




MiniMax实习生实战:用数据处理屠榜开源模型的秘诀

为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了?
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
屠榜开源大模型的MiniMax M2是怎样炼成的?
为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了?
现在的大模型社区,可谓是被M2的横空出世搞得好不热闹。
面对现实任务,M2表现得非常扛打,在香港大学的AI-Trader模拟A股大赛中拿下了第一名,20天用10万本金赚了将近三千元。
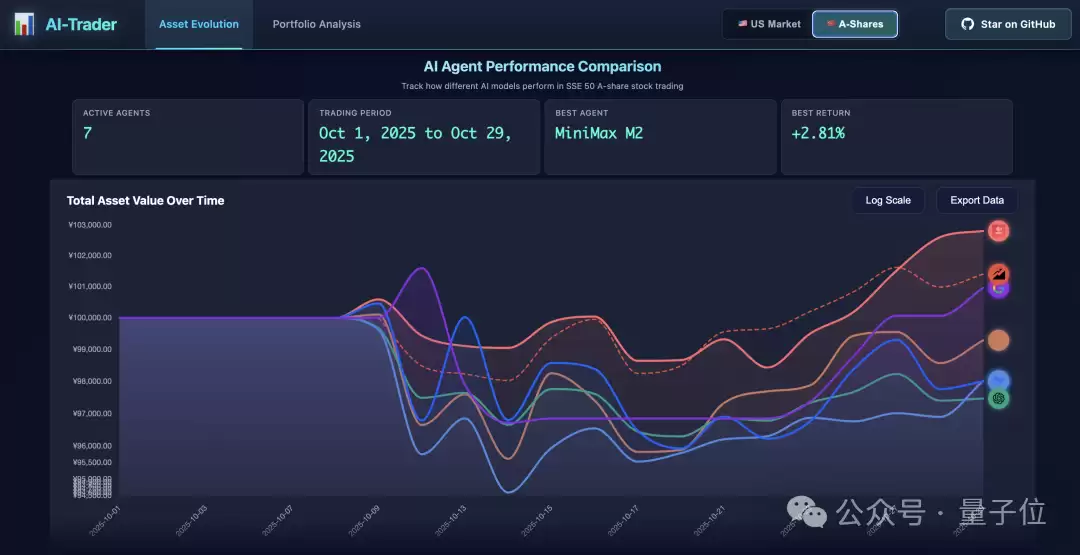
而之所以能够站在聚光灯下,还有一个原因是M2身上着实有不少奇招。
除了注意力机制“回归传统”,M2在数据处理、思考模式上也是另辟蹊径,给开源社区带来了不一样的技术路径。
而且MiniMax还公开了这些招数背后的“棋谱”,接连发布三篇技术博客,将M2的技术细节娓娓道来。
博客一发布,本已讨论得热火朝天的大模型社区变得更热闹了,不乏有大佬给出自己的分析。
其中也包括质疑的声音,比如Thinking Machine Lab技术人员Songlin Yang就表示——
MiniMax团队敢于揭露Linear Attention的不足这点值得肯定,但他们的测试有问题,低估了Linear Attention的实力。
