




牛剑港大联合发布ELIP:多模态检索超CLIP,视觉语言预训练新突破

来自牛津大学VGG实验室、香港大学和上海交通大学的联合研究团队在最新论文中提出了一种创新方法,能够利用学术界的有限计算资源来强化视觉语言大模型的预训练性能,从而在图文检索任务中获得更精准的匹配效果。
多模态图文检索作为计算机视觉与跨模态机器学习领域的重要任务,当前业内普遍采用CLIP/SigLIP等视觉语言大模型。这类模型经过海量数据预训练后,在零样本场景下展现出卓越的判别能力。
该论文已被IEEE国际多媒体内容索引大会接收,并荣获最佳论文提名。近期在爱尔兰都柏林举行的会议上,这项研究获得了学术界的广泛关注。

关键技术:大规模预训练模型;视觉语言模型;图像检索系统 项目主页:https://www.robots.ox.ac.uk/~vgg/research/elip/ 论文链接:https://www.robots.ox.ac.uk/~vgg/publications/2025/Zhan25a/zhan25a.pdf 代码仓库:https://github.com/ypliubit/ELIP
方法概述
下图直观展示了ELIP方法的架构设计。该方法的核心理念在于采用两阶段检索机制:首先通过传统的CLIP/SigLIP模型进行初步排序,随后对候选样本进行精细化重排。
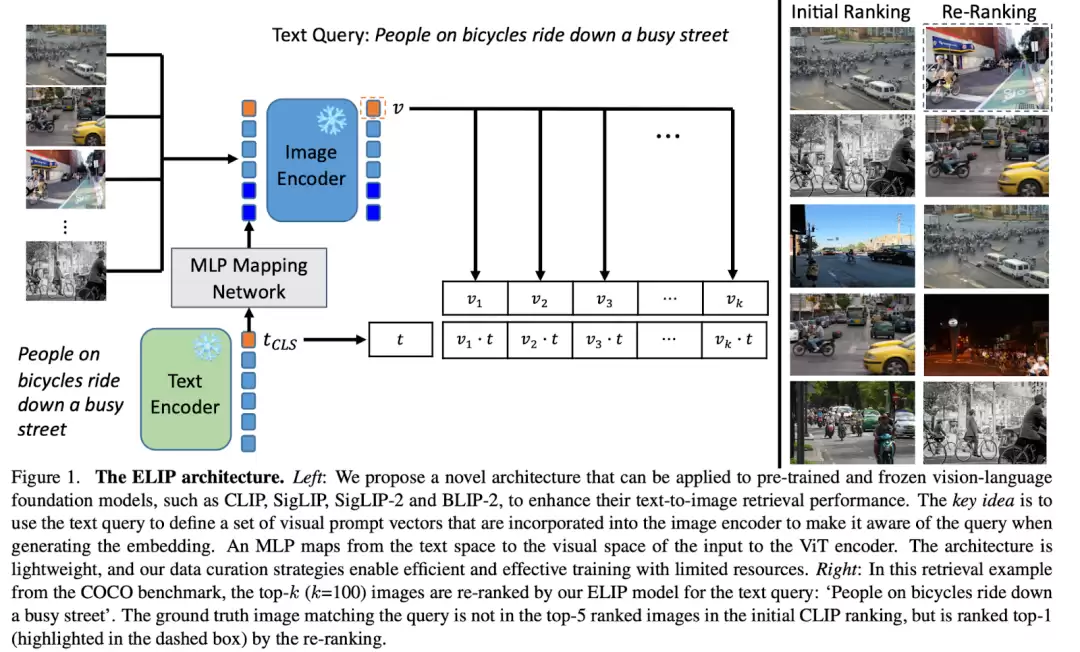
在重排阶段,研究团队设计了一个轻量级的MLP映射网络,将文本特征转化为视觉域的可感知标记。这些标记被注入图像编码器后,使得模型在编码视觉信息时能够同步感知语言语义。经过重新编码的图像特征与文本特征进行对比时,同一查询语句能获得更优化的排序结果。该方法可适配CLIP/SigLIP/SigLIP-2/BLIP-2等主流视觉语言模型,分别形成ELIP-C/ELIP-S/ELIP-S-2/ELIP-B等变体。
学术研究的资源挑战
视觉语言大模型的预训练通常需要工业级计算资源,但这项研究提出的方法使得仅用两张GPU进行训练成为可能。其创新性主要体现在模型架构设计与训练数据构建两个方面。
核心创新:模型架构设计
在模型架构方面,庞大的图像编码器与文本编码器权重保持冻结,仅需训练由三层线性层与GeLU激活函数构成的MLP映射网络。
