




英伟达H100 Transformer引擎让AI训练快6倍更准确

想必各位都深有体会,在当下的计算生态里,训练一个大型AI模型耗上几个月,几乎是家常便饭。但问题在于,这种节奏对于身处激烈竞争中的企业来说,实在太慢了,等不起。随着大语言模型这类庞然大物迈入万亿参数级别,AI、高性能计算和数据分析的复杂度也随之水涨船高,对算力和内存的要求近乎苛刻。NVIDIA最新的H
想必各位都深有体会,在当下的计算生态里,训练一个大型AI模型耗上几个月,几乎是家常便饭。但问题在于,这种节奏对于身处激烈竞争中的企业来说,实在太慢了,等不起。
随着大语言模型这类庞然大物迈入万亿参数级别,AI、高性能计算和数据分析的复杂度也随之水涨船高,对算力和内存的要求近乎苛刻。
NVIDIA最新的Hopper架构,正是为了解决这些棘手问题而生。它从底层重新设计,核心目的就是用惊人的算力和极速的内存,去扛住新一代AI工作负载那越来越重的担子,从容应对日益膨胀的网络和数据集。
而其中关键的亮点之一,就是全新Hopper架构中内置的Transformer引擎。有了它,AI的性能和功能将迎来一次质的飞跃,过去需要数月才能搞定的训练任务,现在几天甚至几小时就能完成。
使用 Transformer 引擎训练 AI 模型
Transformer模型,可以说是当今众多主流语言模型(比如我们熟悉的BERT和GPT-3)背后的基石。虽然它最初是为自然语言处理场景量身打造的,但因为其强大的通用性,现在已经渗透到计算机视觉、药物研发等领域。
与此同时,模型规模的扩张速度也超出了很多人的预期,动不动就是数万亿个参数。面对这样的计算量,训练周期被拉长到数月之久,这显然无法满足快速变化的业务需求。
Transformer引擎的厉害之处在于,它支持16位浮点精度,并引入了全新的8位浮点数据格式。再结合先进的软件算法,从底层把AI的性能和功能拔高了一大截。
我们都知道,AI训练离不开浮点数,像3.14这样的小数。之前随NVIDIA Ampere架构推出的TensorFloat32 (TF32) 格式,现在已经成为TensorFlow和PyTorch框架下的默认32位格式。
多数AI浮点运算,要么用16位“半”精度 (FP16),要么用32位“单”精度 (FP32),专业一点的则用64位“双”精度 (FP64)。而Transformer引擎则更进一步,直接奔着8位运算去了。这就好比在同样的时间内,能处理的运算量翻倍,自然就能更快地训练出更大的网络。
