




国产开源模型的代码跑分如何超越GPT-5.1

2026 年开年,国内量化私募九坤投资创始团队旗下的至知研究院(IQuest Research)发布了首代开源代码大模型系列 IQuest-Coder-V1。这家研究机构声称,其 40B 参数的旗舰
2026 年开年,国内量化私募九坤投资创始团队旗下的至知研究院(IQuest Research)发布了首代开源代码大模型系列 IQuest-Coder-V1。
这家研究机构声称,其 40B 参数的旗舰模型在 SWE-bench Verified 基准测试中拿下了 81.4%的成绩,超越了 Claude Sonnet 4.5 的 77.2%和 GPT-5.1 的 76.3%。模型已在 GitHub 和 Hugging Face 上全面开源,涵盖 7B、14B、40B 三种参数规模,以及标准版和 Loop 变体。
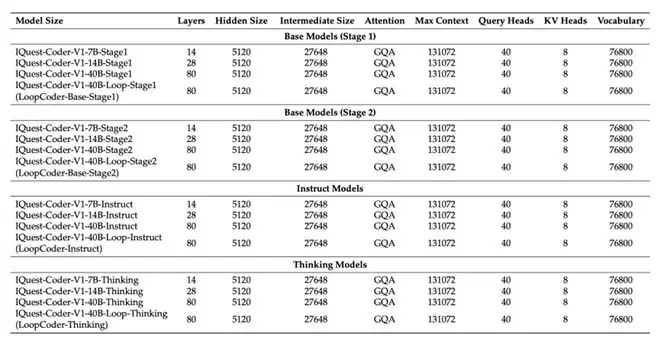
图丨IQuest-Coder-V1的架构(来源:GitHub)
至知研究院由九坤投资创始团队发起设立,定位为独立于量化投研体系的 AI 研究平台。
九坤本身是国内最早将深度学习大规模应用于量化投资的机构之一,2020 年投资过亿建成 AI 超算集群“北溟”,旗下三大实验室长期从事数据、算法和交易执行研究。继幻方量化孵化出 DeepSeek 之后,这是又一家从量化圈走出来的 AI 研究力量。
IQuest-Coder-V1 技术报告中最值得关注的是 Code-Flow 训练范式对 commit 演化数据的利用。传统代码模型基于静态代码文件训练,相当于让模型看一堆代码快照。IQuest-Coder 的做法不同:它试图让模型学习代码仓库的演化轨迹——不只是代码长什么样,还要学习代码是怎么一步步改出来的。
具体来说,他们为每个代码仓库构建了形如(R_old, P, R_new)的三元组训练数据。R_old 代表项目在某个稳定开发阶段的代码状态,P 是捕捉两个状态差异的 Patch 信息(即 commit 变更),R_new 则是迭代后的新状态。
选取起点时有个讲究:他们避开了项目早期不稳定的探索性代码和后期碎片化的维护性修改,专门聚焦于项目生命周期 40%到 80%区间的“成熟期”。理由是这个阶段的代码库相对稳定,变更模式更能反映真实的软件开发逻辑。
这个思路有一定道理。程序员在修 bug 或加新功能时,脑子里转的不是“这段代码是什么”,而是“这段代码要从什么状态变成什么状态”。
Commit 记录天然包含了这种“变更意图”——为什么改、改了哪里、改完之后整体结构如何调整。如果模型能从大量 commit 历史中学到这种模式,理论上应该比只看静态代码更擅长理解“怎么改代码”。
这也解释了为什么 IQuest-Coder 在 SWE-bench 这类需要生成 patch 修复 issue 的任务上表现突出——任务形式本身就和训练数据的结构高度吻合。技术报告中提到的一个发现印证了这点:仓库演化数据(repository transition data)在任务规划能力上提供了比静态快照更好的训练信号。
图丨研究团队展示的太阳系模拟示例(来源:IQuest Lab)
预训练阶段,IQuest-Coder 先用通用数据和代码数据打底,随后用高质量代码语料进行退火(Annealing)。这部分比较常规。中间训练阶段则分两期进行:他们在 32K 上下文长度下注入了推理数据、Agent 轨迹和代码数据的混合,随后将上下文扩展到 128K,加入仓库级的长序列样本。
Agent 轨迹数据包含完整的“行动-观察-修正”循环——命令执行、日志输出、错误信息、测试结果等环境反馈。技术报告的说法是,推理数据提供符号层面的逻辑脚手架,Agent 轨迹则提供“闭环智能”,让模型学会根据环境反馈调整行为。他们声称在高质量代码退火之后、后训练之前注入这类数据,能在分布偏移下稳定模型性能。
后训练阶段分成两条路径:Thinking 路径先用包含显式推理轨迹的数据做监督微调,再用强化学习优化推理能力;Instruct 路径则用通用和代码指令数据做监督微调,再用 RL 增强指令遵循能力。
技术报告声称,Thinking 版本在长程任务中展现出了自主错误恢复(error-recovery)能力,而这种能力在标准 Instruct SFT 路径中几乎观察不到。换言之,RL 可能是解锁代码模型“自主调试”能力的关键。
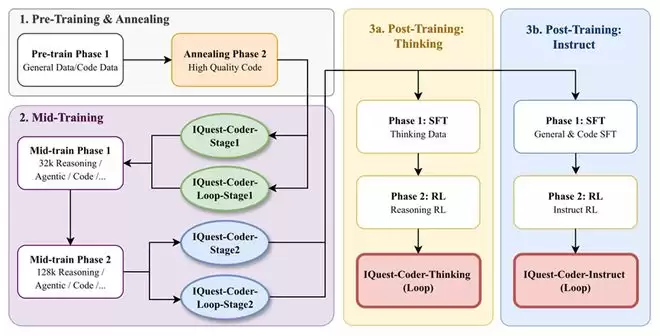
图丨训练流程(来源:GitHub)
架构方面,Loop 变体的设计比较有意思。LoopCoder 采用循环 Transformer 架构,让参数共享的 Transformer 块执行两次固定迭代。第一次迭代正常处理输入嵌入,第二次迭代同时计算两种注意力:全局注意力(iteration 2 的 queries attend to iteration 1 的所有 key-value 对)和局部注意力(维持因果性的常规自注意力)。
两种注意力的输出通过一个基于 query 表示的学习门控机制加权混合。这种设计的目的是在有限参数规模下获得更高的有效计算深度,即用参数共享换取更多计算步骤,在部署效率和模型能力之间找平衡。
后训练的 Thinking 路径也值得一提。技术报告声称,通过强化学习训练的 Thinking 版本在长程任务中展现出了自主错误恢复(error-recovery)能力,而这种能力在标准 Instruct SFT 路径中几乎观察不到。如果属实,这意味着 RL 可能是解锁代码模型“自主调试”能力的关键,模型不只是生成代码,还能在出错后自我修正。
根据技术报告,IQuest-Coder-V1-40B-Loop-Instruct 在 SWE-bench Verified 上取得了 81.4% 的解决率,在 BigCodeBench 上拿下 49.9%,在 BFCL(Berkeley Function Calling Leaderboard,伯克利函数调用排行榜)V3 上达到 73.8%,在 Mind2Web 上取得 62.5%,在 Terminal-Bench v1.0 上达到 51.3%。而 Thinking 版本在 LiveCodeBench v6 上的成绩是 81.1%,在 CRUXEval 的 Input-COT 和 Output-COT 上分别达到 98.5%和 99.4%。
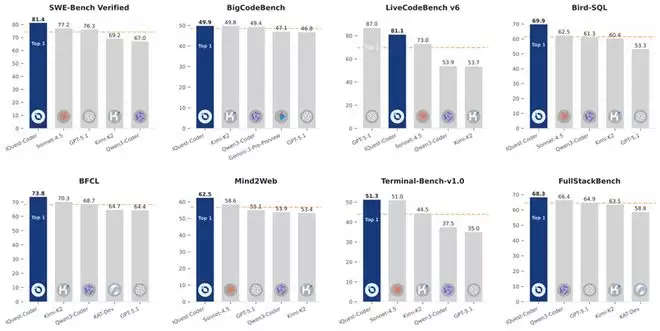
图丨基准测试结果(来源:IQuest-Coder-V1)
当然,SWE-bench Verified 只覆盖 Python 且仅含 500 个样本,社区对“针对榜单优化”的担忧一直存在。其在实际使用中的表现如何,有待社区的进一步测试反馈。
从技术贡献看,IQuest-Coder-V1 最有价值的部分可能是对 commit 演化数据的系统性利用。这个方向此前在学术界有过探索,但在开源模型的大规模训练中应用得并不多。技术报告承诺会开源完整训练流程和中间检查点,这对研究代码模型如何学习软件工程能力将是有价值的参考。至于跑分能否转化为实际生产力,要等更多开发者上手实测才能下结论。
参考资料:
1. https://iquestlab.github.io/#/

