




用NVIDIA FLARE开发更通用的AI模型

联邦学习(FL)已从理论研究迈向实际部署,成为众多跨场景应用中的现实解决方案。它使全球各地的机构能够在无需共享原始数据的前提下,协同构建更稳健、更具泛化能力的机器学习与人工智能模型。尤其在医疗保健这类高度敏感的领域——患者数据受隐私法规保护,罕见病或特定人群的数据可能分布不均,数据在设备类型、性别、
联邦学习(FL)已从理论研究迈向实际部署,成为众多跨场景应用中的现实解决方案。它使全球各地的机构能够在无需共享原始数据的前提下,协同构建更稳健、更具泛化能力的机器学习与人工智能模型。尤其在医疗保健这类高度敏感的领域——患者数据受隐私法规保护,罕见病或特定人群的数据可能分布不均,数据在设备类型、性别、地域上缺乏多样性——联邦学习的价值愈发凸显。
NVIDIA FLARE v2.0 正是为应对这些挑战而打造的开源联邦学习SDK。通过共享模型权重(而非原始数据),它让数据科学家能够更高效地协作开发鲁棒的AI模型。该SDK(全称“联邦学习应用程序运行时环境”)构成了NVIDIA Clara Train FL软件的核心引擎,并已在医学影像分析、基因组学、肿瘤学以及COVID-19研究等AI应用中发挥实际作用。它使研究人员和数据科学家能够将现有的机器学习与深度学习工作流迁移至分布式范式,同时帮助平台开发者构建安全、保护隐私的多方协作产品。
从技术架构来看,NVIDIA FLARE 是一个轻量级、灵活且可扩展的分布式学习框架,完全基于Python实现,并且与底层的训练库无关。你可以使用PyTorch、TensorFlow甚至纯NumPy来实现自己的数据科学工作流,随后将其部署到联邦学习环境中运行。以经典的联邦平均(FedAvg)算法为例,典型流程如下:从一个初始全局模型出发,每个FL客户端在其本地数据上进行若干轮训练,然后将模型更新发送回服务器进行聚合;服务器根据聚合结果更新全局模型,再将其分发给下一轮训练。这一过程反复迭代,直至模型收敛。NVIDIA FLARE 提供了可定制的控制器工作流,用于实现FedAvg以及其他联邦学习算法(如轮次权重转移)。它负责安排不同任务(例如深度学习训练)在各个参与客户端上执行。工作流能够收集每个客户端的返回结果(比如模型更新),聚合它们以更新全局模型,并将更新后的全局模型送回客户端继续训练。图1展示了这一原理。
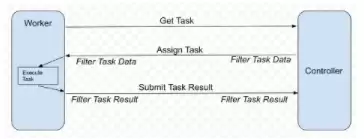
图1. NVIDIA FLARE 工作流程示意
在每个FL客户端上,实际上是一个“工人”角色,负责请求并执行下一个任务(例如模型训练)。控制器下发任务后,工人执行并返回结果。每次通信中可设置可选的过滤器来处理任务数据或结果,如同态加密/解密或差分隐私。
实现FedAvg的具体任务可以是一个简单的PyTorch程序——例如针对CIFAR-10数据集训练一个分类模型。本地的训练器代码大致如下(为简洁起见,省略了完整训练循环):
import torch
import torch.nn as nn
import torch.nn.functional as F
from nvflare.apis.dxo import DXO, DataKind, MetaKey, from_shareable
from nvflare.apis.executor import Executor
from nvflare.apis.fl_constant import ReturnCode
from nvflare.apis.fl_context import FLContext
from nvflare.apis.shareable import Shareable, make_reply
from nvflare.apis.signal import Signal
from nvflare.app_common.app_constant import AppConstants
class SimpleNetwork(nn.Module):
def __init__(self):
super(SimpleNetwork, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class SimpleTrainer(Executor):
def __init__(self, train_task_name: str = AppConstants.TASK_TRAIN):
super().__init__()
self._train_task_name = train_task_name
self.device = torch.device("cuda:0" if torch.cuda.is_a vailable() else "cpu")
self.model = SimpleNetwork()
self.model.to(self.device)
self.optimizer = torch.optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
self.criterion = nn.CrossEntropyLoss()
def execute(self, task_name: str, shareable: Shareable, fl_ctx: FLContext, abort_signal: Signal) -> Shareable:
if task_name == self._train_task_name:
epoch_len = 1
dxo = from_shareable(shareable)
if not dxo.data_kind == DataKind.WEIGHTS:
self.log_exception(fl_ctx, f"data_kind expected WEIGHTS but got {dxo.data_kind} instead.")