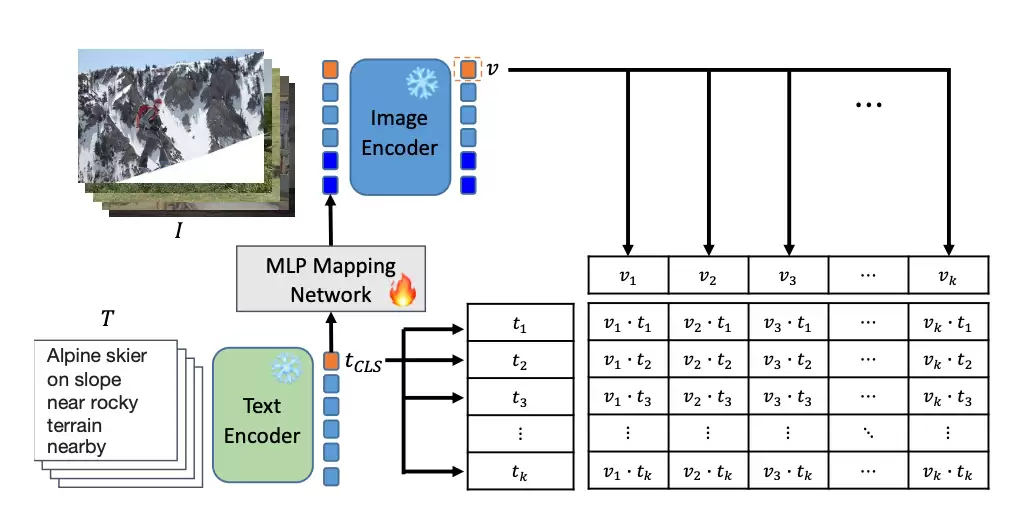
下图展示了ELIP-C与ELIP-S的训练流程。在训练过程中,每个批次的图文对输入模型后,文本特征会被映射到视觉特征空间,从而引导图像信息的编码过程。对于CLIP模型沿用InfoNCE损失函数,而SigLIP模型则采用Sigmoid损失函数,以此对齐文本特征与重新计算的图像特征。
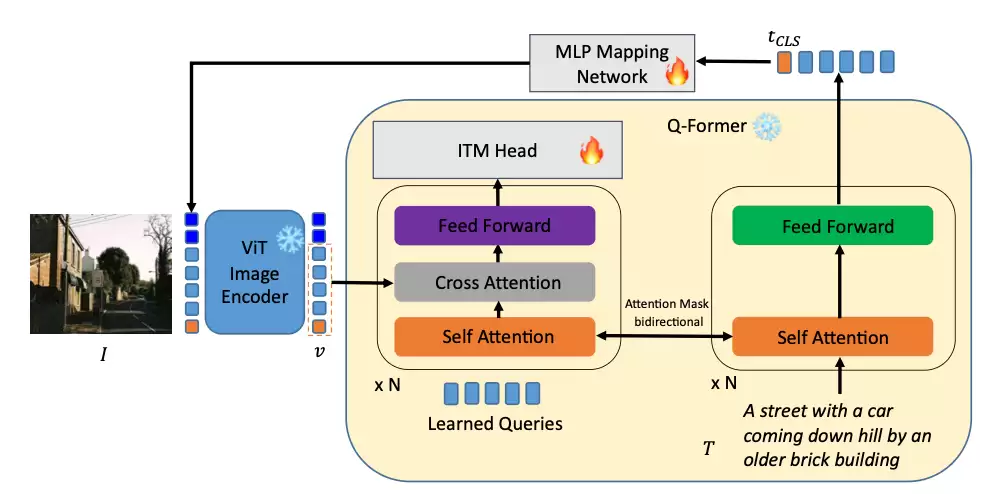
下图呈现了ELIP-B的训练示意图。与CLIP/SigLIP类似,MLP映射网络将文本特征投影到视觉特征空间。独特之处在于,由文本引导生成的图像特征会输入Q-Former模块与文本进行交叉注意力计算,最终通过ITM头部预测图文匹配程度。ELIP-B训练时采用BLIP-2的BCE损失函数。
核心创新:训练数据构建
在训练数据层面,学术界进行大模型训练面临的主要挑战在于GPU数量有限,无法采用大规模批次进行训练,这可能导致模型分辨能力下降。而ELIP方法需要区分CLIP/SigLIP排序生成的困难样本,对模型判别力提出了更高要求。为解决这一难题,研究团队在训练时预先计算每张训练图片及其对应文字标题的CLIP特征,然后将特征相似的图文对聚集在一起形成困难样本训练批次。下图展示了聚合后的训练批次示例:首行样本的描述文字分别为“无底座的木制餐桌”“带折叠桌腿的木质餐桌”“金属底座配橄榄木桌面的桌子”“放置于沥青路面上的户外小桌”;第二行样本描述包括“山涧中漂浮的巨大蓝色冰体”“从悬崖崩落的大块冰川”“地面上碎裂的玻璃残片”“群山环抱的森林水域”。
创新评估基准
除在COCO、Flickr等标准测试集上进行评估外,研究团队还提出了两个新的分布外测试集:遮挡COCO和ImageNet-R。
在遮挡COCO数据集中,正样本包含文字描述的物体(通常被部分遮挡),负样本则不包含所述物体。对于ImageNet-R数据集,正样本包含文字描述的物体,但这些物体来自非常见领域,负样本则不含对应物体。下图展示了具体案例:首行为正样本,次行为负样本。在遮挡COCO中,正样本包含被遮挡的自行车,负样本不含自行车;在ImageNet-R中,正样本包含金鱼,负样本不含金鱼。

