数据源及工具的交互方式,从根本上解决传统集成的碎片化问题。有行业专家说得直白:“MCP之于AI,有点类似于TCP/IP之于互联网。”这个比喻非常精妙——建立一个统一标准,实现万物互联,正是MCP的核心价值所在。
传统API集成与MCP的根本区别

传统API集成面临两大核心痛点:
集成复杂度:每接入一个新工具,开发者都得编写专门的适配代码。
静态工具集:AI只能使用预先定义好的工具,无法动态发现新能力。
而MCP协议通过标准化接口完美解决了这些问题,让AI像人类一样“自主发现并使用工具”,把AI从固定脚本执行者变成了自主决策的智能体。
二、MCP架构深度剖析:三层结构与工作原理
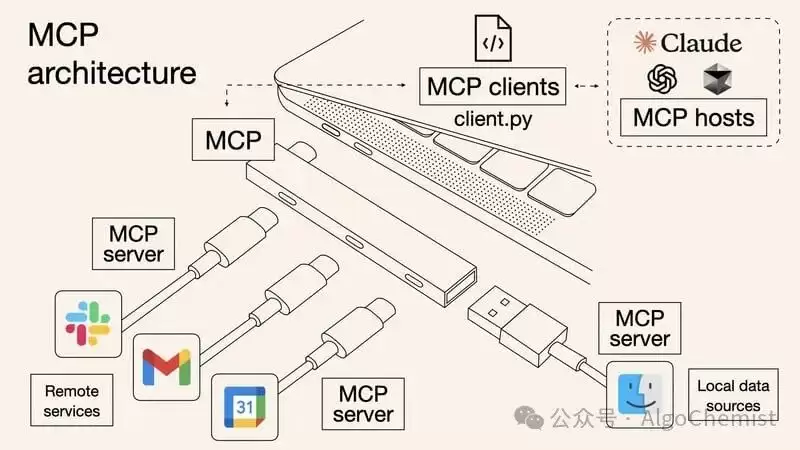
三大核心组件详解
MCP架构基于经典的客户端-服务器模型,由三个关键组件构成:
主机(Host):承载AI交互环境的应用程序,比如Claude Desktop、Cursor等。主机负责集成外部工具、访问多样化数据资源,并运行MCP客户端。
客户端(Client):运行在主机内部的组件,负责与MCP服务器建立高效通信。说白了,它就是个桥梁——在宿主与外部资源之间传递数据、协调指令。
服务器(Server):暴露特定功能接口和数据访问能力的服务提供方。它把外部资源与AI模型连接起来,以标准化方式提供各种服务。
通信层:协议设计与标准化
MCP的通信层是整个系统的心脏,通过定义标准协议来协调客户端与服务器之间的交互。特点很明确:
格式定义:采用基于JSON-RPC的统一数据格式,确保双方能准确解析信息。
兼容性保障:标准化接口让不同AI模型(Claude、LLaMA等)能与各种工具无缝协作。
安全机制:内置认证、加密以及错误处理逻辑,保障通信的稳定性和可靠性。
服务器功能分类
MCP服务器提供的功能,大致可以分成这样几类:
工具(Tools):执行具体操作的能力,比如代码调试、文件管理等。
资源(Resources):提供数据访问的接口,比如文档库、数据库等。
提示(Prompts):预定义的指令模板,帮助AI更好地执行特定领域的任务。
三、MCP服务器开发实践:Python实现详解
Python MCP服务器开发环境搭建
先把开发环境准备好,关键步骤如下:
# 1. 安装uv包管理工具(推荐替代pip)# pip install uv# 2. 初始化MCP服务器项目# uv init server# 3. 添加MCP依赖# uv add 'mcp[cli]'
基础MCP服务器实现代码
下面是一个完整的Python MCP服务器实现样例,展示如何创建工具和处理请求:
# server.py - 基础MCP服务器实现from mcp.server.fastmcp import FastMCPfrom typing import List, Dict, Any, Optionalimport datetime# 创建MCP服务器实例mcp = FastMCP("AdvancedAssistantTools")# 定义日历工具@mcp.tool("calendar", description="日历管理与查询工具")class CalendarTool:@mcp.function(name="query_events",description="查询指定日期的日历事件")def query_events(self,date: str = mcp.parameter(description="查询日期,格式:YYYY-MM-DD")) -> List[Dict[str, Any]]:"""查询日历事件演示函数"""# 在实际应用中,这里会连接真实的日历API# 本示例仅作演示try:query_date = datetime.datetime.strptime(date, "%Y-%m-%d").date()today = datetime.date.today()# 模拟数据if (query_date - today).days > 30:return []elif query_date.weekday() >= 5: # 周末return [{"title": "家庭聚餐", "start": "12:00", "end": "14:00", "location": "家"}]else: # 工作日return [{"title": "团队例会", "start": "09:30", "end": "10:30", "location": "会议室A"},{"title": "项目评审", "start": "14:00", "end": "16:00", "location": "线上"}]except ValueError:return {"error": "日期格式错误,请使用YYYY-MM-DD格式"}# 定义文档处理工具@mcp.tool("document", description="文档处理工具")class DocumentTool:@mcp.function(name="summarize",description="自动总结文档内容")def summarize(self,text: str = mcp.parameter(description="需要总结的文本内容"),max_length: int = mcp.parameter(description="总结的最大长度", default=200)) -> Dict[str, Any]:"""文档总结演示函数"""# 实际实现中会调用NLP模型进行总结# 本示例仅作演示if not text:return {"error": "文本内容为空"}# 简单实现:返回前N个字符summary = text[:min(max_length, len(text))]return {"summary": summary,"original_length": len(text),"summary_length": len(summary)}# 定义数据分析工具@mcp.tool("data_analytics", description="数据分析与可视化工具")class DataAnalyticsTool:@mcp.function(name="analyze_time_series",description="分析时间序列数据并返回统计结果")def