




MoE通信优化技术COMET开源,万卡集群部署节省GPU小时

MoE架构是目前业界扩展大模型规模的主流方案,但始终面临一个关键痛点——分布式训练中高昂的通信开销,严重拉低了训练效率,增加了成本投入。如何突破这一瓶颈?豆包大模型团队推出了全新的通信优化系统 COMET。该系统的设计理念简洁高效:通过更精准、更细粒度的计算-通信重叠技术,在大规模MoE模型上实现了
MoE架构是目前业界扩展大模型规模的主流方案,但始终面临一个关键痛点——分布式训练中高昂的通信开销,严重拉低了训练效率,增加了成本投入。如何突破这一瓶颈?豆包大模型团队推出了全新的通信优化系统 COMET。该系统的设计理念简洁高效:通过更精准、更细粒度的计算-通信重叠技术,在大规模MoE模型上实现了单层1.96倍加速,端到端平均1.71倍效率提升。更重要的是,它在不同并行策略、输入规模及硬件环境下,均表现出高度稳定的性能。COMET已在万卡级生产集群中实际部署,为MoE模型的高效训练提供了有力支撑,累计节省了数百万GPU小时的计算资源。值得一提的是,COMET还可与豆包大模型团队此前发布的新一代稀疏模型架构UltraMem协同优化,进一步释放潜力。该项研究在MLSys 2025会议上获得了5/5/5/4的高分评审,核心代码也已全面开源。

Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
论文链接:https://arxiv.org/pdf/2502.19811
开源地址:https://github.com/bytedance/flux
混合专家模型(MoE)凭借稀疏激活机制,突破了传统稠密模型的计算瓶颈,然而分布式训练中的通信开销却成为一大棘手难题。以Mixtral-8x7B模型为例,在Megatron-LM框架中,通信时间占比可高达40%,严重制约了训练效率与成本控制。问题根源在于:MoE的专家网络分布在多个GPU上,每次计算都需频繁分发Token并聚合结果,导致大量GPU计算资源处于闲置状态。因此,如何将通信有效隐藏于计算过程中,从而提升训练效率、节省计算资源,已成为MoE系统优化的核心议题。