实验结果
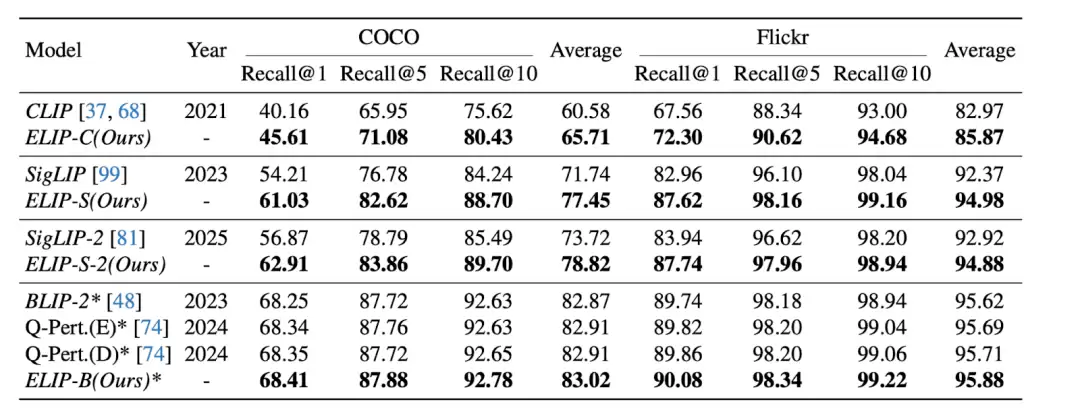
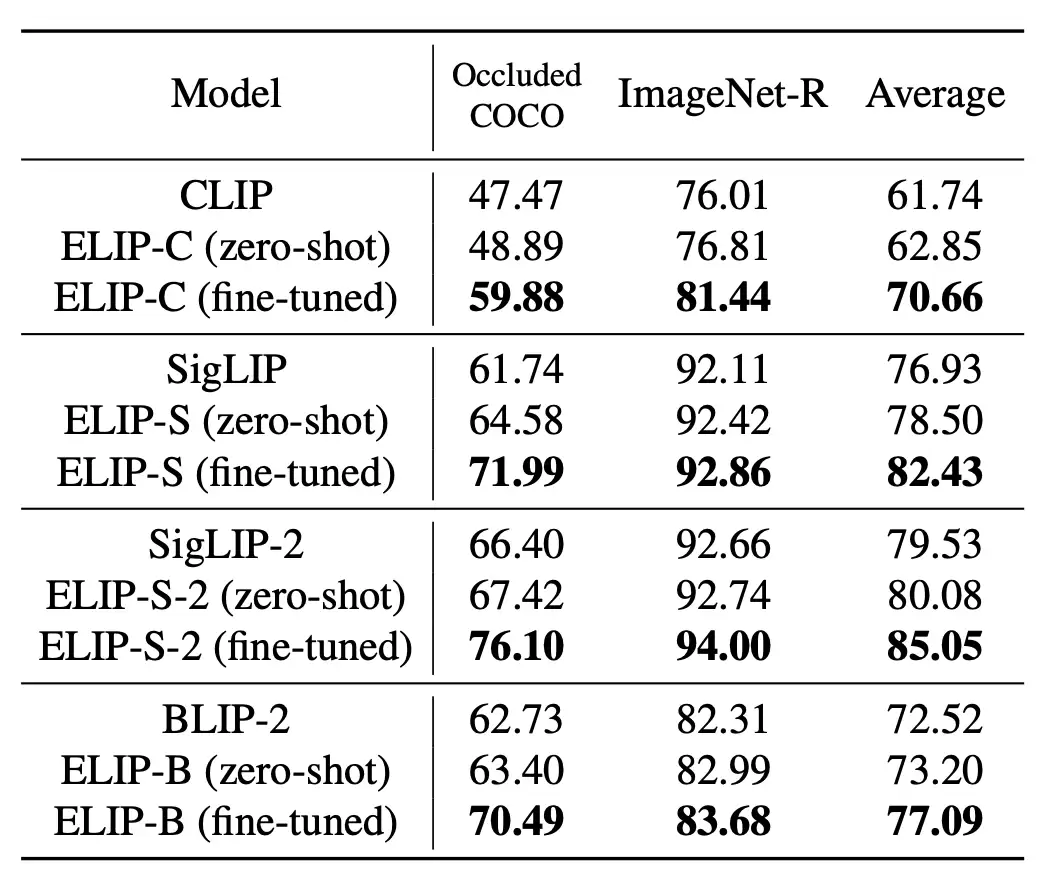
如下表所示,应用ELIP方法后,CLIP/SigLIP/SigLIP-2在图像检索任务上的表现均实现显著提升,其中SigLIP系列模型甚至达到了与BLIP-2相近的水平。ELIP-B在BLIP-2上的应用也显著提升了模型性能,超越了最新的Q-Pert方法。
在分布外测试集上,ELIP系列模型均实现了零样本泛化能力的提升。若在对应领域进行微调——例如在COCO数据集上对遮挡COCO任务微调,在ImageNet数据集上对ImageNet-R任务微调,还能获得更显著的性能提升。这进一步表明ELIP方法不仅能增强预训练效果,还提供了一种高效的自适应机制。
通过可视化注意力图可观察到,当文本查询与图像内容相关时,ELIP能提升图像编码器对文本描述相关区域的关注度。

