




MIT发现AI变聪明的秘密:竟与人类学习原理相同

新智元报道编辑:定慧【新智元导读】你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,

新智元报道
编辑:定慧
【新智元导读】你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
2025年最后一天,麻省理工学院(MIT)丢了一篇重磅论文,就是要解决这个问题的。
这篇论文叫《Recursive Language Models》,也就是递归语言模型。
看起来很学术,但说人话就一句:让AI再做一遍,效果直接起飞。

论文地址:https://arxiv.org/pdf/2512.24601
先剧透两个核心数据:
在复杂推理任务上,仅仅让模型多过2-4遍,正确率就能提升10%-25%
在超长文档处理上,RLM(递归语言模型)在1000万+token的规模下,依然保持稳定表现,而传统模型直接崩盘!
这啥概念?
以前我们觉得,AI不够聪明,那就给它堆参数、加显卡、买更多GPU。
MIT这篇论文直接掀桌子:别堆参数了,让它返工重写一遍,效果可能更好。(真就是人类监工了)
原来解决问题的方法就是这么简单!
并且X上很多大佬纷纷点赞~


从一个让人崩溃的问题说起
你有没有这种经历:
让ChatGPT帮你写一篇文章,它洋洋洒洒写了三千字,你一看——卧槽,离题万里。
或者让它帮你写代码,它写完了,一运行——全是bug。
但神奇的是,你让它再检查一遍、重新想想,有时候它就突然能改对了。
MIT的研究人员发现,这不是玄学,这是有规律的。
大多数AI犯的错,不是因为它不懂,而是因为它初稿写太快了。
就像你写论文,第一稿总是稀烂,但改个三四遍,就像换了个人写的。
AI也是一样。
问题是:现在的大模型基本都是一遍过的模式,你输入问题,它输出答案,完事。
它自己不会主动返工、不会自我检查、不会反复推敲。
或者换一个思路来理解大模型原先的思路:
假设你是一个刚进公司的实习生,领导给你发了一份500页的资料,让你整理出一份报告。
你会怎么做?
正常人的做法是:先翻一翻,找到重点章节,然后一章一章地读,读完一章做个总结,最后把所有总结串起来。
对吧?
但大模型不是这么干的。
大模型的做法是:直接把500页资料从头到尾一口气读完,然后尝试凭记忆回答问题。
这能记住才有鬼了。
这就是大模型面临的困境。
它不是不聪明,它是记不住。