再和Hopper架构里其他新特性,比如提供节点间超高速直连的NVLink Switch系统结合起来,由H100加速服务器组成的集群,就能去训练那些过去几乎不可能在可接受时间内完成的大网络。
更深入地研究 Transformer 引擎
Transformer引擎并非空中楼阁,它依赖于软件技术和自定义的NVIDIA Hopper Tensor Core技术,专门用来加速那些基于Transformer构建的模型。这些Tensor Core能够灵活地应用FP8和FP16混合精度,大幅加快Transformer模型的AI计算。一个直观的数据是,采用FP8的Tensor Core运算,吞吐量直接是16位运算的两倍。
当然,这里有个核心挑战:如何在追求更小、更快数值格式带来的性能提升的同时,还能智能地管理精度,确保模型最终的准确性?Transformer引擎给出的方案是,使用一套经过NVIDIA精心调优的启发式算法。它能动态地在FP8和FP16计算之间做出最有利的选择,并自动处理每一层中这两种精度之间的数据重投影和缩放。
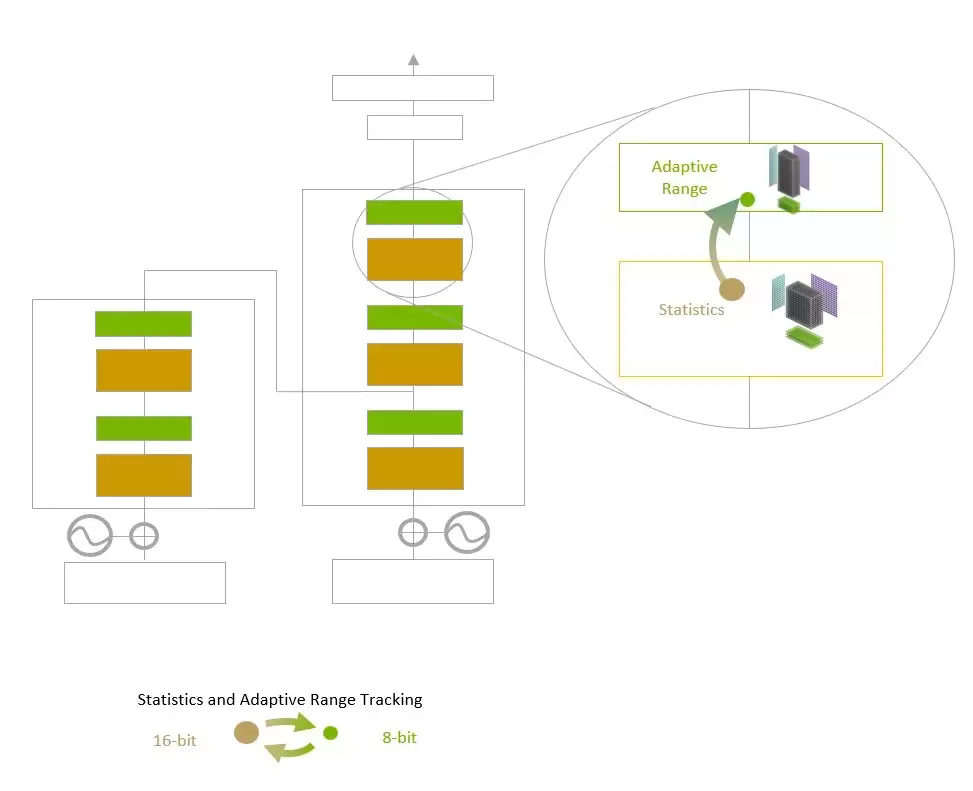
具体来说,Transformer Engine会分析每一层的统计数据,然后为模型的每一层都自动选定最佳的精度(FP16或FP8),从而在保持模型整体精度的前提下,榨干性能。
更让迭代提速的方面是,和上一代相比,NVIDIA Hopper架构在TF32、FP64、FP16和INT8等精度上的每秒浮点运算次数也提升到三倍,这在第四代Tensor Core的基础上又是一次巨大的进步。当Hopper Tensor Core、Transformer引擎以及第四代NVLink这套组合拳打出来,HPC和AI工作负载的加速效果,能实现数量级的提升。
加速 Transformer 引擎
先来看一个大家都熟悉的现状。目前AI领域最前沿的探索,很大一部分都集中在像Megatron 530B这样的大型语言模型上。下面的图非常直观地展示了近几年模型大小的增长趋势,业内普遍认为这个趋势还会持续。许多研究人员已经在着手研究用于自然语言理解和其他应用的超万亿参数模型,这说明,市场对AI计算能力的需求,远未见顶。
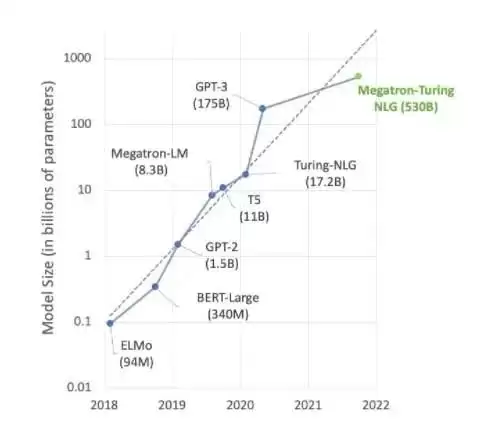
自然语言理解模型的尺寸,还在快速增长。
要满足这些持续膨胀的模型,高算力和大容量高速内存,缺一不可。NVIDIA H100 Tensor Core GPU恰好两者兼备,再加上Transformer引擎这个“翻跟斗”,让AI训练的效率更上一层楼。
