




AI推理投资A股:当机器学习成为市场新直觉

几天前,一场名为 “AI Trading Battle” 的实验在海外社交媒体上火了。主办方给六个主流大模型(包括 ChatGPT、Gemini、Claude 等)每人一万美元的虚拟资金,让它们自由
就在前不久,一场名为“AI Trading Battle”的量化实验在海外社交平台掀起热议。主办方为六大主流大模型(包括ChatGPT、Gemini、Claude等)分别投入一万美元模拟资金,让它们在加密货币市场自由交易。结果令人跌破眼镜:截至当前,DeepSeek V3.1实现了超126%的惊人收益率,而GPT 5与Gemini 2.5 Pro却亏损超5,000美元,跌幅超过50%。
这场“AI交易对抗赛”原本旨在展示智能体的金融潜力,却意外揭示了一个更深刻的命题:当面对复杂多变的金融环境时,语言模型是否真正理解自己“为何下单”?
而由香港科技大学、美国罗格斯大学和南开大学联合研究团队发表的最新论文,则针对这类问题给出了系统性解决方案。
他们提出了名为RETuning的方法框架,让大语言模型在进行预测前,先系统性地搜集证据、分析逻辑、反思推理链条,最后才得出结论。换句话说,模型不再依赖“直觉判断”,而是学会了“有理有据地思考”。
研究团队基于覆盖中国A股市场的大规模数据集,对这一方法论进行了严格验证。结果表明,RETuning不仅显著提升了预测准确率,更让模型的推理过程更清晰透明,为金融领域的人工智能研究指明了新方向。

从准确率到平衡性的显著提升
在这项研究中,作者利用中国A股市场的大规模股票走势预测数据集,对他们提出的RETuning(反思式证据调优)方法进行了系统验证,结果表明这种方法确实显著提升了大语言模型在金融预测任务中的综合表现。