MIT这篇论文干的事儿,就是给AI装上了一个返工的能力。
AI的真正瓶颈:不是脑子不够大,是记性太差
在聊MIT的解决方案之前,我得先跟你说清楚,为什么这件事这么重要。
你可能听说过一个词,叫上下文窗口。
啥意思呢?
你可以把AI大模型想象成一个天才,但是这个天才有个致命缺陷——他的工作台太小了。
你给他一份超长的资料,让他帮你分析,但他只能把资料的一小部分放到工作台上看。
超过工作台大小的部分?看不到,直接忽略。
现在最牛逼的GPT-5,工作台能放27万个token(大约相当于20万字中文)。
听着挺厉害的对吧?
但问题来了。
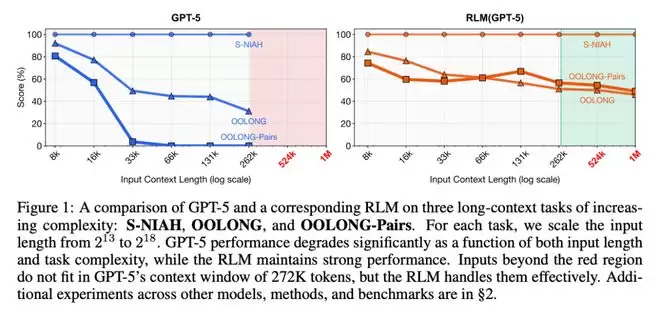
就是说,哪怕是在这27万token的限制之内,模型的表现也会随着输入变长而急剧下降。
当你给它8000个token的时候,它表现贼棒。
给它8万个token的时候,它开始有点迷糊。
给它27万个token的时候,它直接开始胡说八道。
为什么?
因为信息太多了,它处理不过来了,脑子乱了。
就像让一个人同时记住一整本百科全书然后回答问题——记是记住了,但找不到了。
这就是大模型现在的困境:不是上下文窗口不够长,而是长了也用不好。
MIT的天才想法:把资料放到抽屉里
好了,问题讲清楚了,现在来看MIT的解决方案。
传统做法是:你把资料直接塞进AI的脑子里。
MIT的做法是:别塞进去了,放抽屉里吧。
他们发明了一个叫RLM的东西。
RLM的核心思路是:不要让AI直接读那份巨长的资料,而是让AI用代码去翻那份资料。
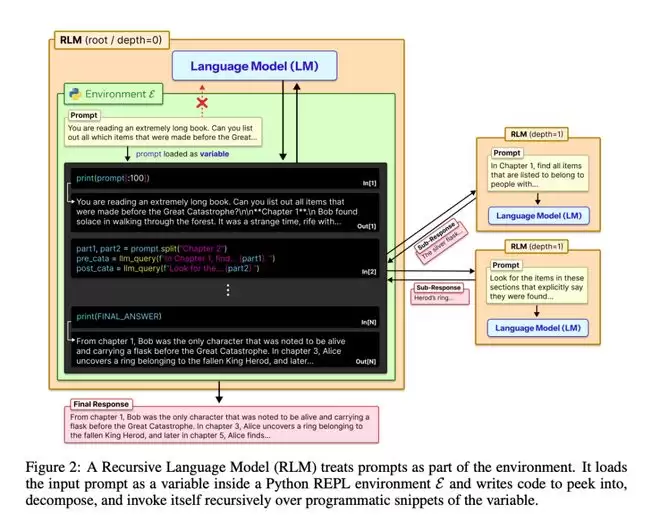
打个比方。
以前的AI,就像一个学生,你把一整本教科书拍在他面前说:看完,然后回答我的问题。
学生:???我看不完啊,我能不能看一部分?
然后他就硬着头皮看前面的一部分,后面的直接放弃。
RLM的做法不一样。
它更像是给这个学生配了一个目录系统和搜索引擎。
资料还是那份资料,但学生不用从头到尾读了。他可以先翻目录,看看大概结构,然后针对问题去搜索相关段落,把有用的信息摘出来。
更牛的是,这个学生可以把一个复杂问题拆成好几个小问题,然后——注意重点来了——他可以召唤自己的分身,让分身去同时处理各个小问题,最后汇总答案。
这就是递归的意思:AI可以调用自己的分身,让自己帮自己干活。
或者再降维一下理解就是:
它把这份超长的文档,当成一个放在外面的资料库,而不是直接塞进脑子里。
然后,模型可以写代码,自己去查这个资料库。
需要第一章的内容?写个代码去查。
需要第十章的内容?再写个代码去查。
需要把第一章和第十章的内容对比?
那就先查第一章,做个总结,再查第十章,做个总结,最后把两个总结合起来。
这就像是一个有无限容量的外置硬盘。
模型的脑子里装不下那么多东西,没关系。
可以随时去硬盘里查,用到什么查什么。
这样一来,理论上,模型可以处理无限长的文档。
具体怎么做的?
MIT的实现方式其实挺优雅的。
他们给AI配了一个Python编程环境(REPL),把那份超长的资料存成一个变量。
然后AI不再直接去读这份资料,而是用代码去操作它。
比如:
想看资料有多长?写一行代码len(input_text)就知道了
想看资料的前1000个字符?写input_text[:1000]
想在资料里搜索关键词?写个正则表达式
更厉害的是,AI可以把这份资料分段,把每一段交给一个子AI去处理,然后自己汇总结果。
这个子AI,用的其实是同一个模型,只不过是递归调用自己。
这个设计有两个巨大的好处:
第一,AI不用在脑子里记住那份超长资料了。
资料就放在外面的抽屉里,需要的时候用代码去取。
这就意味着,理论上,资料可以无限长——只要抽屉够大。
第二,AI可以自己判断需要看什么、不需要看什么。
它不会傻乎乎地从头读到尾,而是会聪明地挑重点看。
这大大节省了计算成本,也提高了准确率。
效果到底有多猛?
MIT在论文里做了一堆实验,结果还是挺震撼的。
实验一:超长文档理解
他们用了很多测试机,其中一个叫OOLONG的测试集,这个测试需要AI理解超长文档,并回答需要综合全文信息才能回答的问题。
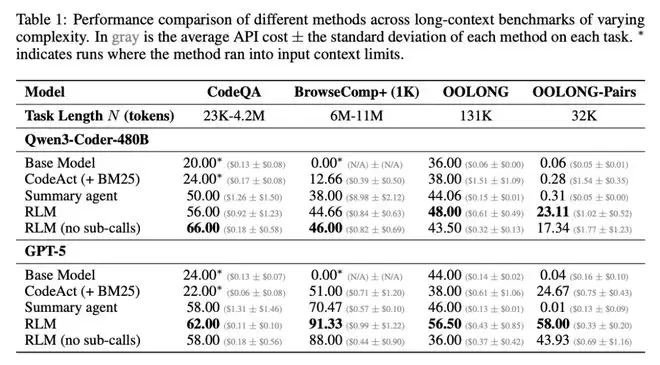
结果:GPT-5基座模型的准确率44%,而RLM达到了56.5%。
而在CodeQA中,GPT-5基座模型的准确率24%,而RLM达到了62%,直接提升了2.7倍!

