




NVIDIA Jetson TX2深度学习推理性能翻倍提升

在旧金山的一场AI技术会议上,NVIDIA正式发布了Jetson TX2模块以及配套的JetPack 3 0 AI SDK。这一消息对于关注边缘计算和嵌入式AI的开发者来说,无疑是一个重磅冲击波。Jetson系列一直以来都是低功耗嵌入式平台中的佼佼者,而TX2的出现,更是将服务器级的AI计算能力真正
在旧金山的一场AI技术会议上,NVIDIA正式发布了Jetson TX2模块以及配套的JetPack 3.0 AI SDK。这一消息对于关注边缘计算和嵌入式AI的开发者来说,无疑是一个重磅冲击波。Jetson系列一直以来都是低功耗嵌入式平台中的佼佼者,而TX2的出现,更是将服务器级的AI计算能力真正推向了边缘设备。
具体来看这个小小的模块:它集成了256核的NVIDIA Pascal GPU,一个六核的ARMv8 64位CPU复合体,以及8GB LPDDR4内存,搭配128位接口。其中CPU部分很有看点,它结合了双核的NVIDIA Denver 2和四核的ARM Cortex-A57。整个模块的尺寸仅为50x87毫米,重量85克,功耗控制在7.5瓦,这样的SwaP(尺寸、重量和功耗)表现,让它能够轻松嵌入到各种空间受限的设备中。
长期以来,物联网设备大多扮演着数据中转站的角色,简单地将采集到的信息上传到云端,然后等待云端的计算结果。但边缘计算的兴起,正在改变这个局面。其核心思想就是利用本地计算能力,在数据产生的源头进行分析和处理。Jetson TX2拥有超过1 TFLOPS的浮点运算性能,非常适合部署在那些网络连接差、或者云服务成本高昂的远程现场。更重要的是,对于需要实时决策的智能机器,比如无人机和自主机器人,TX2提供的近实时响应和低延迟特性,是保证任务可靠性的关键。
从硬件架构来看,Jetson TX2基于16nm制程的NVIDIA Tegra "Parker" SoC。这块芯片最大的亮点在于深度学习推理的能效比——相比前代Jetson TX1,性能翻倍,同时能耗表现更优,甚至超越了某些Intel Xeon服务器CPU。可以说,这种效率的提升,真正重新定义了将先进AI从云端扩展到边缘的可能性。
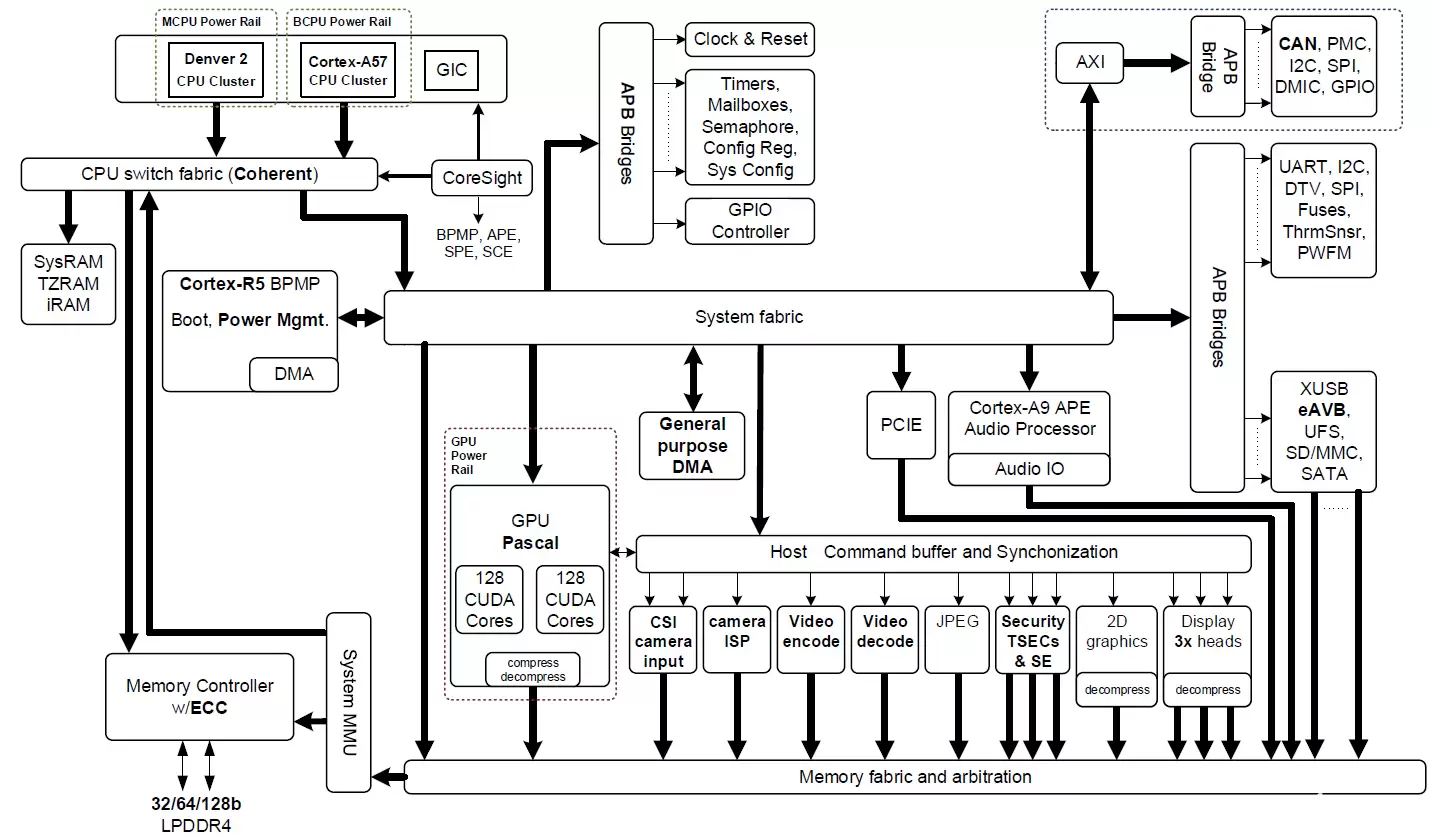
图2:NVIDIA Jetson TX2 Tegra "Parker" SoC框图,集成了NVIDIA Pascal GPU、Denver 2 + Arm Cortex-A57 CPU集群和多媒体加速引擎(点击图片查看完整分辨率)。