analyze_time_series(self,data: List[float] = mcp.parameter(description="时间序列数据点列表"),metric: str = mcp.parameter(description="分析指标:mean, median, trend", default="mean")) -> Dict[str, Any]:"""时间序列数据分析演示函数"""if not data:return {"error": "数据为空"}result = {"data_points": len(data)}if metric == "mean":result["mean"] = sum(data) / len(data)elif metric == "median":sorted_data = sorted(data)mid = len(sorted_data) // 2result["median"] = sorted_data[mid] if len(data) % 2 == 1 else (sorted_data[mid-1] + sorted_data[mid]) / 2elif metric == "trend":# 简单线性趋势计算if len(data) < 2:result["trend"] = "insufficient_data"else:first_half = sum(data[:len(data)//2]) / (len(data)//2)second_half = sum(data[len(data)//2:]) / (len(data) - len(data)//2)result["trend"] = "increasing" if second_half > first_half else "decreasing" if second_half < first_half else "stable"return result# 启动服务器if __name__ == "__main__":mcp.run(host="0.0.0.0", port=8000)
高级功能:动态工具发现与权限控制
2025年的MCP实现已经支持更高级的功能了,比如动态工具发现和细粒度权限控制:
# advanced_server.py - 包含动态工具发现与权限控制from mcp.server.fastmcp import FastMCPfrom mcp.security import Permission, Role, SecurityContextfrom typing import Dict, Any, Listimport osmcp = FastMCP("EnterpriseTools")# 定义权限模型admin_role = Role("admin", "管理员角色,拥有全部权限")user_role = Role("user", "普通用户角色,仅有查询权限")read_permission = Permission("read", "读取数据权限")write_permission = Permission("write", "写入数据权限")admin_role.add_permissions([read_permission, write_permission])user_role.add_permissions([read_permission])# 注册安全上下文security_context = SecurityContext()security_context.add_roles([admin_role, user_role])mcp.set_security_context(security_context)# 企业数据库工具@mcp.tool("database", description="企业数据库访问工具")class DatabaseTool:@mcp.function(name="query_data",description="查询企业数据",required_permissions=["read"] # 需要read权限)def query_data(self,table: str = mcp.parameter(description="表名"),filters: Dict[str, Any] = mcp.parameter(description="查询条件")) -> Dict[str, Any]:# 实际实现中会连接数据库# 示例仅作演示return {"status": "success","data": [{"id": 1, "name": "示例数据"}],"metadata": {"table": table, "filters": filters}}@mcp.function(name="update_data",description="更新企业数据",required_permissions=["write"] # 需要write权限)def update_data(self,table: str = mcp.parameter(description="表名"),record_id: int = mcp.parameter(description="记录ID"),updates: Dict[str, Any] = mcp.parameter(description="更新内容")) -> Dict[str, Any]:# 权限检查在框架层自动完成return {"status": "success","updated_id": record_id,"metadata": {"table": table, "updates": updates}}# 动态工具注册class ToolRegistry:def __init__(self, mcp_server):self.mcp = mcp_serverself.tool_directory = "./plugins"def scan_and_register(self):"""扫描插件目录并注册工具"""if not os.path.exists(self.tool_directory):os.makedirs(self.tool_directory)for filename in os.listdir(self.tool_directory):if