核心难点:“复杂的数据依赖”与“流水线气泡”
为了掩盖庞大的通信开销,现有方案大多聚焦于如何高效实现“计算”与“通信”的重叠。一种思路是将流水线调度与通信算子相结合,通过定制训练中流水线并行的调度方式,使不同microbatch的计算与通信实现重叠,例如DeepSeek的DualPipe方案。但该方法会带来较大的显存开销,且需要对现有训练框架进行复杂的侵入式改造。其他MoE系统方案则倾向于在microbatch内部采用粗粒度的计算-通信流水线,通过将输入数据分割为“数据块”来实现通信与计算的重叠。然而,这种粗粒度方式难以高效利用计算资源,也无法实现无缝的通信延迟隐藏,尤其在动态路由和异构硬件环境下,性能损耗相当显著。基于此,研究团队认为现有系统级MoE方案仍面临两大挑战:
1)复杂数据依赖难以有效解决
MoE的稀疏特性导致计算与通信之间的依赖关系动态且复杂。系统会动态地将Token分配给不同专家,而传统粗粒度矩阵分块方式,往往迫使GPU频繁等待远程数据,造成计算资源大量浪费。如图1所示,当专家0需要在紫色“数据块”中执行Tile-level计算时,必须先通过Token-level通信获取远程数据(Token B)。这种因复杂数据依赖引发的计算-通信粒度错配,显著降低了整体效率。
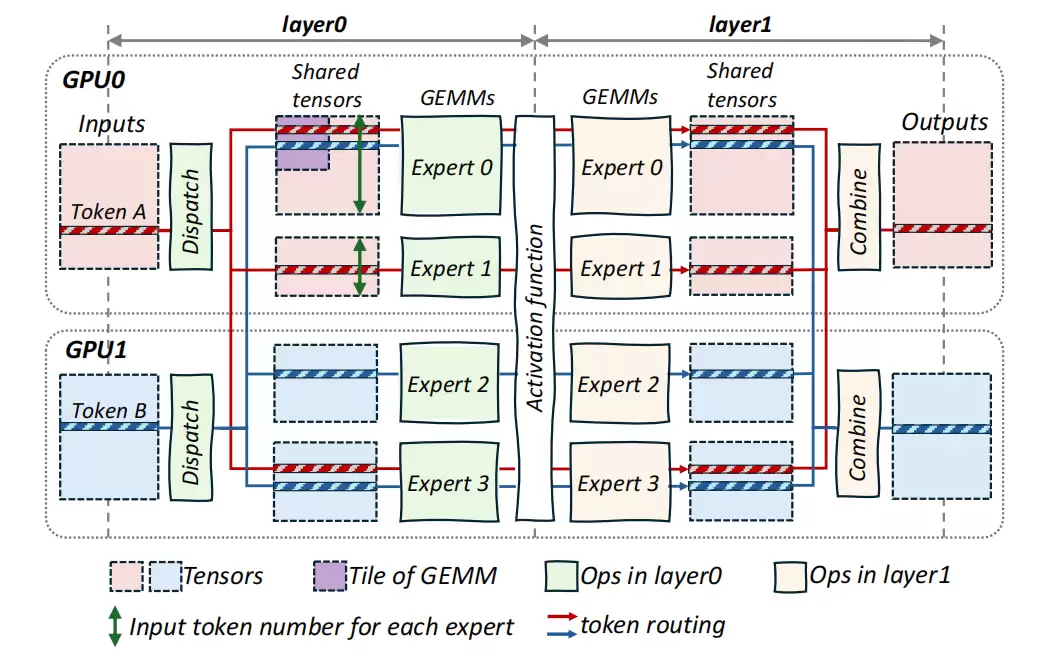
图 1:单层 MoE 模型示意图(专家分布在 GPU0 和 GPU1 两张卡上)
2)计算-通信流水线气泡难以消除
另一个关键问题在于,现有方法无法精确调控计算任务与通信任务对硬件资源的占用,也难以根据模型结构和动态输入自适应调整资源分配策略。这导致计算与通信无法实现无缝重叠,进而产生大量流水线气泡,增加了系统延迟。因此,研究团队认为:解决MoE模型中计算与通信的粒度不匹配问题,是实现二者高效重叠的关键;同时,还需根据负载情况自适应调整通信与计算的资源分配方案,以达成真正的无缝重叠。
COMET 核心方案
COMET是一套专为MoE模型设计的通信优化系统,通过细粒度的计算-通信重叠技术,为大模型训练优化开辟了新路径。团队深入分析后发现,MoE架构中包含两条不同的生产-消费流水线:“计算-通信流水线”与“通信-计算流水线”。如图2所示,数据在流水线中流转时,各流水线内的操作通过一个共享缓冲区进行链接,该缓冲区被称为“共享张量”。