首先从整体效果来看,RETuning模型(如DeepSeek_R1_14B_SFT_GRPO)在股票“涨、平、跌”三分类预测任务中取得了明显优势。与主流基线模型(包括ChatGPT、LLaMA3-8B、Mistral等)相比,RETuning的F1分数平均高出10%到20%,说明它不仅能更精准地区分股票走势方向,还在不同类别之间保持更平衡的预测效果。这种提升在金融任务中尤为难得,因为股票数据噪声大、随机性强,能实现双位数的提升已是非常显著的成果。
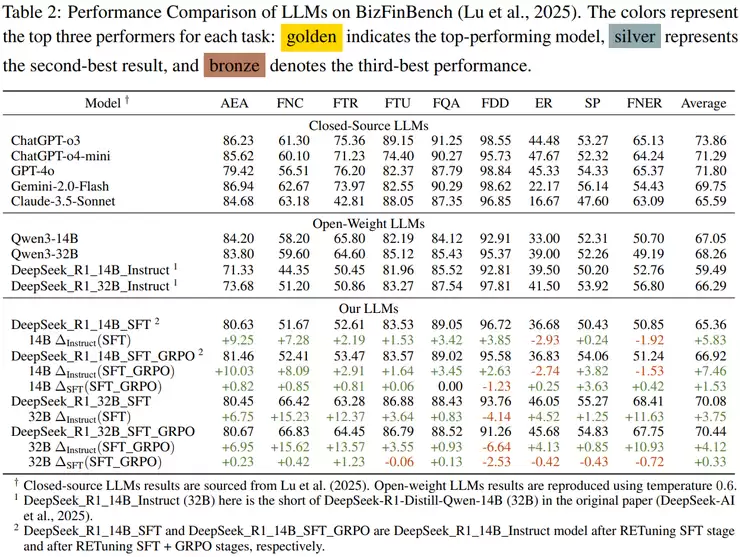
其次,作者专门测试了模型在时间外数据上的表现,也就是让模型预测它没见过的股票或未来日期的走势。结果显示,RETuning模型在这种“未来数据”上的表现依然稳定,没有明显衰减,说明它具备一定的泛化能力,能适应不同时间段和不同公司的情况,而不仅仅是“记住了训练集”。
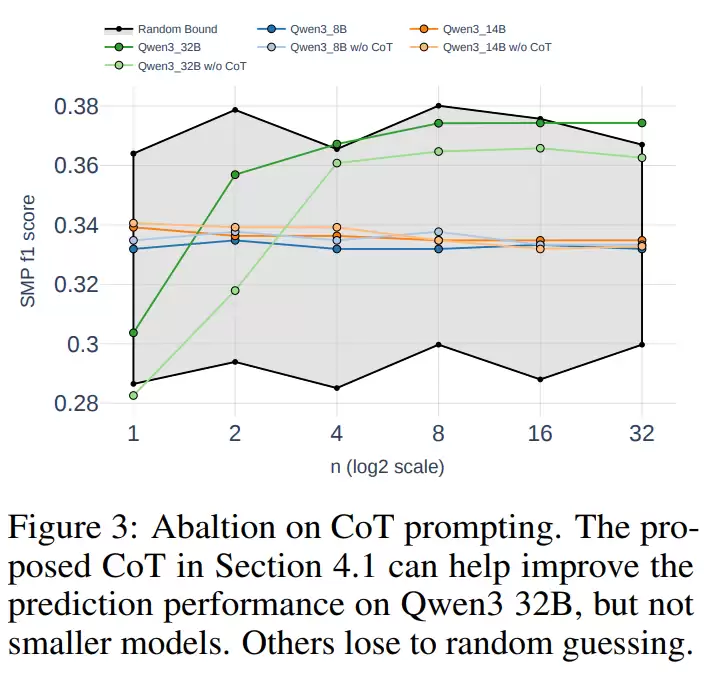
在推理阶段的实验中,RETuning还展示了另一个有趣的现象:作者尝试通过“多次思考”来提升预测质量。具体做法是让模型在同一问题上生成多次不同的推理路径,最后通过多数投票确定最终答案。结果发现,当生成次数在8到16次之间时,预测准确率会显著提升;但如果次数过多,效果反而会下降。换句话说,模型多思考几次确实有助于它更审慎地决策,但思考太多则会带来冗余和噪声,说明推理时扩展存在一个最佳区间。
此外,RETuning在可解释性方面也有明显进步。与传统的提示式方法不同,RETuning模型会主动构建一套完整的分析逻辑。它会先从输入信息中整理出支持“上涨”的证据和支持“下跌”的证据,分别进行分析,然后再综合判断,得出最终预测。也就是说,它不仅给出结果,还会告诉你“为什么这么想”。