filename.endswith(".py") and not filename.startswith("_"):module_path = os.path.join(self.tool_directory, filename)self.register_tool_from_file(module_path)def register_tool_from_file(self, file_path):"""从文件动态注册工具"""# 实际实现会动态加载Python模块# 此处仅作示例说明tool_name = os.path.basename(file_path).replace(".py", "")print(f"发现工具:{tool_name} 从 {file_path}")# 实际实现中的动态加载代码# 启动服务器前扫描并注册工具if __name__ == "__main__":registry = ToolRegistry(mcp)registry.scan_and_register()mcp.run(host="0.0.0.0", port=8000)
四、2025年3月MCP生态系统最新发展
工具接入爆发式增长
越来越多的工具和服务开始接入MCP,呈现爆发式增长。已经覆盖的方向包括:
地图服务:Google Maps
数据库:PostgreSQL、ClickHouse(OLAP数据库)
企业工具:Atlassian系列产品
支付处理:Stripe
文档处理:Office 365、Google Workspace
Smithery平台已经成为查找MCP兼容工具的中心枢纽,开发者可以轻松找到不同功能对应的工具和服务。随着越来越多的Server接入MCP协议,AI能够直接调用的工具呈指数级增长,Agent能力的上限也随之提升。
工业应用新动向
MCP在工业领域的应用正在快速渗透,尤其与中国制造2025战略结合紧密,推动了智能制造和工业互联网的发展。典型场景包括:
智能制造控制系统:通过MCP连接工业设备、生产线和质量控制系统,实现智能制造全流程的AI协调和优化。
产品设计辅助:AI通过MCP连接CAD/CAM系统、材料数据库和仿真工具,辅助产品设计和优化。
供应链优化:MCP赋能的AI系统连接ERP、物流系统和供应商管理平台,实现供应链的实时优化和风险预警。
开发生态标准化进程
MCP的标准化工作取得了重大进展:
官方SDK:主流语言的官方SDK已经完善,包括Python、Ja vaScript、.NET、Ja va等,开发门槛大幅降低。
治理机制:已建立开放的治理机制,包括技术指导委员会和社区贡献流程,确保协议的统一演进。
认证体系:推出了MCP兼容性认证体系,帮助用户识别真正符合标准的MCP实现。
五、MCP典型应用场景与代码示例
企业知识管理系统
下面是企业知识管理系统中MCP的Python实现示例:
# knowledge_management.pyfrom mcp.server.fastmcp import FastMCPfrom typing import Dict, Any, List, Optionalimport datetimemcp = FastMCP("EnterpriseKnowledge")@mcp.tool("knowledge_base", description="企业知识库管理工具")class KnowledgeBaseTool:def __init__(self):# 实际实现中会连接到真实的知识库系统# 以下仅为演示self.knowledge_base = {"product_specs": {"last_updated": "2025-03-15","categories": ["硬件", "软件", "服务"],"total_documents": 1250},"technical_docs": {"last_updated": "2025-03-10","categories": ["API文档", "架构设计", "操作手册"],"total_documents": 3780},"company_policies": {"last_updated": "2025-02-28","categories": ["人力资源", "财务", "IT安全"],"total_documents": 420}}@mcp.function(name="search_documents",description="搜索企业知识库文档")def search_documents(self,query: str = mcp.parameter(description="搜索关键词"),category: Optional[str] = mcp.parameter(description="文档类别", default=None),max_results: int = mcp.parameter(description="最大结果数", default=10)) -> Dict[str, Any]:"""搜索企业知识库"""# 实际实现中会连接到搜索引擎# 示例返回模拟数据results = []if "product" in query.lower():results.append({"title": "产品规格说明书v2.5","category": "产品文档","last_updated": "2025-03-01","relevance": 0.95,"summary": "详细介绍了公司所有产品的技术规格、兼容性信息和使用建议。"})if "security" in query.lower() or "安全" in query:results.append({"title": "企业IT安全规范2025版","category": "公司政策","last_updated": "2025-01-15","relevance": 0.88,"summary": "规定了企业IT系统的安全使用规范、访问控制政策和数据保护要求。"