




谷歌FirstProof数学挑战新纪录:超越IMO金牌难度

编辑|冷猫去年 7 月的 IMO 数学奥林匹克竞赛中,两大人工智能公司抢夺竞赛「金牌」成绩的闹剧搞得沸沸扬扬。当时 OpenAI 和 谷歌 同时声称取得竞赛金牌,而 OpenAI 因绕过最新竞赛规则
编辑|冷猫
去年 7 月的 IMO 数学奥林匹克竞赛中,两大人工智能公司抢夺竞赛「金牌」成绩的闹剧搞得沸沸扬扬。
当时 OpenAI 和 谷歌 同时声称取得竞赛金牌,而 OpenAI 因绕过最新竞赛规则提前官宣,遭到广泛吐槽;谷歌 DeepMind 的 Gemini 进阶模型成为首个获得奥赛组委会最新认定为金牌的 AI 系统。
竞赛与真正的数学研究之间,仍然存在一道明显的分界线。
在此之后,AI 智能体飞速发展,解决数学问题的能力不再仅依靠模型的推理能力。AI 智能体已经可以开始自己做数学,不只是解题,更能够进行数学研究,而且研究的还是顶尖数学家都要挠头的问题,这意味着什么?
近日,来自谷歌 DeepMind ,由 Gemini 3 Deep Think 驱动的最新数学研究智能体 Aletheia 在首届 FirstProof 挑战中,自主解决了 10 道高难度研究问题中的 6 道,成为创下了该数学挑战赛的最佳纪录。
曾带队实现 AI IMO 金牌成绩的 DeepMind 超人类推理方向负责人 Thang Luong 表示,这一成果的分量超过去年 AI 在 IMO 测试中获得金牌的表现。
相关论文《Aletheia tackles FirstProof autonomously》已发布在 arXiv,并且团队在 Github 上公开了解决 FirstProof 问题的提示词与输出结果。

论文标题:Aletheia tackles FirstProof autonomously论文链接:https://arxiv.org/pdf/2602.21201提示词与输出结果:https://github.com/google-deepmind/superhuman/tree/main/aletheia
FirstProof:把 AI 放进真实的数学研究现场
FirstProof 是一项专门为评估 AI 数学研究能力而设计的实验性挑战。项目由多位活跃在不同数学分支的一线研究者发起,题目全部来自真实科研过程中的命题,被提出作为评估当前人工智能能力的测试。
这些问题在挑战启动前从未公开证明,组织方提前将标准证明加密保存,以尽量排除训练数据泄露的可能。最终提交的答案,需要由领域专家人工审阅,判断其逻辑严密性与学术可接受度。评价标准接近论文审稿,而非自动判分。
这种设计刻意提高了门槛。它测试的,是 AI 在陌生问题上进行长期推理与结构构造的能力。换句话说,FirstProof 关心的,是系统是否具备参与数学研究的潜力。