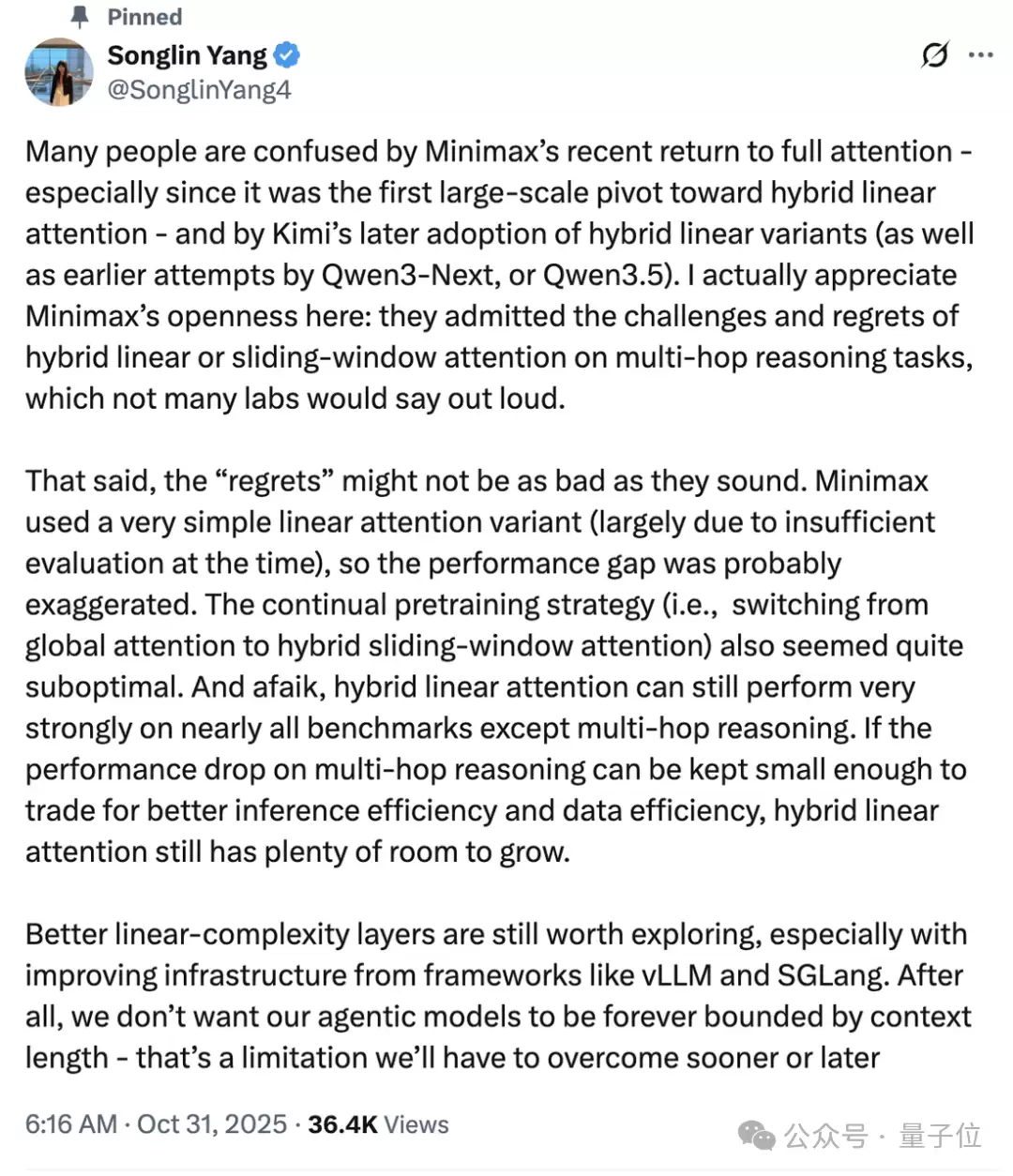
实际上,注意力机制的选择,也确实是M2相关问题当中最热门的一个。
M2团队选择的理由究竟是什么?三篇技术报告揭开了哪些秘密?
快搬起小板凳,我们一点点往下看。
2025年了,还有人用Full Attention?
就从网友们最好奇的Full Attention机制开始说起。
毕竟现在算力十分稀缺,MiniMax却没有选择更省算力的Linear和Hybrid等机制。
加上M2的上一代M1用的就是Linear Attention,这次却换了方案,更是给这个选择添上了几分神秘色彩。
这个问题看似复杂,但MiniMax的理由却非常简单有力——试出来的。
M2团队希望构建的是一个真正可用于商业部署的通用模型,所以稳定性和可靠性就成了优先考量。
一开始,他们确实也试了Efficient Attention,结果发现,用了这些机制之后的模型,虽然在小任务上表现尚可,但随着上下文长度的拉长,性能就大幅下降了。
一番折腾之后,团队最终决定放弃Efficient路径,转而回归稳定可靠的Full Attention。
而且团队试过的路比想象中多得多,Blog下方有网友追问,是否尝试更多的Linear Attention变体,比如GDN或Mamba2。
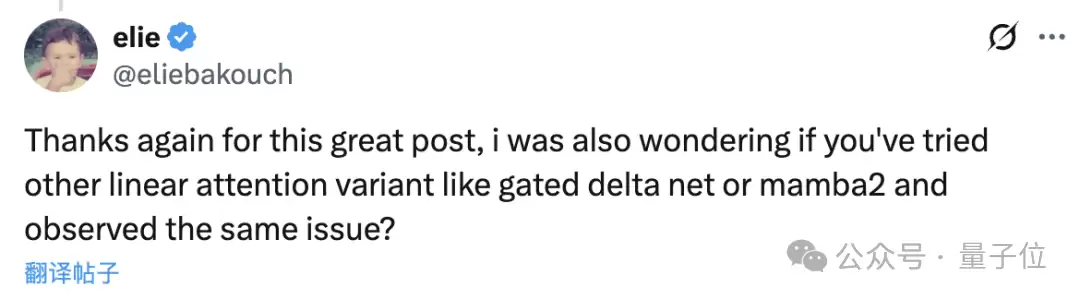
而团队成员表示,这些方法也都尝试过,但结果只有一个——这些方法的实际表现都不及Full Attention。