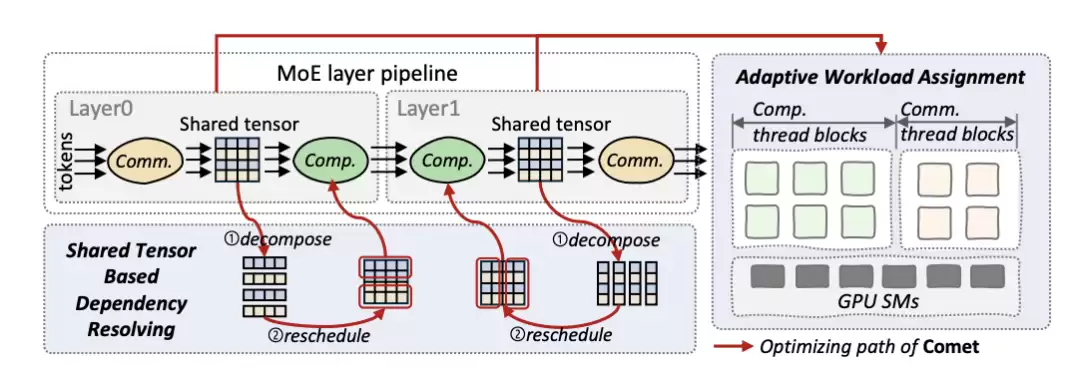
图 2:COMET 的设计结构
基于这一发现,COMET引入了两项关键机制,旨在最小化整体延迟并提升流水线性能。
1)共享张量依赖解析
通过分解与重调度共享张量,解决通信与计算之间的粒度错配问题,实现细至单Token级别的精确重叠。
张量分解:将MoE层间传递的共享张量沿Token维度(M)或隐层维度(N)进行切割,使通信与计算的最小单元实现对齐。例如,在MoE第一层(Layer 0,图3左)沿M维度分解,使通信与计算在M维度上对齐;在MoE第二层(Layer 1,图3右)沿N维度分解,以细粒度方式传输Token结果,确保计算与通信的高效重叠。
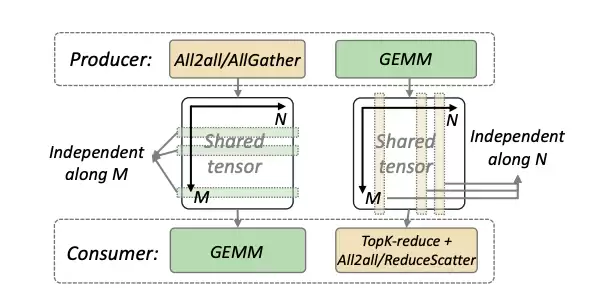
图 3:COMET 对共享张量进行依赖解析和分解
计算重调度:为进一步隐藏计算与通信延迟,COMET动态调整数据块的计算顺序。例如,优先计算本地数据块,同时异步拉取远程Token。当某个专家需要处理Token A(本地)和Token B(远程)时,系统会优先启动Token A的计算线程,并将其与Token B的通信线程并行执行,从而有效消除等待延迟。
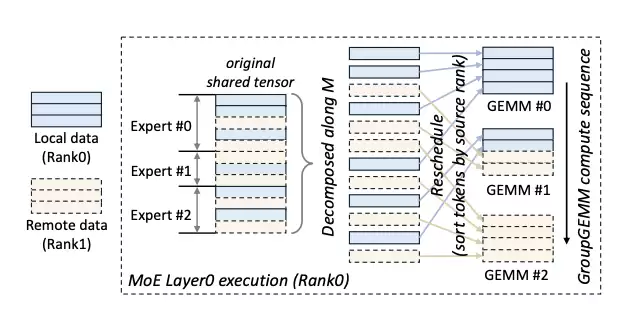
图 4:COMET 在 MoE layer0 中分解并重新调度共享张量
2)自适应负载分配
动态分配GPU线程块资源,精准平衡通信与计算负载,有效消除流水线气泡。
线程块隔离:将通信与计算任务分别封装在独立的线程块中,避免远程I/O阻塞计算核心。在Nvidia Hopper架构中,计算线程块专门执行异步TMA指令的GEMM运算,通信线程块则通过NVSHMEM实现单Token级的数据传输,这种设计使系统具备了算子级别的资源管理能力。
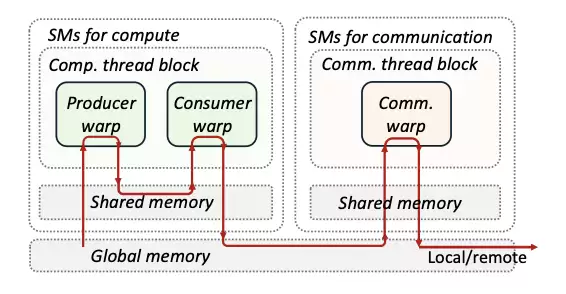
图 5:COMET 的计算/通信线程块隔离设计