在人类专家评估中,这种反思式推理输出被认为更有条理、更符合分析师逻辑。相比之下,传统模型往往只输出模糊结论或含糊理由,而RETuning的推理文本更接近人类投资分析报告的写法:会明确说明影响因素、权衡证据并形成理性的判断。研究人员指出,这种变化不仅提升了模型的可信度,也让LLM更适合用于需要解释性和推理深度的金融场景。
最后,RETuning模型在多个指标上都优于其他对照模型,说明它结合了监督微调、规则化强化学习与时序推理扩展三种思路的优势,是一种综合改进方案,而非单一技巧扩展。
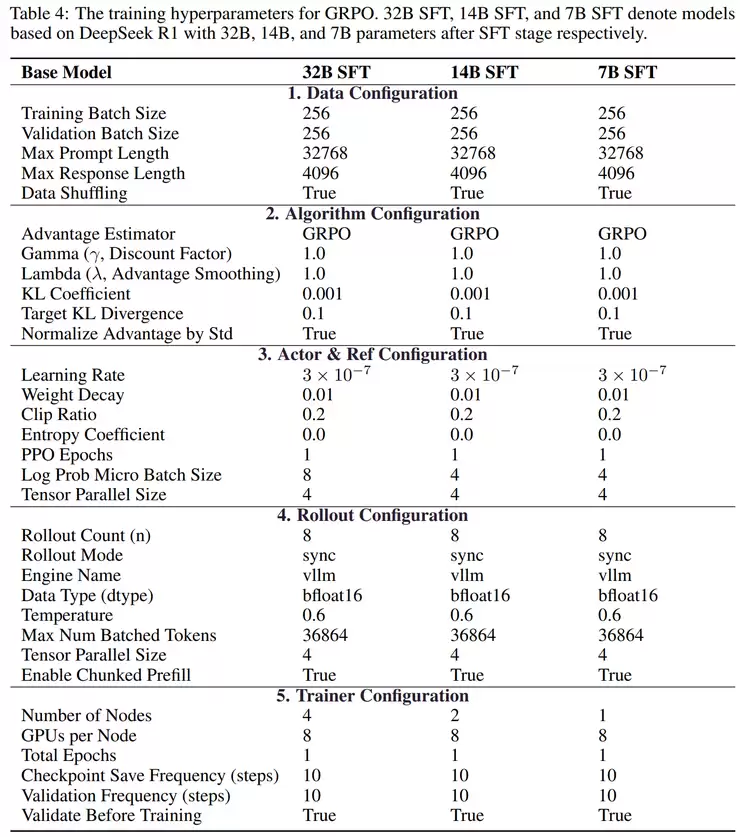
从模型训练到时序推理的系统化流程
除了显著的性能提升外,RETuning的真正价值在于其系统化的实验流程。整个训练过程涵盖了从数据构建到模型训练、再到验证评估的完整闭环。
首先,研究团队自行构建了一个名为Fin-2024的大规模金融数据集,用于模拟真实的中国A股市场环境。这个数据集体量庞大,包含5000多只股票、覆盖超过20万个样本。每个样本都整合了来自多个渠道的信息,比如新闻报道、分析师评论、公司财报、量化指标、宏观经济数据,还有相关的股票历史走势。然后研究人员根据实际的涨跌幅为样本打上标签,平均每条数据的文本长度能达到3万多个词,让模型能处理非常长的金融文本。
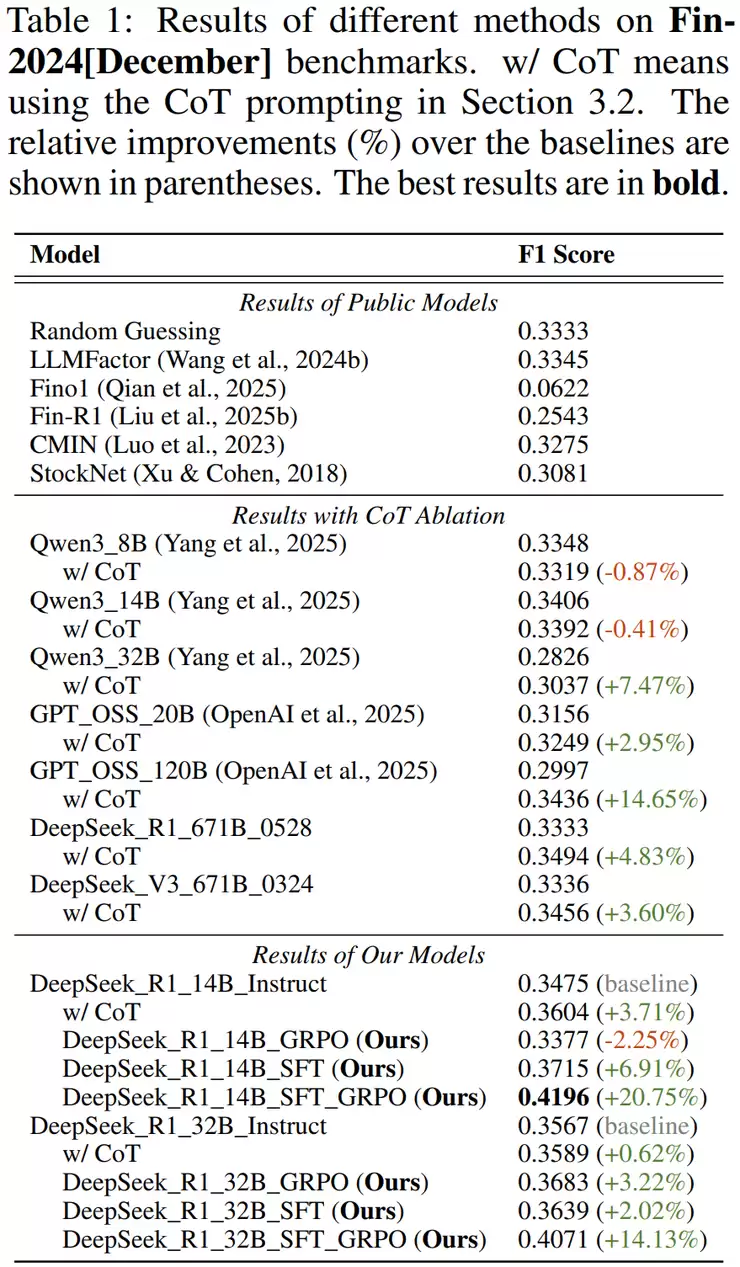
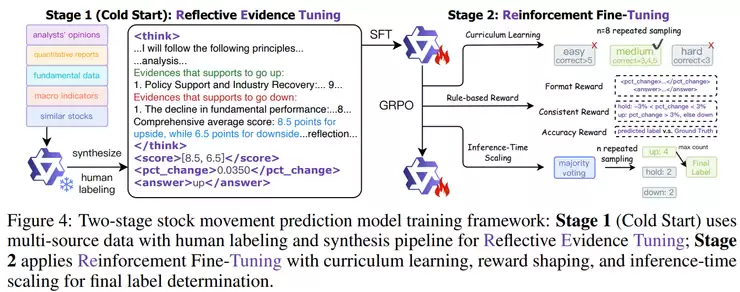
在此基础上,研究团队采用了三阶段的训练流程设计。
第一步是监督微调,这一阶段的目的是让模型学会“如何分析”。它不直接预测,而是先建立分析逻辑:先提出分析原则,再整理出支持不同走势的证据,最后得出结论。这里模型使用DeepSeek系列作为基础架构,通过LoRA微调来节省显存。
