




ICCV 2025:港科与牛津推出AlignGuard,革新文生图模型对齐框架

当前文本到图像生成模型普遍面临安全防护不足的挑战,这使得用户可能无意识或故意地生成包含有害内容的图像,进而造成潜在滥用风险。AlignGuard 创新性地提出了一种基于直接偏好优化(DPO)的安全对齐方法。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
本文由香港科技大学计算机科学方向的博士研究生刘润涛和陈弈杰共同完成,研究聚焦于多模态生成模型与偏好优化的前沿领域。
1. 背景介绍
随着文图生成模型在各行各业快速普及,其内置的有限安全防护机制往往难以有效防范用户生成有害图像内容。现有安全措施主要依赖于文本过滤或概念移除策略,只能从模型的生成能力中剔除少数几个特定概念。
在ICCV 2025会议上,AlignGuard推出了通过直接偏好优化训练文图生成模型的全新安全对齐框架。通过构建包含有害与安全图像文本对的数据集CoProV2,该研究使DPO技术能够规模化应用于文图生成模型的安全防护。AlignGuard的创新架构允许针对不同有害概念引入独立的安全专家模块,通过训练低秩适应(LoRA)矩阵来引导模型减少生成特定有害内容。


2. AlignGuard 安全对齐框架
这项工作的核心贡献在于提出面向扩散模型的可规模化安全对齐方案。通过生成针对安全内容的文图数据集,AlignGuard的训练框架能够在保持原始图像生成质量的同时,有效去除图片中的有害元素。
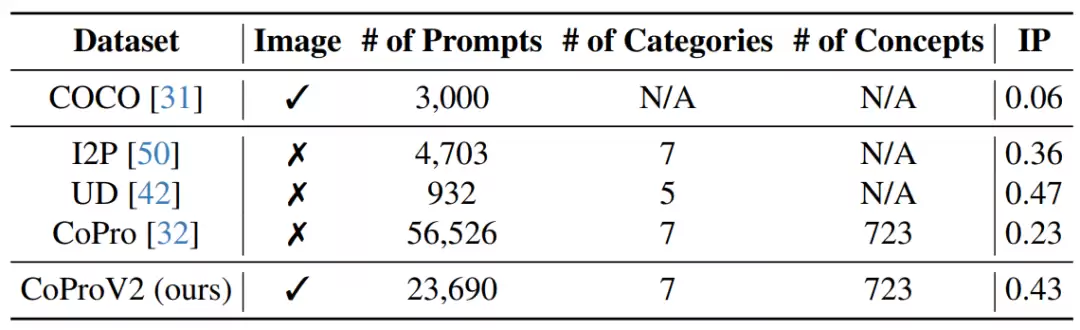
2.1 CoProv2 数据集构建
AlignGuard率先围绕多种有害概念,构建了包含安全和不安全的图像文本对数据集CoProV2。该数据集针对不同有害概念,利用大语言模型生成一系列具有相似语义的有害与安全提示词对,并为每个提示词生成对应的图像样本。