})# 根据category过滤if category:results = [doc for doc in results if category.lower() in doc["category"].lower()]# 限制结果数量results = results[:min(len(results), max_results)]return {"query": query,"total_matches": len(results),"results": results,"metadata": {"search_time": datetime.datetime.now().isoformat(),"index_coverage": "完整","applied_filters": {"category": category} if category else {}}}@mcp.function(name="get_knowledge_stats",description="获取知识库统计信息")def get_knowledge_stats(self) -> Dict[str, Any]:"""获取知识库统计信息"""total_docs = sum(category["total_documents"] for category in self.knowledge_base.values())all_categories = []for kb_section in self.knowledge_base.values():all_categories.extend(kb_section["categories"])return {"total_documents": total_docs,"categories": list(set(all_categories)),"last_system_update": "2025-03-15T08:30:00","sections": list(self.knowledge_base.keys())}# 启动服务器if __name__ == "__main__":mcp.run(host="0.0.0.0", port=8001)
智能客服系统
智能客服系统的MCP服务器实现示例:
# customer_service.pyfrom mcp.server.fastmcp import FastMCPfrom typing import Dict, Any, List, Optionalimport uuidimport datetimemcp = FastMCP("CustomerServiceSystem")@mcp.tool("customer_support", description="客户服务与工单管理工具")class CustomerSupportTool:def __init__(self):# 模拟工单数据库self.tickets = {}self.knowledge_articles = [{"id": "KA-001", "title": "如何重置密码", "category": "账户管理"},{"id": "KA-002", "title": "订单退款流程", "category": "支付与退款"},{"id": "KA-003", "title": "产品激活指南", "category": "产品使用"}]@mcp.function(name="create_ticket",description="创建客户工单")def create_ticket(self,customer_email: str = mcp.parameter(description="客户邮箱"),subject: str = mcp.parameter(description="工单主题"),description: str = mcp.parameter(description="问题描述"),priority: str = mcp.parameter(description="优先级:low, medium, high", default="medium"),category: str = mcp.parameter(description="问题类别", default="general")) -> Dict[str, Any]:"""创建新的客户工单"""# 生成工单IDticket_id = f"TK-{uuid.uuid4().hex[:8]}"# 创建工单记录ticket = {"id": ticket_id,"customer_email": customer_email,"subject": subject,"description": description,"priority": priority,"category": category,"status": "open","created_at": datetime.datetime.now().isoformat(),"updated_at": datetime.datetime.now().isoformat(),"assigned_to": None}# 存储工单self.tickets[ticket_id] = ticketreturn {"status": "success","ticket_id": ticket_id,"message": "工单创建成功","ticket": ticket}@mcp.function(name="update_ticket",description="更新工单状态")def update_ticket(self,ticket_id: str = mcp.parameter(description="工单ID"),status: Optional[str] = mcp.parameter(description="工单状态", default=None),notes: Optional[str] = mcp.parameter(description="更新说明", default=None),assigned_to: Optional[str] = mcp.parameter(description="指派给", default=None)) -> Dict[str, Any]:"""更新工单状态"""if ticket_id not in self.tickets:return {"status": "error","message": f"找不到工单 {ticket_id}"}ticket = self.tickets[ticket_id]# 更新工单信息if