return make_reply(ReturnCode.EXECUTION_EXCEPTION)
torch_weights = {k: torch.as_tensor(v) for k, v in dxo.data.items()}
self.local_train(fl_ctx, torch_weights, epoch_len, abort_signal)
model_diff = ... # 计算本地训练后的权重差
dxo = DXO(data_kind=DataKind.WEIGHT_DIFF, data=model_diff)
dxo.set_meta_prop(MetaKey.NUM_STEPS_CURRENT_ROUND, epoch_len)
self.log_info(fl_ctx, "Local training finished. Returning shareable")
return dxo.to_shareable()
else:
return make_reply(ReturnCode.TASK_UNKNOWN)
def local_train(self, fl_ctx, weights, epoch_len, abort_signal):
# 注意要尊重abort_signal
for e in range(epoch_len):
...
if abort_signal.triggered:
self._abort_execution()
...
def _abort_execution(self, return_code=ReturnCode.ERROR) -> Shareable:
return make_reply(return_code)
从这段代码可以看出,任务实现能够执行多种不同操作。你可以在每个客户端上计算汇总统计信息并与服务器共享(当然需遵守隐私限制),也可以执行本地数据预处理,或者评估已训练好的模型。在联邦学习训练过程中,你还可以在每轮开始时绘制全局模型的性能曲线。下面的例子中,我们在CIFAR-10的异构数据拆分上运行了八个客户端。图2展示了NVIDIA FLARE 2.0中默认提供的几种不同配置的结果:FedAvg、FedProx、FedOpt,以及采用同态加密进行安全聚合的FedAvg(FedAvg HE)。
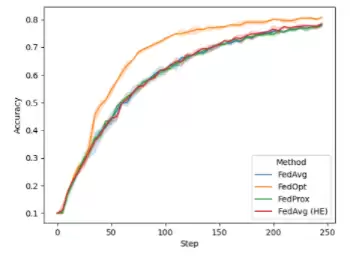
图2. 不同联邦学习算法下全局模型在训练期间的验证精度对比
从结果来看,FedAvg、FedAvg HE和FedProx在该任务中表现相当,而使用FedOpt(采用带动量的SGD来更新服务器端全局模型)可以观察到明显的收敛改善。整个联邦学习系统可通过管理API进行控制,实现不同配置的任务和工作流的自动启动与运行。NVIDIA还提供了一整套资源调配系统,用于在真实世界环境中安全、便捷地部署联邦学习应用,同时也支持在本地运行联邦学习模拟,便于概念验证研究。
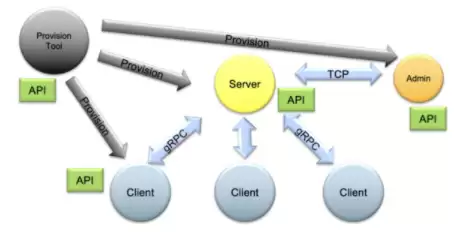
图3. NVIDIA FLARE 供应、启动、操作(PSO)组件及其API架构
总而言之,NVIDIA FLARE 让联邦学习更易于落地实施。潜在的应用场景远不止医疗领域——能源企业可借助它分析地震与井筒数据,制造商可优化工厂运营,金融公司也可改进欺诈检测模型。联邦学习的时代,才刚刚开始。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:用NVIDIA FLARE开发更通用的AI模型要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点你随手拍下一张照片,或者从相册中挑选一张图片,AI就能自动识别画面中的内容,并随即生成一句恰到好处的meme文案——这就是 MemeCam 正在实现的创意功能。它由 GPT-4o 驱动,目标非常明确:让 meme 创作变得轻松、有趣、且零门槛,人人都能成为段子手。 什么是MemeCam? MemeC
先说一个很有意思的应用——Seeing Dogs。它本质上是一款专门为视障人士打造的iPhone和iPad工具,但背后的逻辑其实很值得关注:用AI来“翻译”视觉信息,把周围的世界变得可听、可感。这个方向其实并不算新鲜,但能做到像Seeing Dogs这样把场景描述、物体识别、街道标志读取甚至菜单导航
今天我们来聊一聊名为Cargoship的产品。它的核心功能其实非常直接——为开发者提供经过预训练的AI模型,只需通过API调用即可使用。关键在于,你完全无需掌握机器学习知识,甚至不必了解模型背后的训练细节。这个工具能够直接帮助你跨越技术门槛。 目标用户群体 Cargoship精准定位了这样一类用户:
想象一下,有一个人工智能助手,它不仅能记住您上次聊到的内容,还能根据您的习惯和情绪,给出真正贴合需求的支持。不再是冷冰冰的机器人,而是像一位随时在线的朋友,用自然的语音陪伴您聊天,甚至能“读懂”您发送的图片和视频。这款Personal Voice and Vision Assistant(个人语音视
- 日榜
- 周榜
- 月榜
热点快看