这些问题于 2026 年 2 月 5 日发布,并设定了截止时间为太平洋时间 2026 年 2 月 13 日晚上 11:59 ,解决方法在截止后在互联网上发布。
这项评估本身极其困难,能够真正理解这些问题的专家屈指可数。关键的一点是:Aletheia 的所有解答均在没有任何人工干预的情况下生成,并且在 FirstProof 挑战规定的时间范围内提交。
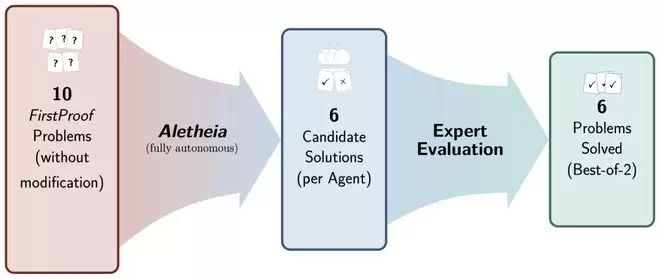
研究团队执行整体流程
FirstProof 的第一作者确认了这一事实:

研究团队运行了两个版本的 Aletheia(两者仅在底层基础模型上有所不同),它们都由 Gemini DeepThink 提供支持。综合多数专家评审意见,这两个系统共同解决了 10 道题中的 6 道(第 2、5、7、8、9、10 题)。我们注意到,专家们对第 8 题的评估并不完全一致。
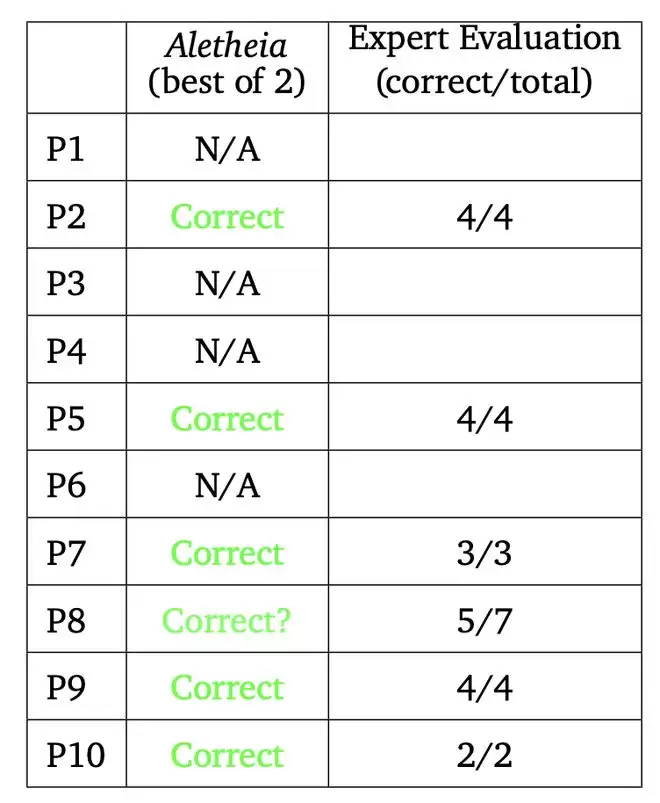
Aletheia 在 FirstProof 上的性能总结。专家评估列显示了在咨询的总专家人数中,有多少专家将解决方案评为正确。仅在 P8 上的评估不是一致的。
Aletheia 的「解题分析」
两个智能体在同样的 FirstProof 十个问题的执行结果如下所示:
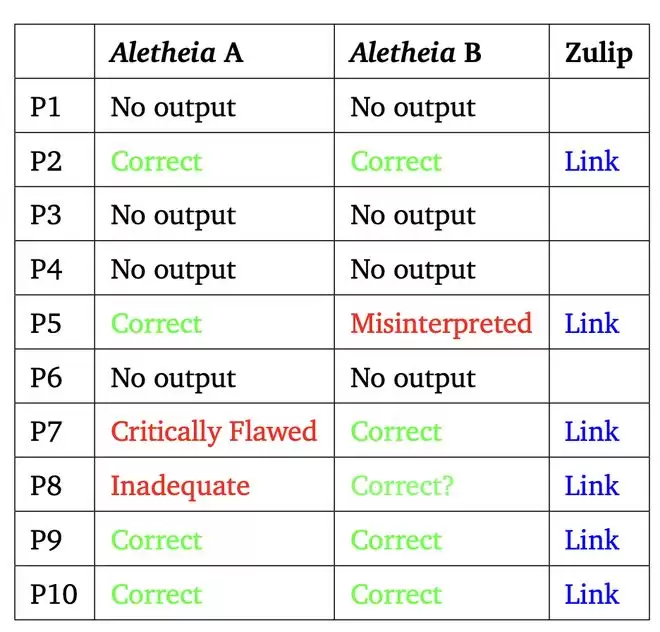
在 FirstProof 的 10 道问题中,Aletheia 为其中 6 道题(P2、P5、P7、P8、P9、P10)生成了候选解答。在「best-of-2」的评估设置下,根据多数专家的评审意见,这 6 道题都被认定为在该解释框架下已正确解决。
Aletheia A 与 Aletheia B 针对相同的六道题目都生成了候选解答。单独来看,每个智能体都至少出现过一次「假阳性」(false positive),但在 best-of-2 的评估机制下,它们共同为六道题目都提供了可信的解答。这一结果相比 2025 年 12 月用于解决 Erdős 问题的 Aletheia 版本,在准确率上有明显提升。
不过,P8 的评估并非一致通过 ——7 位专家中有 5 位给出了「Correct」的评价。对于另外 4 道题(P1、P3、P4、P6),两个智能体都没有给出解答:要么明确输出「No solution found」(未找到解答),要么在时间限制内没有返回任何结果。
研究团队认为,Aletheia 具备一种「自我筛选」机制,这也是 Aletheia 的关键设计原则之一。
在将 AI 扩展为数学研究助手的过程中,可靠性才是首要瓶颈。如果智能体给出错误的「幻觉」答案,会极度浪费人类专家用于验证结果的时间与精力,与提高研究效率和自动化的目标背道而驰。
此外,解决问题的推理成本也是非常重要的指标。
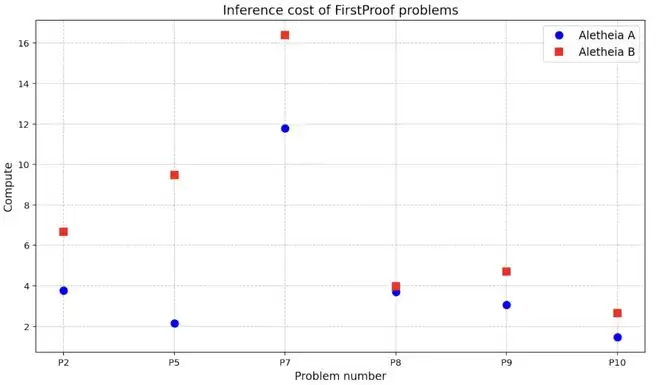