status:ticket["status"] = statusif notes:if "notes" not in ticket:ticket["notes"] = []ticket["notes"].append({"content": notes,"timestamp": datetime.datetime.now().isoformat()})if assigned_to:ticket["assigned_to"] = assigned_toticket["updated_at"] = datetime.datetime.now().isoformat()return {"status": "success","message": "工单已更新","ticket": ticket}@mcp.function(name="search_knowledge_base",description="搜索客服知识库")def search_knowledge_base(self,query: str = mcp.parameter(description="搜索关键词"),category: Optional[str] = mcp.parameter(description="文章类别", default=None)) -> Dict[str, Any]:"""搜索客服知识库文章"""results = []# 简单关键词匹配for article in self.knowledge_articles:if query.lower() in article["title"].lower():if category and category != article["category"]:continueresults.append(article)return {"query": query,"results_count": len(results),"results": results}# 启动服务器if __name__ == "__main__":mcp.run(host="0.0.0.0", port=8002)
六、MCP与2025年AI发展新趋势
三大核心趋势分析
根据2025年3月的最新观察,AI发展呈现出三大核心趋势:
预训练终结,后训练成为重点:
数据被形容为“AI时代的化石燃料”——毕竟人类只有一个互联网。DeepSeek R1的论文明确提到,后训练将成为大模型训练管线中的重要组成部分。在这一背景下,MCP通过提供标准化工具接口,为后训练阶段的能力扩展提供了关键支持。强化学习成为主流,监督学习重要性下降:
强化学习正在成为后训练阶段的主流方法,而MCP为强化学习提供了真实世界的“动作空间”,使AI能够通过与外部工具的交互来学习和优化决策。MultiAgent成为确定性大趋势:
多智能体协作已经成为AI发展的确定性趋势,而MCP为智能体之间的协作提供了标准化接口,让不同专业领域的智能体能够无缝协作,形成更强大的智能网络。
MCP在多智能体系统中的应用
随着MultiAgent成为确定性的技术方向,MCP在多智能体系统中的应用也越来越丰富。下面是一个多智能体协作系统的MCP架构设计:
# multi_agent_system.pyfrom mcp.server.fastmcp import FastMCPfrom mcp.client import McpClientfrom typing import Dict, Any, Listimport asyncioimport json# 主协调智能体服务器coordinator_mcp = FastMCP("CoordinatorAgent")@coordinator_mcp.tool("task_management", description="任务分解与协调工具")class TaskManagementTool:@coordinator_mcp.function(name="decompose_task",description="将复杂任务分解为子任务")def decompose_task(self,task_description: str = coordinator_mcp.parameter(description="任务描述"),complexity: str = coordinator_mcp.parameter(description="任务复杂度: low, medium, high", default="medium")) -> Dict[str, Any]:"""将复杂任务分解为子任务"""# 实际实现中会使用更复杂的任务分解算法subtasks = []if "数据分析" in task_description:subtasks.extend([{"id": "subtask-1", "type": "data_collection", "description": "收集相关数据"},{"id": "subtask-2", "type": "data_processing", "description": "数据清洗与预处理"},{"id": "subtask-3", "type": "data_analysis", "description": "数据分析与洞察提取"},{"id": "subtask-4", "type": "report_generation", "description": "生成分析报告"}])elif "内容创作" in task_description:subtasks.extend([{"id": "subtask-1", "type": "research", "description": "主题研究"},{"id": "subtask-2", "type": "outline", "description": "创建内容大纲"},{"id": "subtask-3", "type": "draft", "description": "撰写初稿"},{"id": "subtask-4", "type": "edit", "description": "编辑与润色"}])else:# 