动态负载平衡:根据输入规模(如Token长度M)和并行策略(EP/TP比例)实时调整线程块分配。如图6所示,当TP=8、EP=1时,通信线程块占所有线程块的比例为19.7%;而当TP=4、EP=2时,该比例需提升至34.8%。系统通过预编译多个版本的计算-通信融合算子,实现运行时“零开销”的算子动态切换,始终提供低延迟的算子支持。
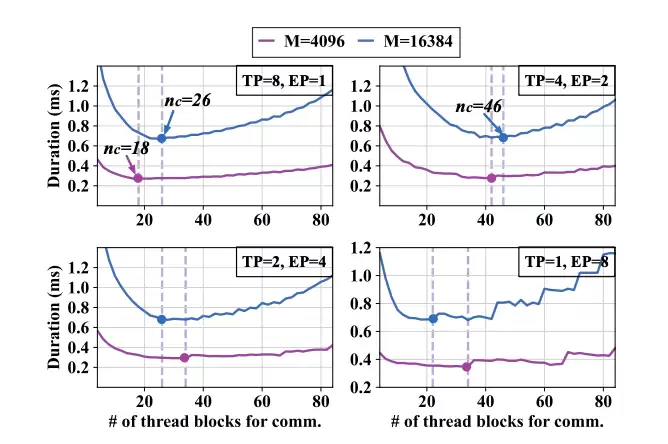
图 6:单个 MoE 层使用不同数量的通信线程块的时延结果
大规模落地验证
团队在多个大规模MoE模型中全面评估了COMET的端到端性能。结果显示,在8卡H800实验集群中,COMET在端到端MoE模型(如Mixtral-8x7B、Qwen2-MoE)上的前向时延,相比其他基线系统降低了31.8%-44.4%,且在不同并行策略、输入规模及硬件环境下,均表现出高度的稳定性。
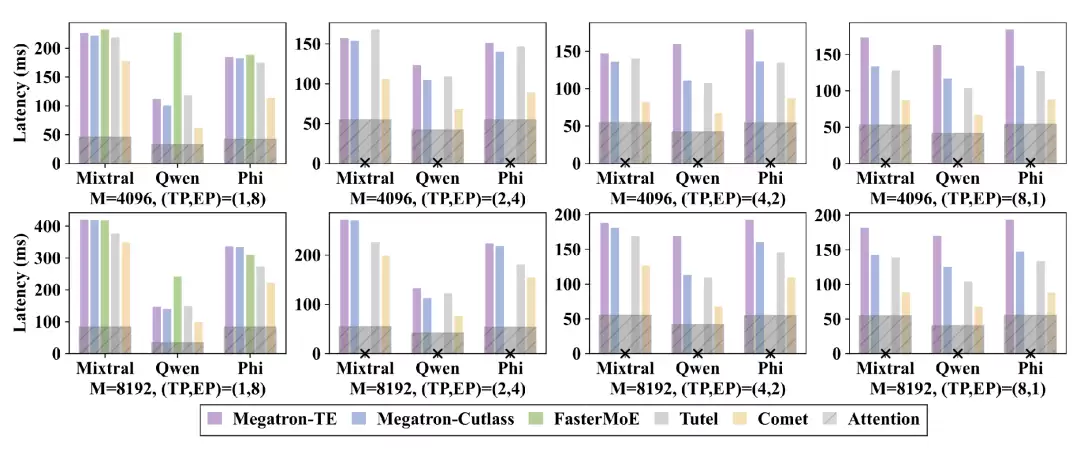
图 7:COMET 在多个 MoE 模型中的测评结果
在单个MoE层上,当输入Token数量不同时,COMET的执行时间均显著短于基线方案,平均实现了1.28倍到2.37倍的速度提升。
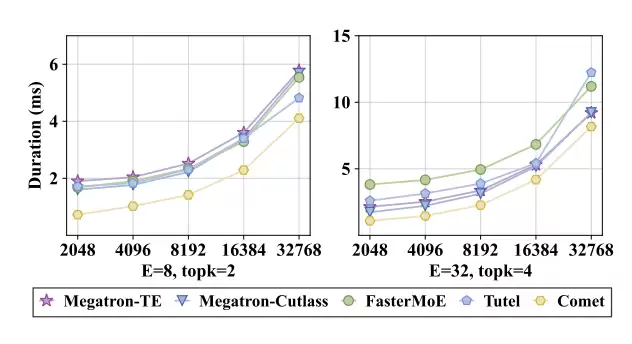
图 8:COMET 在单个 MoE 层不同输入 Token 长度下的延迟情况
目前,COMET已在万卡级生产集群中落地应用,有力支撑了MoE模型的高效训练,累计节省了数百万GPU小时的计算资源。该工作在MLSys 2025会议上获得了5/5/5/4的高分评审,被认为在大规模生产环境中具有极高的应用潜力。具体而言:
强鲁棒性:COMET采用细粒度计算-通信重叠方案,即使在专家负载不均衡的场景下,也能保持低于其他基线系统的延迟,表现极为稳定可靠。
强泛化能力:COMET在NVLink和PCIe等不同网络环境下,均能提供稳定的加速比;使用不同并行策略时,也能生成低延迟算子,便于大规模训练框架直接集成使用。
核心代码开源
COMET包含约1.2万行C++和CUDA代码,以及2千行Python代码,并向开发者提供了一套友好的Python API,便于快速上手与集成。