更多技术细节详见论文原文。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

蚂蚁开源万亿参数思考模型Ring-2.5-1T详解
Ring-2 5-1T是什么 在当今大模型技术激烈竞争的赛道上,追求更长的上下文处理能力和更强大的深度推理性能已成为核心焦点。近日,蚂蚁集团旗下的inclusionAI团队重磅开源了Ring-2 5-1T模型,这是一个参数规模高达万亿级别的混合线性思考大语言模型。该模型基于先进的Ling 2 5架构

Teamily AI:原生智能通讯平台,开启人机协作新纪元
Teamily AI是什么 想象一下,你手机里的微信群聊,除了家人朋友同事,还多了一位特殊的“成员”——它从不缺席,能瞬间理解所有对话,还能帮你处理图片、视频甚至写报告。这不再是科幻场景,而是南加州大学团队带来的现实:全球首个AI原生即时通讯平台,Teamily AI。 它的核心思路很巧妙:不再把A

字节跳动Seedream 5.0 Lite AI图像生成模型详解
Seedream 5 0 Lite是什么 在AI图像生成技术飞速发展的今天,字节跳动Seed团队正式推出了其重磅升级产品——Seedream 5 0 Lite。作为Seedream 4 0的迭代版本,这款全新的AI绘画模型在文本理解、视觉推理与图像生成三大核心维度上实现了显著突破。 该模型采用了创新

WorkAny Bot云端AI助手基于OpenClaw框架详解
WorkAny Bot是什么 想象一下,有一个永不掉线的智能助手,它住在云端,随时准备响应你的召唤。这就是WorkAny Bot——一个基于OpenClaw AI框架构建的云端智能体。它的核心价值在于,将强大的AI能力变成一项即开即用的服务。 你可以把它理解为你私人的、功能齐全的AI工作站。它支持接

KiloClaw推出全托管云服务OpenClaw
KiloClaw是什么 想快速拥有一个能接入几十个聊天平台、还能执行系统命令的AI助手,但一听到要自己部署维护就头疼?这确实是很多开发者和团队面临的现实困境。OpenClaw这个开源项目功能强大,支持50多种平台,可真要自己从零搭建,光是配置环境可能就得折腾半小时以上,后续的更新、监控更是麻烦事。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
