




DeepSeek新版mHC上线,R2模型距我们还有多远?

去年1月,春节前夕,“DeepSeek冲击波”席卷业界,中美同时“破圈”,成为年度现象级事件。而2026年一开年,DeepSeek又惊喜时刻进一步提前。
1月1日,DeepSeek在AI开源社区HuggingFacear和研究分享平台arXiv发布论文,提出了名为mHC(Manifold-Constrained Hyper-Connections)的新型神经网络架构优化方案,再次引发讨论热潮,其对AI产业,包括大模型、芯片等领域可能产生的影响也备受瞩目。

图片来自DeepSeek论文“mHC:Manifold-Constrained Hyper-Connections“
mHC架构让大模型训练更稳、更快、更省
DeepSeek此次提出的mHC架构,建立在字节豆包大模型Foundation团队2024年11月发布的Hyper-Connections(HC)基础上。
彼时,豆包团队宣称HC有望替代大模型开发领域沿用近10年的ResNet残差神经网络架构,通过拓宽残差连接宽度,增加连接模式多样性,提升大模型性能和灵活性。
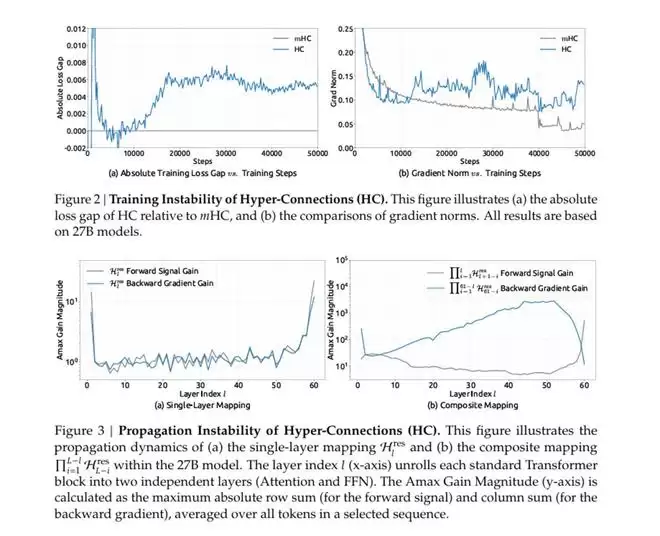
不过,HC只在理论推演和小模型实验中取得了成绩,在大模型训练中,残差连接通道间的交互极易导致信号爆炸或消失,进而全盘失控,无法取得稳定的训练结果,可扩展性也随之降低,成本则大幅升高。
DeepSeek在论文中称,mHC的核心创新在于引入Manifold-Constrained(流形约束),通过Sinkhorn-Knopp算法将残差映射矩阵投影到“双随机矩阵”构成的Birkhoff多面体上。
简单来说,这相当于为上述“易爆”的信号传播环节加上稳定器,确保信号在多层传递过程中受到约束,均值不变、总量守恒,以此解决HC在大模型训练中的稳定性、可扩展性问题。
DeepSeek给出了HC和mHC在270亿参数级别训练中的演示数据,HC在训练到1.2万步左右时信号放大倍数已暴增至3000倍,训练随之崩溃。
而mHC在同等训练中,信号放大倍数仅为1.6倍,全程平稳运行。与此同时,相较于传统架构,mHC训练时的损失显著下降,BBH数据集评测的困难任务推理能力和DROP数据集评测的阅读理解表现均提升2%以上。
图片来自DeepSeek论文“mHC:Manifold-Constrained Hyper-Connections“
另外,DeepSeek延续了“高性价比”“效率优先”的一 贯风格,论文称研究团队同时设计了高效的基础设施优化方案,最终,在残差通道扩展4倍后,mHC的额外训练时间开销仅为6.7%。
DeepSeek在论文中总结称,实验证明mHC在大规模训练中表现稳定,性能优越,具备良好的可扩展性,期望其能为拓扑结构设计提供新视角,并推动基础模型的演进。
值得一提的是,论文作者署名多达19人,核心作者为解振达、韦毅轩、曹焕奇,前两者均为清华大学高等研究院博士,也均进入过微软亚洲研究院联培项目,而DeepSeek创始人、CEO梁文锋的名字则列于最后。
在HuggingFacear上,从2024年1月的LLM论文至今,DeepSeek共发布了23篇重要论文,11篇中有梁文锋署名,包括MoE、Coder、R1、V3等节点性重要成果。
或引发AI架构连锁反应,英伟达生态再获加持
mHC发布后,在研究者、业界、媒体中都有较高的讨论度。相较于此前聚焦专门领域的OCR、Math-V2和在V3基础上更新的V3.2,mHC更被视为是一种底层创新,再加之新年伊始的节点,也更多被赋予了一层象征意义。
科技研究机构Odmia首席分析师苏连杰接受Business Insider采访时称,DeepSeek可能会在AI领域引发连锁反应,竞争对手可能会着手开发类似的架构。
实际上,就在DeepSeeK发布论文的次日,普林斯顿和UCLA的研究团队就提出了名为Deep Delta Learning的架构,同样旨在更新ResNet的基本架构。
接连涌现的新研究,提升了业界对2026年大模型架构产生重大范式更新和迭代的期待。
苏连杰还认为,相关研究成果会在DeepSeek其后的新模型中有所体现。
不少机构预计DeepSeek将在春节前后进行重大发布,很可能是备受期待却推迟已久的R2,并以此复刻去年的“冲击效应”,也可能是更新更快的通用模型V4,进一步激发实用性和经济价值。
不过,目前尚无可靠消息论证mHC是否会进入新模型。
去年春节期间,DeepSeek R1给AI芯片产业带来巨大冲击,甚至一度被认为将颠覆“算力为王”的逻辑,让以英伟达为代表的美股AI芯片产业链公司股价大跌。此次,mHC对算力、硬件端的影响也受到关注。
一份专家调研纪要显示,mHC架构虽然通过效率提升、工程优化提升了整体算力的质效比,延续了“无需堆算力就能打造顶尖大模型”的叙事,但其本身依赖FP32高精度计算格式,对内存带宽和高速互联带宽也提出了更高要求,尤需高端芯片的支持。
而且,目前该架构主要针对英伟达超节点链路设计,更适配英伟达生态,而对国产芯片兼容性较弱。
实际上,此前DeepSeek推迟R2发布时,即有分析称缺少英伟达芯片是原因之一。如果这种架构规模化铺开,英伟达的生态短期内会得到优势强化,国产芯片则需着力强化编译层的适配。而长期来看,供应mHC架构的AI芯片需要提升存储带宽,并转向更加精细化的设计。
不过,值得注意的是,2025年英伟达等制造商的美国AI芯片受地缘、政策因素影响逐渐淡出中国市场后,国产芯片替代大幅加速。相关厂商在提升性能以追赶领先者的同时,也逐渐在生态构建层面大举布局,华为昇腾、摩尔线程等都宣布适配DeepSeek大模型,不过其精度格式仍与英伟达有明显差距。
在国产芯片的生态突围中,与DeepSeek等领先大模型的深度耦合被认为至关重要。2026年,英伟达、AMD等国际巨头重返中国的努力、国产芯片的继续成长,以及大模型创新带来的变量,可能会让故事变得更加精彩。(作者|胡珈萌,编辑|李程程)