实验二:超超超长文档(1000万+token)
他们还把文档长度一路拉到1000万token以上(相当于几十本书的长度)。
GPT-5?压根处理不了,直接爆炸。
RLM(GPT-5)?稳稳当当,表现基本不掉。
这是一个质的飞跃。
实验三:成本对比
你可能会想:这么牛逼的东西,是不是巨贵?
神奇的是,并没有。
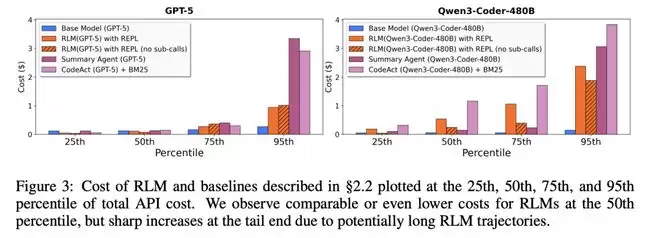
在BrowseComp-Plus基准测试中,让GPT-5-mini直接处理600万-1100万token的输入,成本大约是1.5-2.75美元。
而RLM(GPT-5)的平均成本只有0.99美元。
更便宜,效果还更好。

为什么?
因为RLM不会傻傻地把所有内容都读一遍,它只读需要的部分。
这个发现为什么重要?
MIT这篇论文的意义,远不止于让AI处理更长的文档。
它揭示了一个更根本的道理:
AI的能力边界,不只取决于模型本身有多大、参数有多多,还取决于你怎么使用它。
以前我们的思路是:模型不够强——那就加参数。
MIT告诉我们:等等,也许不用加参数,让它多想几遍就够了。
回到开头提到的那个发现:
在多步推理任务中,仅增加2-4次递归处理,正确率就能提升10%-25%。大约4次迭代后,收益逐渐趋于平缓。
这说明什么?
大多数AI犯的错,都是初稿错误:不是它不懂,是它第一遍太草率了。
让它返工几次,就能改对。(所以有时候,你在使用AI时,还真的当个监工,让AI多输出几次)
这跟人类其实一模一样。
任何牛逼的程序员都知道,第一版代码永远是最烂的,代码质量是改出来的,不是写出来的。
任何牛逼的作家都知道,第一稿永远是废稿,好文章是改出来的,不是写出来的。
现在,AI也一样了。
未来展望
MIT在论文最后提到,这只是一个开始。
目前的RLM还有很多可以优化的地方:
1.异步调用:目前子任务是一个接一个执行的,如果能并行执行,速度会更快。
2.更深的递归:目前只允许一层递归(AI调用自己的分身),如果允许分身再调用分身,理论上能处理更复杂的任务。
3.专门训练:目前RLM用的是现成的大模型,如果专门为递归思考训练一个模型,效果可能更猛。
MIT的研究者们相信,这可能代表了大模型能力扩展的一个新方向:
不是一味地堆参数、堆算力,而是让模型学会更聪明地思考。
彩蛋
MIT这篇论文,让我想起了一个老笑话:
客户问程序员:这个bug你修了多久?
程序员说:5分钟。
客户说:那为什么收我500块?
程序员说:找出问题在哪,花了我3天。
AI也是一样。
它的思考时间远比我们想象的更重要。
给它一点返工的机会,它可能就能从还行变成牛逼。
这也许就是下一代AI进化的方向:不是更大的脑子,而是更深度的思考。
参考资料:
https://x.com/a1zhang/status/2007198916073136152?s=20
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:MIT发现AI变聪明的秘密:竟与人类学习原理相同要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在选择阿里云服务器时,许多用户面对2核4G、4核8G、8核16G等常见配置,常常被经济型e、通用算力型u1、u2i、计算型c9i等实例名称搞得一头雾水——看似配置相近,价格却相差悬殊。例如同样是2核4G,经济型e实例最低仅需599 93元,通用算力型u1有特价199元,而计算型c9i起步价高达118
DeepSeek、通义千问等大语言模型的迅猛发展,使得AI辅助开发已成为常态。代码生成、方案设计、效率提升,这些都已成为现实。然而,一个被许多开发者忽视却普遍存在的难题是:如何将AI输出的那一长串Markdown内容,工程化地转换为可交付的Word或PDF文档? 这绝非简单的复制粘贴操作,两者之间隔
针对视觉语言模型依赖时间顺序判断任务进度的缺陷,浙江大学等团队提出EgoTSR方案,包含4600万样本数据集与三阶段课程学习。该模型通过正反向图像对暴露时间偏差,结合子任务规划器实现长程任务推理,在双向评测中准确率超92%。
大模型API调用成本,核心就是Token计费机制如何设计。阿里云百炼平台提供按量付费、Token Plan、Coding Plan和AI通用型节省计划四种计费模式,每种都有独特的门道。本文从计费逻辑、适用场景、价格对比三个维度深入剖析,帮您找到最能节省成本的方案,把每一分钱都用在实处。 一、按量付费
- 日榜
- 周榜
- 月榜
热点快看