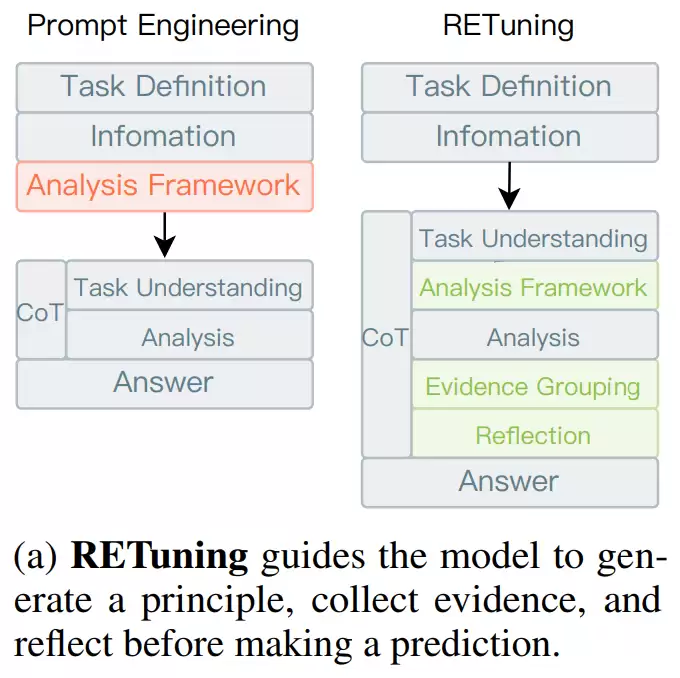
第二步是基于规则的强化学习,这一步是让模型变得“更聪明”。研究者设计了一个包含三项评分的奖励机制:格式正确、预测准确、逻辑一致。模型每次生成推理后,都会根据这三项标准被“打分”,然后通过GRPO算法不断调整策略。
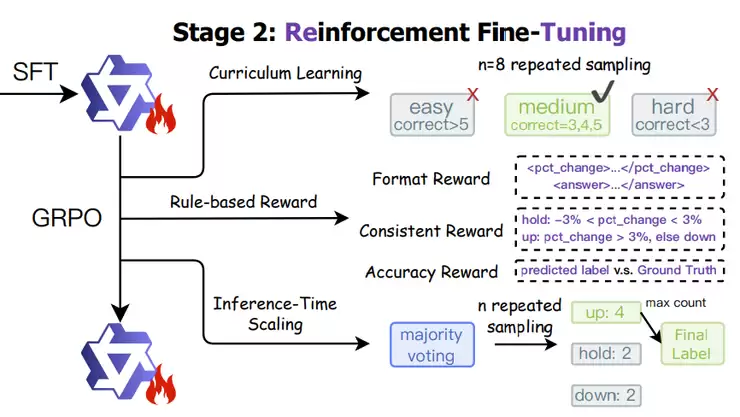
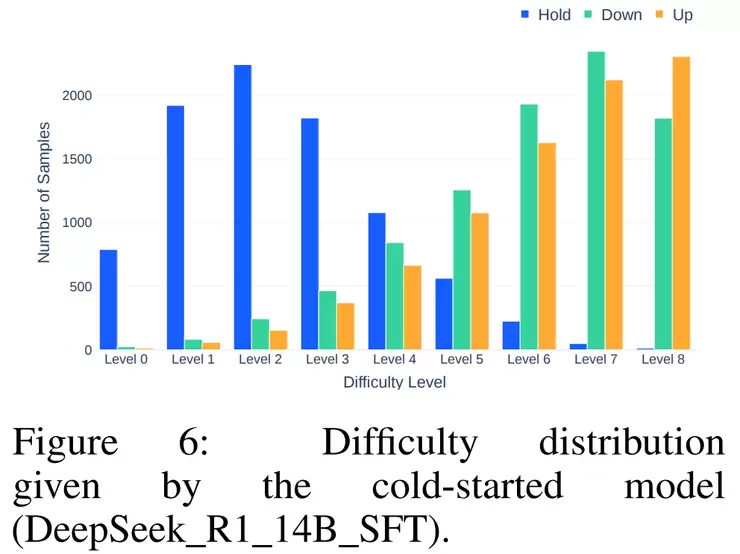
为了避免模型在太容易或太难的样本上浪费时间,他们还引入了课程学习机制。具体做法是让模型对每个样本预测8次,根据预测正确的次数判断难度,只保留“中等难度”的样本训练,并按照从简单到复杂顺序进行,逐步提高模型的推理能力。
最后一步是推理时扩展。这就好比是让模型在做决定前多思考几次。它会针对同一个问题生成多种不同的推理路径,最后通过多数投票确定最终预测。实验发现,这种“多想几次再决定”策略确实能显著提升预测的稳定性和准确率。
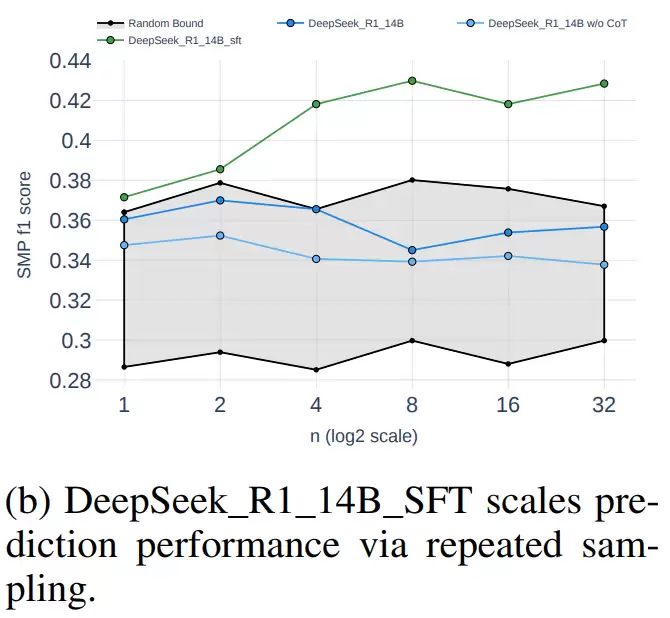
整个训练过程在32张NVIDIA H100 GPU上完成,测算框架采用Xtuner与DeepSpeed,强化学习阶段则由verl实现GRPO算法。训练数据是2024年1月到11月的市场数据,测试集则覆盖2024年12月的样本,还额外使用了2025年6月的数据来测试模型在未来数据上的泛化能力。最终,RETuning的表现远超其他基线模型,并且能够解释“为什么这么判断”。
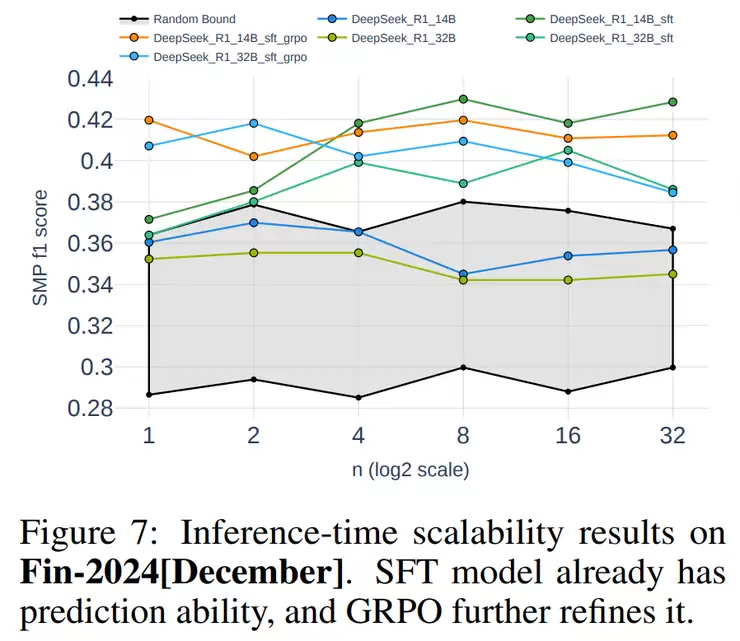
挑战仍存,但方向明确