这些创新带来的直接好处是什么?是吞吐量的巨大提升。一个典型的例子是,过去需要7天的训练任务,现在可以缩短到仅仅20个小时,训练时间直接缩短了9倍。
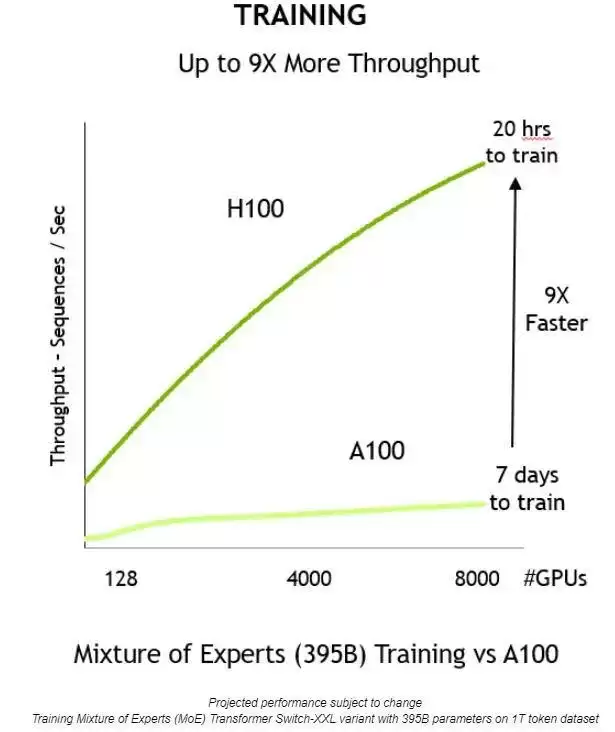
和上一代相比,NVIDIA H100 Tensor Core GPU提供9倍的训练吞吐量,让训练大型模型变得可行且高效。
值得一提的是,Transformer引擎还能直接用于推理,无需进行任何额外的数据格式转换。过去,INT8是推理性能的首选精度,但它需要事先将训练好的网络转换为INT8格式,这本身就是优化流程里的一步。现在,使用以FP8精度训练的模型,开发者完全可以跳过这个转换步骤,直接以相同的精度执行推理。和INT8格式的网络一样,使用Transformer引擎部署的模型,也能以更小的内存占用运行。
在Megatron 530B这个模型上,NVIDIA H100的每GPU推理吞吐量,比NVIDIA A100高出整整30倍,而响应延迟仅为1秒。这足以证明,它是一个非常适合AI部署的强力平台。
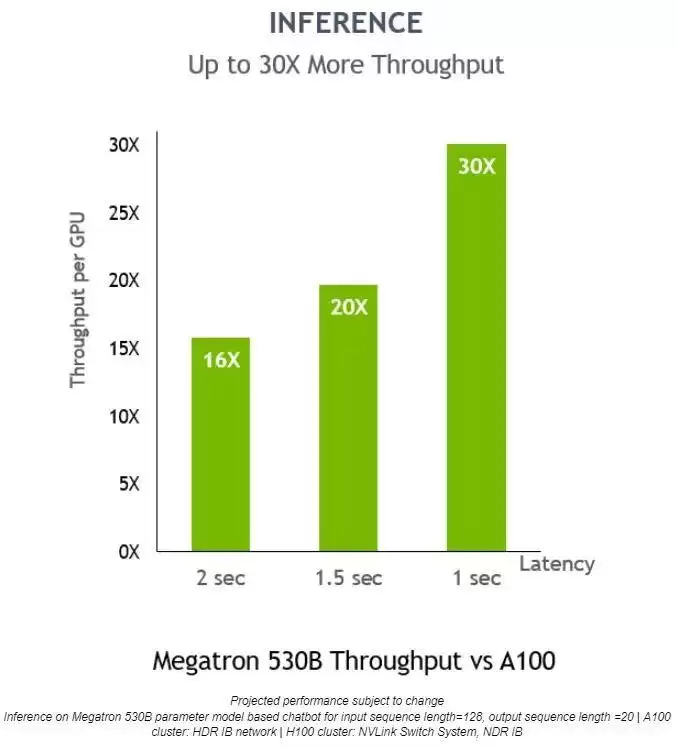
对于低延迟应用场景,Transformer引擎也能将推理吞吐量提高30倍。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:英伟达H100 Transformer引擎让AI训练快6倍更准确要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点OmniParser是微软AI驱动的SaaS工具,基于YOLOv8和BLIP-2,将UI截图与漫画页面解析为结构化数据,支持UI元素检测、漫画面板分析、对话框及人脸识别,适用于自动化测试、漫画翻译等场景。
通义灵码是贯穿开发全流程的智能编码助手,具备代码智能生成、研发智能问答、多编程语言及编辑器支持、代码安全隐私保障四大核心能力,适用于学生、新手及企业开发者等多类人群,提升编码效率。
基于人工智能的自动化道路巡逻和资产数据收集方案,通过车载相机自动采集路面及周边资产数据,识别裂缝、坑槽等病害并建立数字化台账,同时自动删除隐私图像,实现从被动响应向主动预防的转变,降低巡检成本。
阿里旗下通义智文是一款智能阅读工具,支持网页、论文、图书和自由阅读四种场景,帮助用户快速提取核心观点,节省阅读时间,适合学生、研究人员及职场人士高效处理大量文本。
- 日榜
- 周榜
- 月榜
热点快看