在多媒体处理能力上,Jetson TX2也毫不含糊。它集成了多个多媒体流引擎,这些引擎能够直接处理传感器数据的采集和分发,从而解放Pascal GPU,让它专注于更核心的计算任务。具体来说,它提供了6个专用的MIPI CSI-2摄像头端口,每通道带宽高达2.5 GB/s,并支持双图像信号处理器以1.4 GB/s的速度处理数据。视频编解码方面,它支持H.265标准,能够实现每秒60帧的4K视频编解码。
软件生态是硬件发挥实力的保障。Jetson TX2借助NVIDIA的cuDNN和TensorRT库,可以高效加速尖端的深度神经网络。无论是循环神经网络、长短期记忆网络,还是在线强化学习,都能在它上面流畅运行。对于机器人和无人机开发者来说,TX2集成的双CAN总线控制器是一个福音,它使得自动驾驶仪的集成变得非常顺畅。而这一切,都由NVIDIA JetPack 3.0和Linux for Tegra BSP提供底层的软件支持。
如果将Jetson TX2与上一代TX1做个横向对比,差异会更加直观。
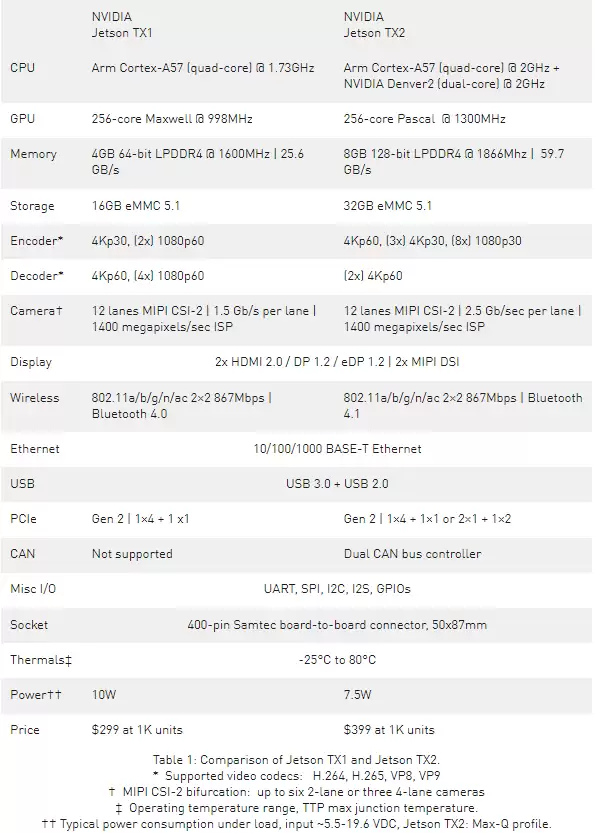
两倍的性能,两倍的效率
在JetPack 2.3的测评中,已经见证过TensorRT如何将Jetson TX1的深度学习推理效率提升到桌面级CPU的18倍以上。它的优化手段包括图优化、内核融合、FP16半精度计算以及架构自动调整。而在Jetson TX2上,TensorRT不仅利用了其硬件对FP16的原生支持,还支持批量处理多张图像,从而带来更高的性能表现。
Jetson TX2与JetPack 3.0的组合,将整个平台的性能和效率推上了一个全新的台阶。开发者可以根据应用场景,在保持与TX1相似功耗的前提下,获得近两倍的性能提升。这使得TX2成为边缘AI产品的理想选择——无论是追求极致能效比,还是需要高性能计算。更贴心的是,TX2与TX1在接口上兼容,为现有基于TX1设计的产品提供了清晰的升级路径。
为了测试这套组合的实力,我们用GoogLeNet深度图像识别网络,将Jetson TX2与服务器级的Intel Xeon E5-2690 v4 CPU做了对比。结果非常震撼:在功耗低于15W的情况下,TX2的深度学习推理吞吐量(每秒处理的图像数)比功耗接近200W的Xeon还要高。
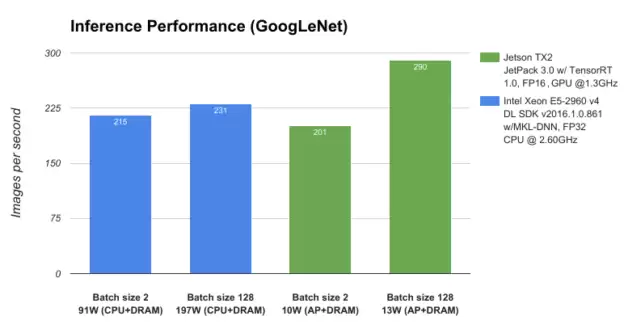
图3:GoogLeNet网络在NVIDIA Jetson TX2 与 Intel Xeon E5-2960 v4上的性能对比。
TX2之所以能实现如此卓越的AI性能和效率,主要归功于三个方面的协同:全新的Pascal GPU架构与动态能耗配置模式(Max-Q和Max-P),JetPack 3.0中经过优化的深度学习库,以及大内存带宽的支持。