图9:COMET 开源页面
此外,COMET建立了一套面向MoE的细粒度流水线编程范式,通过深度融合NVSHMEM通信库与CUTLASS高效计算算子,实现了通信操作与GEMM计算的算子内融合。例如,MoE Layer 1的GEMM计算与Token聚合通信可在单个GPU算子内完成。这与前述Deepseek DualPipe方案并不冲突,二者结合或将带来更优的优化空间。更为关键的是,COMET能够无缝接入现有MoE训练框架,支持TP/EP/EP+TP等多种并行模式,并提供灵活的插拔式部署方案,极大降低了集成门槛。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:MoE通信优化技术COMET开源,万卡集群部署节省GPU小时要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Daetama是面向数据科学面试和SQL能力提升的练习平台,已收录超100个覆盖基础到进阶的SQL题目,求职板块与课程模块在开发中,团队保持每周更新节奏,提供系统性刷题与模拟面试场景。
SpeakMulti是一款AI驱动的配音平台,可将YouTube视频翻译成多种语言,保留原始说话者的音色和语调,降低本地化成本。用户提交视频并选择目标语言后,AI自动完成配音,并由专家团队审核,确保准确自然。
需求人群 如果你经常需要从图片中提取文字——例如整理截图内容、翻译图片里的外语文本、识别带有水印的图片信息——那么 Umi-OCR 无疑是一款相当实用的工具。它完全在本地运行,无需联网,对隐私保护极为友好。 产品特色 这款工具的核心亮点都集中在实用性上。截屏识别操作非常顺手,按下快捷键即可框选区域,
艺术创作与人工智能的融合,正在开启一个全新的创作时代。moonlightai 正是这样一款AI绘画工具,能够帮助用户通过人工智能快速生成不同风格的绘画作品——无论你想复刻文艺复兴时期的古典优雅,还是为画作注入梵高般炽热的笔触,甚至从艾沃佐夫斯基的海浪星空中汲取灵感,它都能轻松实现。 需求人群 简单来
- 日榜
- 周榜
- 月榜
热点快看