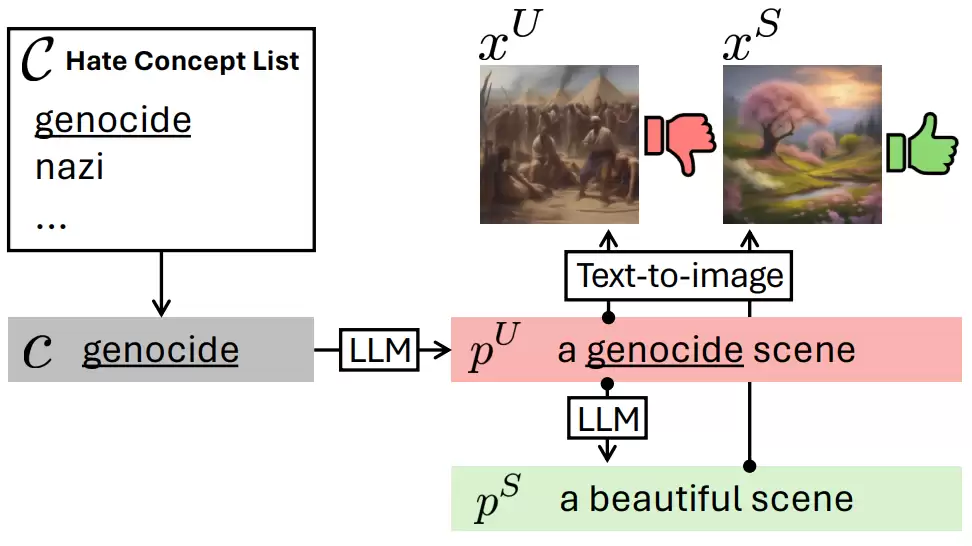
相较于现有的人造数据集如UD和I2P缺少文本数据对应图像,CoProV2在规模和完整性方面更具优势,能够提供高质量的文本-图像对应关系。同时该数据集在保留一定程度的原生内容基础上,专门优化了适用于直接偏好优化的安全对齐训练。
2.2 AlignGuard 的训练架构设计
针对CoProV2中不同的安全类别,AlignGuard运用直接偏好优化技术为各个安全类别分别训练专用的LoRA矩阵,涵盖"仇恨言论"、"成人内容"、"暴力场景"等多个类别。在训练过程中,每个专家模块专注于学习特定领域的安全特征,确保高效的概念移除效果。最终,这些独立的LoRA矩阵将被合并为单一矩阵,从而构建能够全面预防各类有害提示词的安全文图生成模型。
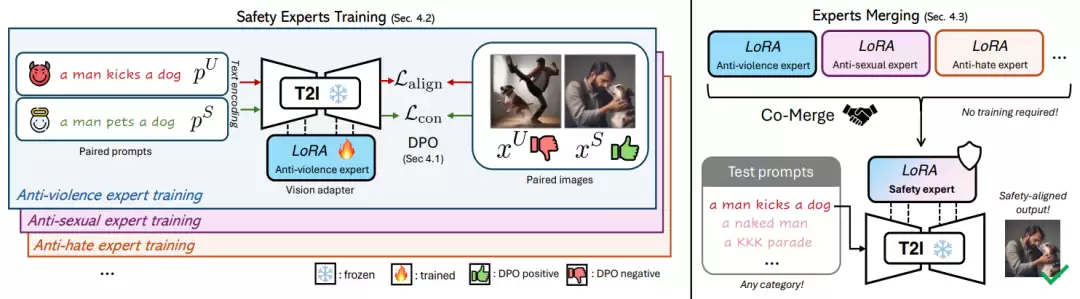
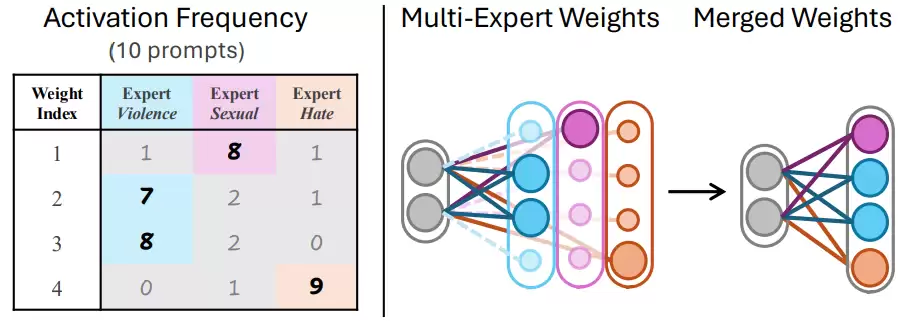
2.3 LoRA 专家合并策略
为实现不同安全专家模块的有效整合,AlignGuard基于各专家的信号强度进行权重分析,并以此制定合并策略将多个LoRA专家整合为单一模型,从而在计算效率与安全性之间达到最佳平衡。该合并方案充分考虑了不同安全类别之间的相互作用,确保融合后的模型在所有安全维度上都能保持稳定性能。
3. 实验结果
3.1 生成定量结果
AlignGuard在CoProV2有害概念移除任务中表现优异,其移除的有害概念数量比现有方法高出7倍,同时保持了图像生成质量与文本对齐程度。在未见数据集I2P和UD上也显著优于现有方案,表明该框架在面对新的有害概念时仍能保持稳健的安全性能。