Max-Q 与 Max-P
Jetson TX2在7.5W功耗下就能达到峰值处理效率,这个状态被定义为Max-Q。它代表的是功率与吞吐量曲线上的最优平衡点。为了达到这个状态,模块上的每个组件,包括电源管理,都经过了精细调优。在Max-Q模式下,GPU频率锁定在854 MHz,而Arm A57 CPU频率则是1.2 GHz。JetPack 3.0中的L4T BSP提供了一个预设的Max-Q平台配置,开发者还可以通过一个叫nvpmodel的新命令行工具,在运行时动态切换不同的配置档。
虽然动态电压频率缩放技术允许SoC根据负载实时调整时钟,但Max-Q模式人为地设定了时钟上限,确保应用程序始终工作在最高效的区间内。从实际测试来看,以GoogLeNet和AlexNet为基准,在Max-Q模式下运行的Jetson TX2,其性能与满载运行的Jetson TX1相当,但功耗仅为其一半,能效翻倍。
当然,不是所有应用都追求极致能效。对于追求峰值吞吐量的场景,Max-P模式就是为它准备的。Max-P是另一种预设配置,可在不到15W的功率内榨出最大性能。在Max-P下,GPU频率可达1122 MHz,CPU频率(当启用Denver 2集群时)可达2 GHz。开发者还可以创建自定义配置,在峰值效率和峰值性能之间找到平衡点。
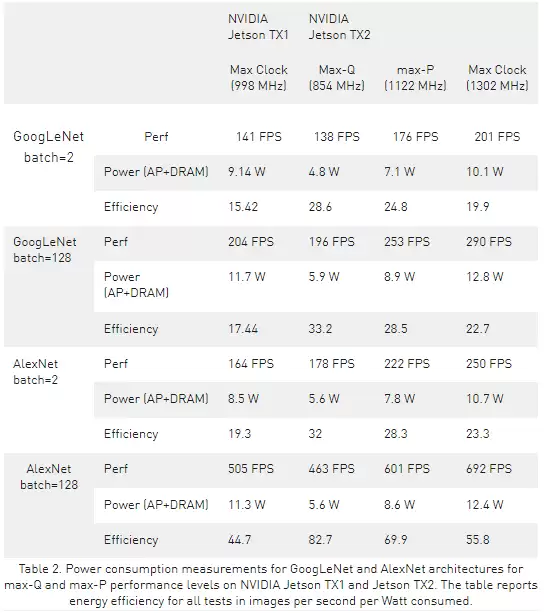
数据表明,Jetson TX2执行GoogLeNet推理时,每瓦功耗可处理33.2张图像,几乎是Jetson TX1的两倍,能效比Intel Xeon高出近20倍。
端到端的人工智能应用
Jetson TX2的强大性能,源于其内部的2个Pascal流式多处理器,每个包含128个CUDA核心。CPU复合体则是由双核NVIDIA Denver 2(动态代码优化,高单线程性能)和四核Arm Cortex-A57组成。值得注意的是,Denver 2和A57共享一个高性能的互连结构,并配备2MB的二级缓存。这种设计允许任务在异构多处理环境中无缝迁移,高效地利用所有核心资源。
对于自主机器来说,Jetson TX2是实现端到端AI管线的理想平台。它能够利用CSI、PCIe、USB3和千兆以太网等高速接口,同时接收多个传感器的实时数据,并在GPU处理完毕后,进行媒体解码/编码、网络传输和低层指令控制。一个典型的流水线包括:传感器数据采集、CUDA预处理(如图像色域转换)、DNN网络推理、以及结果统计分析。
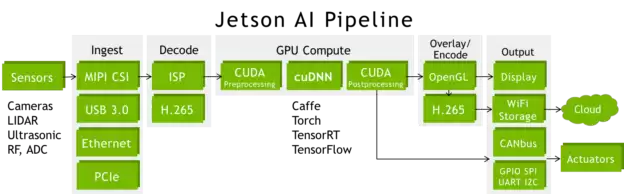