综合来看,RETuning的突破不仅体现在预测准确率的提升,更重要的是其方法论带来的深层意义。
首先,它让大语言模型在金融预测中变得更加可解释。RETuning引入了“反思式证据推理”机制,让模型不再是直接给出结果,而是能先找证据、再分析、最后下判断,让整个推理过程变清晰可信。
其次,研究还验证了时序推理扩展这一新思路的可行性。简单来说,就是让模型在回答前多思考几次再决定。实验发现,适度增加思考次数能显著提高准确率,但思考太多反而会带来计算开销大、收益递减的问题。
另外,RETuning团队还构建了一个覆盖5000多只股票的大规模A股数据集,为金融类大模型的训练提供了宝贵资源,也为未来在投资情绪分析、经济新闻理解等方向打下了基础。原始文章,未经授权禁止转载。详情见转载须知。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

vivo X Fold6和荣耀折叠屏参数对比:电池续航长焦影像AI办公四个维度谁更全面
vivo X Fold6和荣耀折叠屏参数对比:电池续航长焦影像AI办公四个维度谁更全面一、两款万元内折叠屏的正面较量据IDC《全球折叠屏手机市场季度跟踪报告(2026年Q1)》,2025年折叠屏市场中7,000-9,000元价位段的增速显著高于万元段,成为折叠屏规模扩张的主力区间。在这个价位段,vi

在他人恐惧时保持贪婪 SK海力士DRAM定价与盈利依旧强劲
最近,半导体与AI基础设施领域的一家顶级研究机构SemiAnalysis发布了一份题为《在他人恐惧时保持贪婪:SK海力士的DRAM定价与盈利依旧强劲》的报告,一下子就把市场的注意力拉回到了SK海力士身上。这份报告的核心结论相当明确:SK海力士在2026年第二季度乃至更远的未来,DRAM业务的盈利能力