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

高刷显示器提升FPS游戏命中率,LG Display研究证实
LGDisplay研究显示,31名玩家在60Hz至480Hz刷新率下测试第一人称射击游戏。对比60Hz,480HzOLED显示器命中率提升约38%,其中60Hz升至240Hz提升最为显著,再升至480Hz再增约10%,输入延迟减少超过10毫秒。

年确认不插入闰秒,距上次调整已10年
国际地球自转和参考系服务宣布2026年末不插入闰秒,距上次调整已隔十年。闰秒用于协调原子时与地球自转时,已调整27次均为正闰秒。因气候变化导致地球自转减速,首个负闰秒推迟至2029年,国际计量界计划2035年前废止闰秒机制。

红米Note 17 Pro首销活动送电池升级保五年免费换新
REDMINote17Pro首发提供五年电池升级保障:前四年电池健康低于80%免费换新,第五年升级为更大容量电池。内置9000mAh电池,支持67W快充与22 5W反向充电,配备康宁大猩猩Victus2玻璃及四重防水认证,防护规格对标旗舰。

三星A18渲染图曝光 机身变厚或搭载6000mAh电池
据悉,三星A18最新渲染图曝光,其机身厚度增至7 84毫米,较上一代增加0 34毫米,推测或为配备6000毫安时大容量电池。此外,外观延续水滴屏设计,后置三摄模组有微调,并且底部配备USB-C接口,还支持快速充电功能。

三星S26像素级防窥屏幕隐私保护再升级
三星GalaxyS26系列搭载像素级隐私显示技术,从硬件层面控制OLED子像素发光方向,实现物理级防窥,正面观看画质无损,侧面超60°即模糊。该功能深度集成OneUI8 5,支持智能场景触发和多档位强度调节,与Knox安全平台形成防护体系,无需贴膜,不损画质。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-12 12:16
2026-07-12 12:16
2026-07-12 12:16
2026-07-12 12:16
2026-07-12 12:15
2026-07-12 12:15
2026-07-12 12:15
2026-07-12 12:15
热门教程
2026-07-12 12:16
2026-07-12 12:16
2026-07-12 12:16
2026-07-12 12:16
2026-07-12 12:15
2026-07-12 12:15
2026-07-12 12:15
2026-07-12 12:15
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