图4:端到端AI管道,涵盖了传感器采集、处理和指挥控制。
由于内存和带宽是Jetson TX1的两倍,TX2能够轻松处理额外的数据流,比如立体摄像头和4K超高清视频。通过深度学习与计算机视觉的融合,它能够将来自不同来源(如可见光、红外等)的传感器信息融合起来,极大地增强了机器人的感知能力和态势感知能力。
Jetson TX2 开发套件入门
为了让开发者快速上手,NVIDIA提供了一个参考设计的小型ITX载板和一个500万像素的MIPI CSI-2摄像头模块。这个开发套件配备了USB3、HDMI、千兆以太网、SD卡和PCIe x4插槽等标准接口,几乎可以像开发一台标准PC一样进行应用开发。
如果要走向定制化部署,则可以修改参考设计的文件来创建自己的硬件。当然,NVIDIA的生态系统合作伙伴也提供了许多现成的微型载板、外壳和摄像头解决方案。NVIDIA开发者论坛则是技术支持和协作的理想社区。

Jetson TX2开发套件已经开始接受预定。同时,针对教育机构也有相应的折扣方案。此外,NVIDIA也将Jetson TX1开发套件的价格进行了下调。
JetPack 3.0 SDK 开发包
最新的JetPack 3.0为Jetson TX2提供了业界领先的AI开发工具和硬件加速API,包括CUDA 8.0、cuDNN、TensorRT、VisionWorks、GStreamer和OpenCV,这些全都建立在Linux内核v4.4、L4T R27.1 BSP和Ubuntu 16.04 LTS之上。值得一提的是,它还包含用于交互式分析和调试的Tegra系统探查器和图形调试器工具。在刷机时,JetPack会自动配置好完整的开发环境,实现开箱即用。

Jetson是一个高性能的嵌入式解决方案,能够无缝部署Caffe、Torch、Theano和TensorFlow等深度学习框架训练好的模型。得益于cuDNN的集成,大多数框架的模型只需少量调整就能迁移到Jetson上。
Two Days to a Demo
为了降低入门门槛,NVIDIA发起了"Two Days to a Demo"项目。该项目提供了计算机视觉原语(如图像识别、目标检测和分割)、用DIGITS训练的神经网络模型,以及示例流式应用程序。开发者可以将这些模型部署到Jetson上,通过TensorRT进行高效的推理。项目代码在GitHub上开源,并附有详细的指导教程。
这个工作流的核心优势在于迁移学习。开发者可以使用预训练的网络,结合自己的自定义数据,快速训练出满足特定任务的模型。比如,对于自主导航的机器人来说,NVIDIA在"DIGITS 5"中增加了对分割网络的支持。分割原语使用FCN-Alexnet架构,对视野中的每个像素进行分类。这种像素级的理解能力,对于路径规划和障碍物规避至关重要。