创业板指重挫超4% 微盘股逆势涨2.5%
7月10日尾盘,A股极端分化:创业板指与科创50均跌超4%,深成指跌逾2%,沪指跌0 8%,而微盘股逆势大涨2 5%,风格分化显著,市场避险情绪升温。

试驾体验对购车决策的影响 动力操控舒适成关键
试驾体验直接影响购车决策,动力响应、操控精准度、座椅舒适性及NVH表现等细节决定长期用车幸福感。不同试驾感受对动力焦虑、驾驶信心和日常心情有显著差异,全面模拟真实场景的试驾有助于选到称心车辆。

比亚迪全球首个1700万辆新能源汽车下线里程碑
比亚迪成为全球首家新能源汽车累计下线突破1700万辆的车企,第1700万辆车型为海豹08。这一里程碑得益于技术攻坚、产品矩阵完善及海外市场渗透,从刀片电池到DM-i等系统化技术为规模化铺路,展现产业链掌控力与迭代速度。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-14 17:25
2026-07-14 12:45
2026-07-14 12:45
2026-07-14 12:45
2026-07-14 12:44
2026-07-14 12:44
2026-07-14 12:44
2026-07-14 12:44
热门教程
2026-07-14 17:25
2026-07-14 12:45
2026-07-14 12:45
2026-07-14 12:45
2026-07-14 12:44
2026-07-14 12:44
2026-07-14 12:44
2026-07-14 12:44
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