默认分解方案subtasks.extend([{"id": "subtask-1", "type": "research", "description": "背景调研"},{"id": "subtask-2", "type": "execution", "description": "执行主要任务"},{"id": "subtask-3", "type": "review", "description": "结果审核"}])return {"original_task": task_description,"subtasks": subtasks,"total_subtasks": len(subtasks),"estimated_complexity": complexity}@coordinator_mcp.function(name="assign_subtasks",description="将子任务分配给专业智能体")def assign_subtasks(self,subtasks: List[Dict[str, Any]] = coordinator_mcp.parameter(description="子任务列表"),a vailable_agents: List[str] = coordinator_mcp.parameter(description="可用智能体列表")) -> Dict[str, Any]:"""将子任务分配给专业智能体"""assignments = {}# 简单的任务分配逻辑for subtask in subtasks:subtask_type = subtask["type"]# 根据任务类型选择合适的智能体if subtask_type == "data_collection" or subtask_type == "data_processing":if "data_agent" in a vailable_agents:agent = "data_agent"else:agent = a vailable_agents[0] # 默认使用第一个可用智能体elif subtask_type == "research":if "research_agent" in a vailable_agents:agent = "research_agent"else:agent = a vailable_agents[0]else:# 轮询分配其他类型任务agent = a vailable_agents[len(assignments) % len(a vailable_agents)]# 记录分配结果if agent not in assignments:assignments[agent] = []assignments[agent].append(subtask["id"])return {"assignments": assignments,"total_assigned": sum(len(tasks) for tasks in assignments.values())}# 专业智能体服务器示例 - 数据分析智能体data_agent_mcp = FastMCP("DataAnalysisAgent")@data_agent_mcp.tool("data_analysis", description="数据分析工具")class DataAnalysisTool:@data_agent_mcp.function(name="process_data",description="处理和分析数据")def process_data(self,data_source: str = data_agent_mcp.parameter(description="数据源"),analysis_type: str = data_agent_mcp.parameter(description="分析类型:descriptive, predictive, prescriptive")) -> Dict[str, Any]:"""处理和分析数据"""# 实际实现中会执行真实的数据分析result = {"status": "completed","data_source": data_source,"analysis_type": analysis_type,"results": {"summary_statistics": {"count": 1000,"mean": 45.7,"median": 42.3,"std_dev": 15.2},"key_findings": ["发现异常值聚集在特定时间段","数据呈现明显的季节性趋势","两个关键变量存在显著相关性"]}}return result# 智能体协作客户端示例class AgentCollaborationSystem:def __init__(self):self.coordinator_client = McpClient("http://localhost:8010")self.data_agent_client = McpClient("http://localhost:8011")self.research_agent_client = McpClient("http://localhost:8012")async def execute_complex_task(self, task_description):"""执行复杂任务的完整流程"""print(f"接收任务: {task_description}")# 1. 任务分解decomposition_result = await self.coordinator_client.invoke("task_management", "decompose_task",{"task_description": task_description, "complexity": "high"})subtasks = decomposition_result["subtasks"]print(f"任务已分解为 {len(subtasks)} 个子任务")# 2. 任务分配a vailable_agents = ["data_agent", "research_agent"]assignment_result = await self.coordinator_client.invoke("task_management", "assign_subtasks",{"subtasks": subtasks, "a vailable_agents": a vailable_agents})print(f"任务分配结果: {json.dumps(assignment_result['assignments'], indent=2)}")# 3. 