为了鼓励自主飞行控制模式的开发,空中训练数据集、分割模型和相关工具也已发布在GitHub上。可以说,Jetson TX2与"Two Days to a Demo"的组合,让开发者们进入先进深度学习应用领域的门槛大大降低了。
Jetson 生态系统
Jetson TX2模块化的外形设计,让它能适应各种应用场景。NVIDIA开源的参考载板设计为定制化提供了绝佳的起点。一些生态系统合作伙伴甚至提供了与Jetson模块尺寸相同的50x87mm微型载板,可以实现极其紧凑的集成。从工业级的MIL-STD-801G认证模块,到高密度1U机架式服务器(可容纳多达24个Jetson模块),Jetson的生态系统已经覆盖了从边缘到数据中心的广泛领域。其低功耗和无风扇设计,对于需要轻量级、可扩展的云任务,如低功耗Web服务器、多媒体处理和分布式计算,也极具吸引力。
AI 在边缘
总的来说,Jetson TX2以其无与伦比的嵌入式计算能力,将尖端深度学习和下一代人工智能真正带到了边缘设备上。它提供了服务器级的能效比,原始深度学习性能是Intel Xeon的1.25倍,而计算效率却高出近20倍。这个紧凑的平台,配合功能强大的JetPack软件栈,正在让越来越多的开发者有能力利用AI去解决21世纪面临的现实挑战。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:NVIDIA Jetson TX2深度学习推理性能翻倍提升要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点OmniParser是微软AI驱动的SaaS工具,基于YOLOv8和BLIP-2,将UI截图与漫画页面解析为结构化数据,支持UI元素检测、漫画面板分析、对话框及人脸识别,适用于自动化测试、漫画翻译等场景。
通义灵码是贯穿开发全流程的智能编码助手,具备代码智能生成、研发智能问答、多编程语言及编辑器支持、代码安全隐私保障四大核心能力,适用于学生、新手及企业开发者等多类人群,提升编码效率。
基于人工智能的自动化道路巡逻和资产数据收集方案,通过车载相机自动采集路面及周边资产数据,识别裂缝、坑槽等病害并建立数字化台账,同时自动删除隐私图像,实现从被动响应向主动预防的转变,降低巡检成本。
阿里旗下通义智文是一款智能阅读工具,支持网页、论文、图书和自由阅读四种场景,帮助用户快速提取核心观点,节省阅读时间,适合学生、研究人员及职场人士高效处理大量文本。
- 日榜
- 周榜
- 月榜
热点快看