也就是说,Efficient Attention看似是命运的馈赠,实际上早已在暗中标好了价格。
M2的当头一棒,让人们开始意识到,所谓的“免费午餐”根本就不存在。
比如这位网友过去就认为,Lightning Attention与Full Attention混合起来效果和纯Full Attention是一样的,但他现在发现,对于复杂任务而言根本不是这么回事。

不过MiniMax也并没有把其他Attention一棒子打死,M2团队探讨了这些Attention未来的改进方向。
但问题不是出在Attention本身,而是人们缺乏有效的评估系统。
M2团队指出,现在的模型评测系统不完善,很多常用榜单根本拉不开差距,造成了Efficient Attention表现能与Full Attention持平的假象。
可只要一遇到多跳推理或长链逻辑过程这种高端局,Efficient Attention就立马现原形。
推理基础设施也需要进一步提升——如何将理论计算复杂度优势转化为应用层面的速度和价格优势,是目前业界仍在攻克的方向。
总之,要想转化为实际生产力,需要提前构建更丰富的长文数据、更完善的评测体系、更贴近部署场景的实验范式,以及更稳定的训练与推理基建。
但随着Context Length越来越长,尤其是在Pretrain和Posttrain阶段都面临长上下文挑战的背景下,未来某个阶段GPU的增长速度可能赶不上数据长度增长带来的压力,那时Linear或Sparse结构的优势将会逐渐释放。
想让模型做好推理,还得从数据开始
现在骨架(模型)搭好了,该往里面填肉(数据)了,有意思的是,这件事,M2团队雇了一帮实习生来干,还把这个细节写到了博客里。
网友看了就很纳闷,直言自己get不到M2团队强调这个细节的目的。

面对这样犀利的提问,作者也是丝毫不卖关子。
之所以强调实习生呢,是想反衬出M2用的数据处理流程非常成熟,成熟到让没有经验的人来操作,一样可以达到预期效果。

说到底,M2团队是咋处理数据的?咱们接着往下看。
他们希望模型能够具有更强的泛化能力,也就是能够适应更多的任务类型。
确定了这个目标之后,筛选数据的标准自然也就有了。
M2团队把数据质量的衡量标准拆解成了思维链(CoT)和Response这两个关键维度。
CoT部分的标准很容易理解,逻辑完整、表述简洁,就是优质数据,符合我们的常识。
Response部分就更能体现M2团队的巧思了。
前面说过,团队的目的是想让模型适应更多场景,而在他们看来,Response数据,刚好就是症结所在——
过去的Response数据,对榜单格式的依赖已经达到过拟合了,导致换个环境就秒变战五渣。
所以,M2在数据合成时刻意引入了格式多样性。
当然只靠形式是不够的,数据内容本身,也要尽可能多地涉猎不同领域的任务。
好的数据要广泛吸纳,不好的数据则要及时剔除——
M2团队发现,模型表现出的所有问题,包括幻觉、指令未遵循等等,几乎都能从数据上找到根源。
所以在处理数据时,他们专门整理了一批典型的bad case,基于规则和大模型判断,构建了数据清洗流程,从而消灭这些“坏数据”。
数据范围更加广泛,质量也有了保障之后,接下来的事,就是扩大数据规模了。
交叉思考,让模型不再“高分低能”
在M2团队的实践过程中,有一个“高分低能”的问题贯穿始终——模型一考试成绩都很高,但到了真实场景就被虐得渣也不剩。
这个问题在Agent场景中也是如此,甚至同一个模型,在不同的Agent系统里体验差异也会非常大。
问题出在了哪里呢?M2团队对Agent执行任务的流程进行了拆解。
Agent在执行任务时,会分析用户的意图,然后做出任务规划,之后付诸执行,中间过程还会涉及外部工具的调用。
在传统的模型当中,Agent会在规划阶段进行思考,但到了执行环节,就变成了既没有思维也没有感情的机器。
但实际工作并不是能够完全依照原始规划进行的,如果不根据执行过程中遇到的实际情况对规划进行调整,那便是刻舟求剑,任务做不好就不是什么怪事了。
而要想根据每步的执行结果进行动态调整,就需要把原先只在开头进行的思考过程,复制到每一个关键节点。
所以,M2团队提出了“Interleaved Thinking”(交错式思维链)的策略。
这种策略让思考在显式推理与工具调用之间交替进行,并把推理结果持续带入后续步骤,这样一来原本冗长、重度依赖工具的任务,就变成了稳定的“计划→行动→反思”循环。
Interleaved Thinking保持了思维链的连贯性,使其在多轮交互中不断累积,更加接近人类的任务执行方式,也减少了状态漂移与重复性错误的产生。
实际应用当中效果也是立竿见影,不仅提升了模型在长链任务中的容错率,也显著增强了对环境扰动的适应能力。
除了新的思考模式,泛化也是M2团队自始至终在强调的一个关键指标。
他们发现,即便模型的工具调用能力得到大幅提升,但只要换个框架,模型依然容易失控。
怎么办呢?简单说,菜就多练——M2团队选择从训练数据下手。
他们设计了一整套覆盖全轨迹扰动的数据链路,在构建训练样本时,他们不仅模拟了工具本身的变化,还覆盖了系统提示语、环境参数变化、用户反复提问、工具返回异常等多种情况。
看上去指标很复杂,但简单概括就是,让这些训练数据尽可能多地去模拟真实使用场景,在训练中就学会如何在不确定性中完成任务。
能实现落地,才是好选择
回看M2的结构选择,MiniMax并不是为了“回归传统”而选择Full Attention。
相反,在Efficient Attention广受追捧的当下,坚持使用Full Attention恰恰体现了团队更偏工程理性的判断——优先考虑模型在真实任务中的稳定性与可用性,而非盲目追求资源的节省。
这并非首次类似决策,例如早在MoE架构尚未成为行业主流前,MiniMax就已投入探索,并取得阶段性成果。
彼时,选择MoE的厂商寥寥,MiniMax却凭借自身理解做出了不同判断,并最终验证了可行性。
可以看出,MiniMax不仅拥有深刻的技术洞察,更突出以实用性为导向,在M2上,这种思路也表现得尤为明确——
它不是一个为参数堆叠而生的“炫技模型”,而是为开发者准备的落地工具,强调解释逻辑、兼顾系统性,并不断通过社区反馈与真实使用场景持续迭代。
在今天这个“结构百花齐放”的阶段,MiniMax展示的,不只是模型能力本身,更是一套面向复杂现实问题的思考方式。
比起抢占某个风口,拥有一套稳定可用、被理解并认可的工程体系,也许更具意义。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