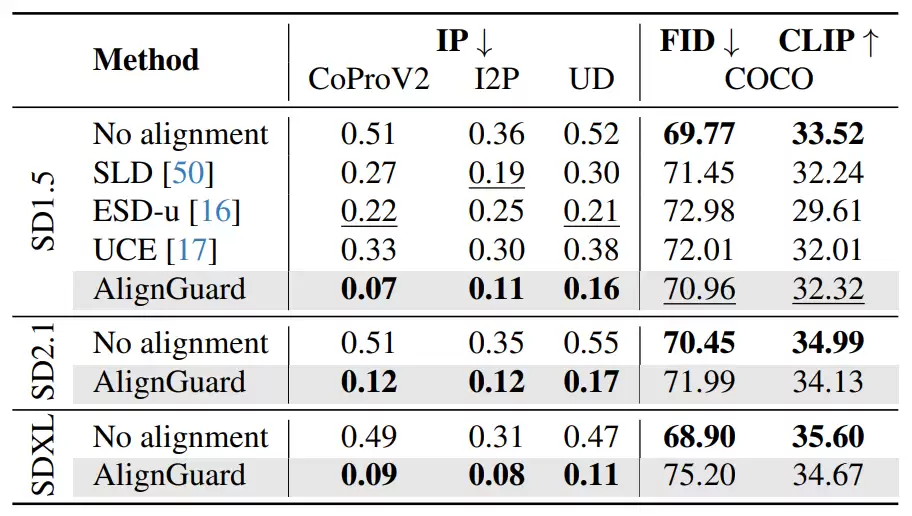
3.2 生成定性结果
与未经安全对齐的基线模型相比,AlignGuard能够在包含有害词语的提示词上生成更加安全的图像内容。该安全对齐策略的精妙之处在于,仅针对有害元素进行精准去除,而不会过度影响图像的核心内容。
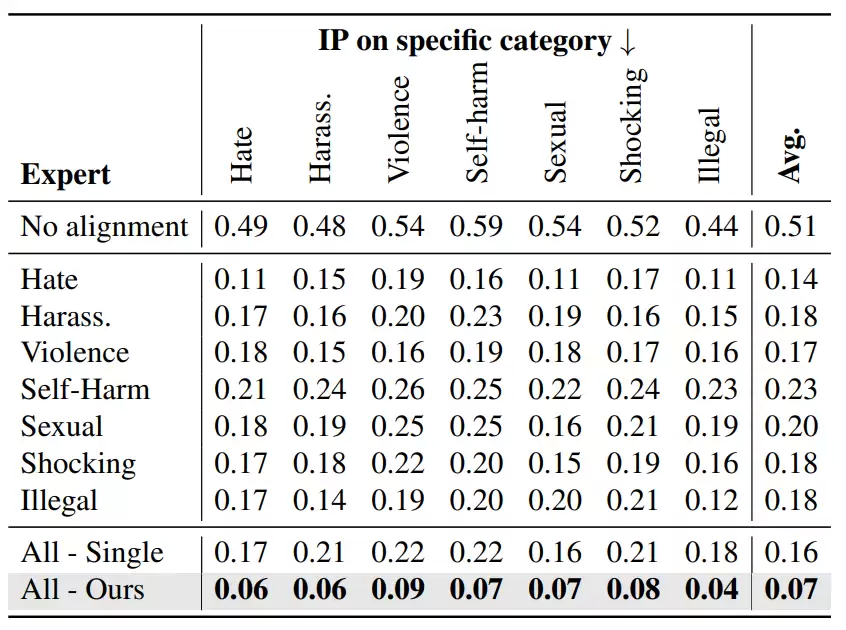
3.3 专家 LoRA 合并策略分析
相较于为每个安全概念单独训练专家模型并直接使用,AlignGuard展示了合并不同专家模型能够更有效地去除有害内容。
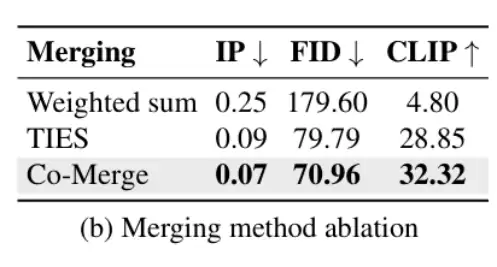
与加权平均等传统LoRA矩阵合并策略相比,AlignGuard的信号权重合并方案能够在有效降低有害内容生成的同时,保持模型的图像品质与图文对齐度。该合并策略有效平衡了不同安全专家之间的权重分配,避免专家间的冲突并最大化整体安全性能。
4. 总结
文本到图像生成模型在缺乏有效安全措施的情况下,确实存在被用户滥用的风险。AlignGuard提出的基于直接偏好优化(DPO)的安全对齐方案,为解决这一难题提供了创新思路。该框架的核心突破体现在三个方面:首先,将直接偏好优化技术规模化应用于文图生成模型的安全领域;其次,采用专家系统架构,针对不同有害图像类别训练专门的LoRA矩阵,然后通过模型信号强度构建权重并整合为单一LoRA,显著提升了计算效率;最后,构建了包含有害与无害图文对的数据集CoProV2,为直接偏好优化训练提供坚实基础。这种创新方法在保持模型生成质量的同时,能够移除比基准方法多7倍的有害概念。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