在图中展示了每个候选解的推理成本,并将其表示为相对于 Erdős-1051 解答推理成本的倍数。不难发现,Aletheia 在所有问题上,推理成本都高于 Erdős-1051。
尤其是 P7,其推理成本比此前观察到的规模高出一个数量级。研究者称,这一方面是因为 Generator 子智能体在生成候选解时消耗了大量计算资源,另一方面是因为需要更多轮交互才能通过 Verifier 子智能体的验证。
总结
数学研究包含多个环节:提出问题、建立框架、寻找关键结构、完成证明。当前系统显然还无法全面承担所有角色,但它已经开始在证明与验证环节发挥作用。
未来的研究场景或许会发生变化。人类研究者提出方向与核心思想,AI 负责高强度的路径搜索与形式化验证,再由人类进行理论整合与升华。这种协作模式,正在逐渐成形。
数学长期以来被视为人类理性能力的高地。如今,AI 正在这里取得实质性突破。当机器开始稳定地完成研究级证明,我们或许需要重新思考一个问题:
在未来的数学论文作者名单中,AI 会以什么身份出现?
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:谷歌FirstProof数学挑战新纪录:超越IMO金牌难度要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点微软与约翰霍普金斯大学的研究团队近日联合发表了一项最新研究成果,提出了一种名为 KBLAM (Knowledge Base augmented Language Model,即知识库增强语言模型) 的创新方法。简单来说,KBLAM的核心思路是:将知识库压缩成一张张“知识卡片”,并直接嵌入到大语言模型
MCP这个词,最近在圈子里频繁刷屏。说到底,MCP协议的出现,确实把模型调用工具的难度拉低了一大截。发布短短几个月,各类工具的MCP服务就像雨后春笋般冒了出来。 但说实话,MCP本身的使用逻辑并不难——跟平时和AI聊天提需求差不多。真正的痛点,卡在配置环节。目前支持MCP的客户端,要么是Claude
摘 要:快速、精准地识别铝型材表面缺陷,是生产线面临的一项实际挑战。传统方法要么成本高昂、设备复杂,要么检测效率欠佳。本文提出一种基于YOLO深度学习模型的缺陷识别方案——首先通过图像增广技术解决样本量不足和类别分布不均问题,随后构建YOLO模型,并增加预测尺度以增强对微小缺陷的捕捉能力。同时,对缺
树莓派安装OpenCV 4 完整实战教程:从零开始搭建计算机视觉环境 早期的计算机主要依赖键盘和鼠标进行交互,但如今它们已经进化到能够智能读取图像与视频中的信息。这种能力——让计算机从图像中提取、分析并理解信息——正是计算机视觉的核心。近年来,计算机视觉技术突飞猛进,不仅能识别出人和物体,还能分析其
- 日榜
- 周榜
- 月榜
热点快看