




让离线强化学习从「局部描摹」变「全局布局」丨ICLR'26

面对复杂连续任务的长程规划,现有的生成式离线强化学习方法往往会暴露短板。它们生成的轨迹经常陷入局部合理但全局偏航的窘境。它们太关注眼前的每一步,却忘了最终的目的地。针对这一痛点,厦门大学和香港科技大
面对复杂连续任务的长程规划,现有的生成式离线强化学习方法往往会暴露短板。
它们生成的轨迹经常陷入局部合理但全局偏航的窘境。
它们太关注眼前的每一步,却忘了最终的目的地。

针对这一痛点,厦门大学和香港科技大学提出一种名为MAGE(魔法师,Multi-scale Autoregressive Generation)的离线强化学习新算法。
MAGE与现有序列生成方法不同,MAGE采用自顶向下的“由粗到细”生成策略,先建模轨迹的宏观规划,再逐步细化微观细节。
MAGE的核心思路非常符合人类的直觉:“自顶向下、由粗到细”。
这就好比画一幅素描,你不会一上来就描绘眼睛的睫毛,而是先画出整体的身体轮廓(宏观规划),再逐步细化五官和表情
(微观动作)
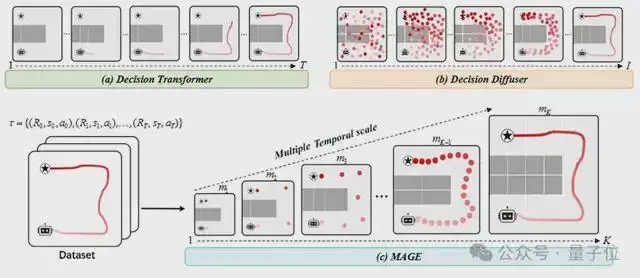
△MAGE的思考过程
从一场”迷宫寻宝“揭示AI规划的盲区
为了直观展示现有模型的缺陷,研究团队设计了一个迷宫吃金币小实验。智能体需要从随机起点出发,依靠对环境的长程空间理解,先吃银币,再吃金币,最后抵达终点。
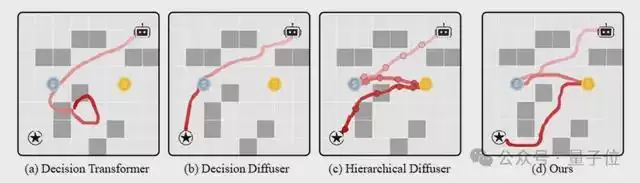
△各个算法在迷宫环境的表现
然而,面对这种需要全局规划的场景,现有的模型纷纷暴露了缺陷。
Decision Transformer受限于单向自回归特性带来的全局上下文缺失,它在长程规划中完全迷失方向,最终连终点都未能抵达。Decision Diffuser则由于扩散模型固有的局部生成偏差,生成的轨迹往往只能保证局部合理;虽然智能体抵达了终点,却遗漏了关键的一枚金币,全局连贯性较差。Hierarchical Diffuser虽然尝试通过分层结构建模全局轨迹,但由于其固定的双层结构过于僵硬高低层策略之间缺乏有效协同,生成的轨迹甚至出现了物理违规的“穿墙”现象,全局规划与局部动作严重脱节。
相比之下,MAGE则通过多尺度“从粗到细”的生成架构成功完成了任务。它首先在最粗的时间尺度上勾勒出包含所有关键节点的宏观全局轮廓,随后利用多尺度Transformer在更细的时间尺度上逐层细化,顺利规划出完整的路径。
MAGE的核心思路:从画大纲到扣细节
MAGE采用“自顶向下、由粗到细”的生成方式。MAGE包含两大核心模块,并辅以精确的控制机制:
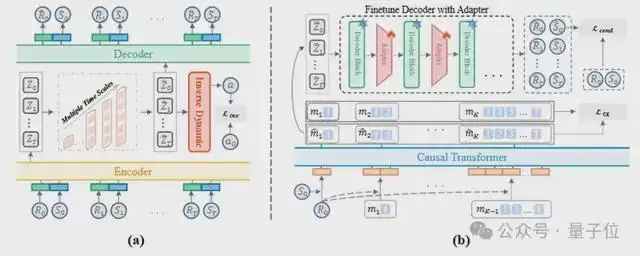
△MAGE的架构图
MTAE多尺度轨迹自编码器:MAGE将长序列轨迹转化为从粗到细的多尺度离散Token。粗尺度的Token负责掌控全局长程结构,最细尺度的Token则详细建模短期的动态细节。
多尺度条件引导自回归生成:模型使用Transformer序列化地生成这些多尺度Token。在生成每层时,都会严格以“目标回报”和“初始状态”作为条件进行约束,确保智能体的每一步都在朝着最终目标前进。
条件引导细化与动作决策:因为把连续世界变成离散Token会丢失信息,普通的生成过程容易让轨迹起点偏离现实。为此,MAGE在解码器中集成了轻量级的适配器(adapter)模块,并引入了条件引导损失函数Lcond,强制解码出的初始状态与真实环境是精确对齐的。最后,通过潜在逆动力学模型决定最终的动作。
实验表现:长序列任务全面超越,推理速度满足实时控制
研究团队在包含Adroit、Franka Kitchen、AntMaze等5个离线RL基准测试中,将MAGE与15种具有代表性的基线算法进行了广泛的评估。
多任务表现出色
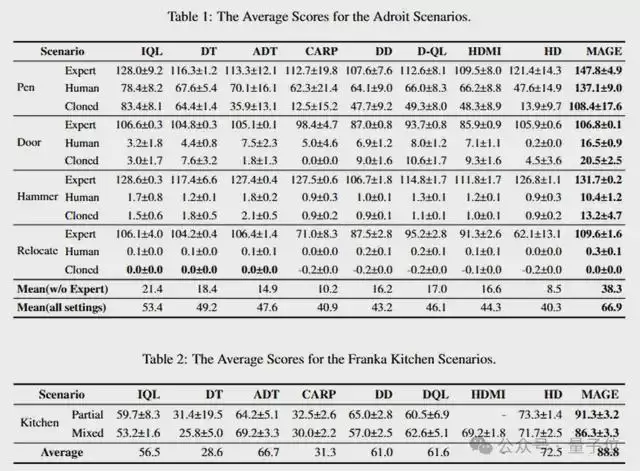
在极具挑战的高维连续控制Adroit机械臂任务中,面对极其稀疏的奖励,MAGE实现了显著的性能提升,大幅优于对比方法。在强调子目标执行顺序的Franka Kitchen组合任务中,MAGE凭借捕获全局结构和局部细节的能力,以相当大的优势超越了所有竞争算法。
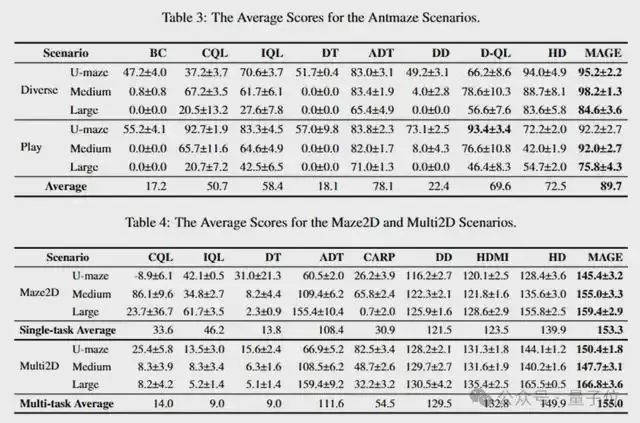
在迷宫导航任务中,MAGE在所有数据集上均取得了最佳性能,证明了其处理长序列导航任务的卓越能力。
极高的推理效率与部署潜力