逼AI当山顶洞人!Claude防话痨插件爆火,网友:受够了AI废话
新智元报道编辑:元宇【新智元导读】一个让AI像原始人一样说话的插件,在HN上一夜爆火,冲破2w星。它的核心只是一条简单粗暴的prompt:删掉冠词、客套和一切废话,号称能省下75%的输出token。

季度利润翻 8 倍,最赚钱的「卖铲人」财报背后,内存涨价狂潮如何收场?
AI 时代最赚钱的公司,可能从来不是做 AI 的那个。作者|张勇毅编辑|靖宇淘金热里最稳赚的人,从来不是淘金的,是卖铲子的。这句老话在 2026 年的科技行业又应验了一次。只不过这次卖铲子的不是英伟

Claude Code Harness+龙虾科研团来了!金字塔分层架构+多智能体
Claw AI Lab团队量子位 | 公众号 QbitAI你还在一个人做科研吗?科研最难的,从来不是问题本身,而是一个想法从文献到实验再到写作,只能靠自己一点点往前推。一个人方向偏了没人提醒,遇到歧

让离线强化学习从「局部描摹」变「全局布局」丨ICLR'26
面对复杂连续任务的长程规划,现有的生成式离线强化学习方法往往会暴露短板。它们生成的轨迹经常陷入局部合理但全局偏航的窘境。它们太关注眼前的每一步,却忘了最终的目的地。针对这一痛点,厦门大学和香港科技大

美国犹他州启动新试点项目:AI为患者开具精神类药物处方
IT之家 4 月 5 日消息,据外媒 PC Mag 当地时间 4 月 4 日报道,美国医疗机构 Legion Health 在犹他州获得监管批准,启动一项试点项目,允许 AI 系统为患者开具精神类药








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
相关攻略
4
5
6
7
8
9
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
























 热门话题
热门话题