一篇讲透:豆包、元宝、DeepSeek、Kimi、WorkBuddy,职场里到底怎么分工
别再把所有 AI 当成一个东西:WorkBuddy 和豆包、元宝、DeepSeek、Kimi,到底该怎么选? 这一年,AI 的进化速度着实叫人眼花缭乱。 大家的关注点,早就从“这工具能写文章吗”跳到了“它能不能帮我做方案、改稿子、整理会议纪要,甚至把任务往前推一步”。 于是,一个新问题浮出水面。 很

我用WorkBuddy“克隆“了一个我,从此每句话像我自己说的
如何使用WorkBuddy深度学习我的说话方式,让每一份文案都自带个人风格 作为一名企业培训师,每年主讲上百场课程是行业常态。无论是线下公开课、线上直播,还是视频号、公众号的内容创作,每天的工作状态不是在授课,就是在准备各种讲稿的路上。早期借助通用AI工具辅助创作,写作效率确实有所提升,但生成的内容

英国视障跑者挑战马拉松,将借助智能眼镜“看”到赛道、辨别方向
英国视障跑者挑战马拉松,将借助智能眼镜“看”到赛道、辨别方向 最近有一则科技助残的新闻,让人眼前一亮。当地时间4月2日,英国BBC报道称,视障跑者克拉克·雷诺兹正计划借助一项创新技术,参加一场全程马拉松。这项技术的巧妙之处在于,它能让世界另一端有视力的志愿者,实时“看到”雷诺兹眼前的景象,并为他提供
彻底卸载 OpenClaw (龙虾) 指南
彻底卸载 OpenClaw (龙虾) 指南 想把 OpenClaw(大家常叫它“龙虾”)从你的系统里清理干净?这事儿得讲究个章法,胡乱删除往往治标不治本,残留的服务和文件就像散落在角落的贝壳,时不时硌你一下。接下来,咱们就按一套稳妥的流程,帮你把它请走。 卸载原则 核心原则就一句话:先停服务,再卸工

AI 让英国学生“不会思考”,近 6000 名英格兰中学教师表示担忧
AI让英国学生“不会思考”?近6000名教师敲响教育警钟 一项来自英国教育界的深度调查,为当前AI技术涌入课堂的热潮带来了冷静思考。据英国《卫报》4月2日报道,英格兰的中学教师们普遍观察到一种现象:随着人工智能在教育中的应用日益广泛,学生的批判性思维能力与深度思考习惯正面临下滑风险。这项由英国全国教








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程

