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

LiblibAI云端WebUI降低AI绘画部署门槛
LiblibAI在线WebUI的核心优势在于——只需通过浏览器即可流畅运行Stable Diffusion,无需自行搭建本地环境。云端直接处理运算,模型即选即试,大幅降低了AI绘画的创作门槛。对于轻量创作和模型快速测试来说,体验相当顺畅,但用户仍需重视数据隐私保护和版权合规等问题。 过去使用Stab

微软因用户不安叫停Edge浏览器AI历史搜索功能
微软紧急暂停Edge浏览器AI历史搜索功能,该功能因被用户吐槽“令人不安”而暂缓部署。尽管微软强调所有AI处理在设备端完成且数据不上传云端,但用户仍不信任。此举与WindowsK2计划减少功能堆砌的理念一致。

红魔游戏平板5 Pro发布 4999元起售将登陆全球市场
【CNMO科技消息】近日,红魔游戏平板5 Pro正式发布。这款平板从定位上就明确瞄准“极致游戏”体验,外观方面带来了一个重磅亮点——首次引入RGB水冷散热系统,背部那条可视化的水路通道,配合纯平透明背板设计,核心配置信息一览无余,科技感十足。 图源网络 屏幕方面同样表现突出。一块9 06英寸OLED

杭州全国首所机器人学校首批30台机器人入学
30台机器人整齐列队,有的刚从生产线卸下,机械零件还带着崭新的“工业气息”;有的已搭载运动控制模块,能稳健地小跑、跳跃几下。它们来自不同制造工厂,外形与功能各有千秋,但此刻都拥有了同一个身份——杭州机器人学校的第一批入学新生。 6月30日,杭州经信正式发布:由浙江大学机器人研究院、浙江省质量科学研究

美国计划发射航天器托举天文卫星
就在最近,NASA公布了一项非常果断的干预计划——他们定于6月30日实施一次“卫星维修任务”,派遣一台名为“连接”号的机器人服务卫星,为一颗超期服役的天文卫星延长运行寿命。这颗卫星是“尼尔·格雷尔斯·斯威夫特天文台”,其轨道高度正在不断衰减,如果不进行干预,今年年底前很可能会坠入地球大气层并烧毁。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-02 10:42
2026-07-02 10:42
2026-07-02 10:41
2026-07-02 10:41
2026-07-02 10:41
2026-07-02 10:41
2026-07-02 10:41
2026-07-02 10:41
热门教程
2026-07-02 10:42
2026-07-02 10:42
2026-07-02 10:41
2026-07-02 10:41
2026-07-02 10:41
2026-07-02 10:41
2026-07-02 10:41
2026-07-02 10:41
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