并行执行子任务execution_tasks = []for agent, task_ids in assignment_result["assignments"].items():for task_id in task_ids:# 查找对应的子任务详情subtask = next((t for t in subtasks if t["id"] == task_id), None)if subtask:# 根据不同智能体执行不同任务if agent == "data_agent" and subtask["type"] in ["data_collection", "data_processing"]:execution_tasks.append(self.data_agent_client.invoke("data_analysis", "process_data",{"data_source": "database", "analysis_type": "descriptive"}))# 等待所有子任务完成results = await asyncio.gather(*execution_tasks)# 4. 整合结果final_result = {"original_task": task_description,"subtask_results": results,"completion_status": "success","timestamp": datetime.datetime.now().isoformat()}return final_result# 启动多智能体系统示例if __name__ == "__main__":# 在实际应用中,这些服务器会在不同的进程或机器上运行import threadingdef run_coordinator():coordinator_mcp.run(host="0.0.0.0", port=8010)def run_data_agent():data_agent_mcp.run(host="0.0.0.0", port=8011)# 启动服务器threading.Thread(target=run_coordinator).start()threading.Thread(target=run_data_agent).start()# 等待服务器启动time.sleep(2)# 创建协作系统并执行任务collaboration_system = AgentCollaborationSystem()asyncio.run(collaboration_system.execute_complex_task("分析过去三个月的销售数据并生成报告"))
七、MCP面临的技术挑战与解决方案
当然,MCP也并非完美无缺。盘点一下当前面临的几个核心挑战,以及对应的解决思路。
跨平台兼容性与互操作性
挑战:不同实现之间的兼容性问题导致生态系统碎片化。
解决方案:
统一的一致性测试套件,确保不同实现符合相同的标准。
参考实现的开源发布,为其他实现提供基准。
主流开发语言的官方SDK,减少重复实现。
安全性与隐私保护
挑战:工具访问权限的精细控制与用户友好性之间的平衡。
解决方案:
基于意图的权限模型,允许用户基于高级任务目标授权。
沙箱隔离技术,限制工具访问范围。
端到端加密通信,保护数据传输安全。
性能优化
挑战:当AI需要访问大量外部资源时,MCP通信可能成为性能瓶颈。
解决方案:
批处理请求机制,减少通信次数。
本地缓存优化,避免重复请求。
异步通信模型,提高并发处理能力。
八、未来展望:MCP的发展路径
技术演进方向
多模态扩展:从当前主要文本交互扩展到支持音频、视频等格式。
分布式协作框架:支持多个AI系统之间的协同工作,创建分布式智能网络。
端到端安全机制:更强大的安全和隐私保护机制,满足企业级需求。
生态系统展望
随着工具数量的指数级增长,可以预见以下几个方向:
工具市场:类似应用商店的MCP工具市场将形成,开发者可以发布和分享MCP兼容工具。
垂直领域专业化:针对金融、医疗、法律等特定领域的专业化MCP工具集将出现。
开源社区驱动:开源社区将成为推动MCP发展的核心力量,促进技术创新和最佳实践分享。
MCP的战略意义
MCP不仅仅是一项技术协议,更是AI生态系统演进的关键推动力。它正在把分散、孤立的AI工具转变为一个互联互通的生态系统,让AI能够更自然、更高效地与现实世界交互。
从技术架构来看,MCP代表了AI应用开发的新范式——从“为每个工具编写专门代码”转变为“一次集成,连接所有”。这种范式转变不仅大幅降低了开发成本,还开辟了全新的应用可能性。
最终,MCP正在成为连接AI与现实世界的关键基础设施,其战略地位类似于早期互联网发展中的TCP/IP协议。随着MCP生态的成熟,我们将看到更多创新应用的涌现,以及AI与现实世界更深层、更自然的融合,真正实现AI时代的“万物互联”愿景。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:MCP革命:AI时代万物互联技术基石3月最新研究报告要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点OmniParser是微软AI驱动的SaaS工具,基于YOLOv8和BLIP-2,将UI截图与漫画页面解析为结构化数据,支持UI元素检测、漫画面板分析、对话框及人脸识别,适用于自动化测试、漫画翻译等场景。
通义灵码是贯穿开发全流程的智能编码助手,具备代码智能生成、研发智能问答、多编程语言及编辑器支持、代码安全隐私保障四大核心能力,适用于学生、新手及企业开发者等多类人群,提升编码效率。
基于人工智能的自动化道路巡逻和资产数据收集方案,通过车载相机自动采集路面及周边资产数据,识别裂缝、坑槽等病害并建立数字化台账,同时自动删除隐私图像,实现从被动响应向主动预防的转变,降低巡检成本。
阿里旗下通义智文是一款智能阅读工具,支持网页、论文、图书和自由阅读四种场景,帮助用户快速提取核心观点,节省阅读时间,适合学生、研究人员及职场人士高效处理大量文本。
- 日榜
- 周榜
- 月榜
热点快看