MAGE在保持高性能的同时,实现了出色的计算效率平衡。实验数据表明,MAGE的运行速度比Hierarchical Diffuser快约50倍,比Decision Diffuser快80倍。其每步推理时间保持在27毫秒,完美满足了真实机器人控制所要求的20 Hz实时运行门槛。
结语
MAGE成功地将多尺度轨迹建模与条件引导相结合,通过“从粗到细”的自回归框架生成连贯且可控的高回报轨迹。当有一天,机器人不再需要人类一口一口地“喂”奖励,而是能够自主审视全局,制定长远计划并流畅执行时,也许具身智能的下一个奇点就真正到来了。
论文链接:
https://arxiv.org/abs/2602.23770
开源代码:
https://github.com/xmu-rl-3dv/MAGE
实验室主页:
https://asc.xmu.edu.cn/
作者介绍:
本文第一作者来自厦门大学空间感知与计算实验室(ASC Lab)2024级硕士生林晨兴、2025级硕士生高鑫辉,通讯作者为厦门大学沈思淇副教授,并由张海鹏、李欣然(香港科技大学)、王海涛、梅松竹副研究员、刘伟权副教授(集美大学)、王程教授共同合作完成。研究团队长期聚焦于强化学习,多智能体系统以及大模型智能体。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:让离线强化学习从「局部描摹」变「全局布局」丨ICLR'26要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点面壁智能聚焦端侧AI,不拼参数大小,而是通过知识密度提升与模型风洞技术,将大模型压缩至手机、汽车等设备。其MiniCPM以2B参数超越同期8B对手。CTO曾国洋22岁主导训练中国首个大语言模型CPM-1。端侧AI追求“默契系统”,在用户开口前预判需求,已在吉利、上汽大众等车型落地应用。
印度IT巨头HCLTech投资最高350亿卢比建设AI数据中心,容量可扩展至50MW,提供从设计到运营的端到端服务,旨在满足政府及企业日益增长的算力需求,抢占印度快速增长的数据中心市场,并推动AI基础设施布局。
小米具身机器人在汽车工厂自攻螺母上件工站实现双侧作业成功率98%,接近人工水平。同时在新工站分别达到90%成功率,从单一操作拓展至多工站协同,验证了具身智能在复杂工业环境的落地能力。
全球AI行业正迎来新的财富格局,DeepSeek创始人梁文锋凭借其公司的迅猛发展,个人财富急剧膨胀,一举超越多位硅谷知名人物,成为全球AI公司领域的新首富。以下将详细解析其身价飙升背后的关键因素及公司发展历程。 一、身价飙升至360亿美元,超越多位AI大佬 根据最新彭博亿万富豪指数,DeepSeek
- 日榜
- 周榜
- 月榜
热点快看